系列文章目录
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part1 案例复现
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part2 自有数据集构建
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part3 化为己用
本篇文章是对已有一篇文章的整理归纳,并对文章中提及的模型用Pytorch实现。
文章目录
- 系列文章目录
- 前言
- 一、任务问题和数据集
- 1 任务问题
- 2 数据集
- 3 数据集读取并展示
- 二、模型实现
- 1 数据导入
- 2 数据预处理
- 3 数据集划分
- 4 网络模型及实例化
- 5 训练过程
- 三、总结
前言
序列,可以是采样得到的信号样本,也可以是传感器数据。
对于序列分类任务,常用的思路有两种:
1、原理统计相关,分解序列的相关性质研究规律(人工设计特征,再分类)
2、数据挖掘思路,机器学习做特征工程,模型拟合(自动学习特征,再分类)
-
人工设计特征方法:
基于序列距离:计算距离进行分类(类别模板or聚类)
基于统计特征:时序特征提取 (均值,方差,差分)再分类 -
自动学习特征方法:
深度学习端到端(RNN, LSTM)
本文通过LSTM来实现对序列信号的分类。
主要思想和代码框架来自参考文献[1]
一、任务问题和数据集
1 任务问题
人体运动估计:
传感器生成高频数据,对不同状态下采集的数据进行分类,可以识别其范围内对象的移动。通过设置多个传感器并对信号进行采样分析,可以识别物体的运动方向。
“ 室内用户运动预测 ”问题:
在该任务中,多个运动传感器被放置在不同房间中,目标基于运动传感器捕获的数据来识别个体是否已经移动穿过房间。
两个房间有四个运动传感器(A1,A2,A3,A4)。
下图说明了传感器在每个房间中的位置。
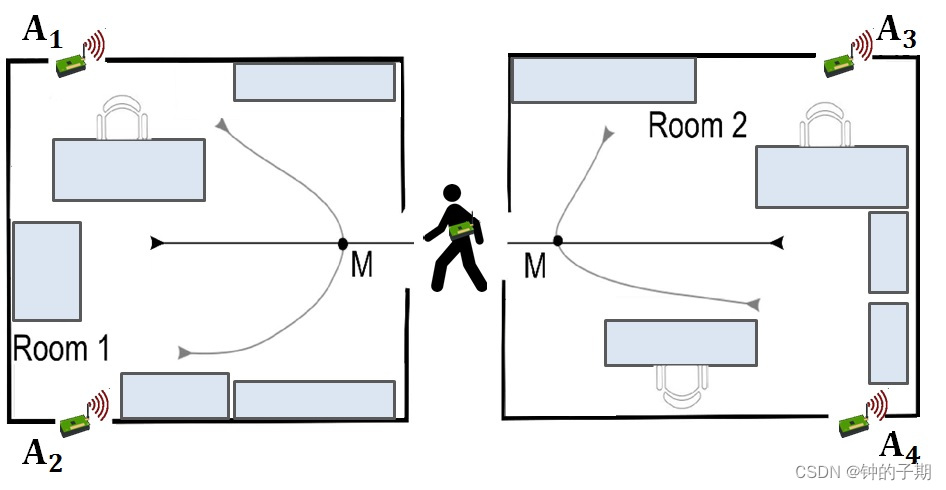
一个人可以沿着上图中所示的六个预定义路径中的任何一个移动。每个路径都生成一个 RSS 测量的轨迹样本,从轨迹的开始一直到标记点,在图中表示为 M。标记 M 对于所有运动都是相同的,因此不能仅仅根据在 M 处收集的 RSS 值来区分不同的路径。
该图还显示了所考虑的用户轨迹类型的简化说明,直线路径导致于空间变化,曲线路径导致空间不变。有在房间内移动和在房间之间移动两种类别。
2 数据集
| 文件 | 含义 |
|---|---|
| RSS_Position_dataset/dataset | 样本数据 |
| RSS_Position_dataset/groups | 标签文件和组别文件(划分数据集) |
| RSS_Position_dataset/MovementAAL.jpg | 上面的示意图 |
数据集最重要的有316个csv文件:
- 【dataset 文件夹】
314 个MovementAAL csv文件,是序列样本,每个文件都包含与输入 RSS 数据的一个序列数据(每个文件记录一个用户轨迹)。该数据集包含314个序列数据(样本csv文件)。
1个 MovementAAL_target.csv 文件,是每个MovementAAL文件对应的标签(类别)。每一个样本对应的类别,表明用户的轨迹是否会导致空间变化(例如房间的变化)。特别地,标签为+1与位置变化相关联,而标签为 -1与位置保留相关联。 - 【groups 文件夹】
MovementAAL_DatasetGroup.csv文件,用于划分数据集
3 数据集读取并展示
import pandas as pd
# ----------------------------------------------------#
# 路径指定,文件读取
# ----------------------------------------------------#
df1 = pd.read_csv("DATA/RSS_Position_dataset/dataset/MovementAAL_RSS_1.csv")
df2 = pd.read_csv("DATA/RSS_Position_dataset/dataset/MovementAAL_RSS_2.csv")
df1.head() # 返回一个新的DataFrame或Series对象,默认返回前5行。
df1.shape # 返回文件的size,不同文件的len(行数)不同
二、模型实现
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
1 数据导入
'''
/****************************************************/
导入数据集
/****************************************************/
'''
# ----------------------------------------------------#
# 数据集样本
# ----------------------------------------------------#
path = "DATA/RSS_Position_dataset/dataset/MovementAAL_RSS_"
sequences = list()
for i in range(1, 315): # 315为样本数
file_path = path + str(i) + '.csv'
df = pd.read_csv(file_path, header=0)
values = df.values
sequences.append(values)
# ----------------------------------------------------#
# 数据集标签
# ----------------------------------------------------#
targets = pd.read_csv('DATA/RSS_Position_dataset/dataset/MovementAAL_target.csv')
targets = targets.values[:, 1]
# ----------------------------------------------------#
# 数据集划分
# ----------------------------------------------------#
groups = pd.read_csv('DATA/RSS_Position_dataset/groups/MovementAAL_DatasetGroup.csv', header=0)
groups = groups.values[:, 1]
分析:
- 数据集样本:将所有的样本读入sequences列表中,列表长度为样本数,列表中每一个元素为一个样本。
- 数据集标签:targets 中存放。
- 数据集划分:数据集是在三对不同的房间中收集的,因此有三组。此信息可用于将数据集划分为训练集,测试集和验证集。
2 数据预处理
由于时间序列数据的长度不同,sequences列表中每个元素长度不一。无法直接在此数据集上构建模型。需要统一。原文中的思想是填充使相等。
这里是对样本,即sequences列表变量进行处理。
# ----------------------------------------------------#
# Padding the sequence with the values in last row to max length
# ----------------------------------------------------#
# 函数用于填充和截断序列
def pad_truncate_sequences(sequences, max_len, dim=4, truncating='post', padding='post'):
# 初始化一个空的numpy数组,用于存储填充后的序列
padded_sequences = np.zeros((len(sequences), max_len, dim))
for i, one_seq in enumerate(sequences):
if len(one_seq) > max_len: # 截断
if truncating == 'pre':
padded_sequences[i] = one_seq[-max_len:]
else:
padded_sequences[i] = one_seq[:max_len]
else: # 填充
padding_len = max_len - len(one_seq)
to_concat = np.repeat(one_seq[-1], padding_len).reshape(dim, padding_len).transpose()
if padding == 'pre':
padded_sequences[i] = np.concatenate([to_concat, one_seq])
else:
padded_sequences[i] = np.concatenate([one_seq, to_concat])
return padded_sequences
# 使用自定义函数进行填充和截断
seq_len = 32
# truncate or pad the sequence to seq_len
final_seq = pad_truncate_sequences(sequences, max_len=seq_len, dim=4, truncating='post', padding='post')
对数据集来说,标签 +1/-1 不利于模型输出,变为 1/0。
这里是对标签,即targets类别变量进行处理。
# 设置标签从 +1/-1 ,变为 1/0
targets = np.array(targets)
final_targets = (targets+1)/2
3 数据集划分
# ----------------------------------------------------#
# 数据集划分
# ----------------------------------------------------#
# 将numpy数组转换为PyTorch张量
final_seq = torch.tensor(final_seq, dtype=torch.float)
# 划分样本为 训练集,验证集 和 测试集
train = [final_seq[i] for i in range(len(groups)) if groups[i] == 1]
validation = [final_seq[i] for i in range(len(groups)) if groups[i] == 2]
test = [final_seq[i] for i in range(len(groups)) if groups[i] == 3]
# 标签同理
train_target = [final_targets[i] for i in range(len(groups)) if groups[i] == 1]
validation_target = [final_targets[i] for i in range(len(groups)) if groups[i] == 2]
test_target = [final_targets[i] for i in range(len(groups)) if groups[i] == 3]
# 转换为PyTorch张量
train = torch.stack(train)
train_target = torch.tensor(train_target).long()
validation = torch.stack(validation)
validation_target = torch.tensor(validation_target).long()
test = torch.stack(test)
test_target = torch.tensor(test_target).long()
4 网络模型及实例化
'''
/****************************************************/
网络模型
/****************************************************/
'''
# ----------------------------------------------------#
# LSTM 模型
# ----------------------------------------------------#
class TimeSeriesClassifier(nn.Module):
def __init__(self, n_features, hidden_dim=256, output_size=1):
super().__init__()
self.lstm = nn.LSTM(input_size=n_features, hidden_size=hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_size) # output_size classes
def forward(self, x):
x, _ = self.lstm(x) # LSTM层
x = x[:, -1, :] # 只取LSTM输出中的最后一个时间步
x = self.fc(x) # 通过一个全连接层
return x
# ----------------------------------------------------#
# 模型实例化 和 部署
# ----------------------------------------------------#
n_features = 4 # 根据你的特征数量进行调整
output_size = 2
model = TimeSeriesClassifier(n_features=n_features, output_size=output_size)
# 打印模型结构
print(model)
5 训练过程
'''
/****************************************************/
训练过程
/****************************************************/
'''
# 设置训练参数
epochs = 100 # 训练轮数,根据需要进行调整
batch_size = 4 # 批大小,根据你的硬件调整
# DataLoader 加载数据集
# 将数据集转换为张量并创建数据加载器
train_dataset = torch.utils.data.TensorDataset(train, train_target)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
validation_dataset = torch.utils.data.TensorDataset(validation, validation_target)
validation_loader = torch.utils.data.DataLoader(dataset=validation_dataset, batch_size=batch_size, shuffle=True)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
# 学习率和优化策略
learning_rate = 1e-3
optimizer = optim.Adam(params=model.parameters(), lr=learning_rate, weight_decay=5e-4)
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.5) # 设置学习率下降策略
# ----------------------------------------------------#
# 训练
# ----------------------------------------------------#
def calculate_accuracy(y_pred, y_true):
_, predicted_labels = torch.max(y_pred, 1)
correct = (predicted_labels == y_true).float()
accuracy = correct.sum() / len(correct)
return accuracy
for epoch in range(epochs):
model.train() # 将模型设置为训练模式
train_epoch_loss = []
train_epoch_accuracy = []
for i, data in enumerate(train_loader, 0):
inputs, labels = data # 获取输入数据和标签
optimizer.zero_grad() # 清零梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels)
loss.backward() # 反向传播和优化
optimizer.step()
# 打印统计信息
# train_epoch_loss.append(loss.item())
# accuracy = calculate_accuracy(outputs, labels)
# train_epoch_accuracy.append(accuracy.item())
#
# train_running_loss = np.average(train_epoch_loss)
# train_running_accuracy = np.average(train_epoch_accuracy)
#
# if i % 10 == 9: # 每10个批次打印一次
# print("--------------------------------------------")
# print(f'Epoch {epoch + 1}, Loss: {train_running_loss}, accuracy: {train_running_accuracy}')
# Validation accuracy
model.eval()
valid_epoch_accuracy = []
with torch.no_grad():
for inputs, labels in validation_loader: # Assuming validation_loader is defined
outputs = model(inputs)
accuracy = calculate_accuracy(outputs, labels)
valid_epoch_accuracy.append(accuracy.item())
# 计算平均精度
valid_running_accuracy = np.average(valid_epoch_accuracy)
print(f'Epoch {epoch + 1}, Validation Accuracy: {valid_running_accuracy:.4f}')
print('Finished Training')
三、总结
在验证集上的分类准确率最高才70%。emmm我猜是数据少。
CSDN: 进行时间序列分类实践–python实战
![[ESP32]在Thonny IDE中,如何將MicroPython firmware燒錄到ESP32開發板中?](https://img-blog.csdnimg.cn/direct/48013f462d3c415da60991e4e32513e2.png)