一、朴素贝叶斯
朴素贝叶斯(Naive Bayes)是基于贝叶斯定理。它测量每个类的概率,每个类的条件概率给出 x 的值。这个算法用于分类问题,得到一个二进制“是 / 非”的结果。看看下面的方程式。
- 先验概率:即基于统计的概率,是基于以往历史经验和分析得到的结果,不需要依赖当前发生的条件。
- 后验概率:则是从条件概率而来,由因推果,是基于当下发生了事件之后计算的概率,依赖于当前发生的条件。
- 条件概率:记事件A发生的概率为P(A),事件B发生的概率为P(B),则在B事件发生的前提下,A事件发生的概率即为条件概率,记为P(A|B),读作“在B条件下A的概率”。
- 联合概率:表示两个事件共同发生的概率。A与B的联合概率表示为P(AB),或者P(A,B),或者P(A∩B)。
二、支持向量机(SVM)
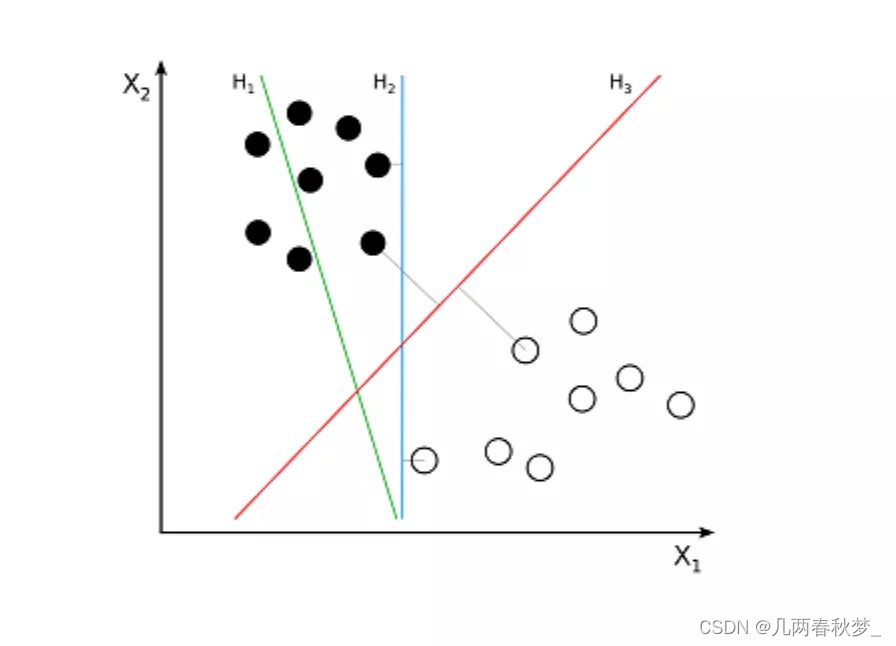
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,SVM可以用于线性和非线性分类问题,回归以及异常值检测
其基本原理是通过在特征空间中找到一个超平面,将不同类别的样本分开,并且使得离超平面最近的样本点到超平面的距离最大化。
超平面与最近的类点之间的距离称为边距。最优超平面具有最大的边界,可以对点进行分类,从而使最近的数据点与这两个类之间的距离最大化。
三、K-最近邻算法(KNN)
KNN 通过在整个训练集中搜索 K 个最相似的实例,即 K 个邻居,并为所有这些 K 个实例分配一个公共输出变量,来对对象进行分类。
当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别

四、随机森林
随机森林(Random Forest)是一种非常流行的集成机器学习算法。这个算法的基本思想是,许多人的意见要比个人的意见更准确。在随机森林中,我们使用决策树集成(参见决策树)。
为了对新对象进行分类,我们从每个决策树中进行投票,并结合结果,然后根据多数投票做出最终决定。

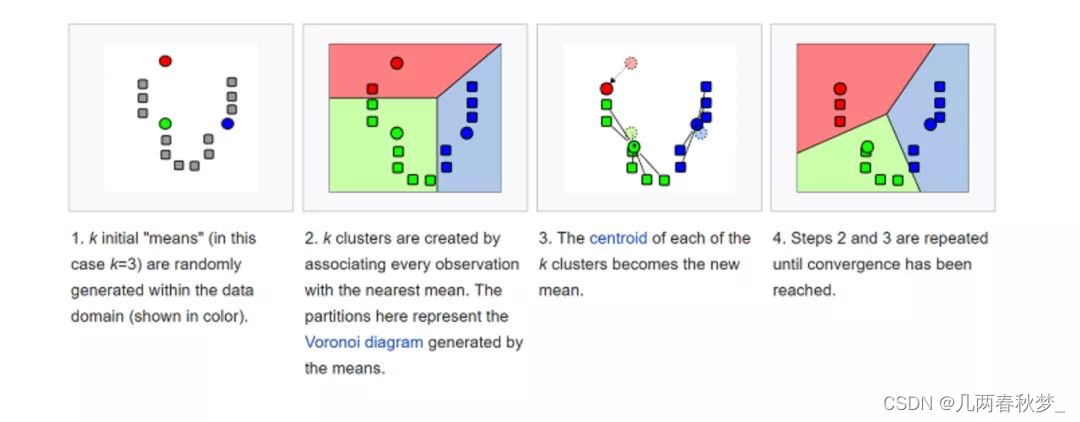
五、K-均值
K- 均值(K-means)是通过对数据集进行分类来聚类的。例如,这个算法可用于根据购买历史将用户分组。它在数据集中找到 K 个聚类。K- 均值用于无监督学习,因此,我们只需使用训练数据 X,以及我们想要识别的聚类数量 K。
该算法根据每个数据点的特征,将每个数据点迭代地分配给 K 个组中的一个组。它为每个 K- 聚类(称为质心)选择 K 个点。基于相似度,将新的数据点添加到具有最近质心的聚类中。