创作不易,友友们给个三连呗!!
本文为经典算法OJ题练习,大部分题型都有多种思路,每种思路的解法博主都试过了(去网站那里验证)是正确的,大家可以参考!!
一、移除元素(力扣)
经典算法OJ题:移除元素
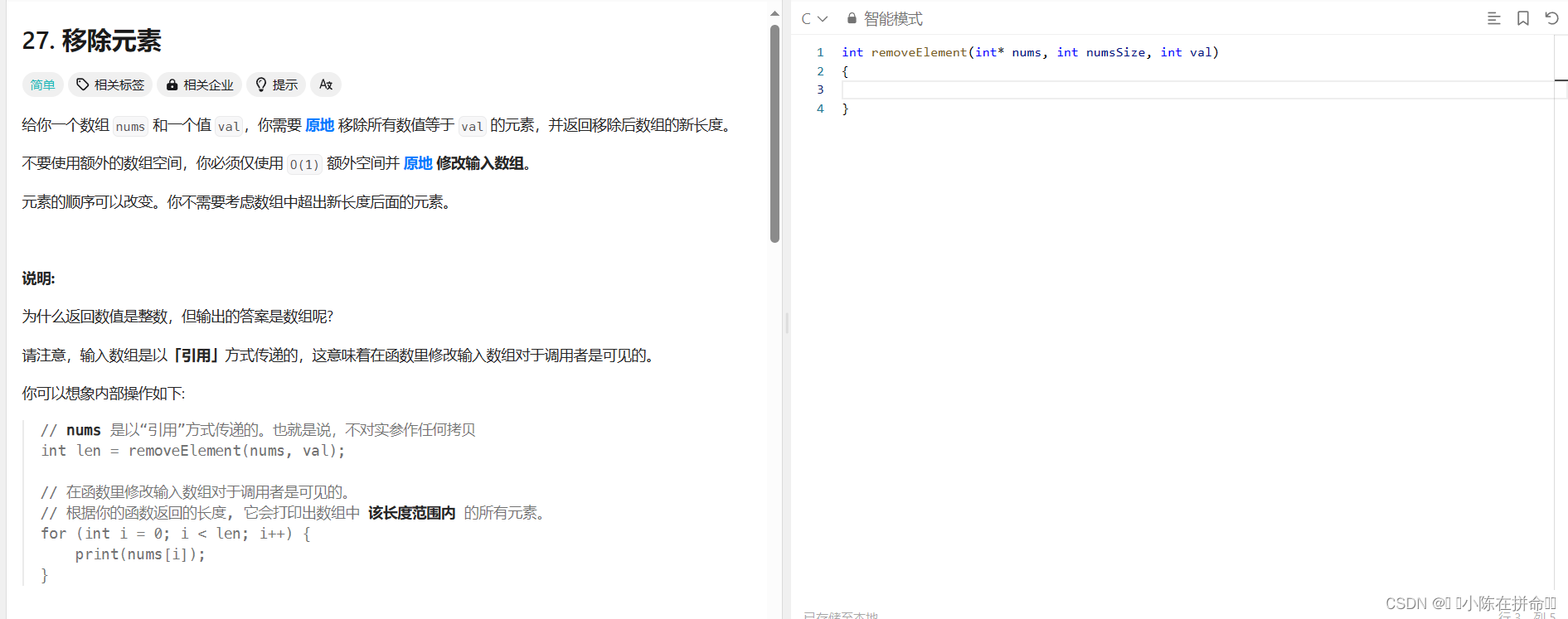 思路1:遍历数组,找到一个元素等于val,就把后面的所有元素往前挪,类似顺序表实现中的指定位置删除!
思路1:遍历数组,找到一个元素等于val,就把后面的所有元素往前挪,类似顺序表实现中的指定位置删除!
//思路1:遍历数组,找到一个元素等于val,就把后面的所有元素往前挪,类似顺序表实现中的指定位置删除!
int removeElement(int* nums, int numsSize, int val)
{
for (int i = 0; i < numsSize; i++)//用来遍历
{
if (nums[i] == val)//要挪动,而且是从前往后挪
{
for (int j = i; j < numsSize - 1; j++)
nums[j] = nums[j + 1];//从前往后挪
numsSize--;//挪完长度-1
i--;//挪动后新的数据还在原来的位置,所以不能让i往前走!!
}
}
return numsSize;
}思路2:(双指针法)利用双指针,第一个指针引路,第二个指针存放想要的元素(不等于val的元素)(较优)
//思路2:(双指针法)利用双指针,第一个指针引路,第二个指针存放想要的元素(不等于val的元素)
int removeElement(int* nums, int numsSize, int val)
{
int src = 0;//用来探路,src即原操作数
int dst = 0;//用来存放想要的数据,dst即目标操作数
while (src < numsSize)
{
if (nums[src] == val)
{
src++;//找到val就src走
}
else
{
nums[dst] = nums[src];//dst接收想要的数据
//找不到就两个都走
dst++;
src++;
}
}
//此时dst恰好就是数组的新长度
return dst;
}二、合并两个有序数组(力扣)
经典算法OJ题:合并两个有序数组

思路1:num2全部存储到num1中,再统一进行排序(qsort)
int int_cmp(const void* p1, const void* p2)//比较方法
{
return (*(int*)p1 - *(int*)p2);//返回值来影响qsort
}
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{
int i = m;//指向数组1后面的空位置
int j = 0;//指向数组2
while (i < m + n)
{
nums1[i] = nums2[j];
i++;
j++;
}
//循环结束说明插入完成,使用快速排序
qsort(nums1, m + n, sizeof(int), int_cmp);
}思路2:合并的时候顺便排序,利用3个指针,l1用来遍历数组1,l2用来遍历数组2,比大小之后的数据用l3记录。(较优)
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{
int l1=m-1;//从1数组的最后一个有效数据往前
int l2=n-1;//从2数组的最后一个有效数据往前
int l3=n+m-1;//从1数组的最后一个元素开始往前
while(l1>=0 && l2>=0)//l1和l2其中一个遍历完就得跳出循环
{
//从后往前比大小
if(nums1[l1]>nums2[l2])
nums1[l3--]=nums1[l1--];
else
nums1[l3--]=nums2[l2--];
}
//循环结束后,有两种情况,一种是l1先遍历完,此时l2要接着插进去,
//另一种是l2先遍历完,此时l1就不需要处理了
while(l2>=0)
nums1[l3--]=nums2[l2--];
}三、移除链表元素(力扣)
经典算法OJ题:移除链表元素
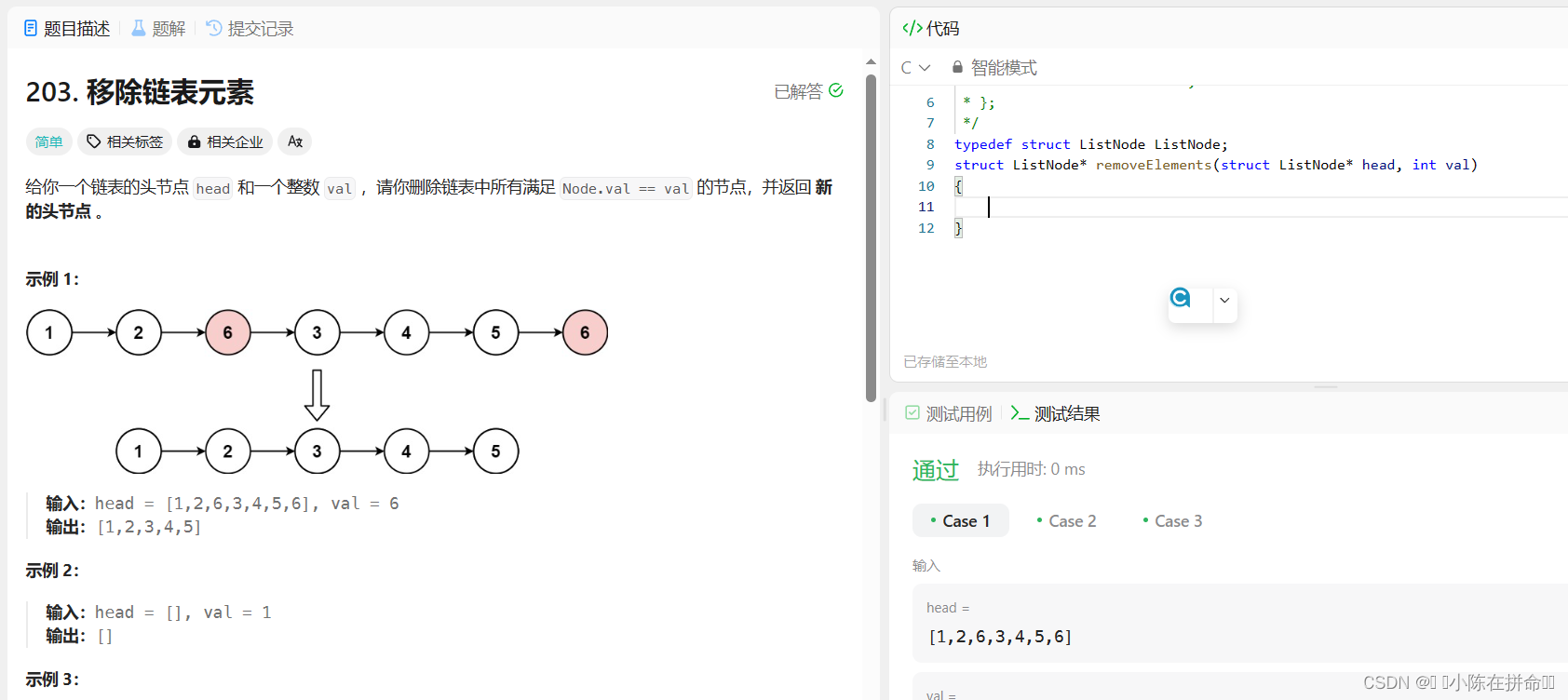
思路1:遍历原链表,遇到val就删除,类似单链表的指定位置删除
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{
//考虑头节点就是val的情况
while(head!=NULL&&head->val==val)
head=head->next;
//此时头节点不可能是val
//当链表为空
if(head==NULL)
return head;
//当链表不为空时
ListNode*pcur=head;//用来遍历链表
ListNode*prev=NULL;//用来记录前驱结点
while(pcur)
{
//当找到val时
if(pcur->val==val)
{
prev->next=prev->next->next;//前驱结点指向pucr的下一个结点
free(pcur);//删除的结点被释放
pcur=prev->next;//继续指向新的结点
}
//没找到val时
else
{
prev=pcur;//往后走之前记录前驱结点
pcur=pcur->next;//pcur往前遍历
}
}
return head;
}思路2:定义一个不带头新链表,将不为val的结点尾插进去
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{
ListNode*pcur=head;//用来遍历链表
//定义新链表的头尾指针
ListNode*newhead=NULL;//用来记录头
ListNode*newtail=NULL;//用来尾插新链表
while(pcur)
{
if(pcur->val!=val)//不满足val则插入到新链表
{
//一开始链表是空的
if(newhead==NULL)
newhead=newtail=pcur;
//链表不为空了,开始尾插
else
{
newtail->next=pcur;//尾插
newtail=newtail->next;//尾插后向后挪动
}
}
pcur=pcur->next;//pcur要遍历往后走
}
//插入完后要加NULL!还要避免newtail是空的情况
if(newtail)
newtail->next=NULL;
return newhead;
}思路3:给原链表创造一个哨兵结点,然后遍历,遇到val就删(和思路1比较,多了一个哨兵,稍优于思路1)
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{
ListNode*newhead=(ListNode*)malloc(sizeof(ListNode));//创建一个新的哨兵节点
newhead->next=head;//哨兵接头
ListNode*pcur=head;//用来遍历链表
ListNode*prev=newhead;//记录前驱结点
while(pcur)
{
//遇到了,开始删除
if(pcur->val==val)
{
prev->next=pcur->next;
free(pcur);
pcur=prev->next;
}
//如果没遇到val,都往后走
else
{
prev=pcur;
pcur=pcur->next;
}
}
//循环结束,删除完成
ListNode*ret=newhead->next;//释放哨兵结点前记住需要返回的结点
free(newhead);
newhead=NULL;
return ret;
}思路4:定义一个带头新链表,将不为val的结点尾插进去(和思路2相比较,多了一个哨兵)(较优)
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val)
{
ListNode*newhead,*newtail;
newhead=newtail=(ListNode*)malloc(sizeof(ListNode));//创建一个新的哨兵节点
ListNode*pcur=head;//用来遍历链表
while(pcur)
{
if(pcur->val!=val)
{
//找打不为val的值 开始尾插
newtail->next=pcur;
newtail=newtail->next;
}
pcur=pcur->next;//没找到就往后找
}
newtail->next=NULL;
ListNode*ret=newhead->next;//释放哨兵时记住返回值
free(newhead);
newhead=NULL;
return ret;
}四、反转链表(力扣)
经典算法OJ题:反转链表
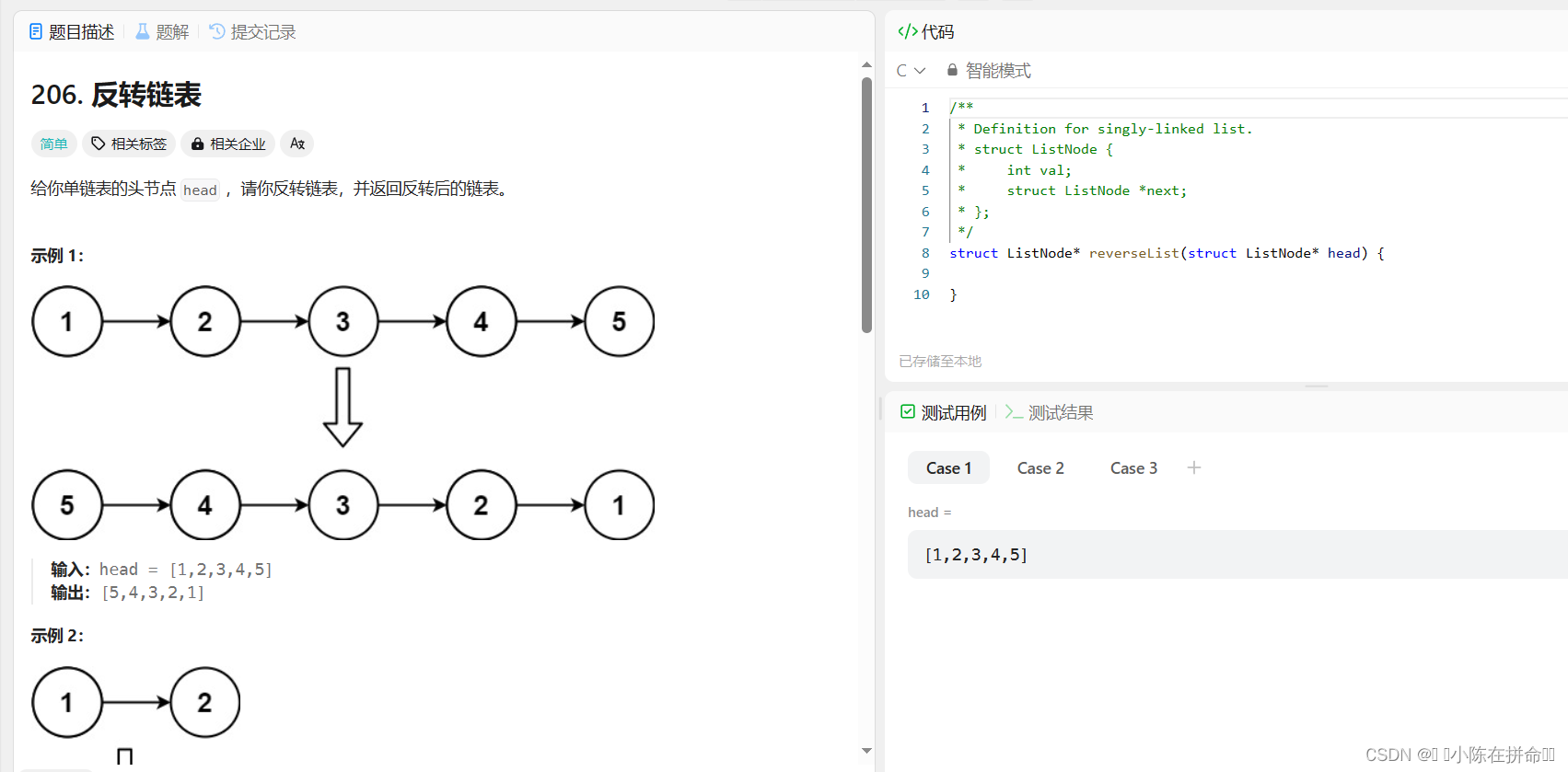
思路1:利用带头单链表头插法,建立一个新的带头结点的单链表L,扫描head链表的所有结点,每扫描一个结点就创造一个s结点并将值赋给s结点然后头插法插入新链表L中,得到的就是逆序的head链表
typedef struct ListNode ListNode;
ListNode*BuyNode(int x)//封装创建新结点的函数
{
ListNode*newnode=(ListNode*)malloc(sizeof(ListNode));
newnode->next=NULL;
newnode->val=x;
return newnode;
}
struct ListNode* reverseList(struct ListNode* head)
{
ListNode*pcur=head;//用来遍历
ListNode*newhead=BuyNode(-1);//创建哨兵结点
ListNode*temp=NULL;//充当临时变量
while(pcur)
{
temp=BuyNode(pcur->val);//创建新结点接收pur的值
//头插
temp->next=newhead->next;
newhead->next=temp;
//pcur往后走
pcur=pcur->next;//pcur往后走
}
ListNode*ret=newhead->next;//哨兵位释放之前保存头节点
free(newhead);
newhead=NULL;
return ret;
}思路2:利用带头单链表头插法,建立一个新的带头结点的单链表L,扫描head链表的所有结点,每扫描一个结点就头插法插入新链表L中,得到的就是逆序的head链表(相比思路1多了个哨兵,稍优于思路1)
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{
//如果链表为空
if(head==NULL)
return head;
//如果链表不为空
ListNode*newhead,*newtail;//一个哨兵,一个记录尾巴方便后面置NULL;
newhead=(ListNode*)malloc(sizeof(ListNode));//创建哨兵结点
newhead->next=head;//哨兵和原来的头节点连接起来
newtail=head;//newtail记住一开始的head,方便后面连接NULL
ListNode*pcur=head->next;//pcur用来遍历(从第二个)
ListNode*temp=NULL;//用来记录下一个遍历点
while(pcur)
{
temp=pcur->next;//连接前,先记住下一个结点的位置
//头插 插在哨兵结点和原来头结点的中间
newhead->next=pcur;
pcur->next=head;
head=pcur;//头插进来的成为哨兵结点后面的新头
pcur=temp;//pcur从原先链表的下一个结点开始继续遍历
}
newtail->next=NULL;//要记得给尾巴结点连接NULL;
free(newhead);
newhead=NULL;
return head;
}思路3:利用不带头链表头插法,扫描head链表的所有结点,每扫描一个结点就头插法插入新链表L中,得到的就是逆序的head链表(较优)
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{
//如果链表为空
if(head==NULL)
return head;
//如果链表不为空
ListNode*pcur=head->next;//用来遍历
ListNode*ptail=head;//用来记录尾巴,方便后面置NULL;
ListNode*temp;//记录遍历的结点
while(pcur)
{
temp=pcur->next;
//头插到head前面
pcur->next=head;
head=pcur;
pcur=temp;
}
ptail->next=NULL;
return head;
}思路4:利用3个指针,分别记录前驱结点、当前结点、后继结点,改变原链表的指针指向(最优)
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head)
{
//链表为空的时候
if(head==NULL)
return head;
//链表不为空的时候,创建3个指针,分别指向前驱、当前、后继结点
ListNode*p1,*p2,*p3;
p1=NULL;//前驱
p2=head;//当前
p3=head->next;//后继
while(p2)
{
//改变指向
p2->next=p1;
//向后挪动
p1=p2;
p2=p3;
//考虑p3为NULL的时候
if(p3)
p3=p3->next;
}
return p1;
}五、合并两个有序链表(力扣)
经典算法OJ题:合并两个有序链表
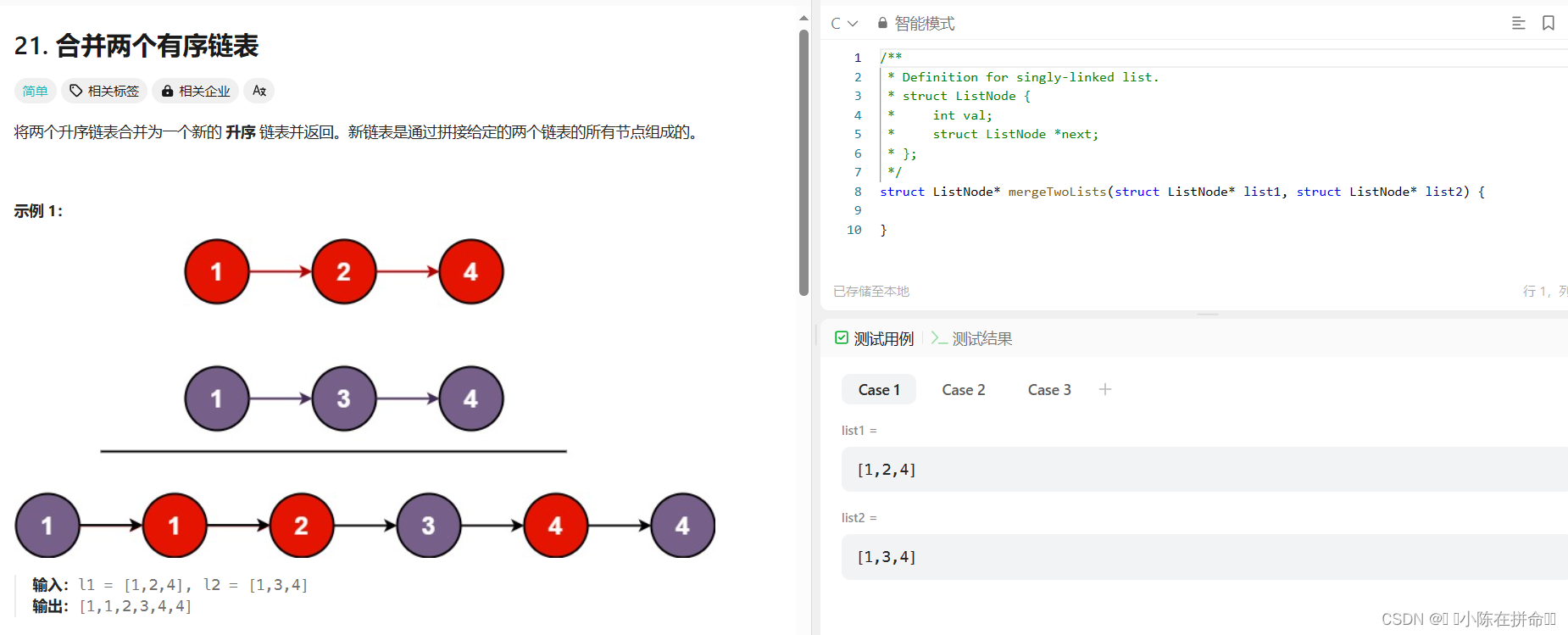
思路1:创建一个哨兵节点,双指针判断两组数据的大小,因为是把 list2 的节点插入 list1 ,所以只要当 list1 指向的数大于 list2 的数,就把当前 list2 节点插入 list1 的前面。循环判定条件,只要双指针中有一个为空就跳出循环,即有一个指针到了节点末端。若 list1 先结束,表示剩下 list2 的数都比 list1 里的数大,直接把 list2 放到 list1后即可若 list2 先结束,即表示已经合并完成。
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
ListNode*newhead=(ListNode*)malloc(sizeof(ListNode));//创建一个新的哨兵结点
newhead->next=list1;//哨兵点与list1相连接
ListNode*p1=list1;//利用p1遍历链表1
ListNode*p2=list2;//利用p2遍历链表2
ListNode*prev=newhead;//prev记录前驱结点
ListNode*temp=NULL;//充当临时变量,暂时保存list2的指向
while(p1&&p2)//p1和p2有一个为NULL了就必须跳出循环
{
if(p1->val>p2->val)//list2插入list1该元素前面
{
temp=p2->next;//记住p2指针的遍历点
//尾插
prev->next=p2;
p2->next=p1;
//尾插完成往前走
prev=p2;
p2=temp;
}
//找不到时,prev和p1都往后走
else
{
p1=p1->next;
prev=prev->next;
}
}
//跳出循环后有两种可能,一种是p1先为NULL,一种是p2先为NULL
//此时prev恰好走到尾结点
//如果p2为NULL,说明已经结束!如果p1为NULL,此时尾插p2在prev后面
if(p1==NULL)
prev->next=p2;
ListNode*ret=newhead->next;//哨兵位要释放,返回前要记录newhead->next
free(newhead);
newhead=NULL;
return ret;
}思路2:定义一个带头新链表(方便返回),两个指针分别指向两组数组,逐个比较,较小的尾插到新的链表中,循环判断条件,只要有一个指针为NULL就跳出循环,无论是 list1 结束还是 list2 结束,只需要把剩下的部分接在新链表上即可。(较优)
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
ListNode*newhead,*newptail;
newhead= newptail=(ListNode*)malloc(sizeof(ListNode));//创建一个新的哨兵结点
//newptail是用来尾插的
ListNode*p1=list1;//利用p1遍历链表1
ListNode*p2=list2;//利用p2遍历链表2
while(p1&&p2)//p1和p2有一个为NULL了就必须跳出循环
{
if(p1->val<p2->val)
{
newptail->next=p1;//尾插
newptail=newptail->next;//插入后newptail往后走
p1=p1->next;//插入后p1往后走
}
else
{
newptail->next=p2;//尾插
newptail=newptail->next;//插入后newptail往后走
p2=p2->next;//插入后p2往后走
}
}
//跳出循环后有两种可能,一种是p1先为NULL,一种是p2先为NULL
//在newtail后面插入不为NULL的链表。
newptail->next=(p1==NULL?p2:p1);
ListNode*ret=newhead->next;//哨兵位要释放,返回前要记录newhead->next
free(newhead);
newhead=NULL;
return ret;
}六、链表的中间结点(力扣)
经典算法OJ题:链表的中间结点

思路1:统计链表中结点的个数,然后除以2找到中间结点
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
int count=0;//用来记录总共的结点数量
ListNode*pcur=head;//用来遍历
while(pcur)
{
pcur=pcur->next;
count++;
}
//此时计算出count,除以2
count=count/2;//此时count代表中间结点的位置
while(count)
{
head=head->next;
count--;
}
return head;
}思路2:(快慢指针法),创建两个指针一开始都指向头节点,一个一次走一步,一个一次走两步,当快指针为NULL时,慢指针指向的就是中间的位置(较优)
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
ListNode*fast,*slow;
fast=slow=head;//都指向头结点
while(fast!=NULL&&fast->next!=NULL)//存在一个就得跳出循环
//而且顺序不能反!!!因为与运算符从前往后运算
{
fast=fast->next->next;//走两步
slow=slow->next;//走一步
}
//循环结束slow正好指向中间结点
return slow;
}七、分割链表(力扣)
经典算法OJ题:分割链表
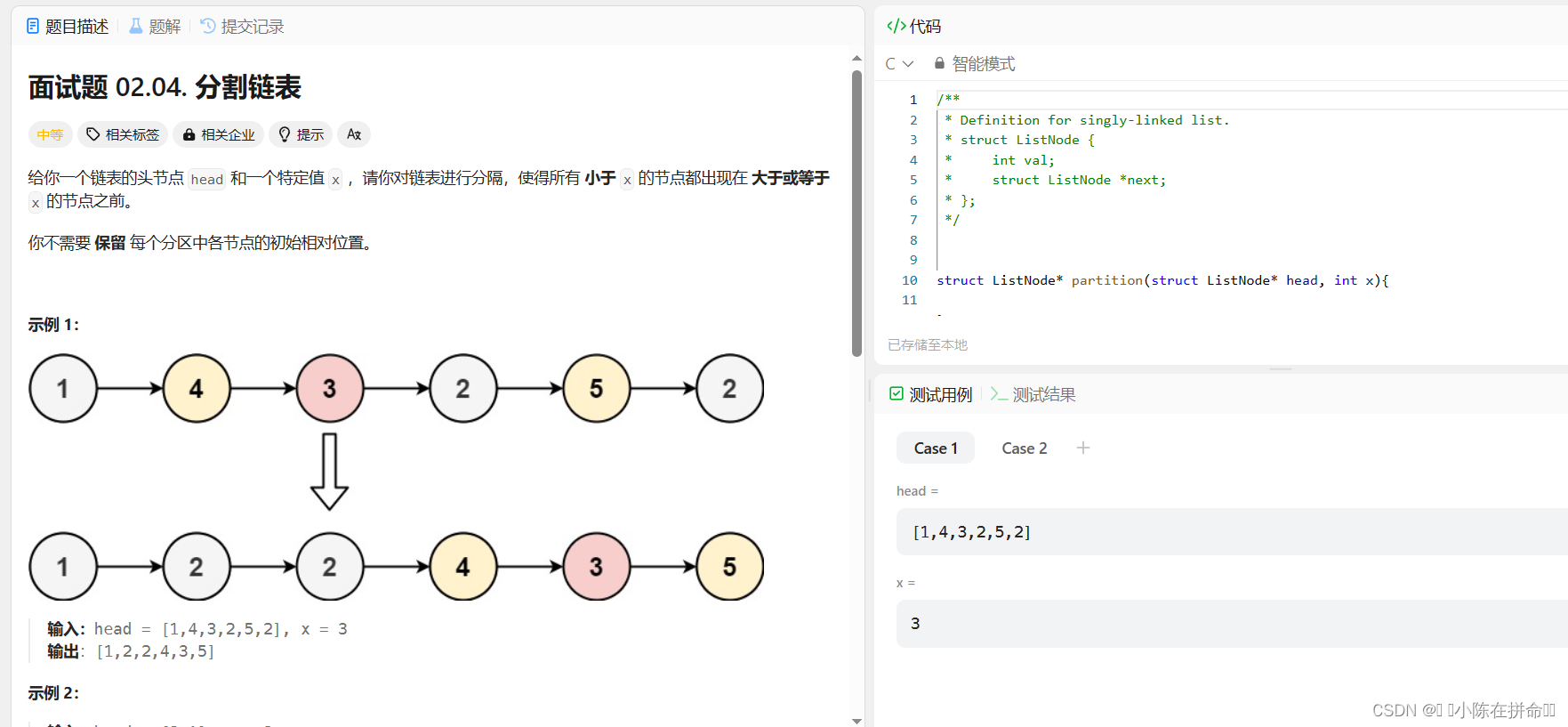
思路1:创建一个新链表,遍历原链表,小的头插,大的尾插。
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x)
{
//链表为空
if(head==NULL)
return head;
//链表不为空
ListNode*pcur,*newtail;
pcur=newtail=head;//pcur用来遍历 newtail用来尾插
while(pcur)
{
ListNode * temp=pcur->next;
if(pcur->val<x)
{
//头插
pcur->next=head;
head=pcur;//pcur成为新的头
}
//尾插
else
{
newtail->next=pcur;
newtail=newtail->next;
}
pcur=temp;//继续遍历
}
newtail->next=NULL;
return head;
}思路2:创建两个新链表,遍历原链表,大的尾插大链表,小的尾插小链表,最后合并在一起。
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x)
{
if(head==NULL)
return head;
ListNode*bighead,*bigtail,*smallhead,*smalltail;
bighead=bigtail=(ListNode*)malloc(sizeof(ListNode));//大链表哨兵
smallhead=smalltail=(ListNode*)malloc(sizeof(ListNode));//小链表哨兵
ListNode*pcur=head;//pcur用来遍历
while(pcur)
{
if(pcur->val<x)
//尾插小链表
{
smalltail->next=pcur;
smalltail=smalltail->next;
}
else
//尾插大链表
{
bigtail->next=pcur;
bigtail=bigtail->next;
}
pcur=pcur->next;//继续往下走
}
//遍历完成,连接大小链表
smalltail->next=bighead->next;
bigtail->next=NULL;
ListNode*ret=smallhead->next;//记住返回值
free(bighead);
free(smallhead);
return ret;
}八、环形链表的约瑟夫问题(牛客)
经典算法OJ题:环形链表的约瑟夫问题
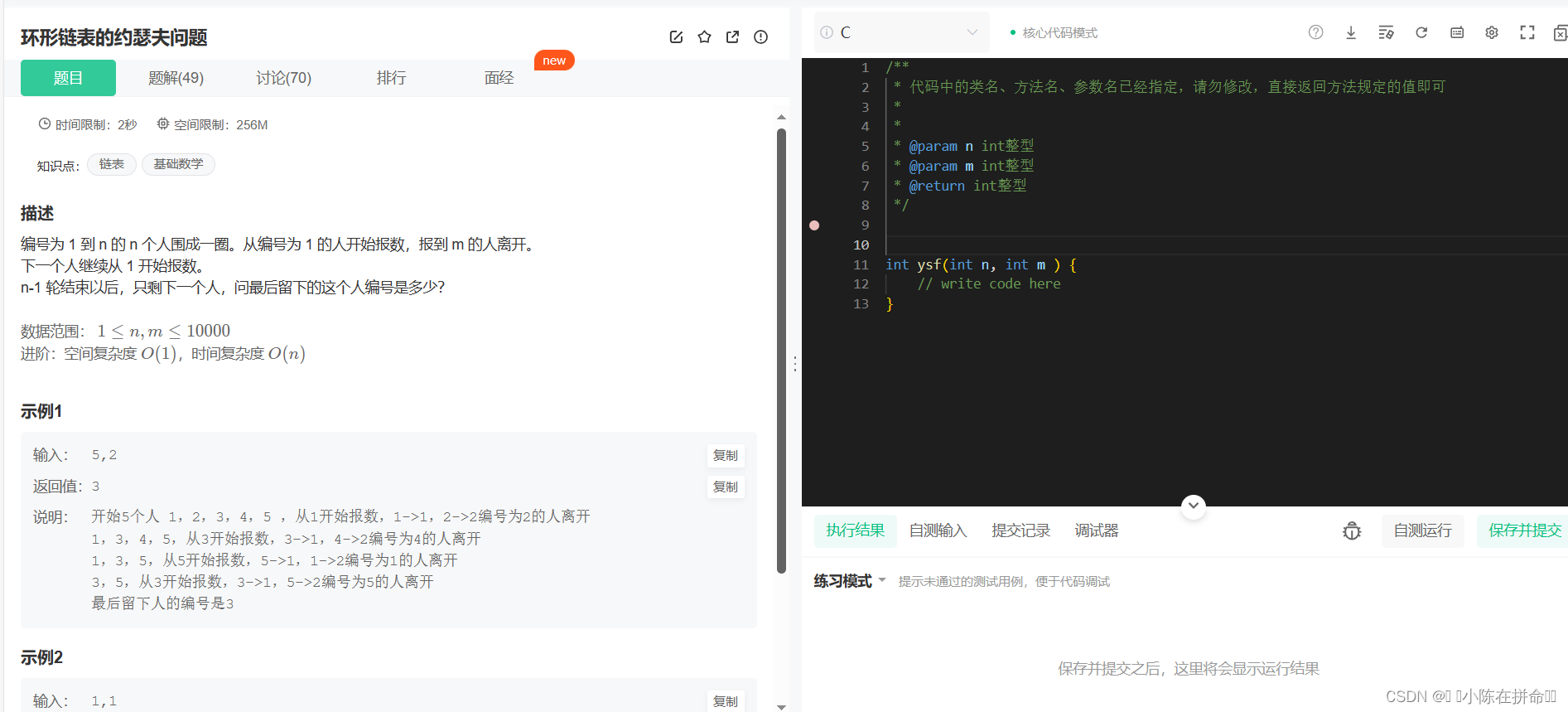
思路:创建一个不带头的单向链表,每逢m就删除
typedef struct ListNode ListNode;
ListNode * BuyNode(int x)//创建结点的函数
{
ListNode *newnode=(ListNode *)malloc(sizeof(ListNode));
newnode->next=newnode;
newnode->val=x;
return newnode;
}
int ysf(int n, int m ) {
// write code here
//创建一个不带头的单向循环链表
ListNode *phead=BuyNode(1);//创建一个头节点
ListNode *ptail=phead;//用来遍历
for(int i=2;i<=n;i++)
{
ptail->next=BuyNode(i);
ptail=ptail->next;
}
//创建完后要首尾相连
ptail->next=phead;
ListNode *pcur=phead;//pcur用来遍历
ListNode *prev=NULL;//用来记录前驱结点
int count=1;//用来数数
while(pcur->next!=pcur)//结束条件是场上只剩下一个人
{
if(count==m)
{
//指定位置删除
prev->next=pcur->next;
free(pcur);
pcur=prev->next;
count=1;//重新数
}
else
{
prev=pcur;
pcur=pcur->next;
count++;
}
}
//此时pcur是场上唯一还在的结点
return pcur->val;
}九、总结
1、顺序表背景的OJ题较为简单,因为顺序表底层是数组,有连续存放的特点,一方面指针运算偏移比较容易(可以多往指针的方向思考),另一方面就是我可以根据下标去拿到我想要的元素,无论是从前遍历还是从后遍历还是从中间都很方便!所以解题思路容易一些,而单链表只能通过指向,并且非双向的链表想从后面或者中间遍历会比较吃力!
2、顺序表背景的题,如果涉及到指定位置插入或者是指定位置删除,需要大量挪动数据,多层for循环比较麻烦,有时候可以往指针运算去思考!
3、链表背景的题,涉及到有关中间结点的,一般是快慢指针!!
4、关于链表的头插,如果是两个链表根据情况插入到一个新链表的头插,那么创建一个哨兵位结点会比较容易点,因为这样可以避免一开始就得换头结点。如果是在原链表的基础上头插,因为原链表是存在头节点的,这个时候不设哨兵位就会简单点,因为可以直接换头。
5、关于链表的尾插,一般需要设置一个tail指针往后遍历。
6、关于链表的指定位置插入或删除,需要记录前驱结点,这个时候需要除了需要考虑头节点为NULL的情况,还要考虑链表只有一个结点的情况,因为这个时候也没有前驱结点,这个时候如果运用哨兵就不需要考虑只有一个结点的情况,因为哨兵位可以充当头结点的前驱结点。
7、哨兵链表容易记住起始地址