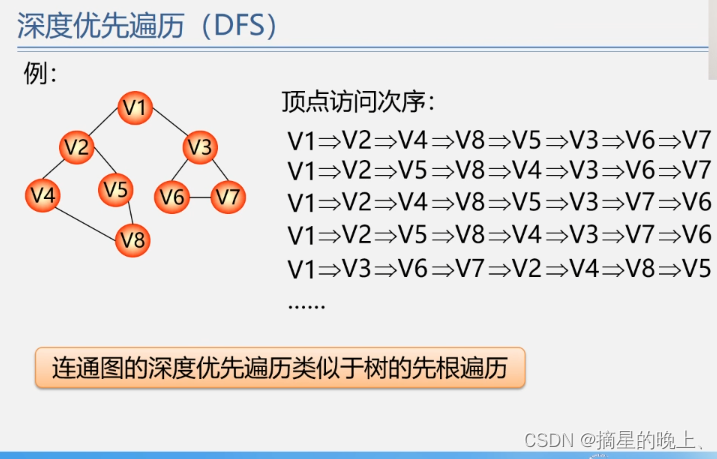
如何使大型语言模型更加事实、正确和可靠?
检索增强生成(RAG)是一种有效的方法,可以缓解大型语言模型的基本局限性,如幻觉和缺乏最新知识。
然而,如果您曾尝试过RAG,您会同意我所说的RAG易于原型设计,但很难达到理想的水平。
在本文中,我将讨论一篇关于自我RAG的新研究论文:Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection,该论文提出了一种改进RAG模型性能的新方法。
介绍 Self-RAG:一种新方法
RAG 效率在很大程度上依赖于诸如文本分块方法、嵌入和检索技术等因素。
当不加选择地检索固定数量的段落,或者获取与查询无关的内容时,可能会导致糟糕的响应,并降低 LLM 的多功能性。
在2023年10月,一篇名为“Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection”的新研究论文引入了一种创新框架。这个框架通过教导LLM何时检索来增强其一致性和性能。
实验证明,自我RAG(7B和13B参数)在各种任务上显著优于最先进的LLM(例如ChatGPT和Llama2-chat)以及检索增强模型。
让我们深入探讨吧!
用通俗易懂的方式讲解系列
- 用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
- 用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
- 用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
- 用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
- 用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
- 用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调)
- 用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
- 用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
- 用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
- 用通俗易懂的方式讲解:大模型训练过程概述
- 用通俗易懂的方式讲解:专补大模型短板的RAG
- 用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
- 用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
- 用通俗易懂的方式讲解:大模型微调方法总结
- 用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
- 用通俗易懂的方式讲解:掌握大模型这些优化技术,优雅地进行大模型的训练和推理!
Self-RAG:教导LLM何时检索
自我反思式检索增强生成(Self-RAG)是一种新方法,它教导LLM在检索、生成和评论中以增强其响应的准确性和质量。
与传统的检索增强生成(RAG)方法相反,Self-RAG 根据需要检索信息,这意味着它可以根据遇到的查询多次检索或根本不检索。
它还从各个角度评估其响应,使用称为“反思标记”的特殊标记。这些标记允许LLM控制其行为,并在推理阶段根据特定任务要求进行定制。

Self-RAG 内部工作原理
Self-RAG 方法的核心思想是通过一种称为“自我反思标记”的东西来教导和控制大型语言模型(LLM)。这个过程发生在推理阶段,即LLM生成响应时。
以下是Self-RAG 的工作方式:
- 检索:Self-RAG 首先确定将检索到的信息添加到响应是否有帮助。如果是,它会发出一个检索过程的信号,并要求外部检索模块找到相关文档。
- 生成:如果不需要检索,Self-RAG 会像常规语言模型一样预测响应的下一个部分。如果需要检索,它首先评估检索到的文档是否相关,然后根据所发现的内容生成响应的下一个部分。
- 评论:如果需要检索,Self-RAG 会检查它检索到的段落是否支持响应。它还评估响应的整体质量。
Self-RAG 的训练过程
Self-RAG 训练了两个模型,评论家和生成器,两者都使用反思标记扩展令牌词汇,并使用标准的下一个令牌预测目标进行训练。
- 第一步 评论家数据创建:通过提示GPT-4生成反思标记,生成评论家的训练数据。
- 第二步 评论家训练:在合成数据集上训练评论家模型。
- 第三步 生成器数据创建:使用评论家和检索器生成生成器的训练数据。
- 第四步 生成器训练:在RAG数据集上训练生成器,包括特殊标记,以教导模型何时进行检索或不检索。
实际应用:使用 Self-RAG
现在,让我们从理论方面转向 Self-RAG 的实际应用!
以下代码可以在免费的Colab笔记本实例上运行。
使用 Self-RAG 进行推理
Self-RAG 模型在基础模型 Llama-2-7b-hf 上进行了微调,并且可以在Hugging Face上获取。这使得从Hub下载模型并进行测试变得非常简单。
以下是如何使用 Self-RAG 进行推理的方法。
- 安装必要的包
!pip install vllm
!pip install torch
!pip install transformers, tokenizer, datasets, peft, bitsandbytes
!pip install accelerate>=0.21.0,<0.23.0 # 0.23.0将在使用deepspeed时导致不正确的学习率调度,可能是由https://github.com/huggingface/accelerate/commit/727d624322c67db66a43c559d8c86414d5ffb537引起的
!pip install peft>=0.4.0
!pip install evaluate>=0.4.0
!pip install tiktoken
- 运行推理
我们将使用研究团队推荐的vllm来加速推理。
# 导入必要的库
from vllm import LLM, SamplingParams
# 使用指定的模型和数据类型初始化LLM(大型语言模型)
model = LLM("selfrag/selfrag_llama2_7b", dtype="half")
# 为文本生成定义采样参数
sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=100, skip_special_tokens=False)
# 定义一个函数来格式化提示,包括指令和可选的检索段落
def format_prompt(input, paragraph=None):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]{0}".format(paragraph)
return prompt
# 为模型生成响应的两个查询
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the difference between llamas and alpacas?"
queries = [query_1, query_2]
# 为查询生成响应
preds = model.generate([format_prompt(query) for query in queries], sampling_params)
# 打印每个查询的模型预测
for pred in preds:
print("\n\nModel prediction: {0}".format(pred.outputs[0].text))
让我们分析一下 Self-RAG 的输出。
我们执行了两个查询,并观察到对于第一个查询,自我RAG直接生成响应,因为不需要检索信息。在第二个查询中,自我RAG显示出[Retrieve]标记,因为问题需要更多的事实信息。

使用您自己的数据运行 Self-RAG
在这里,我们将探讨两种使用您自己的数据与自我RAG进行交互的方法:
直接数据插入:最简单的方法是将您的数据直接插入到format_prompt函数的段落参数中。这样可以让自我RAG直接访问并将您的数据整合到其响应生成过程中。
基于嵌入的检索:对于更复杂的数据或直接插入不可行的情况,您可以为您的数据生成嵌入,并利用检索机制提取自我RAG所需的相关信息。这种方法使自我RAG能够根据查询的上下文选择性地检索和利用您的数据中的信息。
直接数据插入
对于需要外部事实支持的查询,您可以插入一个段落。
自我RAG可以在生成过程中随时检索和插入段落,并在它们被上下文标记特殊令牌所包围时识别它们。

基于嵌入的检索
您可以利用原始研究论文提供的脚本和代码将您自己的数据整合到自我RAG中。该过程包括三个主要步骤:
- 数据准备
将您的数据集准备为JSON或JSONL格式。每个实例应包含一个问题或一条指令,这将在检索过程中用作查询。
- 嵌入生成
使用GitHub存储库中提供的脚本为您的数据生成嵌入。这将将您的数据转换为数字表示,可以有效地通过检索机制处理。
cd retrieval_lm
CUDA_VISIBLE_DEVICES=0
python generate_passage_embeddings.py --model_name_or_path facebook/contriever-msmarco \
--output_dir [YOUR_OUTPUT_DIR] \
--passages [YOUR_PASSAGE_DATA] \
--shard_id 0 --num_shards 4 > ./log/nohup.my_embeddings 2>&1 &
- 运行自我RAG在您自己的数据上
将您生成的嵌入与自我RAG的检索模块结合起来,从您的数据中提取相关信息。然后,自我RAG将利用这些信息生成针对您特定查询的响应。
from passage_retriever import Retriever
retriever = Retriever({})
query = "YOUR_QUERY"
retriever.setup_retriever("facebook/contriever-msmarco", [YOUR_JSON_DATA_FILE], [YOUR_DATA_EMBEDDING], n_docs=5, save_or_load_index=False)
retrieved_documents = retriever.search_document(query, 5)
prompts = [format_prompt(query, doc["title"] +"\n"+ doc["text"]) for doc in retrieved_documents]
preds = model.generate(prompts, sampling_params)
top_doc = retriever.search_document(query, 1)[0]
print("Reference: {0}\nModel prediction: {1}".format(top_doc["title"] + "\n" + top_doc["text"], preds[0].outputs[0].text))
使用 Self-RAG 增强您的RAG流程
或者,您还可以使用Self-RAG方案训练一个新的预训练LLM,例如Mistral-7b。如果您使用hugging face transformers,您可以简单地在训练脚本script_finetune_7b.sh中更改model_name_or_path和tokenizer_name。
export CUDA_VISIBLE_DEVICES=0,1,2,3
MODEL_SIZE=7B
NUM_GPUS=4
BATCH_SIZE_PER_GPU=1
TOTAL_BATCH_SIZE=128
GRADIENT_ACC_STEPS=$(($TOTAL_BATCH_SIZE/$NUM_GPUS/$BATCH_SIZE_PER_GPU))
echo "Training llama model ${MODEL_SIZE} using $NUM_GPUS GPUs, $BATCH_SIZE_PER_GPU batch size per GPU, $GRADIENT_ACC_STEPS gradient accumulation steps"
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch \
--mixed_precision bf16 \
--num_machines 1 \
--num_processes $NUM_GPUS \
--use_deepspeed \
--deepspeed_config_file stage3_no_offloading_accelerate.conf \
finetune.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--use_flash_attn \
--tokenizer_name meta-llama/Llama-2-7b-hf \
--use_slow_tokenizer \
--train_file full_output_1005.jsonl \
--max_seq_length 2048 \
--preprocessing_num_workers 16 \
--per_device_train_batch_size $BATCH_SIZE_PER_GPU \
--gradient_accumulation_steps $GRADIENT_ACC_STEPS \
--learning_rate 2e-5 \
--lr_scheduler_type linear \
--warmup_ratio 0.03 \
--weight_decay 0. \
--num_train_epochs 3 \
--output_dir output/self_rag_${MODEL_SIZE}/ \
--with_tracking \
--report_to tensorboard \
--logging_steps 1 \
--use_special_tokens
最后思考
RAG可能导致糟糕的响应。在该过程中添加特殊标记可以教导模型何时检索信息以及什么是相关的。
自我RAG是一种改进事实性而不牺牲大型语言模型创造性多样性的有趣方法。它展示了让LLM反思自身局限性并有选择地获取知识的好处。
论文中分享的模型经过了对150,000个实例进行的评论家训练。正如您所想象的那样,这是最具挑战性的任务,因为数据集需要对检索和非检索示例都具有多样性。很酷的是,完整的数据集和代码都在GitHub上完全共享,因此您也可以微调您选择的自定义LLM,例如Mistral-7b。
但是,请记住,训练和维护自我RAG模型需要更多的努力。如果您需要LLM提供高度可靠的响应,例如在金融领域,这可能是一个值得的选择。我也渴望看到关于如何增强RAG和解决LLM局限性的新研究。
参考文献
-
https://levelup.gitconnected.com/upgrade-your-retrieval-augmented-generation-with-self-rag-bb30b2a0ffa4
-
https://github.com/AkariAsai/self-rag






![[BT]小迪安全2023学习笔记(第19天:Web开发-.NET项目)](https://img-blog.csdnimg.cn/direct/7927b8d158bd4c4b84232a0ed6cba79b.png)