💡💡💡本文摘要:提出了一种基于YOLOV5框架的新型XM-YOLOViT雾天行人车辆实时检测算法,有效解决了密集目标干扰和雾霾遮挡问题,提高了复杂雾天环境下的检测效果。
1.XM-YOLOViT原理介绍
XM-YOLOViT框架图
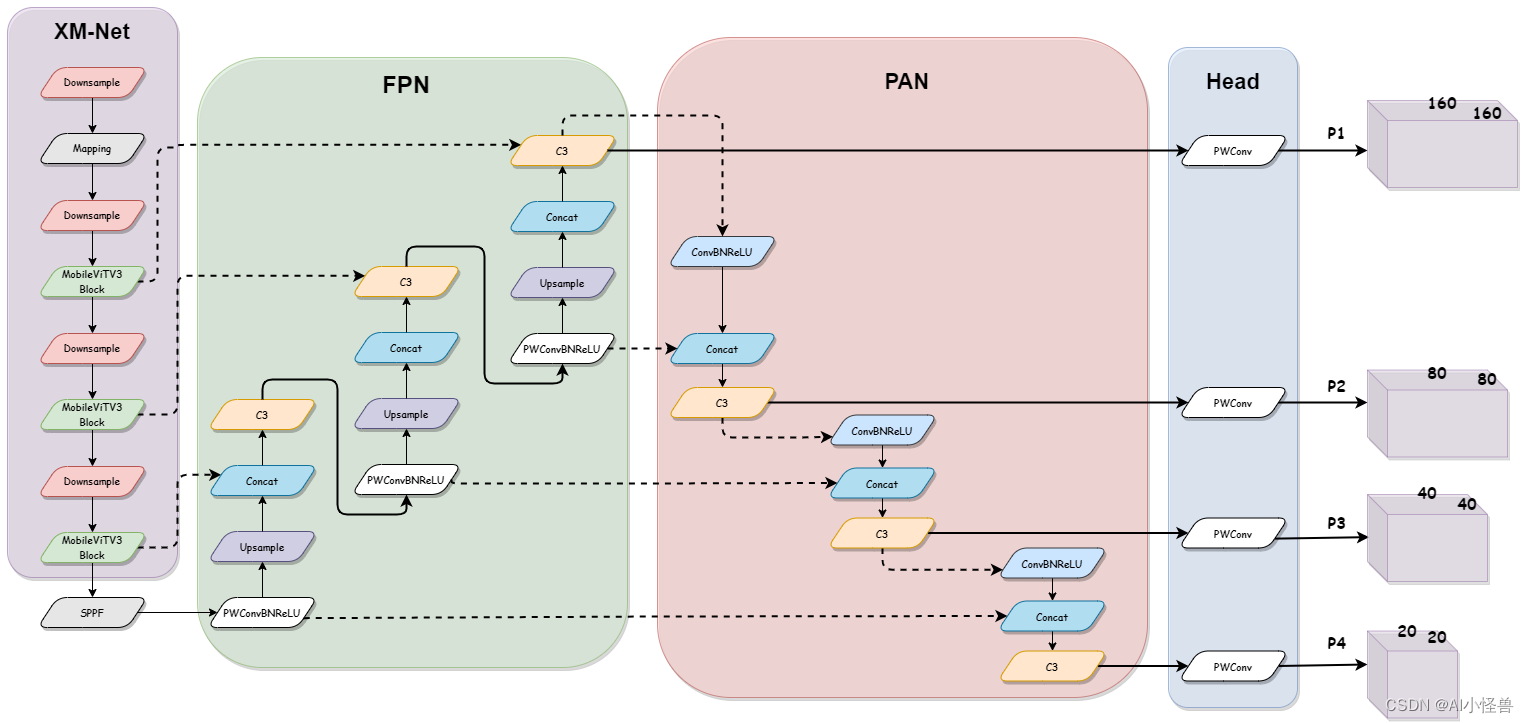
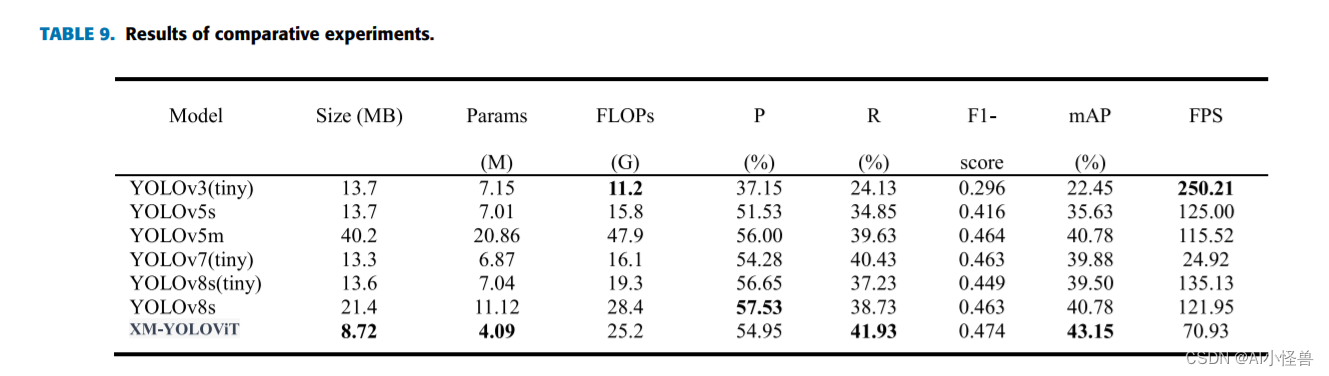
摘要:提出了一种基于YOLOV5框架的新型XM-YOLOViT雾天行人车辆实时检测算法,有效解决了密集目标干扰和雾霾遮挡问题,提高了复杂雾天环境下的检测效果。首先,引入倒残差块和MobileViTV3块构建XM-net特征提取网络;其次,采用EIOU作为位置损失函数,在颈部区域增加高分辨率检测层;在数据方面,基于大气散射模型和暗通道先验,设计了一种将图像从无雾空间映射到有雾空间的雾化方法。最后,分别在不同雾环境下的4个数据集上验证了算法的有效性。实验结果表明,XM-YOLOViT模型的准确率、召回率和mAP分别为54.95%、41.93%和43.15%,F1-Score为0.474,分别提高了3.42%、7.08%、7.52%和13.94%,模型参数降低41.7%至4.09M, FLOPs为25.2G,检测速度为70.93 FPS。XM-YOLOViT模型比先进的YOLO探测器性能更好,F1-Score和mAP分别比YOLOv7-tiny提高了5.57%和3.65%,比YOLOv8s分别提高了2.38%和2.37%。因此,本文提出的XM-YOLOViT算法具有较高的检测精度和极轻的结构,可以有效提高无人机在雾天,特别是对极小目标的检测任务的效率和质量。

1.1 对应yaml文件
nc: 3 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [ 3,4, 6,5, 4,8 ] # 4
- [ 7,12, 11,7, 11,13 ] # 8
- [ 21,10, 13,21, 30,17 ] # 16
- [ 29,32, 48,42, 90,73 ] # 32
backbone:
[
# conv1
[-1, 1, ConvLayer, [16, 6, 2]], # 0 2
# layer1
[-1, 1, InvertedResidual, [32, 1, 4]], # 1 2
# layer2
[-1, 1, InvertedResidual, [64, 2, 4]], # 2 4
[-1, 2, InvertedResidual, [64, 1, 4]], # 3 4
# layer3
[-1, 1, InvertedResidual, [96, 2, 4]], # 4 8
[-1, 1, MobileViTBlock, [144, 288, 2, 0, 0, 0, 2, 2]], # 5 8
# layer4
[-1, 1, InvertedResidual, [128, 2, 4]], # 6 16
[-1, 1, MobileViTBlock, [192, 384, 4, 0, 0, 0, 2, 2]], # 7 16
# layer5
[-1, 1, InvertedResidual, [160, 2, 4]], # 8 32
[-1, 1, MobileViTBlock, [240, 480, 3, 0, 0, 0, 2, 2]], # 9 32
# SPPF
[ -1, 1, SPPF, [ 160, 5 ] ], # 10
]
head:
[[-1, 1, Conv, [128, 1, 1]], # 11
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 12
[[-1, 7], 1, Concat, [1]], # 13
[-1, 1, C3, [128, False]], # 14
[-1, 1, Conv, [96, 1, 1]], # 15
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 16
[[-1, 5], 1, Concat, [1]], # 17
[-1, 1, C3, [96, False]], # 18
[ -1, 1, Conv, [ 64, 1, 1 ] ], # 19
[ -1, 1, nn.Upsample, [ None, 2, 'nearest' ] ], # 20
[ [ -1, 3 ], 1, Concat, [ 1 ] ], # 21
[ -1, 1, C3, [64, False]], # 22
[ -1, 1, Conv, [ 64, 3, 2 ] ], # 23
[ [ -1, 19 ], 1, Concat, [ 1 ] ], # 24
[ -1, 1, C3, [96, False]], # 25
[-1, 1, Conv, [96, 3, 2]], # 26
[[-1, 15], 1, Concat, [1]], # 27
[-1, 1, C3, [128, False]], # 28
[-1, 1, Conv, [128, 3, 2]], # 29
[[-1, 11], 1, Concat, [1]], # 30
[-1, 1, C3, [160, False]], # 31
[[22, 25, 28, 31], 1, Detect, [nc, anchors]],
]1.2 实验结果
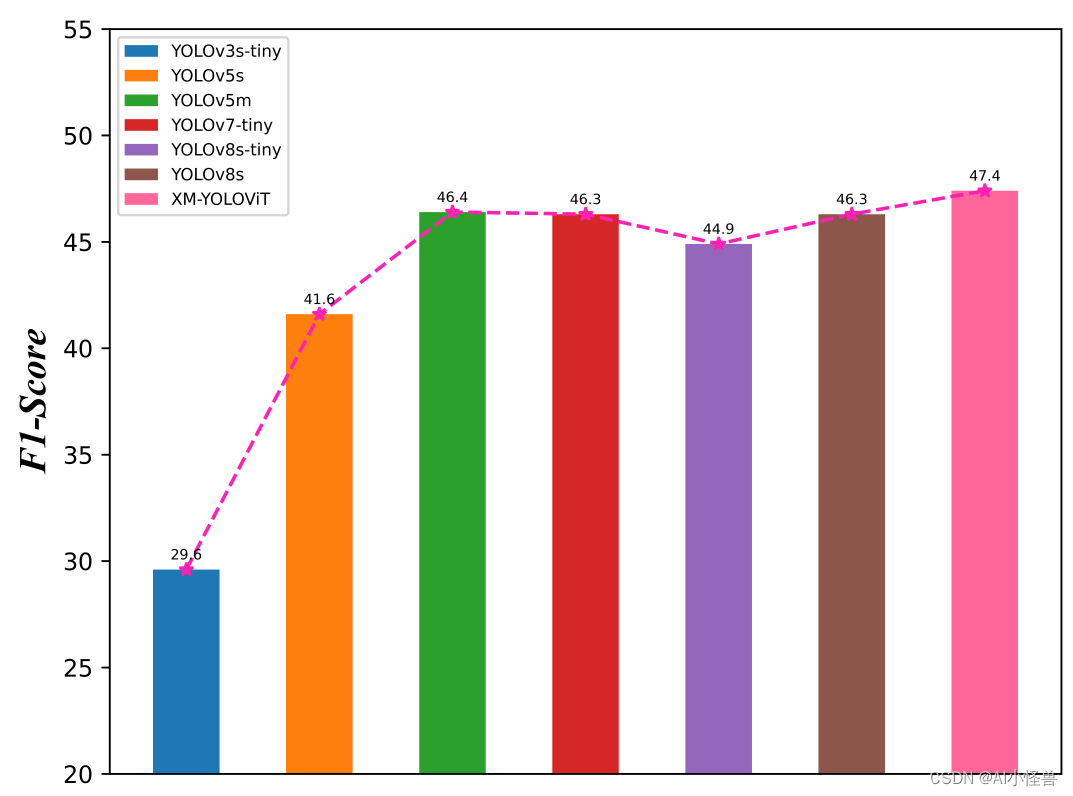
F1-score比较
mAP比较
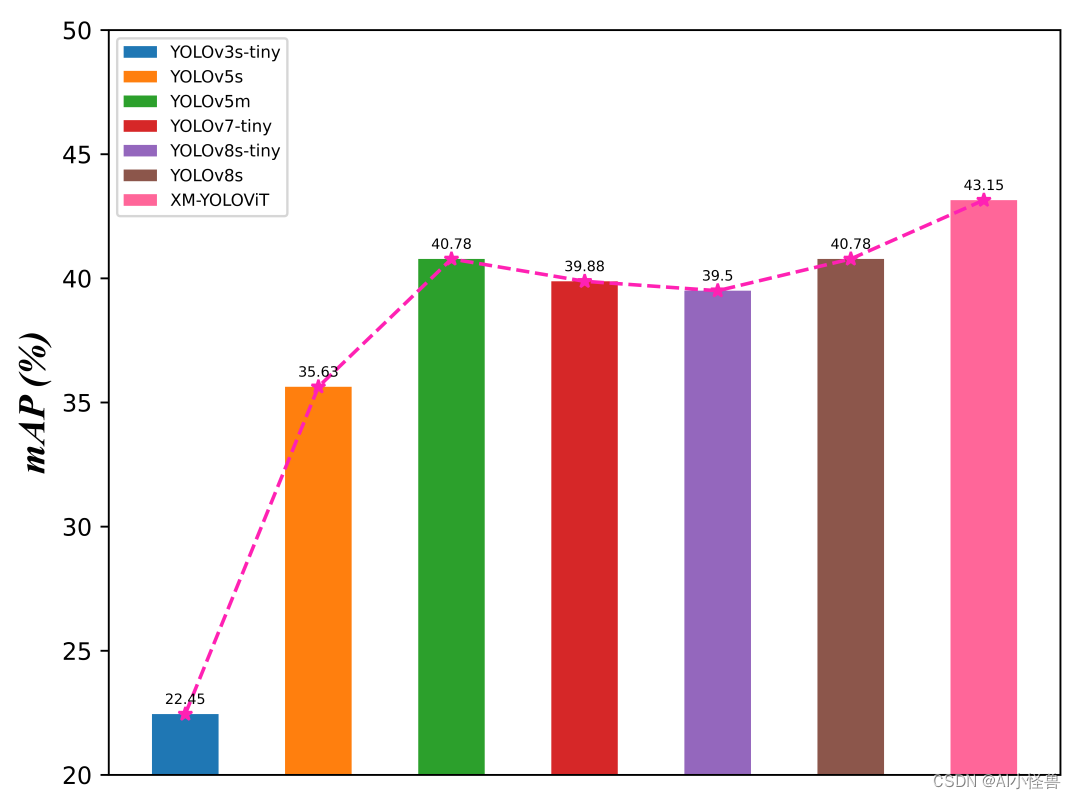
各个YOLO性能比较
预测结果对比
 1.3 核心代码
1.3 核心代码
'''----------------------MobileViT-------------------'''
def make_divisibles(
v: Union[float, int],
divisor: Optional[int] = 8,
min_value: Optional[Union[float, int]] = None,
) -> Union[float, int]:
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvLayer(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int, int]],
stride: Optional[Union[int, Tuple[int, int]]] = 1,
groups: Optional[int] = 1,
bias: Optional[bool] = False,
use_norm: Optional[bool] = True,
use_act: Optional[bool] = True,
) -> None:
super().__init__()
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
if isinstance(stride, int):
stride = (stride, stride)
assert isinstance(kernel_size, Tuple)
assert isinstance(stride, Tuple)
padding = (
int((kernel_size[0] - 1) / 2),
int((kernel_size[1] - 1) / 2),
)
block = nn.Sequential()
conv_layer = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
groups=groups,
padding=padding,
bias=bias
)
block.add_module(name="conv", module=conv_layer)
if use_norm:
norm_layer = nn.BatchNorm2d(num_features=out_channels, momentum=0.1)
block.add_module(name="norm", module=norm_layer)
if use_act:
act_layer = nn.SiLU()
block.add_module(name="act", module=act_layer)
self.block = block
def forward(self, x: Tensor) -> Tensor:
return self.block(x)
class InvertedResidual(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
stride: int,
expand_ratio: Union[int, float],
skip_connection: Optional[bool] = True,
) -> None:
assert stride in [1, 2]
hidden_dim = make_divisibles(int(round(in_channels * expand_ratio)), 8)
super().__init__()
block = nn.Sequential()
if expand_ratio != 1:
block.add_module(
name="exp_1x1",
module=ConvLayer(
in_channels=in_channels,
out_channels=hidden_dim,
kernel_size=1
),
)
block.add_module(
name="conv_3x3",
module=ConvLayer(
in_channels=hidden_dim,
out_channels=hidden_dim,
stride=stride,
kernel_size=3,
groups=hidden_dim
),
)
block.add_module(
name="red_1x1",
module=ConvLayer(
in_channels=hidden_dim,
out_channels=out_channels,
kernel_size=1,
use_act=False,
use_norm=True,
),
)
self.block = block
self.in_channels = in_channels
self.out_channels = out_channels
self.exp = expand_ratio
self.stride = stride
self.use_res_connect = (
self.stride == 1 and in_channels == out_channels and skip_connection
)
def forward(self, x: Tensor, *args, **kwargs) -> Tensor:
if self.use_res_connect:
return x + self.block(x)
else:
return self.block(x)
class SeparableSelfAttention(nn.Module):
def __init__(
self,
embed_dim: int,
attn_dropout: float = 0.0,
bias: bool = True,
*args,
**kwargs
) -> None:
super().__init__()
self.x2ikv = nn.Linear(embed_dim, 1 + 2 * embed_dim, bias=bias)
self.attn_dropout = nn.Dropout(p=attn_dropout)
self.out_linear = nn.Linear(embed_dim, embed_dim, bias=bias)
self.softmax = nn.Softmax(dim=-1)
self.embed_dim = embed_dim
def forward(self, x: Tensor) -> Tensor:
ikv = self.x2ikv(x)
i, k, v = ikv.split([1, self.embed_dim, self.embed_dim], dim=-1)
context_scores = self.softmax(i)
context_vector = torch.sum(context_scores * k, keepdim=True, dim=-2)
v = torch.relu(v)
context_vector = self.attn_dropout(context_vector)
attn = context_vector * v
y = self.out_linear(attn)
return y
class SSATransformerEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
ffn_latent_dim: int,
attn_dropout: Optional[float] = 0.0,
dropout: Optional[float] = 0.0,
ffn_dropout: Optional[float] = 0.0,
*args,
**kwargs
) -> None:
super().__init__()
attn_unit = SeparableSelfAttention(
embed_dim,
attn_dropout=attn_dropout,
bias=True
)
self.pre_norm_mha = nn.Sequential(
nn.LayerNorm(embed_dim),
attn_unit,
nn.Dropout(p=dropout)
)
self.pre_norm_ffn = nn.Sequential(
nn.LayerNorm(embed_dim),
nn.Linear(in_features=embed_dim, out_features=ffn_latent_dim, bias=True),
nn.SiLU(),
nn.Dropout(p=ffn_dropout),
nn.Linear(in_features=ffn_latent_dim, out_features=embed_dim, bias=True),
nn.Dropout(p=dropout)
)
self.embed_dim = embed_dim
self.ffn_dim = ffn_latent_dim
self.ffn_dropout = ffn_dropout
self.std_dropout = dropout
def forward(self, x: Tensor) -> Tensor:
# multi-head attention
res = x
x = self.pre_norm_mha(x)
x = x + res
# feed forward network
x = x + self.pre_norm_ffn(x)
return x
class MobileViTBlock(nn.Module):
def __init__(
self,
in_channels: int,
transformer_dim: int,
ffn_dim: int,
n_transformer_blocks: int = 2,
attn_dropout: float = 0.0,
dropout: float = 0.0,
ffn_dropout: float = 0.0,
patch_h: int = 8,
patch_w: int = 8,
conv_ksize: Optional[int] = 3,
*args,
**kwargs
) -> None:
super().__init__()
conv_3x3_in = ConvLayer(
in_channels=in_channels,
out_channels=in_channels,
kernel_size=conv_ksize,
stride=1,
groups=in_channels
)
conv_1x1_in = ConvLayer(
in_channels=in_channels,
out_channels=transformer_dim,
kernel_size=1,
stride=1,
use_norm=False,
use_act=False
)
conv_1x1_out1 = ConvLayer(
in_channels=transformer_dim,
out_channels=transformer_dim,
kernel_size=1,
stride=1
)
conv_1x1_out2 = ConvLayer(
in_channels=2 * transformer_dim,
out_channels=in_channels,
kernel_size=1,
stride=1
)
self.local_rep = nn.Sequential()
self.local_rep.add_module(name="conv_3x3", module=conv_3x3_in)
self.local_rep.add_module(name="conv_1x1", module=conv_1x1_in)
global_rep = [
SSATransformerEncoder(
embed_dim=transformer_dim,
ffn_latent_dim=ffn_dim,
attn_dropout=attn_dropout,
dropout=dropout,
ffn_dropout=ffn_dropout
)
for _ in range(n_transformer_blocks)
]
global_rep.append(nn.LayerNorm(transformer_dim))
self.global_rep = nn.Sequential(*global_rep)
self.out_conv1 = conv_1x1_out1
self.out_conv2 = conv_1x1_out2
self.patch_h = patch_h
self.patch_w = patch_w
self.patch_area = self.patch_w * self.patch_h
self.cnn_in_dim = in_channels
self.cnn_out_dim = transformer_dim
self.ffn_dim = ffn_dim
self.dropout = dropout
self.attn_dropout = attn_dropout
self.ffn_dropout = ffn_dropout
self.n_blocks = n_transformer_blocks
self.conv_ksize = conv_ksize
def unfolding(self, x: Tensor) -> Tuple[Tensor, Dict]:
patch_w, patch_h = self.patch_w, self.patch_h
patch_area = patch_w * patch_h
batch_size, in_channels, orig_h, orig_w = x.shape
new_h = int(math.ceil(orig_h / self.patch_h) * self.patch_h)
new_w = int(math.ceil(orig_w / self.patch_w) * self.patch_w)
interpolate = False
if new_w != orig_w or new_h != orig_h:
# Note: Padding can be done, but then it needs to be handled in attention function.
x = F.interpolate(x, size=(new_h, new_w), mode="bilinear", align_corners=False)
interpolate = True
# number of patches along width and height
num_patch_w = new_w // patch_w
num_patch_h = new_h // patch_h
num_patches = num_patch_h * num_patch_w
x = x.reshape(batch_size, in_channels, num_patch_h, patch_h, num_patch_w, patch_w)
x = x.transpose(3, 4)
x = x.reshape(batch_size, in_channels, num_patches, patch_area)
x = x.transpose(1, 3)
x = x.reshape(batch_size * patch_area, num_patches, -1)
info_dict = {
"orig_size": (orig_h, orig_w),
"batch_size": batch_size,
"interpolate": interpolate,
"total_patches": num_patches,
"num_patches_w": num_patch_w,
"num_patches_h": num_patch_h,
}
return x, info_dict
def folding(self, x: Tensor, info_dict: Dict) -> Tensor:
n_dim = x.dim()
assert n_dim == 3, "Tensor should be of shape BPxNxC. Got: {}".format(
x.shape
)
x = x.contiguous().view(
info_dict["batch_size"], self.patch_area, info_dict["total_patches"], -1
)
batch_size, pixels, num_patches, channels = x.size()
num_patch_h = info_dict["num_patches_h"]
num_patch_w = info_dict["num_patches_w"]
x = x.transpose(1, 3)
x = x.reshape(batch_size * channels * num_patch_h, num_patch_w, self.patch_h, self.patch_w)
x = x.transpose(1, 2)
x = x.reshape(batch_size, channels, num_patch_h * self.patch_h, num_patch_w * self.patch_w)
if info_dict["interpolate"]:
x = F.interpolate(
x,
size=info_dict["orig_size"],
mode="bilinear",
align_corners=False,
)
return x
def forward(self, x: Tensor) -> Tensor:
res = x
local_out = self.local_rep(x)
# convert feature map to patches
patches, info_dict = self.unfolding(local_out)
# learn global representations
for transformer_layer in self.global_rep:
patches = transformer_layer(patches)
fm = self.folding(x=patches, info_dict=info_dict)
fm = self.out_conv1(fm)
fm = self.out_conv2(torch.cat((local_out, fm), dim=1))
fm = res + fm
return fm2.完整代码获取
可添加下方名片获取
3.专栏介绍
YOLOv5原创自研
https://blog.csdn.net/m0_63774211/category_12511931.html
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!

目录
原创自研
CBAM魔改,升级
卷积魔改,升级版本
注意力机制
自研检测头
2024年前沿最新成果
计算机视觉顶会创新
原创自研
CBAM魔改,升级
1.自研独家创新MSAM注意力,通道注意力升级,魔改CBAM
YOLOv5独家原创改进:自研独家创新MSAM注意力,通道注意力升级,魔改CBAM-CSDN博客
2. 新颖自研设计的BSAM注意力,基于CBAM升级
YOLOv5/YOLOv7独家原创改进:新颖自研设计的BSAM注意力,基于CBAM升级-CSDN博客
3.创新自研CPMS注意力,多尺度通道注意力具+多尺度深度可分离卷积空间注意力,全面升级CBAM
YOLOv5独家原创改进:创新自研CPMS注意力,多尺度通道注意力具+多尺度深度可分离卷积空间注意力,全面升级CBAM-CSDN博客
4.一种新颖的跨通道交互的高效率通道注意力EMCA,ECA注意力改进版 YOLOv5原创改进:一种新颖的跨通道交互的高效率通道注意力EMCA,ECA注意力改进版-CSDN博客
卷积魔改,升级版本
1.自研独家创新FT_Conv,卷积高效结合分数阶变换
YOLOv5独家原创改进:自研独家创新FT_Conv,卷积高效结合傅里叶分数阶变换-CSDN博客
2.AKConv(可改变核卷积),即插即用的卷积,效果秒杀DSConv
YOLOv5独家原创改进: AKConv(可改变核卷积),即插即用的卷积,效果秒杀DSConv | 2023年11月最新发表-CSDN博客
3.轻量化自研设计双卷积,重新设计backbone和neck卷积结构 YOLOv5独家原创改进:轻量化自研设计双卷积,重新设计backbone和neck卷积结构,完成涨点且计算量和参数量显著下降-CSDN博客
注意力机制
1. SENet v2,Squeeze-Excitation模块融合Dense Layer,效果秒杀SENet
YOLOv5全网独家首发改进:SENetv2,Squeeze-Excitation模块融合Dense Layer,效果秒杀SENet-CSDN博客
2.一种新颖的多尺度滑窗注意力,助力小目标和遥感影像场景
YOLOv5涨点技巧:一种新颖的多尺度滑窗注意力,助力小目标和遥感影像场景-CSDN博客
3.一种新颖的自适应空间相关性金字塔注意力 ,实现小目标暴力涨点
YOLOv5独家原创改进:一种新颖的自适应空间相关性金字塔注意力 ,实现小目标暴力涨点-CSDN博客
自研检测头
1.独家创新(Partial_C_Detect)检测头结构创新,实现涨点
YOLOv5优化:独家创新(Partial_C_Detect)检测头结构创新,实现涨点 | 检测头新颖创新系列-CSDN博客
2. 独家创新(SC_C_Detect)检测头结构创新,实现涨点
YOLOv5优化:独家创新(SC_C_Detect)检测头结构创新,实现涨点 | 检测头新颖创新系列-CSDN博客
SPPF创新
1.SPPF与感知大内核卷积UniRepLK结合,大kernel+非膨胀卷积提升感受野
YOLOv5独家原创改进:SPPF自研创新 | SPPF与感知大内核卷积UniRepLK结合,大kernel+非膨胀卷积提升感受野-CSDN博客
2.可变形大核注意力(D-LKA Attention),大卷积核提升不同特征感受野的注意力机制
YOLOv5独家原创改进:SPPF自研创新 | 可变形大核注意力(D-LKA Attention),大卷积核提升不同特征感受野的注意力机制-CSDN博客
3.SPPF创新结构,重新设计全局平均池化层和全局最大池化层
YOLOv5独家原创改进:SPPF自研创新 | SPPF创新结构,重新设计全局平均池化层和全局最大池化层,增强全局视角信息和不同尺度大小的特征-CSDN博客
IOU & loss优化
1.提出一种新的Shape IoU,更加关注边界框本身的形状和尺度,对小目标检测也很友好
YOLOv5独家原创改进:提出一种新的Shape IoU,更加关注边界框本身的形状和尺度,对小目标检测也很友好 | 2023.12.29收录_yolov5引入shape-iou-CSDN博客
2.新颖的Shape IoU结合 Inner-IoU,基于辅助边框的IoU损失的同时关注边界框本身的形状和尺度,小目标实现高效涨点
YOLOv5独家原创改进:新颖的Shape IoU结合 Inner-IoU,基于辅助边框的IoU损失的同时关注边界框本身的形状和尺度,小目标实现高效涨点-CSDN博客
2024年前沿最新成果
1. 多种新颖的改进方式 | 保持原始信息-深度可分离卷积(MDSConv) | 全局感受野的空间金字塔 (Improve-SPPF)算法 | CA注意力改进版
YOLOv5独家原创改进: 多种新颖的改进方式 | 保持原始信息-深度可分离卷积(MDSConv) | 全局感受野的空间金字塔 (Improve-SPPF)算法 | CA注意力改进版-CSDN博客
计算机视觉顶会创新
持续更新中,本专栏打造高质量、高原创的专栏,为客户提供精品服务