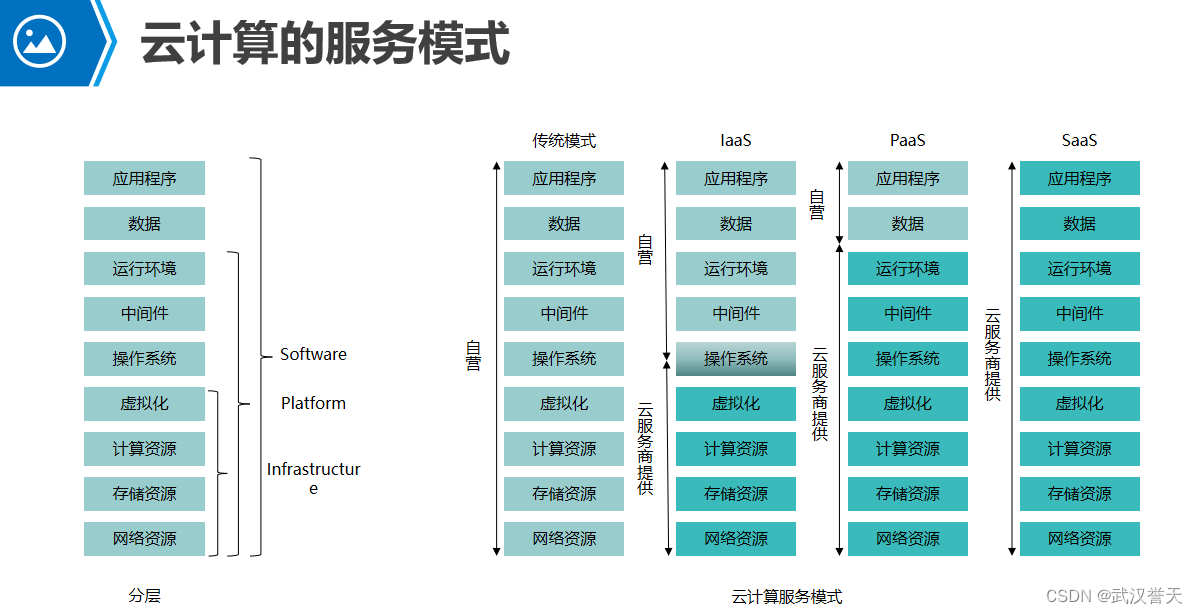
【ARXIV2207】LightViT: Towards Light-Weight Convolution-Free Vision Transformers
论文地址:https://arxiv.org/abs/2207.05557
代码地址:https://github.com/hunto/LightViT
1、研究动机
作者认为,在ViT中混合 convolution,是一种信息聚合的方式,convolution 建立了所 token 之间的明确联系。基于这一点,作者等人提出“如果这种明确的聚合能以更均匀的方式发挥作用,那么它们对于轻量级的ViTs来说实际上是不必要的”。
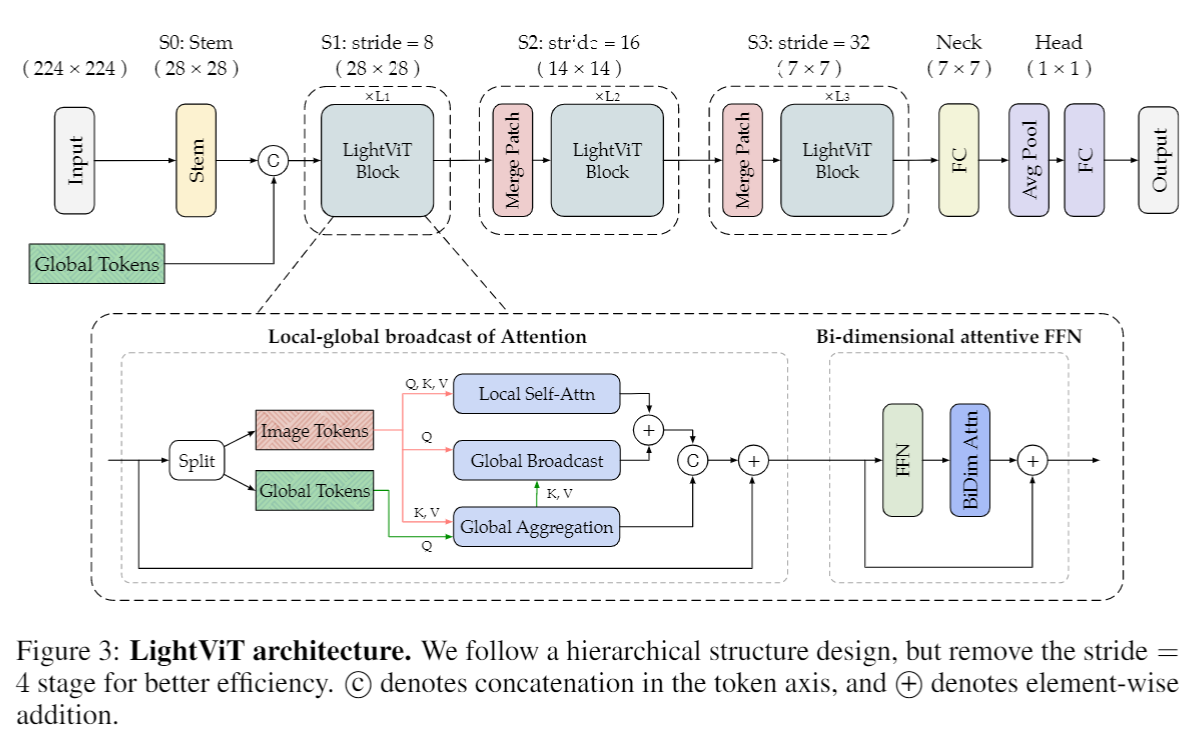
因此,作者提出纯 attention 的轻量级网络,架构如上图所示,可以看出主要改进在于 attention 和 FFN 部分:
- Local-global broadcast attention: 在self-attention中引入可学习的全局标记来对全局依赖关系进行建模,并被广播到局部token中,因此每一个token除了拥有局部窗口注意计算带来的局部依赖关系外,还获得了全局依赖关系
- 在FFN中,设计一种双维注意模块来提升模型性能
2、Local-global broadcast of attention
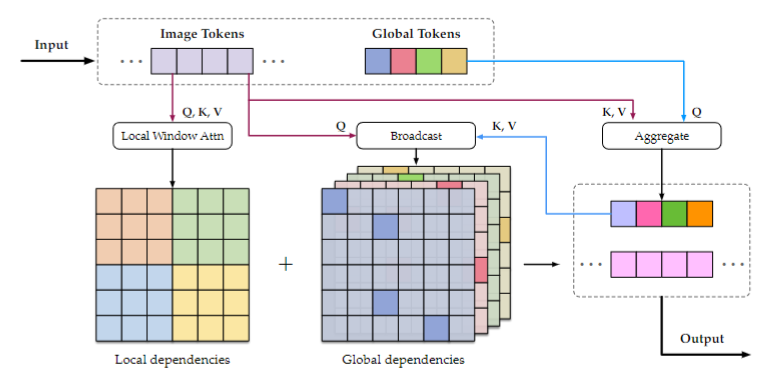
- local windows attention:和大多数方法一样,在7x7的局部窗口中计算注意力
- global aggregation:设计矩阵 G ∈ R T × C G\in\R^{T\times C} G∈RT×C,是可以学习的,其中T代表token数量,C是特征维度。G做为Q与 image token 计算注意力得到 G ^ \hat{G} G^,
- global broadcast:将 G ^ \hat{G} G^作为 K和V,和 image token 计算注意力,得到全局矩阵,与 local window attention 的结果相加得到输出
其中,T数量远小于窗口大小7x7(LightVIT-T中T设置为8),可以大大节省 global aggregation 和 broadcast 的计算量
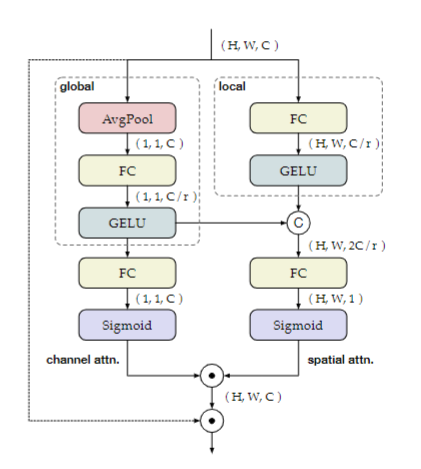
3、FFN with bi-dimensional attention
作者提出了基于二维注意力的FFN,包括通道注意力和空间注意力两个分支,具体细节如下图所示,这里不再多说。
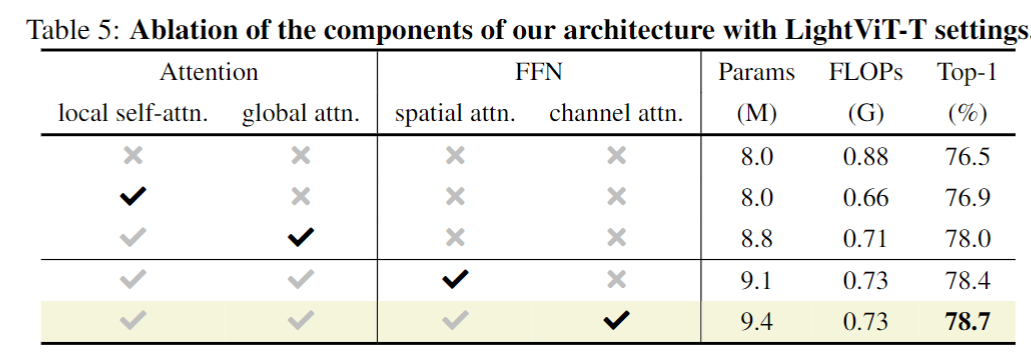
4、实验分析
该方法在多个任务上都取得了非常好的性能,这里重点介绍消融实验。如下表所示, global attn显著提升了性能,而计算量只有轻微增加。FFN中的空间注意力可以捕获空间相关性,并且选择性的关注重要的token,更好的挖掘图像结构信息。