写在开头
哈喽大家好,在高铁上码字的感觉是真不爽啊,小桌板又拥挤,旁边的小朋友也比较的吵闹,影响思绪,但这丝毫不影响咱学习的劲头!哈哈哈,在这喧哗的车厢中,思考着这样的一个问题,Java中的对象是如何在各个方法,或者网络中流转的呢?
通过这个问题便引出了我们今天的主人公:序列化与反序列化!
序列化:所谓的序列化就是将Java对象或数据结构转为字节序列的过程,以便于存储到数据库、内存、文件系统或者网络传输。
反序列化:而反序列化就是序列化的逆向操作将字节流转为Java对象的过程。

序列化的基本实现(JDK)
这样一看序列化是不是非常有用?毋容置疑,这是一个无形中都会用到的知识点!那么想要在Java中实现序列化该如何做呢?继续往下看。
其实只要做到2点,就可以实现基本的序列化功能:序列流(ObjectInputStream 和 ObjectOutputStream)、实现 Serializable 接口(一个标识型接口,没有具体的方法,仅是一种通知,告诉JVM这个对象需要序列化)

【示例代码】
/**
* 测试序列化,反序列化
* @author javabuild
*/
public class TestSerializable implements Serializable {
private static final long serialVersionUID = 5887391604554532906L;
private int id;
private String name;
public TestSerializable(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "TestSerializable [id=" + id + ", name=" + name + "]";
}
@SuppressWarnings("resource")
public static void main(String[] args) throws IOException, ClassNotFoundException {
//序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("TestSerializable.obj"));
oos.writeObject("测试序列化");
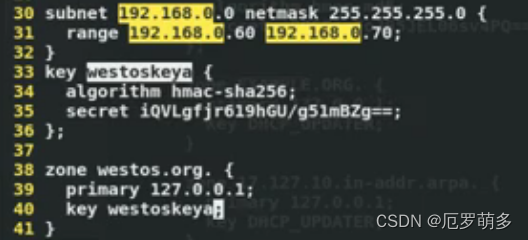
oos.writeObject(618);
TestSerializable test = new TestSerializable(1, "JavaBuild");
oos.writeObject(test);
//反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("TestSerializable.obj"));
System.out.println((String)ois.readObject());
System.out.println((Integer)ois.readObject());
System.out.println((TestSerializable)ois.readObject());
}
}
输出:
测试序列化
618
TestSerializable [id=1, name=JavaBuild]
这种实现方式是JDK自带的,方便好用,易于实现,代码逻辑不复杂,但它有着诸多的致命缺陷,导致很多大厂不会使用这种方式。
1、不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了。
2、性能差:相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
3、存在安全问题:序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。
序列化的其他实现方式(Kryo)
除了JDK自带的实现方式,国内外的大厂们推出过不好的开源且好用的序列化协议,比如Hessian、Kryo、Protobuf、ProtoStuff。
Hessian
一个轻量级的,自定义描述的二进制 RPC 协议。Hessian 是一个比较老的序列化实现了,并且同样也是跨语言的。Dubbo2.x 默认启用的序列化方式是 Hessian2 ,但是,Dubbo 对 Hessian2 进行了修改,不过大体结构差别不大。
Protobuf
自于 Google,性能优秀,支持多种语言,同时还是跨平台的。就是在使用中过于繁琐,因为你需要自己定义 IDL 文件和生成对应的序列化代码。这样虽然不灵活,但是,另一方面导致 protobuf 没有序列化漏洞的风险。不过后续谷歌推出了升级版,进行了很多缺陷的优化,诞生了ProtoStuff。
Kryo
目前使用最广泛,好评诸多的就是具有高性能、高效率和易于使用和扩展等特点的Kryo, 目前像Twitter、Groupon、Yahoo 以及多个著名开源项目(如 Hive、Storm)中都在使用这款序列化工具。
【示例代码】
1、引入相应的pom依赖库
<!-- 引入 Kryo 序列化工具 -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.4.0</version>
</dependency>
2、通过调用方法,通过二进制实现序列化与反序列化
public class KryoDemo {
public static void main(String[] args) throws FileNotFoundException {
Kryo kryo = new Kryo();
kryo.register(KryoParam.class);
KryoParam object = new KryoParam("JavaBuild", 123);
Output output = new Output(new FileOutputStream("logs/kryo.bin"));
kryo.writeObject(output, object);
output.close();
Input input = new Input(new FileInputStream("logs/kryo.bin"));
KryoParam object2 = kryo.readObject(input, KryoParam.class);
System.out.println(object2);
input.close();
}
}
class KryoParam {
private String name;
private int age;
public KryoParam() {
}
public KryoParam(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "KryoParam{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
序列化的细节知识点!
1、一般实现序列化接口后,还会有个serialVersionUID,它有什么作用?
答:SerialVersionUid 是为了序列化对象版本控制,告诉 JVM 各版本反序列化时是否兼容
如果在新版本中这个值修改了,新版本就不兼容旧版本,反序列化时会抛出InvalidClassException异常
仅增加了一个属性,希望向下兼容,老版本的数据都保留,就不用修改 删除了一个属性,或更改了类的继承关系,就不能不兼容旧数据,这时应该手动更新
SerialVersionUid
2、如果有些字段不想进行序列化怎么办?
答:对于不想进行序列化的变量,可以使用 transient 关键字修饰。transient
关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。