文章目录
- 摘要
- Abstract
- 文献阅读
- 题目
- 引言
- 方法
- The ARIMA model
- Time delay neural network (TDNN) model
- LSTM and DLSTM model
- 评估准则
- 实验
- 数据描述
- 实验结果
- 深度学习
- Attention
- Attention思想
- 公式步骤
- Attention代码实现
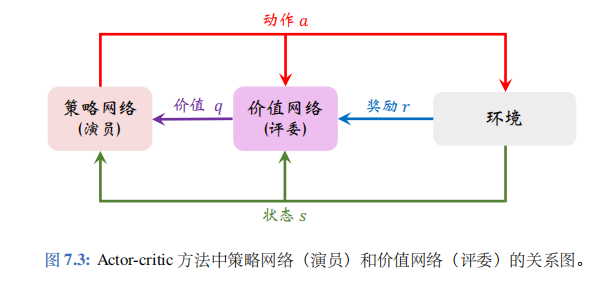
- 注意力机制
- seq2seq解码器
- Model
- 验证
- 总结
摘要
本周阅读了一篇基于深度长短期记忆的农产品价格预测模型的文章,文章提出了一种基于深度长短期记忆(DLSTM)的模型。DLSTM模型同时利用递归架构和深度学习方法,在捕获非线性和易失性模式方面具有优势。利用国际玉米和棕榈油月度价格序列,比较了DLSTM模型与传统时延神经网络(TDNN)和ARIMA模型的价格预测能力。实证结果表明,开发的DLSTM模型优于其他模型的各种预测评价标准,在预测这些月度价格序列的方向变化方面也显示出优于其他模型的优势。此外还对attention机制进行理论学习和代码实现。
Abstract
This week, an article about agricultural product price forecasting model based on deep long-term and short-term memory is readed, and the article proposed a model based on deep long-term and short-term memory (DLSTM). Recursive architecture and deep learning method at the same time is used in DLSTM model, which has advantages in capturing nonlinear and volatile patterns. Using the monthly price series of international corn and palm oil, the price forecasting ability of DLSTM model is compared with that of traditional TDNN and ARIMA model. The empirical results show that the developed DLSTM model is superior to other models in various forecasting evaluation criteria, and it also shows advantages over other models in forecasting the direction changes of these monthly price series. In addition, the attention mechanism is studied theoretically and realized by code.
文献阅读
题目
Deep long short-term memory based model for agricultural price forecasting
引言
农产品价格预测以其独特的特点成为时间序列预测的研究热点之一。本文通过改变数据集的时间步长、隐节点数和隐层数,提出了一种深度LSTM(DLSTM)架构,该架构可以适应农业价格序列数据的非平稳和非线性特征。开发的模型可以通过利用多层LSTM单元的记忆单元的诀窍来提取有用的信息,并通过识别序列的短期和长期依赖关系来学习内部表示,从而精确地预测农产品价格,可以准确预测下个月价格走势的能力。
开发的模型进行了进一步的评估和比较严格的基准模型,即TDNN和ARIMA模型使用真实的月度价格序列的两个全球重要的农产品。对于强大的验证和检查开发的模型的预测能力的优越性,使用参数和非参数检验,分别是Diebold-Mariano检验和弗里德曼检验。
方法
The ARIMA model
自回归积分移动平均(ARIMA)模型是基于时间序列变量值之间的线性假设,一个单变量时间序列可以通过将其表示为它自己的滞后值或过去值以及其中发生的一些随机干扰的函数来建模。
ARIMA(p,d,q)模型,其中p,d和q分别为自回归,差分(积分)和移动平均的阶数,可以表示为:


Time delay neural network (TDNN) model
TDNN是一种前馈神经网络模型,通过使用单变量时间序列的时间延迟来捕获序列的时间维度,在数学上,前向传播可以表示为:
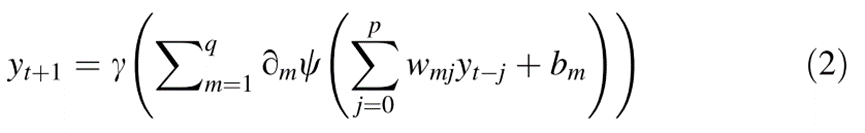
在反向传播中,通过比较模型输出和期望输出来计算损失函数或成本函数。该损失函数在网络中向后遍历,以链规则的特定顺序计算其相对于所有权重的梯度或偏导数。具有负方向的偏导数说明梯度下降,其更新网络的突触权重,旨在尽可能小地最小化损失函数。所有示例或样本的信息的前向和后向传播的这几次迭代被称为训练的时期。因此,模型的训练需要优化时期的数量沿着以及其他几个超参数,如输入节点的数量,隐藏节点的数量,批量大小等。
LSTM and DLSTM model
LSTM有三个门,即遗忘门(ft)、输入门(it)和输出门(ot)。除了sigmoid激活函数之外,LSTM单元中还使用了另一个激活函数(通常是tanh),以克服消失梯度问题,即可以长时间维持二阶导数。通过LSTM处理信息的第一步是从细胞状态中丢弃不相关的信息。

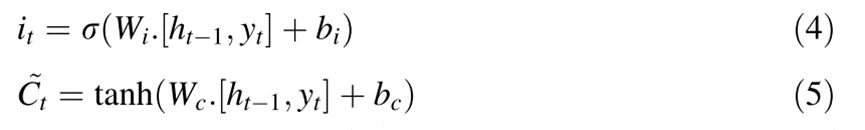
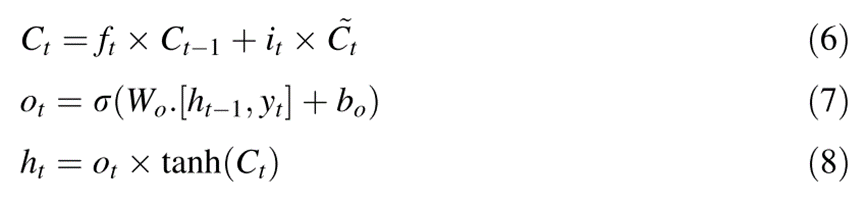
DLSTM模型是LSTM网络架构的高级版本,通过堆叠多个隐藏层获得,每个隐藏层具有多个隐藏节点,能够通过逐层解码(分层处理)来捕获时间序列的复杂模式,从而在训练时进行有效学习,实现更好的预测。
DLSTM对时间序列数据的建模需要类似于TDNN的数据准备。数据首先被转换为监督学习格式。与TDNN略有不同,DLSTM需要一个额外的转换来准备用于拟合LSTM神经网络的数据。具体来说,监督学习数据的2-D结构被转换为3-D结构。LSTM输入的三个维度是(1)样本:一个序列是一个样本,(2)滞后数,(3)特征:在单变量的情况下,一个特征是一个时间步长的一个观察。一个批次由一个或多个样品组成。任何单变量序列都必须以这种方式准备,才能通过LSTM建模。与TDNN模型一样,LSTM模型将通过映射每个样本的输入和输出数据来学习函数。通过实验和网格搜索法调整和确定模型超参数,以获得优化结果。
评估准则
为了比较所开发的DLSTM模型与ARIMA和TDNN在水平和方向预测方面的预测性能,选择了四个指标,包括均方根误差(RMSE),平均绝对偏差(MAD),平均绝对百分比误差(MAPE)和方向统计量(Dstat):
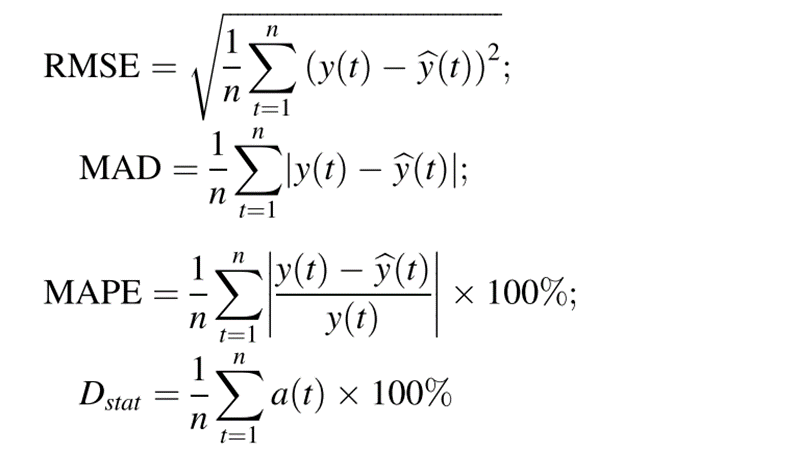
DM测试用于评估两个竞争模型的预测准确性:

实验
数据描述
两种全球重要农产品的月度价格系列,一种来自谷物,即玉米,另一种来自食用植物油,即棕榈油,被用作本研究的实验数据集。表1列出了研究中使用的两个系列的描述性统计数据,图3和图4显示了两个系列的时间图。


本研究的目的是建立一个用于农产品价格预测的DLSTM模型,并将其与ARIMA和TDNN等预测模型进行比较。在这项研究中,ARIMA建模是在R版本3.6.1软件中完成的,而其他神经网络模型是在Python 3.7中使用Keras和Tensorflow库构建的。
实验结果
2019年8月至2020年7月使用不同模型的两个价格系列预测值:

玉米价格不同模型的12个月预测值与实际值的图:

棕榈油价格不同模型的12个月预测值与实际值的图:

可以看出,预测序列的值更接近使用DLSTM获得的实际价格序列的值,DLSTM模型比传统模型更好地捕捉了价格变动的模式和方向。
深度学习
Attention
Attention机制:又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术.通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素。其中重要程度的判断取决于应用场景,拿个现实生活中的例子,比如1000个人眼中有1000个哈姆雷特。根据应用场景的不同,Attention分为空间注意力和时间注意力,前者用于图像处理,后者用于自然语言处理。
注意力的核心目标就是从众多信息中选择出对当前任务目标更关键的信息,将注意力放在上面。本质思想就是【从大量信息中】【有选择的筛选出】【少量重要信息】并【聚焦到这些重要信息上】,【忽略大多不重要的信息】。聚焦的过程体现在【权重系数】的计算上,权重越大越聚焦于其对应的value值上。即权重代表了信息 的重要性,而value是其对应的信息。
Attention思想
基本流程描述:
以seq2seq模型为例子,对于一个句子序列S,其由单词序列[w1,w2,w3,…,wn]构成:
1) 将S的每个单词 wi编码为一个单独向量 vi,这里对应seq2seq模型,就是在encoder编码阶段,每个时间步单位(即每个单词)的输出隐状态。
2)在解码decoder阶段,待预测词的输入隐状态C(即上一个时间步的输出状态)与1中每个单词的隐状态相乘再做softmax归一化后得到权重分数,使用学习到的注意力权重 ai对1中得到的所有单词向量做加权线性组合:
3)利用输入状态C以及输入变量Z作为对待预测词的共同输入,来进行预测。
公式步骤

以例子进行更通俗详细的描述:
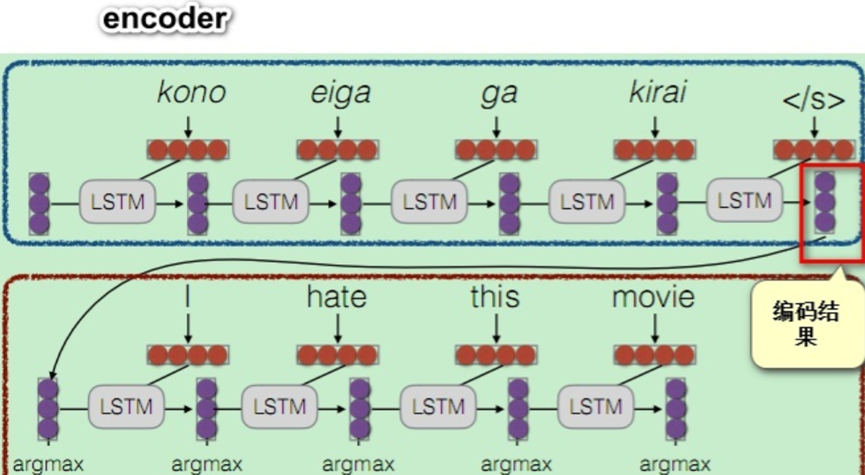
我们的最终目标是要能够帮助decoder在生成词语时,有一个不同词语的权重的参考。在训练时,对于decoder我们是有训练目标的,此时将decoder中的信息定义为一个Query。而encoder中包含了所有可能出现的词语,我们将其作为一个字典,该字典的key为所有encoder的序列信息,n个单词相当于当前字典中有n条记录,而字典的value通常也是所有encoder的序列信息,一般情况下,key和value是一样的。
上面对应于第一步,然后是第二部计算注意力权重,由于我们要让模型自己去学习该对哪些语素重点关注,因此要用我们的学习目标Query来参与这个过程,因此对于Query的每个向量,通过一个函数  ,这里的Qi就是上一个时间步的输出隐状态,计算预测i时刻词时,需要学习的注意力权重,由于包含n个单词,因此,ai 应当是一个n维的向量,为了后续计算方便,需要将该向量进行softmax归一化,让向量的每一维元素都是一个概率值。
,这里的Qi就是上一个时间步的输出隐状态,计算预测i时刻词时,需要学习的注意力权重,由于包含n个单词,因此,ai 应当是一个n维的向量,为了后续计算方便,需要将该向量进行softmax归一化,让向量的每一维元素都是一个概率值。

上图的黄色框圈的hate变量,就是由I单词之后的输出隐状态C,也可以称之为q,这里的q再与上面的Key Vector相乘再做softmax归一化得到一个权重分数。
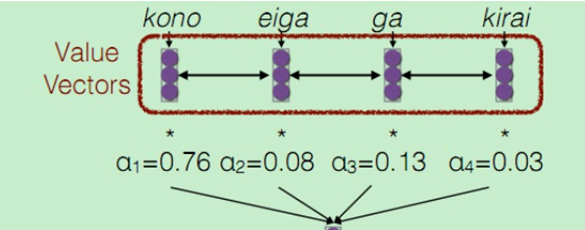
这个权重分数再与Value Vectors(这里的value与key一样)进行加权线性组合,得到一组新的带有注意力的变量,这个变量就是预测hate的输入值Z,最后由C和Z来共同输入预测hate。
Attention代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
1.将输入序列input_ids通过Embedding层映射为词向量序列。
2. 将词向量序列输入到LSTM层,得到该序列在每个时刻的输出状态输出output_states。
3. 返回最后一个时刻的隐藏状态final_h,以及所有时刻的输出状态output_states
class Seq2SeqEncoder(nn.Module):
#实现基于LSTM的编码器,也可以是RNN、GRU
def __init__(self,embedding_dim,hidden_size,source_vocab_size):
super(Seq2SeqEncoder,self).__init__()
#lstm层输入大小为embedding_dim,隐层大小为hidden_size,然后把batch_size放在首个维度
self.lstm_layer=nn.LSTM(input_size=embedding_dim,hidden_size=hidden_size,batch_first=True)
#Embedding层将输入序列input_ids映射到embedding_dim维的表示空间
self.embedding_table=nn.Embedding(source_vocab_size,embedding_dim)
def forward(self,input_ids):
#利用embedding层得到输入序列的向量表示
input_sequence = self.embedding_table(input_ids)
#输入input_sequence到LSTM层,得到所有时刻的输出状态输出output_states
output_states,(final_h,final_c) = self.lstm_layer(input_sequence)
#返回最后时刻的隐藏状态final_h,以及输出状态
return output_states,final_h
注意力机制
- 接收解码器当前状态decoder_state_t和编码器状态序列encoder_states作为输入。
- 计算解码器状态与每个编码器状态的点积,得到相关性得分score。
- 对score做softmax,得到normalize后的权重attn_prob。
- 利用attn_prob对编码器状态加权求和,得到上下文向量context。5. 返回注意力权重attn_prob和上下文向量context。
class Seq2SeqAttentionMechanism(nn.Module):
#实现dot-product的Attention
def __init__(self):
super(Seq2SeqAttentionMechanism,self).__init__()
#接收两个参数:
#decoder_state_t: 解码器当前时刻的状态,形状为[batch_size, hidden_size]
#encoder_states: 编码器输出的状态序列,形状为[batch_size, source_length, hidden_size]
def forward(self,decoder_state_t,encoder_states):
#从encoder_states得到输入序列相关的形状信息
bs,source_length,hidden_size = encoder_states.shape
#size:[batch_size, 1, hidden_size]。
decoder_state_t=decoder_state_t.unsqueeze(1)
#size:[batch_size,source_length,hidden_size]
decoder_state_t=torch.tile(decoder_state_t,dims=(1,source_length,1))
#点乘注意力,计算解码器状态与编码器状态的点积,得到相关性得分score。计算结果为[bs,source_length]
score = torch.sum(decoder_state_t*encoder_states,dim=-1)
#softmax,对score进行softmax,得到normalize后的概率attn_prob作为注意力权重
attn_prob = F.softmax(score,dim=-1)
#利用attn_prob对编码器状态加权求和,得到上下文向量context
context = torch.sum(attn_prob.unsqueeze(-1)*encoder_states,1)
return attn_prob,context
seq2seq解码器
- 在__init__中定义了词向量层、LSTM计算单元、投影层、注意力层等组件。
- forward函数实现训练模式下的解码计算。 - 将目标序列通过词向量层映射为词向量序列。
- 利用LSTM逐步解码每个时刻。
- 计算注意力权重和上下文向量。
- 将上下文向量与LSTM隐状态拼接后通过投影层计算当前时刻的logits。
- 存储每个时刻的logits和注意力权重矩阵。
- inference函数实现测试模式下的自回归解码。 - 利用start token初始化,循环调用LSTM生成隐状态。
- 计算注意力和上下文向量。
- 通过投影层计算logits,选择概率最高的词作为当前预测。
- 将预测词不断累加到结果中,直到生成结束词end_id。
class Seq2SeqDecoder(nn.Module):
def __init__(self,embedding_dim,hidden_size,num_classes,target_vocab_size,start_id,end_id):
super(Seq2SeqDecoder,self).__init__()
#LSTM的计算单元,lstm层输入大小为embedding_dim,隐层大小为hidden_size
self.lstm_cell = torch.nn.LSTMCell(embedding_dim,hidden_size)
#全连接层,将两份隐状态映射到词典大小的 logits,num_classes就是target_vocab_size
self.proj_layer = nn.Linear(hidden_size*2,num_classes)
#注意力机制
self.attention_mechanism = Seq2SeqAttentionMechanism()
#最后的分类层,词典大小,等于目标语言的词汇量target_vocab_size
self.num_classes = num_classes
#Embedding层,将输入token ID映射为embedding向量
self.embedding_table = torch.nn.Embedding(target_vocab_size,embedding_dim)
#推理时,从start id开始,一直到start end结束,两个token
self.start_id = start_id
self.end_id=end_id
def forward(self,shifted_target_ids,encoder_states):
#输入target序列id先通过Embedding层,得到对应的词向量表示shifted_target。
shifted_target = self.embedding_table(shifted_target_ids)
bs,target_length,embedding_dim = shifted_target.shape
bs,source_length,hidden_size = encoder_states.shape
#初始化存储变量,存储每个时间步的logits,用于计算损失
logits = torch.zeros(bs,target_length,self.num_classes)
#存储每个时间步的attention权重,用于可视化
probs = torch.zeros(bs,target_length,source_length)
for t in range(target_length):
decoder_input_t = shifted_target[:,t,:]
if t==0:
h_t,c_t = self.lstm_cell(decoder_input_t)
else:
h_t,c_t = self.lstm_cell(decoder_input_t,(h_t,c_t))
attn_prob,context = self.attention_mechanism(h_t,encoder_states)
decoder_output=torch.cat((context,h_t),-1)
# logits存储了每个时间步的logits输出
logits[:,t,:] = self.proj_layer(decoder_output)
# probs存储了每个时间步的attention权重矩阵
probs[:,t,:] = attn_prob
return probs,logits
def inference(self,encoder_states):
target_id = self.start_id
h_t = None
result = []
"""
- 将当前target_id通过Embedding层得到输入向量。
- 如果是第一个时间步,调用LSTM计算初始隐状态。
- 否则使用上一步的隐状态进行递归计算当前隐状态。
- 计算attention权重和上下文向量。
- 将上下文向量与隐状态拼接后通过投影层计算logits。
- 根据logits选取概率最大的词id作为当前预测目标,存储到结果列表中。
- 如果预测到end_id,终止循环。
"""
while True:
decoder_input_t = self.embedding_table(target_id)
if h_t is None:
h_t,c_t = self.lstm_cell(decoder_input_t)
else:
h_t,c_t = self.lstm_cell(decoder_input_t,(h_t,c_t))
attn_prob,context = self.attention_mechanism(h_t,encoder_states)
decoder_output = torch.cat((context,h_t),-1)
logits = self.proj_layer(decoder_output)
target_id = torch.argmax(logits,-1)
result.append(target_id)
if torch.any(target_id ==self.end_id):
print("stop decoding!")
break
predicted_ids = torch.stack(result,dim=0)
return predicted_ids
Model
在__init__中定义编码器模块encoder和解码器模块decoder。
forward函数定义模型的训练模式前向计算过程: - 输入源语言序列input_sequence_ids和目标语言序列shifted_target_ids。
- 通过编码器模块获得编码器状态encoder_states。
- 将编码器状态传入解码器模块。
- 解码器模块输出注意力权重probs和预测的logits。
- 返回probs和logits。
infer函数预留了模型的推理模式下前向计算的接口。
class Model(nn.Module):
def __init__(self,embedding_dim,hidden_size,num_classes,source_vocab_size,target_vocab_size,start_id,end_id):
super(Model,self).__init__()
self.encoder=Seq2SeqEncoder(embedding_dim,hidden_size,source_vocab_size)
self.decoder=Seq2SeqDecoder(embedding_dim,hidden_size,num_classes,target_vocab_size,start_id,end_id)
"""
def forward():
- 定义模型的前向计算过程。
- input_sequence_ids:源语言序列。
- shifted_target_ids:目标语言序列(向后偏移一位)。
- 通过编码器模块获得编码器状态。
- 通过解码器模块获得attention权重和预测logits。
- 返回attention权重probs和预测logits。
"""
def forward(self,input_squence_ids,shifted_target_ids):
encoder_states,final_h=self.encoder(input_sequence_ids)
probs,logits = self.decoder(shifted_target_ids,encoder_states)
return probs,logits
def infer(self):
pass
验证
通过定义模型和输入,示例代码实现了一次Seq2Seq模型的前向传播过程,并打印出attention概率矩阵和预测logit矩阵的大小,验证了Seq2Seq模型的训练模式下的前向计算流程。
input_sequence_ids: shape=(2, 3),源语言序列 target_ids: shape=(2, 4),目标语言序列
shifted_target_ids: 在target_ids前面添加start_id,shape=(2, 5)
正向传播计算probs和logits: encoder编码input_sequence_ids得到编码器状态
decoder解码shifted_target_ids,在编码器状态条件下生成目标序列
probs表示attention概率矩阵,shape=(2, 5, 3)logits表示预测的logits,shape=(2, 5, 10)5. 打印输出大小: probs size:
torch.Size([2, 5, 3]) logits size: torch.Size([2, 5, 10])
if __name__ == '__main__':
source_length=3
target_length=4
embedding_dim=8
hidden_size=16
num_classes=10
bs = 2
start_id=end_id=0
source_vocab_size=100
target_vocab_size=100
#源序列的ids
input_sequence_ids = torch.randint(source_vocab_size,size=(bs,source_length)).to(torch.int32)
target_ids = torch.randint(target_vocab_size,size = (bs,target_length))
target_ids = torch.cat((target_ids,end_id*torch.ones(bs,1)),dim=1).to(torch.int32)
shifted_target_ids = torch.cat((start_id*torch.ones(bs,1),target_ids[:,1:]),dim=1).to(torch.int32)
model = Model(embedding_dim, hidden_size, num_classes, source_vocab_size, target_vocab_size, start_id, end_id)
probs, logits = model(input_sequence_ids, shifted_target_ids)
print(probs.shape)
print(logits.shape)
总结
通过示例代码实现了一次Seq2Seq模型的前向传播过程,并打印出attention概率矩阵和预测logit矩阵的大小。此外还对Seq2Seq模型的训练模式下的前向计算流程进行验证。通过理论与实践相结合,加深了对attention机制的理解。