背景
目前查询框架使用的是trino,但是trino也有其局限性,需要准备一个备用的查询框架。考虑使用spark,spark operator也已经部署到k8s,现在需要定向提交spark sql到k8s的sparkoperator上,使用k8s资源执行sql。
对比
查询了java调用k8s的框架,有两个:fabric8io/kubernetes-client和kubernetes-client/java,fabric8io/kubernetes-client:始于2015年,用户很多,社区活跃。Fabric8项目的愿景是成为运行在Kubernetes之上的云原生微服务的PaaS平台。Fabric8 Kubernetes客户端在Fabric8生态系统中发挥了关键作用,因为它是Kubernetes REST API的抽象
kubernetes-client/java:官方的Kubernetes Java客户端是由Brendan Burns(他也是Kubernetes的创始人)和其他几个用于其他语言(如PERL、Javascript、Python等)的客户端于2017年底启动的。所有客户端似乎都是从一个通用的OpenAPI生成器脚本生成的:kubernetes-client/gen和Java客户端也是以相同的方式生成的。因此,它的用法与使用该脚本生成的其他客户端相似。
具体可以参考下面这篇文章
https://itnext.io/difference-between-fabric8-and-official-kubernetes-java-client-3e0a994fd4af![]() https://itnext.io/difference-between-fabric8-and-official-kubernetes-java-client-3e0a994fd4af
https://itnext.io/difference-between-fabric8-and-official-kubernetes-java-client-3e0a994fd4af
最终我选择了fabric8io,因为我们需要使用k8s的自定义资源sparkApplication,对于自定义资源,kubernetes-client/java需要创建各个k8s对象的pojo,比较麻烦。而fabric8io/kubernetes-client支持两种方式,一种和前者一样,创建pojo,还有一种方式使用GenericKubernetesResource动态创建并使用自定义资源,为了简便,选择使用fabric8io。
Spark Operator镜像及部署
spark operator的部署不再介绍,参考我前面的博客文章。
这里提一下,我在重新使用spark operator的时候,发现原来官方的google的spark operator镜像已经不能拉取了,貌似是google发现它的两个镜像存在漏洞,所以关闭了开源镜像。重新寻找了类似的镜像,发现了有openlake的spark镜像。拉取spark和spark operator镜像
https://hub.docker.com/u/openlake


程序调用架构

一:主程序(Main App)
编写主程序,即调用spark的主要代码。将下面的程序打包成jar,比如我的zyspark-0.0.1-SNAPSHOT.jar
import java.io.File;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.s3a.S3AFileSystem;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
public class SparkDemo {
public static void main(String[] args) throws Exception{
sparkQueryForFhc();
}
public static void sparkQueryForFhc() throws Exception{
System.out.println("=========================1");
String warehouseLocation = new File("spark-warehouse").getAbsolutePath();
System.out.println("===========================2");
String metastoreUri = "thrift://10.40.8.200:5000";
SparkConf sparkConf = new SparkConf();
sparkConf.set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem");
sparkConf.set("fs.s3a.access.key", "apPeWWr5KpXkzEW2jNKW");
sparkConf.set("spark.hadoop.fs.s3a.path.style.access", "true");
sparkConf.set("spark.hadoop.fs.s3a.connection.ssl.enabled", "true");
sparkConf.set("fs.s3a.secret.key", "cRt3inWAhDYtuzsDnKGLGg9EJSbJ083ekuW7PejM");
sparkConf.set("fs.s3a.endpoint", "wuxdimiov001.seagate.com:9000"); // 替换为实际的 S3 存储的地址
sparkConf.set("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem");
sparkConf.set("spark.sql.metastore.uris", metastoreUri);
sparkConf.set("spark.sql.warehouse.dir", warehouseLocation);
sparkConf.set("spark.sql.catalogImplementation", "hive");
sparkConf.set("hive.metastore.uris", metastoreUri);
//Class.forName("org.apache.hadoop.fs.s3a.S3AFileSystem");
long zhenyang2 = System.currentTimeMillis();
SparkSession sparkSession = SparkSession.builder()
.appName("Fhc Spark Query")
.config(sparkConf)
.enableHiveSupport()
.getOrCreate();
System.out.println("sparkSession create cost:"+(System.currentTimeMillis()-zhenyang2));
System.out.println("==============================3");
// 获取 SparkConf 对象
String exesql = sparkSession.sparkContext().getConf().get("spark.query.sql");
System.out.println("==============================3.1:"+exesql);
System.out.println("Hive Metastore URI: " + sparkConf.get("spark.sql.metastore.uris"));
System.out.println("Hive Warehouse Directory: " + sparkConf.get("spark.sql.warehouse.dir"));
System.out.println("SHOW DATABASES==============================3.1:"+exesql);
sparkSession.sql("SHOW DATABASES").show();
long zhenyang3 = System.currentTimeMillis();
Dataset<Row> sqlDF = sparkSession.sql(exesql);
System.out.println("sparkSession sql:"+(System.currentTimeMillis()-zhenyang3));
System.out.println("======================4");
System.out.println("===========sqlDF count===========:"+sqlDF.count());
sqlDF.show();
long zhenyang5 = System.currentTimeMillis();
List<Row> jaList= sqlDF.javaRDD().collect();
System.out.println("rdd collect cost:"+(System.currentTimeMillis()-zhenyang5));
System.out.println("jaList list:"+jaList.size());
List<TaskListModel> list = new ArrayList<TaskListModel>();
long zhenyang4 = System.currentTimeMillis();
jaList.stream().forEachOrdered(result -> {
System.out.println("serial_num is :"+result.getString(1));
});
System.out.println("SparkDemo foreach cost:"+(System.currentTimeMillis()-zhenyang4));
System.out.println("=========================5");
sparkSession.close();
}
}二:调用k8s程序(Spark App)
- 首先保证spark operator驱动程序已经发布在k8s集群
- 创建一个springboot程序,开放restful接口,接收传入的参数,比如spark的driver和executor参数,cpu,内存,instance个数等,及传入的需要运行的sql。
- 组织yaml内容,使用fabric8io将yaml提交到k8s执行
maven导入fabric8io包
<dependency>
<groupId>io.fabric8</groupId>
<artifactId>kubernetes-client</artifactId>
<version>6.1.1</version> <!-- 替换为实际版本 -->
</dependency>代码
注:因为sparkapplication是在k8s的自定义资源,应使用CustomResourceDefinitionContext来加载sparkapplication程序,提交到k8s的核心代码在submitSparkApplicationFabi2方法。
import java.io.File;
import java.io.FileReader;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Map;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
import io.fabric8.kubernetes.api.model.GenericKubernetesResource;
import io.fabric8.kubernetes.client.*;
import io.fabric8.kubernetes.client.dsl.base.CustomResourceDefinitionContext;
import io.fabric8.kubernetes.client.utils.Serialization;
import io.kubernetes.client.openapi.ApiClient;
import io.kubernetes.client.openapi.Configuration;
import io.kubernetes.client.openapi.apis.CustomObjectsApi;
import io.kubernetes.client.util.ClientBuilder;
import io.kubernetes.client.util.KubeConfig;
import io.kubernetes.client.util.Yaml;
@RestController
public class SparkSqlController {
@GetMapping(value = "/test")
public String test() {
System.out.println("test()");
return "Spring Boot SparkSqlController:Hello World";
}
@PostMapping(value = "/submitSparkSql",consumes="application/json;charset=utf-8")
public String executeSparkSql(@RequestBody Object message1) throws Exception {
String errorInf = "";
@SuppressWarnings("unchecked")
Map<String,Object> message = (Map<String,Object>)message1;
System.out.println(message);
String taskName = String.valueOf(message.get("taskName"));
String sparkImage = String.valueOf(message.get("sparkImage"));
String mainClass = String.valueOf(message.get("mainClass"));
String sparkJarFile = String.valueOf(message.get("sparkJarFile"));
String driverCpu = String.valueOf(message.get("driverCpu"));
String driverMemory = String.valueOf(message.get("driverMemory"));
String executorCpu = String.valueOf(message.get("executorCpu"));
String instance = String.valueOf(message.get("instance"));
String executorMemory = String.valueOf(message.get("executorMemory"));
String dynamicSQLQuery = String.valueOf(message.get("dynamicSQLQuery"));
// 构建 SparkApplication YAML 配置
String sparkApplicationYAML = buildSparkApplicationYAML(taskName, sparkImage, sparkJarFile, mainClass,
instance, driverCpu, driverMemory, executorCpu, executorMemory, dynamicSQLQuery);
System.out.println(sparkApplicationYAML);
// 提交 SparkApplication 到 Kubernetes
submitSparkApplicationFabi2(sparkApplicationYAML);
return null;
}
//组织yaml,根据动态传入的参数生成yaml
private static String buildSparkApplicationYAML(String taskName, String sparkImage, String sparkJarFile, String mainClass, String instance,
String driverCpu, String driverMemory, String executorCpu, String executorMemory, String dynamicSQLQuery) {
return String.format(
"apiVersion: \"sparkoperator.k8s.io/v1beta2\"\n" +
"kind: SparkApplication\n" +
"metadata:\n" +
" name: %s\n" +
" namespace: spark-app\n" +
"spec:\n" +
" type: Scala\n" +
" mode: cluster\n" +
" image: \"%s\"\n" +
" imagePullPolicy: Always\n" +
" imagePullSecrets: [\"harbor\"]\n" +
" mainClass: \"%s\"\n" +
" mainApplicationFile: \"%s\"\n" +
" sparkVersion: \"3.3.1\"\n" +
" restartPolicy:\n" +
" type: Never\n" +
" volumes:\n" +
" - name: nfs-spark-volume\n" +
" persistentVolumeClaim:\n" +
" claimName: sparkcode\n" +
" driver:\n" +
" cores: %s\n" +
" coreLimit: \"1200m\"\n" +
" memory: \"%s\"\n" +
" labels:\n" +
" version: 3.3.1\n" +
" serviceAccount: spark-svc-account\n" +
" volumeMounts:\n" +
" - name: nfs-spark-volume\n" +
" mountPath: \"/app/sparkcode\"\n" +
" env:\n" +
" - name: AWS_REGION\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: AWS_REGION\n" +
" - name: AWS_ACCESS_KEY_ID\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: AWS_ACCESS_KEY_ID\n" +
" - name: AWS_SECRET_ACCESS_KEY\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: AWS_SECRET_ACCESS_KEY\n" +
" - name: MINIO_ENDPOINT\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: MINIO_ENDPOINT\n" +
" - name: MINIO_HOST\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: MINIO_HOST\n" +
" - name: BUCKET_NAME\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: BUCKET_NAME\n" +
" executor:\n" +
" cores: %s\n" +
" instances: %s\n" +
" memory: \"%s\"\n" +
" labels:\n" +
" version: 3.3.1\n" +
" volumeMounts:\n" +
" - name: nfs-spark-volume\n" +
" mountPath: \"/app/sparkcode\"\n" +
" env:\n" +
" - name: AWS_REGION\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: AWS_REGION\n" +
" - name: AWS_ACCESS_KEY_ID\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: AWS_ACCESS_KEY_ID\n" +
" - name: AWS_SECRET_ACCESS_KEY\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: AWS_SECRET_ACCESS_KEY\n" +
" - name: MINIO_ENDPOINT\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: MINIO_ENDPOINT\n" +
" - name: MINIO_HOST\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: MINIO_HOST\n" +
" - name: BUCKET_NAME\n" +
" valueFrom:\n" +
" secretKeyRef:\n" +
" name: minio-secret\n" +
" key: BUCKET_NAME\n" +
" sparkConf:\n" +
" spark.query.sql: \"%s\"",
taskName,sparkImage,mainClass,sparkJarFile,driverCpu,driverMemory,executorCpu,instance,executorMemory,dynamicSQLQuery
);
}
private static void submitSparkApplicationFabi2(String sparkApplicationYAML) throws Exception{
try (KubernetesClient client = new KubernetesClientBuilder().build()) {//默认读取~/.kube/config的配置
CustomResourceDefinitionContext animalCrdContext = new CustomResourceDefinitionContext.Builder()
.withName("sparkapplications.sparkoperator.k8s.io")
.withGroup("sparkoperator.k8s.io")
.withKind("SparkApplication")
.withScope("Namespaced")
.withVersion("v1beta2")
.withPlural("sparkapplications")
.build();
GenericKubernetesResource cr3 = Serialization.unmarshal(sparkApplicationYAML, GenericKubernetesResource.class);
client.genericKubernetesResources(animalCrdContext).inNamespace("spark-app").resource(cr3).create();
System.out.println("over");
} catch (Exception e) {
e.printStackTrace();
}
}
}实际的生成的yaml
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: zy-spark
namespace: spark-app
spec:
type: Scala
mode: cluster
image: "10.38.199.203:1443/fhc/zy-spark:v0.1" //以openlake/spark镜像为基准的本地镜像
imagePullPolicy: Always
imagePullSecrets: ["harbor"]
mainClass: com.seagate.client.zyspark.SparkDemo //主程序入口
mainApplicationFile: "local:///app/sparkcode/zyspark-0.0.1-SNAPSHOT.jar" //主程序
sparkVersion: "3.3.1"
restartPolicy:
type: Never
volumes:
- name: nfs-spark-volume
persistentVolumeClaim:
claimName: sparkcode
driver:
cores: 1
coreLimit: "1200m"
memory: "2G"
labels:
version: 3.3.1
serviceAccount: spark-svc-account
volumeMounts:
- name: nfs-spark-volume
mountPath: "/app/sparkcode"
env: //以下为minio的访问参数
- name: AWS_REGION
valueFrom:
secretKeyRef:
name: minio-secret
key: AWS_REGION
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-secret
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: AWS_SECRET_ACCESS_KEY
- name: MINIO_ENDPOINT
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ENDPOINT
- name: MINIO_HOST
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_HOST
- name: BUCKET_NAME
valueFrom:
secretKeyRef:
name: minio-secret
key: BUCKET_NAME
executor:
cores: 1
instances: 10
memory: "1G"
labels:
version: 3.3.1
volumeMounts:
- name: nfs-spark-volume
mountPath: "/app/sparkcode"
env:
- name: AWS_REGION
valueFrom:
secretKeyRef:
name: minio-secret
key: AWS_REGION
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: minio-secret
key: AWS_ACCESS_KEY_ID
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: AWS_SECRET_ACCESS_KEY
- name: MINIO_ENDPOINT
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_ENDPOINT
- name: MINIO_HOST
valueFrom:
secretKeyRef:
name: minio-secret
key: MINIO_HOST
- name: BUCKET_NAME
valueFrom:
secretKeyRef:
name: minio-secret
key: BUCKET_NAME
sparkConf:
spark.query.sql: "select * from cimarronbp_n.p025_load_stat limit 10" //传入的sql三:传入参数,调用restful接口(Client)
public static void main(String[] args) throws Exception{
Map<String,Object> param = new HashMap<String, Object>();
param.put("taskName", "spark"+System.currentTimeMillis());
param.put("sparkImage", "10.38.199.203:1443/fhc/zy-spark:v0.1");
param.put("mainClass", "com.seagate.client.zyspark.SparkDemo");
param.put("sparkJarFile", "local:///app/sparkcode/zyspark-0.0.1-SNAPSHOT.jar");
param.put("driverCpu", "1");
param.put("driverMemory", "1G");
param.put("executorCpu", "1");
param.put("instance", "5");
param.put("executorMemory", "2G");
param.put("dynamicSQLQuery", "select * from cimarronbp_n.p025_load_stat limit 10");
callSparkSqk(JSONObject.toJSON(param));
}四:查看log
查看rancher的spark-app的namesapce下面,生成了driver和executor 的pod
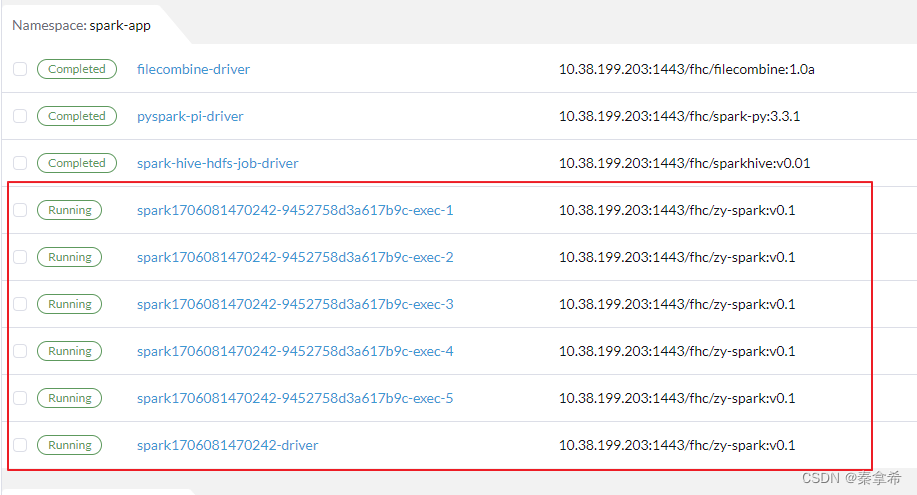
查看driver的log,生成了453个task
++ id -u
+ myuid=1000
++ id -g
+ mygid=1000
+ set +e
++ getent passwd 1000
+ uidentry=hive:x:1000:1000::/home/hive:/bin/bash
+ set -e
+ '[' -z hive:x:1000:1000::/home/hive:/bin/bash ']'
+ '[' -z /usr/local/openjdk-11 ']'
+ SPARK_CLASSPATH=':/opt/spark/jars/*'
+ env
+ sort -t_ -k4 -n
+ grep SPARK_JAVA_OPT_
+ sed 's/[^=]*=\(.*\)/\1/g'
+ readarray -t SPARK_EXECUTOR_JAVA_OPTS
+ '[' -n '' ']'
+ '[' -z ']'
+ '[' -z ']'
+ '[' -n '' ']'
+ '[' -z ']'
+ '[' -z x ']'
+ SPARK_CLASSPATH='/opt/spark/conf::/opt/spark/jars/*'
+ case "$1" in
+ shift 1
+ CMD=("$SPARK_HOME/bin/spark-submit" --conf "spark.driver.bindAddress=$SPARK_DRIVER_BIND_ADDRESS" --deploy-mode client "$@")
+ exec /usr/bin/tini -s -- /opt/spark/bin/spark-submit --conf spark.driver.bindAddress=10.42.2.226 --deploy-mode client --properties-file /opt/spark/conf/spark.properties --class com.seagate.client.zyspark.SparkDemo local:///app/sparkcode/zyspark-0.0.1-SNAPSHOT.jar
24/01/24 07:31:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
=========================1
===========================2
24/01/24 07:31:21 INFO HiveConf: Found configuration file null
24/01/24 07:31:22 INFO SparkContext: Running Spark version 3.3.2
24/01/24 07:31:22 INFO ResourceUtils: ==============================================================
24/01/24 07:31:22 INFO ResourceUtils: No custom resources configured for spark.driver.
24/01/24 07:31:22 INFO ResourceUtils: ==============================================================
24/01/24 07:31:22 INFO SparkContext: Submitted application: spark1706081470242
24/01/24 07:31:22 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 2048, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
24/01/24 07:31:22 INFO ResourceProfile: Limiting resource is cpus at 1 tasks per executor
24/01/24 07:31:22 INFO ResourceProfileManager: Added ResourceProfile id: 0
24/01/24 07:31:22 INFO SecurityManager: Changing view acls to: hive,root
24/01/24 07:31:22 INFO SecurityManager: Changing modify acls to: hive,root
24/01/24 07:31:22 INFO SecurityManager: Changing view acls groups to:
24/01/24 07:31:22 INFO SecurityManager: Changing modify acls groups to:
24/01/24 07:31:22 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hive, root); groups with view permissions: Set(); users with modify permissions: Set(hive, root); groups with modify permissions: Set()
24/01/24 07:31:22 INFO Utils: Successfully started service 'sparkDriver' on port 7078.
24/01/24 07:31:22 INFO SparkEnv: Registering MapOutputTracker
24/01/24 07:31:22 INFO SparkEnv: Registering BlockManagerMaster
24/01/24 07:31:23 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
24/01/24 07:31:23 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
24/01/24 07:31:23 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
24/01/24 07:31:23 INFO DiskBlockManager: Created local directory at /var/data/spark-f47fd19b-5ec5-4ed4-9bb8-d43710f560da/blockmgr-823ae0ab-d2a2-4448-a920-2c80674a13c4
24/01/24 07:31:23 INFO MemoryStore: MemoryStore started with capacity 413.9 MiB
24/01/24 07:31:23 INFO SparkEnv: Registering OutputCommitCoordinator
24/01/24 07:31:23 INFO Utils: Successfully started service 'SparkUI' on port 4040.
24/01/24 07:31:23 INFO SparkContext: Added JAR local:///app/sparkcode/zyspark-0.0.1-SNAPSHOT.jar at file:/app/sparkcode/zyspark-0.0.1-SNAPSHOT.jar with timestamp 1706081482116
24/01/24 07:31:23 INFO SparkContext: The JAR local:///app/sparkcode/zyspark-0.0.1-SNAPSHOT.jar at file:/app/sparkcode/zyspark-0.0.1-SNAPSHOT.jar has been added already. Overwriting of added jar is not supported in the current version.
24/01/24 07:31:23 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using current context from users K8S config file
24/01/24 07:31:25 INFO ExecutorPodsAllocator: Going to request 5 executors from Kubernetes for ResourceProfile Id: 0, target: 5, known: 0, sharedSlotFromPendingPods: 2147483647.
24/01/24 07:31:25 INFO BasicExecutorFeatureStep: Decommissioning not enabled, skipping shutdown script
24/01/24 07:31:26 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 7079.
24/01/24 07:31:26 INFO NettyBlockTransferService: Server created on spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:7079
24/01/24 07:31:26 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
24/01/24 07:31:26 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc, 7079, None)
24/01/24 07:31:26 INFO BlockManagerMasterEndpoint: Registering block manager spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:7079 with 413.9 MiB RAM, BlockManagerId(driver, spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc, 7079, None)
24/01/24 07:31:26 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc, 7079, None)
24/01/24 07:31:26 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc, 7079, None)
24/01/24 07:31:26 INFO BasicExecutorFeatureStep: Decommissioning not enabled, skipping shutdown script
24/01/24 07:31:26 INFO BasicExecutorFeatureStep: Decommissioning not enabled, skipping shutdown script
24/01/24 07:31:26 INFO BasicExecutorFeatureStep: Decommissioning not enabled, skipping shutdown script
24/01/24 07:31:26 INFO BasicExecutorFeatureStep: Decommissioning not enabled, skipping shutdown script
24/01/24 07:31:30 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.42.4.3:50280) with ID 3, ResourceProfileId 0
24/01/24 07:31:30 INFO BlockManagerMasterEndpoint: Registering block manager 10.42.4.3:38355 with 1048.8 MiB RAM, BlockManagerId(3, 10.42.4.3, 38355, None)
24/01/24 07:31:30 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.42.3.163:33768) with ID 2, ResourceProfileId 0
24/01/24 07:31:30 INFO BlockManagerMasterEndpoint: Registering block manager 10.42.3.163:40237 with 1048.8 MiB RAM, BlockManagerId(2, 10.42.3.163, 40237, None)
24/01/24 07:31:30 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.42.7.131:56864) with ID 5, ResourceProfileId 0
24/01/24 07:31:30 INFO BlockManagerMasterEndpoint: Registering block manager 10.42.7.131:45533 with 1048.8 MiB RAM, BlockManagerId(5, 10.42.7.131, 45533, None)
24/01/24 07:31:30 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.42.2.227:52014) with ID 4, ResourceProfileId 0
24/01/24 07:31:31 INFO KubernetesClusterSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
sparkSession create cost:9290
==============================3
==============================3.1:select * from cimarronbp_n.p025_load_stat limit 10
Hive Metastore URI: thrift://10.40.8.200:5000
Hive Warehouse Directory: /opt/spark/work-dir/spark-warehouse
SHOW DATABASES==============================3.1:select * from cimarronbp_n.p025_load_stat limit 10
24/01/24 07:31:31 INFO BlockManagerMasterEndpoint: Registering block manager 10.42.2.227:43975 with 1048.8 MiB RAM, BlockManagerId(4, 10.42.2.227, 43975, None)
24/01/24 07:31:31 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir.
24/01/24 07:31:31 INFO SharedState: Warehouse path is 'file:/opt/spark/work-dir/spark-warehouse'.
24/01/24 07:31:31 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.42.6.99:42804) with ID 1, ResourceProfileId 0
24/01/24 07:31:31 INFO BlockManagerMasterEndpoint: Registering block manager 10.42.6.99:36793 with 1048.8 MiB RAM, BlockManagerId(1, 10.42.6.99, 36793, None)
24/01/24 07:31:36 INFO HiveUtils: Initializing HiveMetastoreConnection version 2.3.9 using Spark classes.
24/01/24 07:31:36 INFO HiveClientImpl: Warehouse location for Hive client (version 2.3.9) is file:/opt/spark/work-dir/spark-warehouse
24/01/24 07:31:36 INFO metastore: Trying to connect to metastore with URI thrift://10.40.8.200:5000
24/01/24 07:31:36 INFO metastore: Opened a connection to metastore, current connections: 1
24/01/24 07:31:36 INFO metastore: Connected to metastore.
24/01/24 07:31:37 INFO CodeGenerator: Code generated in 329.422595 ms
24/01/24 07:31:37 INFO CodeGenerator: Code generated in 8.039488 ms
24/01/24 07:31:37 INFO CodeGenerator: Code generated in 8.313137 ms
+------------+
| namespace|
+------------+
| cimarronbp|
|cimarronbp_n|
| default|
| idat|
| mintest|
|mintestsmall|
| ods|
+------------+
sparkSession sql:396
======================4
24/01/24 07:31:38 INFO DataSourceStrategy: Pruning directories with:
24/01/24 07:31:39 INFO CodeGenerator: Code generated in 11.76912 ms
24/01/24 07:31:39 INFO SQLStdHiveAccessController: Created SQLStdHiveAccessController for session context : HiveAuthzSessionContext [sessionString=486be1dc-3907-49cb-ad05-f4200a382ae5, clientType=HIVECLI]
24/01/24 07:31:39 WARN SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
24/01/24 07:31:39 INFO metastore: Mestastore configuration hive.metastore.filter.hook changed from org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl to org.apache.hadoop.hive.ql.security.authorization.plugin.AuthorizationMetaStoreFilterHook
24/01/24 07:31:39 INFO metastore: Closed a connection to metastore, current connections: 0
24/01/24 07:31:39 INFO metastore: Trying to connect to metastore with URI thrift://10.40.8.200:5000
24/01/24 07:31:39 INFO metastore: Opened a connection to metastore, current connections: 1
24/01/24 07:31:39 INFO metastore: Connected to metastore.
24/01/24 07:31:39 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 215.8 KiB, free 413.7 MiB)
24/01/24 07:31:39 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 36.3 KiB, free 413.7 MiB)
24/01/24 07:31:39 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:7079 (size: 36.3 KiB, free: 413.9 MiB)
24/01/24 07:31:39 INFO SparkContext: Created broadcast 0 from
24/01/24 07:31:39 INFO metastore: Trying to connect to metastore with URI thrift://10.40.8.200:5000
24/01/24 07:31:39 INFO metastore: Opened a connection to metastore, current connections: 2
24/01/24 07:31:39 INFO metastore: Connected to metastore.
24/01/24 07:31:50 WARN MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties
24/01/24 07:31:50 INFO MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
24/01/24 07:31:58 INFO DAGScheduler: Registering RDD 1248 (count at SparkDemo.java:443) as input to shuffle 0
24/01/24 07:31:58 INFO DAGScheduler: Got map stage job 0 (count at SparkDemo.java:443) with 453 output partitions
24/01/24 07:31:58 INFO DAGScheduler: Final stage: ShuffleMapStage 0 (count at SparkDemo.java:443)
24/01/24 07:31:58 INFO DAGScheduler: Parents of final stage: List()
24/01/24 07:31:58 INFO DAGScheduler: Missing parents: List()
24/01/24 07:31:58 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[1248] at count at SparkDemo.java:443), which has no missing parents
24/01/24 07:31:59 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 416.1 KiB, free 413.3 MiB)
24/01/24 07:31:59 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 64.4 KiB, free 413.2 MiB)
24/01/24 07:31:59 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:7079 (size: 64.4 KiB, free: 413.8 MiB)
24/01/24 07:31:59 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1513
24/01/24 07:31:59 INFO DAGScheduler: Submitting 453 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[1248] at count at SparkDemo.java:443) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14))
24/01/24 07:31:59 INFO TaskSchedulerImpl: Adding task set 0.0 with 453 tasks resource profile 0
24/01/24 07:31:59 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (10.42.2.227, executor 4, partition 0, PROCESS_LOCAL, 4708 bytes) taskResourceAssignments Map()
24/01/24 07:31:59 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1) (10.42.6.99, executor 1, partition 1, PROCESS_LOCAL, 4710 bytes) taskResourceAssignments Map()
24/01/24 07:31:59 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2) (10.42.4.3, executor 3, partition 2, PROCESS_LOCAL, 4712 bytes) taskResourceAssignments Map()
24/01/24 07:31:59 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3) (10.42.7.131, executor 5, partition 3, PROCESS_LOCAL, 4712 bytes) taskResourceAssignments Map()
24/01/24 07:31:59 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4) (10.42.3.163, executor 2, partition 4, PROCESS_LOCAL, 4710 bytes) taskResourceAssignments Map()
24/01/24 07:31:59 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.42.7.131:45533 (size: 64.4 KiB, free: 1048.7 MiB)
24/01/24 07:31:59 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.42.3.163:40237 (size: 64.4 KiB, free: 1048.7 MiB)
24/01/24 07:31:59 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.42.2.227:43975 (size: 64.4 KiB, free: 1048.7 MiB)
24/01/24 07:31:59 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.42.4.3:38355 (size: 64.4 KiB, free: 1048.7 MiB)
24/01/24 07:31:59 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.42.6.99:36793 (size: 64.4 KiB, free: 1048.7 MiB)
24/01/24 07:31:59 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.42.4.3:38355 (size: 36.3 KiB, free: 1048.7 MiB)
24/01/24 07:32:00 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.42.7.131:45533 (size: 36.3 KiB, free: 1048.7 MiB)
24/01/24 07:32:00 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.42.2.227:43975 (size: 36.3 KiB, free: 1048.7 MiB)
24/01/24 07:32:00 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.42.3.163:40237 (size: 36.3 KiB, free: 1048.7 MiB)
24/01/24 07:32:00 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.42.6.99:36793 (size: 36.3 KiB, free: 1048.7 MiB)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5) (10.42.4.3, executor 3, partition 5, PROCESS_LOCAL, 4712 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 2932 ms on 10.42.4.3 (executor 3) (1/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6) (10.42.2.227, executor 4, partition 6, PROCESS_LOCAL, 4712 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2991 ms on 10.42.2.227 (executor 4) (2/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7) (10.42.3.163, executor 2, partition 7, PROCESS_LOCAL, 4710 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 3004 ms on 10.42.3.163 (executor 2) (3/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 8.0 in stage 0.0 (TID 8) (10.42.4.3, executor 3, partition 8, PROCESS_LOCAL, 4710 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 130 ms on 10.42.4.3 (executor 3) (4/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9) (10.42.7.131, executor 5, partition 9, PROCESS_LOCAL, 4708 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 3107 ms on 10.42.7.131 (executor 5) (5/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 10.0 in stage 0.0 (TID 10) (10.42.3.163, executor 2, partition 10, PROCESS_LOCAL, 4709 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 134 ms on 10.42.3.163 (executor 2) (6/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 11.0 in stage 0.0 (TID 11) (10.42.4.3, executor 3, partition 11, PROCESS_LOCAL, 4711 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 100 ms on 10.42.4.3 (executor 3) (7/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 12.0 in stage 0.0 (TID 12) (10.42.7.131, executor 5, partition 12, PROCESS_LOCAL, 4708 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 97 ms on 10.42.7.131 (executor 5) (8/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 13.0 in stage 0.0 (TID 13) (10.42.3.163, executor 2, partition 13, PROCESS_LOCAL, 4708 bytes) taskResourceAssignments Map()
24/01/24 07:32:02 INFO TaskSetManager: Finished task 10.0 in stage 0.0 (TID 10) in 87 ms on 10.42.3.163 (executor 2) (9/453)
24/01/24 07:32:02 INFO TaskSetManager: Starting task 14.0 in stage 0.0 (TID 14) (10.42.4.3, executor 3, partition 14, PROCESS_LOCAL, 4713 bytes) taskResourceAssignments Map()
...........
24/01/24 07:32:18 INFO DAGScheduler: Final stage: ResultStage 3 (show at SparkDemo.java:445)
24/01/24 07:32:18 INFO DAGScheduler: Parents of final stage: List()
24/01/24 07:32:18 INFO DAGScheduler: Missing parents: List()
24/01/24 07:32:18 INFO DAGScheduler: Submitting ResultStage 3 (MapPartitionsRDD[2499] at show at SparkDemo.java:445), which has no missing parents
24/01/24 07:32:18 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 565.9 KiB, free 413.1 MiB)
24/01/24 07:32:18 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 79.7 KiB, free 413.0 MiB)
24/01/24 07:32:18 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:7079 (size: 79.7 KiB, free: 413.8 MiB)
24/01/24 07:32:18 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1513
24/01/24 07:32:18 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 3 (MapPartitionsRDD[2499] at show at SparkDemo.java:445) (first 15 tasks are for partitions Vector(0))
24/01/24 07:32:18 INFO TaskSchedulerImpl: Adding task set 3.0 with 1 tasks resource profile 0
24/01/24 07:32:18 INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID 454) (10.42.3.163, executor 2, partition 0, PROCESS_LOCAL, 4722 bytes) taskResourceAssignments Map()
24/01/24 07:32:18 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 10.42.3.163:40237 (size: 79.7 KiB, free: 1048.7 MiB)
24/01/24 07:32:19 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 10.42.3.163:40237 (size: 36.4 KiB, free: 1048.7 MiB)
24/01/24 07:32:19 INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID 454) in 323 ms on 10.42.3.163 (executor 2) (1/1)
24/01/24 07:32:19 INFO TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
24/01/24 07:32:19 INFO DAGScheduler: ResultStage 3 (show at SparkDemo.java:445) finished in 0.346 s
24/01/24 07:32:19 INFO DAGScheduler: Job 2 is finished. Cancelling potential speculative or zombie tasks for this job
24/01/24 07:32:19 INFO TaskSchedulerImpl: Killing all running tasks in stage 3: Stage finished
24/01/24 07:32:19 INFO DAGScheduler: Job 2 finished: show at SparkDemo.java:445, took 0.362538 s
24/01/24 07:32:19 INFO CodeGenerator: Code generated in 23.175128 ms
+----------+---------+--------------+------+----------+---+--------------+---------+---------+-------------+-------------+----------+----------+------+---------+
|serial_num|trans_seq| state_name|spc_id|occurrence|seq|test_seq_event|stat_name|load_time|load_peak_cur|load_peak_vel|vcm_offset|event_date|family|operation|
+----------+---------+--------------+------+----------+---+--------------+---------+---------+-------------+-------------+----------+----------+------+---------+
| WP01C6DB| 53|LUL_TEST25_SCS| 30101| 1| 17| 1| MAX| 156.5| -511.4| -3.2| 65535.0| 20231202| 3AK| CRT2|
| WP01C6DB| 53|LUL_TEST25_SCS| 30101| 1| 17| 1| MIN| 156.5| -511.4| -3.2| 65535.0| 20231202| 3AK| CRT2|
| WP01C6DB| 53|LUL_TEST25_SCS| 30101| 1| 17| 1| AVG| 156.5| -511.4| -3.2| 65535.0| 20231202| 3AK| CRT2|
| WP01C6DB| 53|LUL_TEST25_SCS| 30101| 1| 17| 1| STDEV| 0.0| 0.0| 0.0| 65535.0| 20231202| 3AK| CRT2|
| WP01C6DB| 53|LUL_TEST25_SCS| 30101| 1| 17| 1| ERRCNT| 0.0| 0.0| 0.0| 0.0| 20231202| 3AK| CRT2|
| WP0187VM| 51|LUL_TEST25_SCS| 30101| 1| 17| 1| MAX| 152.2| -512.9| -3.1| 65535.0| 20231202| 3AK| CRT2|
| WP0187VM| 51|LUL_TEST25_SCS| 30101| 1| 17| 1| MIN| 152.2| -512.9| -3.1| 65535.0| 20231202| 3AK| CRT2|
| WP0187VM| 51|LUL_TEST25_SCS| 30101| 1| 17| 1| AVG| 152.2| -512.9| -3.1| 65535.0| 20231202| 3AK| CRT2|
| WP0187VM| 51|LUL_TEST25_SCS| 30101| 1| 17| 1| STDEV| 0.0| 0.0| 0.0| 65535.0| 20231202| 3AK| CRT2|
| WP0187VM| 51|LUL_TEST25_SCS| 30101| 1| 17| 1| ERRCNT| 0.0| 0.0| 0.0| 0.0| 20231202| 3AK| CRT2|
+----------+---------+--------------+------+----------+---+--------------+---------+---------+-------------+-------------+----------+----------+------+---------+
24/01/24 07:32:19 INFO DataSourceStrategy: Pruning directories with:
24/01/24 07:32:19 INFO CodeGenerator: Code generated in 71.006193 ms
24/01/24 07:32:19 INFO MemoryStore: Block broadcast_5 stored as values in memory (estimated size 216.0 KiB, free 412.8 MiB)
24/01/24 07:32:19 INFO MemoryStore: Block broadcast_5_piece0 stored as bytes in memory (estimated size 36.4 KiB, free 412.8 MiB)
24/01/24 07:32:19 INFO BlockManagerInfo: Added broadcast_5_piece0 in memory on spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:7079 (size: 36.4 KiB, free: 413.8 MiB)
24/01/24 07:32:19 INFO SparkContext: Created broadcast 5 from
24/01/24 07:32:22 INFO BlockManagerInfo: Removed broadcast_4_piece0 on spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:7079 in memory (size: 79.7 KiB, free: 413.9 MiB)
24/01/24 07:32:22 INFO BlockManagerInfo: Removed broadcast_4_piece0 on 10.42.3.163:40237 in memory (size: 79.7 KiB, free: 1048.8 MiB)
.................
24/01/24 07:32:32 INFO DAGScheduler: looking for newly runnable stages
24/01/24 07:32:32 INFO DAGScheduler: running: Set()
24/01/24 07:32:32 INFO DAGScheduler: waiting: Set()
24/01/24 07:32:32 INFO DAGScheduler: failed: Set()
24/01/24 07:32:32 INFO CodeGenerator: Code generated in 17.641789 ms
24/01/24 07:32:32 INFO SparkContext: Starting job: collect at SparkDemo.java:448
24/01/24 07:32:32 INFO DAGScheduler: Got job 4 (collect at SparkDemo.java:448) with 1 output partitions
24/01/24 07:32:32 INFO DAGScheduler: Final stage: ResultStage 6 (collect at SparkDemo.java:448)
24/01/24 07:32:32 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 5)
24/01/24 07:32:32 INFO DAGScheduler: Missing parents: List()
24/01/24 07:32:32 INFO DAGScheduler: Submitting ResultStage 6 (MapPartitionsRDD[3753] at javaRDD at SparkDemo.java:448), which has no missing parents
24/01/24 07:32:32 INFO MemoryStore: Block broadcast_7 stored as values in memory (estimated size 40.2 KiB, free 412.8 MiB)
24/01/24 07:32:32 INFO MemoryStore: Block broadcast_7_piece0 stored as bytes in memory (estimated size 17.0 KiB, free 412.7 MiB)
24/01/24 07:32:32 INFO BlockManagerInfo: Added broadcast_7_piece0 in memory on spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:7079 (size: 17.0 KiB, free: 413.8 MiB)
24/01/24 07:32:32 INFO SparkContext: Created broadcast 7 from broadcast at DAGScheduler.scala:1513
24/01/24 07:32:32 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 6 (MapPartitionsRDD[3753] at javaRDD at SparkDemo.java:448) (first 15 tasks are for partitions Vector(0))
24/01/24 07:32:32 INFO TaskSchedulerImpl: Adding task set 6.0 with 1 tasks resource profile 0
24/01/24 07:32:32 INFO TaskSetManager: Starting task 0.0 in stage 6.0 (TID 908) (10.42.7.131, executor 5, partition 0, NODE_LOCAL, 4472 bytes) taskResourceAssignments Map()
24/01/24 07:32:32 INFO BlockManagerInfo: Added broadcast_7_piece0 in memory on 10.42.7.131:45533 (size: 17.0 KiB, free: 1048.7 MiB)
24/01/24 07:32:32 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to 10.42.7.131:56864
24/01/24 07:32:33 INFO TaskSetManager: Finished task 0.0 in stage 6.0 (TID 908) in 1175 ms on 10.42.7.131 (executor 5) (1/1)
24/01/24 07:32:33 INFO TaskSchedulerImpl: Removed TaskSet 6.0, whose tasks have all completed, from pool
24/01/24 07:32:33 INFO DAGScheduler: ResultStage 6 (collect at SparkDemo.java:448) finished in 1.183 s
24/01/24 07:32:33 INFO DAGScheduler: Job 4 is finished. Cancelling potential speculative or zombie tasks for this job
24/01/24 07:32:33 INFO TaskSchedulerImpl: Killing all running tasks in stage 6: Stage finished
24/01/24 07:32:33 INFO DAGScheduler: Job 4 finished: collect at SparkDemo.java:448, took 1.191350 s
rdd collect cost:14796
jaList list:10
serial_num is :32
serial_num is :32
serial_num is :32
serial_num is :32
serial_num is :32
serial_num is :32
serial_num is :32
serial_num is :32
serial_num is :32
serial_num is :32
SparkDemo foreach cost:1
=========================5
24/01/24 07:32:34 INFO SparkUI: Stopped Spark web UI at http://spark1706081470242-7219f68d3a6157ef-driver-svc.spark-app.svc:4040
24/01/24 07:32:34 INFO KubernetesClusterSchedulerBackend: Shutting down all executors
24/01/24 07:32:34 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Asking each executor to shut down
24/01/24 07:32:34 WARN ExecutorPodsWatchSnapshotSource: Kubernetes client has been closed.
24/01/24 07:32:34 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
24/01/24 07:32:34 INFO MemoryStore: MemoryStore cleared
24/01/24 07:32:34 INFO BlockManager: BlockManager stopped
24/01/24 07:32:34 INFO BlockManagerMaster: BlockManagerMaster stopped
24/01/24 07:32:34 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
24/01/24 07:32:34 INFO SparkContext: Successfully stopped SparkContext