【MATLAB第95期】#源码分享 | 基于MATLAB的卷积神经网络CNN图像分类源代码分享(含两个案例)
一、案例一
1、背景介绍
目的:训练和测试卷积神经网络,以检测钻头三种类型。
深度学习(DL)是机器学习的一个子集,它使用受神经网络启发的架构来进行预测。卷积神经网络(CNN)是一种DL模型,它在学习图像等二维数据中的模式方面是有效的。钻头类型的图像用于训练分类器,以识别钻头类型。
本练习演示使用图像分类来区分照片中的对象。尽管应用于位类型,但相同的方法和代码可以用于任何类型或数量的对象。此示例可以通过将训练和测试照片包含在使用对象类型命名的文件夹中进行修改。该代码自动将文件夹的名称作为照片标签,用于训练分类器。

图像数据包含两个文件夹,一个测试文件夹和一个训练文件夹,其子目录包含三种钻头类型。图像位于每个子目录中。
照片被导入到MATLAB中。第一步是将图像处理成一种格式,
1)使数据对模型可读,
2)为模型学习提供更多的训练材料。例如,train_processor变量对数据进行缩放,使其可以成为模型的特征(输入),但也可以获取每个图像并对其进行扩充,使模型可以从同一图片的多个变化中学习。它可以水平翻转、旋转和移动钻头,等等,以确保模型从钻头的形状而不是方向或大小中学习。
数据中样本数量有限,总共约有60个。由于缺乏数据,可以将使用测试数据作为验证数据,以便训练更好的神经网络。
2、代码展示
%数据处理
train_processor = imageDataAugmenter( ...
'RandScale', [.8 1.2], ...
'RandXReflection', true, ...
'RandRotation', [-45, 145], ...
'RandXShear', [0 45], ...
'RandYShear', [0 45], ...
'RandXTranslation', [-5 5], ...
'RandYTranslation', [-5 5], ...
'RandYReflection', true);
test_processor = imageDataAugmenter('RandScale', [0.8 1.2]);
% 导入数据
train = imageDatastore('train\', 'IncludeSubfolders',true, ...
'LabelSource','foldernames','ReadFcn',@imread);
train_preprocess = augmentedImageDatastore([255,255],train, 'DataAugmentation', train_processor);
test = imageDatastore('test\', 'IncludeSubfolders', true,...
'LabelSource', 'foldernames', 'ReadFcn', @imread);
test = augmentedImageDatastore([255,255],test, 'DataAugmentation', test_processor);
%imageDatastore函数创建一个对象来管理图像文件的集合。
构建神经网络
更改训练时期的数量和其他选项以修改训练神经网络。要知道,训练阶段越多,训练过程所需的时间就越长。基于数据集的大小、网络的大小和所选择的超参数,网络的训练时间可能会变化。
num_training_epochs = 20;
%基于上述值构建神经网络
layers=[imageInputLayer([255 255 3]);%指定输入数据的尺寸
convolution2dLayer([3 3],20); %将20个大小为3x3的过滤器应用于输入数据
reluLayer();%ReLU将负值设置为零并保持正值不变
maxPooling2dLayer([22]);%最大池化通过在每个2x2区域内选择最大值来减少空间维度
fullyConnectedLayer(3);%创建一个包含3个神经元的完全连接层
softmaxLayer();%将输出值转换为概率分布
classificationLayer();%根据概率分配分类
];
options=trainingOptions("adam",...%使用adam优化器作为优化算法
'InitialLearnRate',0.001,...%设置初始学习率
'SquaredGradientDecayFactor',0.99,...%将平方梯度项设置为在每个时间步长衰减1%(防止过度波动)
'MaxEpochs',num_training_epochs,...%设置分类器遍历整个数据集的最大次数
'MiniBatchSize',24,...%设置要拆分为24个较小批量的数据
'Verbose',true,...%显示培训期间的培训进度
'ValidationData',test, ...
'Plots',"training-progress");
[net,~] = trainNetwork(train_preprocess, layers, options);
测试神经网络
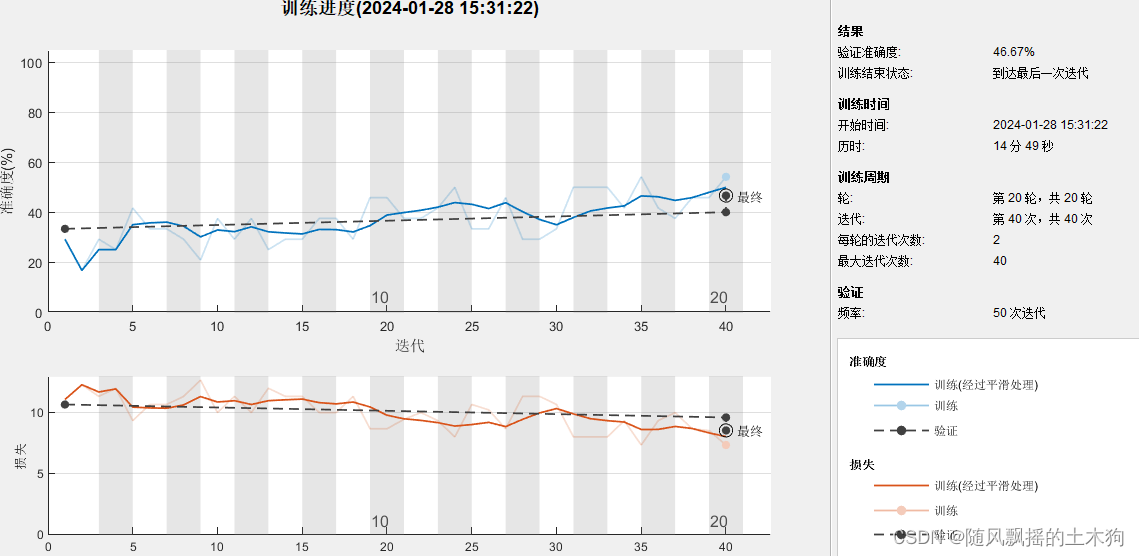
随机抽取测试钻头并预测其类型。验证的准确性以及个别测试表明存在错误分类。
%随机抓取图片
btype = ["PDC", "Roller Cone", "Spoon"]; % possible output values
bbtype = ["PDC", "Roller_Cone", "Spoon"]; % possible output values
rng('shuffle');
i=randi(3);
j=randi(5);
b = btype(i);
bb = bbtype(i);
im = strcat(lower(strrep(strcat(bb,'_',num2str(j),'.jpg'),'',"")));
test_image_filepath = fullfile('./test',b,im);
% 读取图片
image_fp = test_image_filepath;
ime = imread(image_fp); % load image
%修改图像以适应神经网络
im = double(imresize(ime,[255 255]));
%显示带有预测的图像
true_value = regexp(image_fp, "(PDC)|(Roller Cone)|(Spoon)", 'match');
figure('Position', [0,0,1000,1000])
imshow(ime);
%创建标题字符串并显示标题
label = "True value: " + string(true_value{1}) + "\n" + "Predicted: " + string(net.classify(im));
label = compose(label);
bit_title = title(label);
%调整标题位置
titlePos = get(bit_title, 'Position');
titlePos(2) = -0.1; % Adjust the title
set(bit_title, 'Position', titlePos, 'FontSize', 8);


二、案例二
1、背景介绍
裂纹分类,替换钻头分类案例研究中的照片,以建立分类器来区分有裂纹(正)或无裂纹(负)的混凝土照片。
数据集被分为两个(负和正)裂纹图像文件夹用于图像分类。每个train文件夹有500个图像,总共1000个图像,具有227 x 227像素的RGB通道。测试文件夹具有来自完整图像集的100个图像,总共200个测试图像。同样,我们将使用测试数据作为验证数据来训练更好的神经网络。

2、代码展示
% 数据处理
train_processor = imageDataAugmenter( ...
'RandScale', [.8 1.2], ...
'RandXReflection', true, ...
'RandRotation', [-45, 145], ...
'RandXShear', [0 45], ...
'RandYShear', [0 45], ...
'RandXTranslation', [-5 5], ...
'RandYTranslation', [-5 5], ...
'RandYReflection', true);
test_processor = imageDataAugmenter('RandScale', [0.8 1.2]);
% 导入数据
train = imageDatastore('train\', 'IncludeSubFolders', true, ...
'LabelSource','foldernames', 'ReadFcn',@imread);
train_preprocess_con = augmentedImageDatastore([128,128],train, 'DataAugmentation', train_processor);
test = imageDatastore('test\', 'IncludeSubfolders', true,...
'LabelSource', 'foldernames', 'ReadFcn', @imread);
test = augmentedImageDatastore([128,128],test, 'DataAugmentation', test_processor);
构建神经网络
更改训练时期的数量和其他选项以修改训练神经网络。要知道,训练时期和神经网络层越多,训练过程所需的时间就越长。基于数据集的大小、网络的大小和所选择的超参数,网络的训练时间可能会变化。
num_conv_layers = 2;
layer_size = 16;
num_training_epochs = 5;
基于上述值构建神经网络
%为图层创建单元
layers = cell((num_conv_layers+1)*3+4,1);
layers{1} = imageInputLayer([128 128 3]);
layers{2} = convolution2dLayer([3 3],layer_size);
layers{3} = reluLayer();
layers{4} = maxPooling2dLayer([2 2]);
%基于num_conv_layers添加额外的卷积层
for i = 1:num_conv_layers-1
layers{i*3 + 2} = convolution2dLayer([3 3],layer_size);
layers{i*3 + 3} = reluLayer();
layers{i*3 + 4} = maxPooling2dLayer([2 2]);
end
%降低维度
layers{end-5} = flattenLayer();
layers{end-4} = fullyConnectedLayer(layer_size);
layers{end-3} = reluLayer();
%添加最终致密层
layers{end - 2} = fullyConnectedLayer(2);
layers{end - 1} = softmaxLayer();
layers{end} = classificationLayer();
%将单元格转换为常规数组
layers = [layers{:}];
options = trainingOptions("adam", ...
SquaredGradientDecayFactor=0.99, ...
InitialLearnRate=0.001, ...
MaxEpochs=num_training_epochs, ...
MiniBatchSize=32, ...
Verbose=true,...
Plots="training-progress",...
ValidationData=test ...
);
训练神经网络
(预计时间:5分钟)
[net,info] = trainNetwork(train_preprocess_con, layers, options);
测试神经网络
获取随机测试图像并预测类型。
btype = ["Positive", "Negative"]; % possible output values
rng('shuffle');
i=randi(2);
j=randi([19901,20000]);
b = btype(i);
im = strcat(lower(strrep(strcat(num2str(j),'.jpg'),'',"")));
test_image_filepath = fullfile('./test',b,im);
%显示图像
image_fp = test_image_filepath;
ime = imread(image_fp); % load image
%为神经网络修改图像
im = double(imresize(ime,[128 128]));
%显示带有预测的图像
true_value = regexp(image_fp, "(Positive)|(Negative)", 'match');
figure('Position', [0,0,1000,1000])
imshow(ime);
%创建标题字符串并显示标题
label = "True value: " + string(true_value{1}) + "\n" + "Predicted: " + string(net.classify(im));
label = compose(label);
crack_title = title(label);
%调整标题位置
titlePos = get(crack_title, 'Position');
titlePos(2) = -0.1; % Adjust the title
set(crack_title, 'Position', titlePos, 'FontSize', 8);
验证的准确性以及个体测试表明存在许多错误分类。

三、总结分析
以下是一些可以提高此应用程序准确性的内容:
1、扩充数据集!这是最重要的一点,机器学习通常需要许多照片来代表分类器所看到的内容。在这一点上,没有足够的照片让模型学习每一种类型。
2、背景干扰。此集合中的大多数图像都已删除背景。为了训练分类器来识别字段中的类型,需要更多具有真实背景的照片。还可以添加合成背景。
3、超参数优化。为了制作最佳模型,必须选择最佳参数以最大限度地提高精度(超参数优化)。超参数可以通过控制变量进行调整,
四、代码获取
1.阅读首页置顶文章
2.关注CSDN
3.根据自动回复消息,回复“95期”以及相应指令,即可获取对应下载方式。