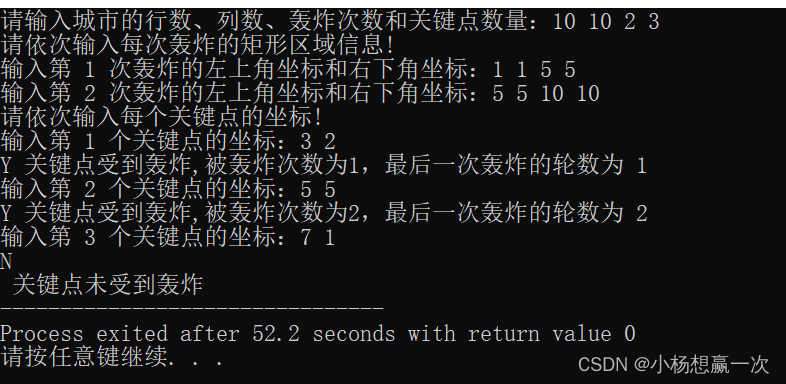
Deconstructing Denoising Diffusion Models for Self-Supervised Learning
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
4. 解构去噪扩散模型
4.1. 用于自监督学习的重新导向 DDM
4.2. 解构分词器
4.3. 迈向经典去噪自动编码器
5. 分析和对比
6. 结论
0. 摘要
在这项研究中,我们研究了去噪扩散模型(Denoising Diffusion Models,DDM)的表示学习(representation learning)能力,这些模型最初是为图像生成而设计的。我们的理念是解构一个DDM,逐渐将其转化为经典的去噪自动编码器(Denoising Autoencoder,DAE)。这个解构过程使我们能够探索现代 DDM 的各个组件如何影响自监督表示学习(self-supervised representation learning,SSRL)。我们观察到,只有很少一部分现代组件对学习良好的表示至关重要,而许多其他组件是非必要的。我们的研究最终得出了一种高度简化的方法,很大程度上类似于经典的 DAE。我们希望我们的研究能重新激发人们对现代自监督学习领域内一类经典方法的兴趣。
最近,人们对检查去噪扩散模型(DDMs)的表示学习能力越来越感兴趣 [40, 28]。具体而言,这些研究直接使用现成的预训练 DDMs [23, 32, 11],这些模型最初是为生成而设计的,然后评估它们在识别方面的表示质量。他们报告使用这些以生成为导向的模型取得了令人鼓舞的结果。然而,这些开创性的研究显然留下了一些问题:这些现成的模型是为生成而设计的,而不是为了识别;表示能力是通过去噪驱动的过程获得的,还是通过扩散驱动的过程,目前仍然不太清楚。
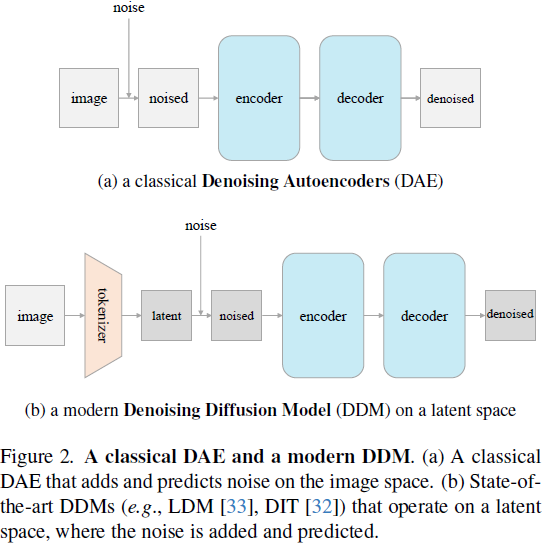

4. 解构去噪扩散模型
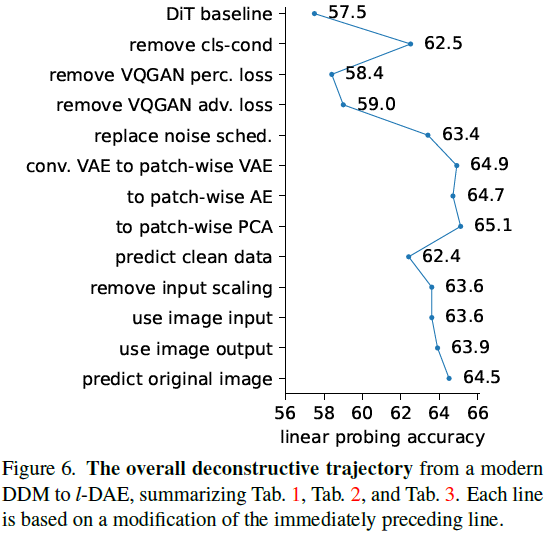
我们的解构轨迹分为三个阶段。
- 第一阶段。我们调整 Diffusion Transformer(DiT)(可在账号历史文章中找到)中以生成为中心的设置,使其更加面向自监督学习。
- 第二阶段。我们逐步解构和简化分词器(tokenizer)的步骤。
- 第三阶段。我们尝试反演尽可能多的 DDM 激发的设计,将模型推向经典的 DAE。
4.1. 用于自监督学习的重新导向 DDM
在 DDM 中,许多设计都是面向生成任务的。一些设计对于自监督学习来说是不合适的(例如,涉及到类标签);还有一些在不涉及视觉质量时是不必要的。通过重新调整 DDM基线,以便用于自监督学习,总结在表 1 中。

移除类别条件显著提高了线性探针准确性,从 57.5% 提高到 62.1%(表1),尽管如预期的那样,生成质量大幅下降(FID 从 11.6 下降到 34.2)。我们假设在模型上加入类别标签会减少模型对与类别标签相关的信息进行编码的需求。移除类别条件可以迫使模型学习更多的语义信息。
解构 VQGAN。在我们的基线中,由 LDM [33] 提出并由 DiT 继承的 VQGAN 分词器(tokenizer)使用多个损失项进行训练:(i) 自编码重建损失;(ii) KL-散度正则化损失 [33]; (iii) 基于 ImageNet 分类的监督预训练 VGG 网络 [35] 的感知损失 [44];和 (iv) 带有鉴别器的对抗损失 [18, 16]。我们在表 1 中去掉了后两项。
由于感知损失 [44] 涉及到一个监督预训练网络,使用以此损失训练的 VQGAN 是不合适的。相反,我们训练了另一个 VQGAN 分词器 [33],在这个分词器中去除了感知损失。使用这个分词器将线性探针的准确性显著降低,从 62.5% 降至 58.4%(表1),然而这提供了到目前为止的第一个合法的实验结果。这个比较表明,使用带有感知损失(带有类别标签)的分词器本身提供了语义表示。我们注意到从现在开始,在本文的剩余部分中将不再使用感知损失。
我们训练下一个 VQGAN 分词器,进一步去除对抗损失。这略微提高了线性探针准确性,从 58.4% 增加到 59.0%(表1)。到此为止,我们的分词器本质上是一个 VAE,我们将在下一个小节中解构它。我们还注意到去除任何一种损失都会损害生成质量。
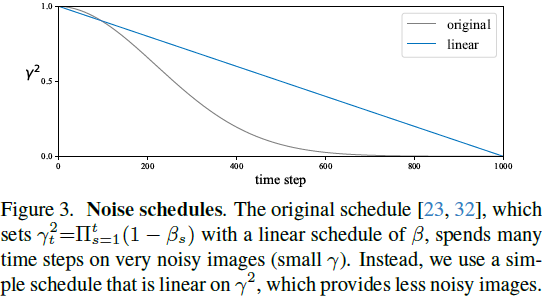
替换噪声计划。在生成任务中,目标是逐步将噪声图转化为图像。因此,原始的噪声计划在许多时间步骤上花费在非常嘈杂的图像上(图 3)。如果我们的模型不以生成为导向,这是不必要的。使用线性计划可以提升线性探测精度(表 1)。
总结。总体而言,表 1 中的结果表明,自监督学习的性能与生成质量没有相关性。DDM 的表示能力不一定是其生成能力的结果。
4.2. 解构分词器
接下来,我们通过进行实质性的简化进一步解构 VAE 分词器。我们比较以下四种自编码器作为分词器的变体,每种都是前一种的简化版本:
- 卷积 VAE(Convolutional VAE):编码器和解码器是深度卷积神经网络。
- 逐 patch VAE(Patch-wise VAE):编码器和解码器都是线性投影,而 VAE 输入是一个 patch。
- 逐 patch VA(Patch-wise AE):移除了 VAE 中的 KL 散度项。因此,这个分词器本质上是一个基于 patch 的 AE,其编码器和解码器都是线性投影。
- 逐 patch(Patch-wise PCA):对 patch 空间执行主成分分析(Principal Component Analysis,PCA)。

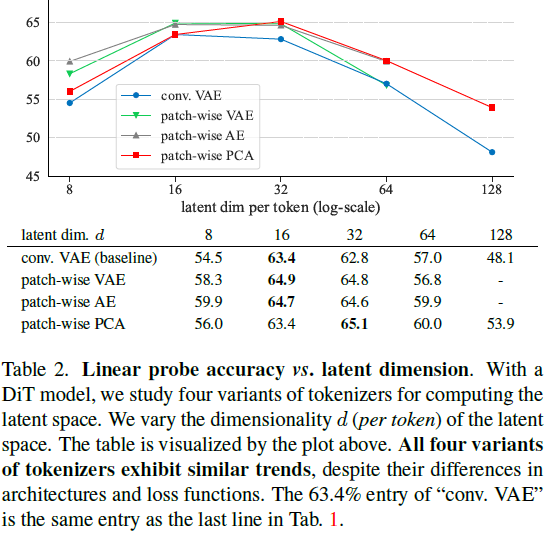
如表 2 所示,尽管它们在架构和损失函数上有所不同,但所有四个分词器变体都表现出类似的趋势。
- 分词器的潜在维度对于DDM在自监督学习中表现良好至关重要。
- 卷积 VAE 分词器既不是必要的,也不是有利的;所有基于 patch 的分词器,始终优于 Conv VAE变体。此外,KL 正则化项是不必要的,因为 AE 和 PCA 变体都表现良好。
- PCA 分词器也表现良好。与 VAE 或 AE 对应物不同,PCA 分词器不需要基于梯度的训练。PCA 分词器的有效性在很大程度上帮助我们将现代 DDM 推向一个经典的 DAE。
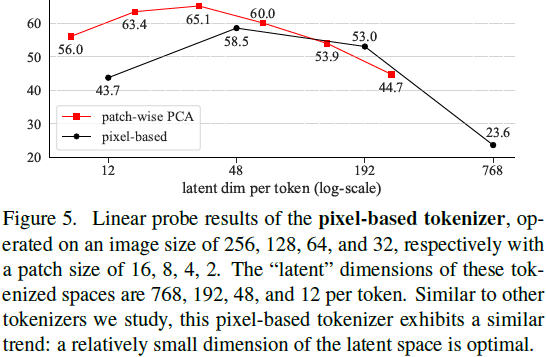
高分辨率、基于像素的 DDM 在自监督学习中表现较差。
4.3. 迈向经典去噪自动编码器
我们继续解构,目标是尽可能接近经典的去噪自动编码器(DAE)[39]。我们尝试去除我们当前基于 PCA 的 DDM 与经典 DAE 实践之间仍然存在的每一个方面。通过这个解构过程,我们更好地理解每个现代设计可能如何影响经典 DAE。接下来将讨论表 3 中的结果。

预测干净数据(而不是噪声)。该修改使线性探针的准确性从 65.1% 降至 62.4%(表 3)。这表明预测目标的选择影响了表示质量。
![]()
移除输入缩放。在现代 DDM 中,输入被因子 γt 缩放(如等式 1 所示)。这在经典 DAE 中不是常见的做法。移除缩放因子后,我们获得了一个不错的准确率,为 63.6%(表 3)。这表明在我们的情况下,通过缩放因子对数据进行缩放是不必要的。
使用逆 PCA 在图像空间操作。到目前为止,对于我们探索的所有实验(除了图 5 之外),模型都在由分词器产生的潜在空间上运行(图2(b))。理想情况下,我们希望我们的 DAE 可以直接在图像空间上运行,同时仍然具有良好的准确性。我们可以通过逆 PCA 实现这个目标。
这个想法在图 1 中得到了说明。具体来说,我们通过 PCA 基将输入图像投影到潜在空间,然后在潜在空间中添加噪声,并通过逆 PCA 基将带有噪潜在投影回图像空间。图1(中间,底部)显示了一个在潜在空间中添加噪声的示例图像。使用这个带有噪声的图像作为网络的输入,我们可以应用一个标准的 ViT 网络 [15],直接在图像上操作,就好像没有分词器一样。
应用这个修改在输入端(仍然在潜在空间上预测输出)的准确率为63.6%(表 3)。进一步应用在输出端(即使用逆 PCA 在图像空间上预测输出)的准确率为63.9%。两个结果都表明,在图像空间上使用逆 PCA 与在潜在空间上操作可以获得类似的结果。
预测原始图像。虽然逆 PCA 可以在图像空间中生成一个预测目标,但该目标并不是原始图像。这是因为 PCA 对于任何降维后的维度 d 都是有损的编码器。相反,直接预测原始图像是一个更自然的解决方案。
当我们让网络预测原始图像时,“噪声”包括两个部分:(i) 加性高斯噪声,其内在维度是 d,(ii) PCA重构误差,其内在维度是 D − d(D 为 768)。我们以不同的权重对这两个部分的损失进行加权。
这个变体在概念上非常简单:其输入是一个在 PCA 潜在空间中添加的噪声的有噪图像,其预测是原始的干净图像(图 1)。采用这个修稿,预测原始图像实现了 64.5% 的线性探针准确性(表3)。
单一噪声水平。最后,出于好奇,我们进一步研究了一种具有单一噪声水平的变体。我们注意到,由噪声调度给出的多级噪声是扩散过程的一个特性;在经典 DAE 中,这在概念上是不必要的。
我们将噪声水平 σ 固定为一个常数。使用这个单一噪声水平实现了 61.5% 的准确性,与多级噪声对应的 64.5% 相比,降低了 3%。使用多级噪声类似于 DAE 中的一种数据增强形式:它是有益的,但不是一个使能因素。这也意味着 DDM 的表示能力主要是通过去噪驱动的过程获得的,而不是通过扩散驱动的过程。
5. 分析和对比

可视化潜在噪声。在概念上,𝑙-DAE 是一种学习去除添加到潜在空间的噪声的 DAE 形式。由于PCA的简单性,我们可以通过逆PCA轻松可视化潜在噪声。
图 7 比较了添加到像素和添加到潜在的噪声。与像素噪声不同,潜在噪声在很大程度上独立于图像的分辨率。使用基于 patch 的 PCA 作为分词器,潜在噪声的模式主要由 patch 大小确定。直观地说,我们可以将其视为使用 patch 而不是像素来解析图像。这种行为类似于 MAE(Masked AE) [21],它掩蔽 patch 而不是单个像素。

去噪结果。图 8 展示了基于 𝑙-DAE 的更多去噪结果的示例。尽管存在大量噪声,我们的方法仍然能够产生合理的预测。
![]()
数据增强。𝑙-DAE 的表示学习能力很大程度上不依赖数据增强。类似的行为在 MAE [21] 中观察到,这与对比学习方法的行为(例如,[6])有很大的不同。
![]()
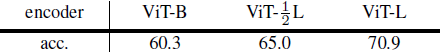

6. 结论
我们报告了 𝑙-DAE,它在很大程度上类似于经典的 DAE,在自监督学习中可以有竞争力的表现。关键组成部分是一个低维的潜在空间,噪声被添加到其中。我们希望我们的发现将重新引起对去噪方法在当今自监督学习研究背景下的兴趣。