目录
一、基本用法
二、函数介绍
1、match函数
2、search 函数
3、compile 函数
4、findall 和 finditer 函数
5、sub 函数和 subn 函数
6、split 函数
一、基本用法
首先我们需要引入 re 库
代码基本框架使用两行代码实现
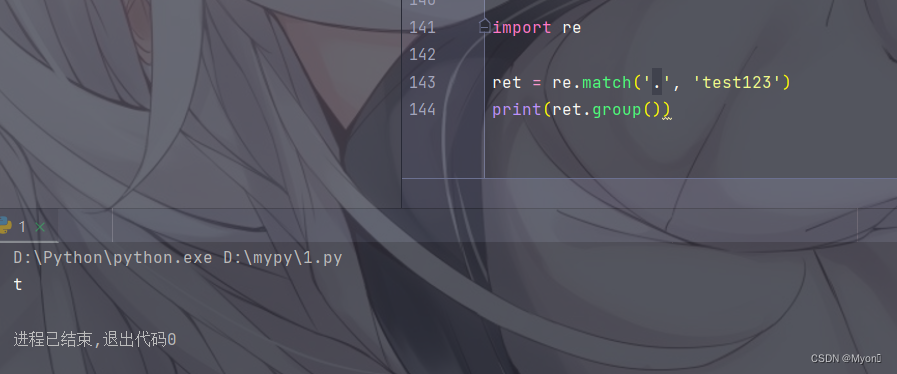
测试代码:
import re
ret = re.match('.', 'test123')
print(ret.group())代码详解:
使用 import 导入 re库;
ret 为自定义的一个变量 (这里称为匹配对象)用于接受返回的匹配信息;
Python中点是调用的意思,调用 re 库下的 match() 函数;
后面我们介绍的函数基本上都有三个参数,我们通常设置前两个就行了,便于大家理解。
match() 函数中第一个参数为正则表达式模式,即我们按照什么样的规则去进行正则匹配,第二个参数为要进行匹配的目标字符串,两者都需要使用引号包裹;
最后使用 print() 函数输出结果,其中 ret 为匹配对象,group() 是匹配对象的一个方法,调用该方法返回匹配到的字符串。
运行结果:
二、函数介绍
我们先讲最基础的用法,后面再介绍一些常用的匹配规则。
1、match函数
用法及参数上面已经介绍
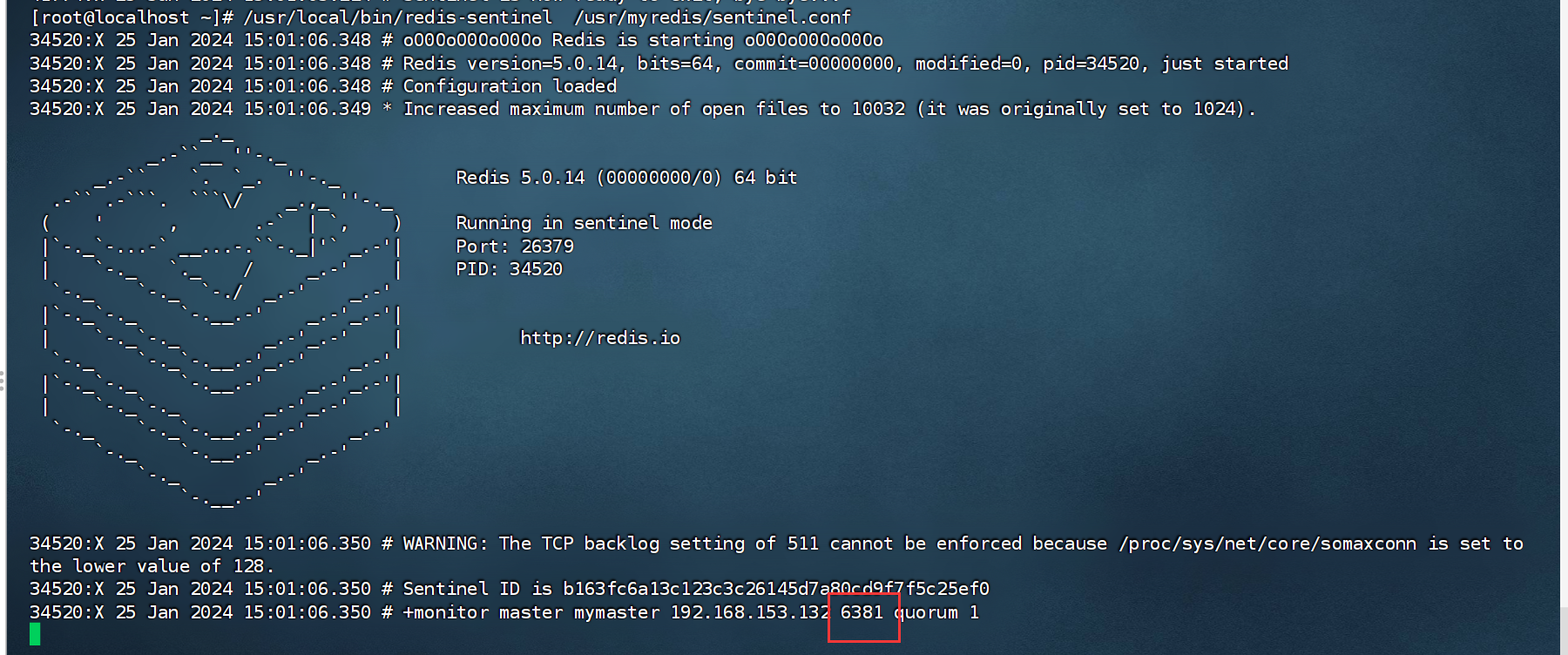
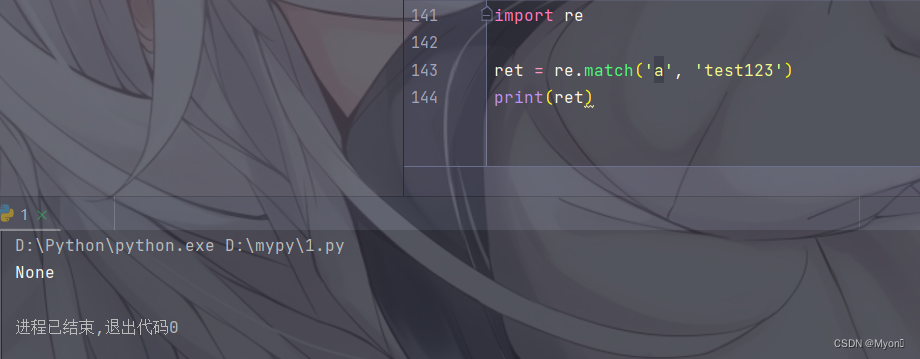
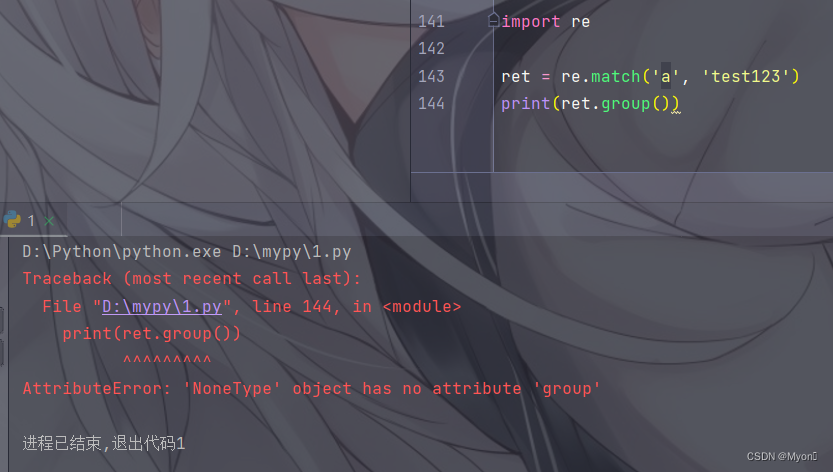
对于 match() 函数,它只会匹配字符串的开头,如果目标字符串的开头匹配正则表达式,re.match() 返回一个匹配对象,否则返回 None(此时如果调用 group() 输出就会报错)。
具体如下图:
尝试在开头匹配字母 a ,由于字符串开头是 t ,因此匹配失败
2、search 函数
扫描整个字符串并返回第一个成功的匹配,如果没有匹配成功,则返回 None。
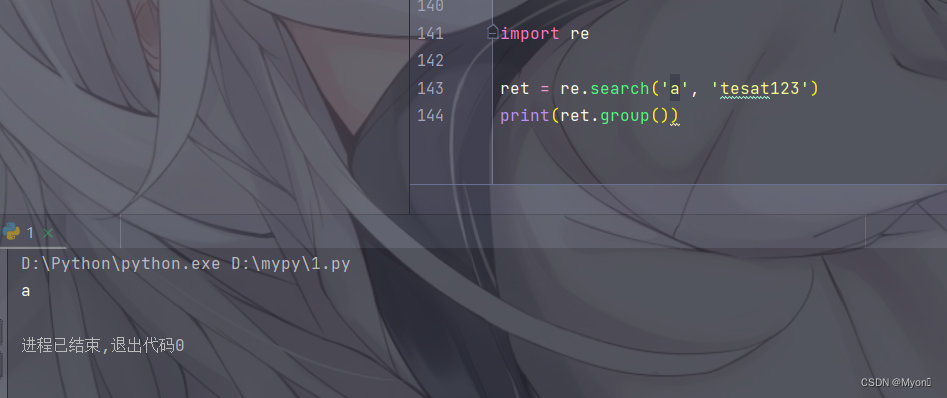
测试代码:
import re
ret = re.search('a', 'tesat123')
print(ret.group())运行结果:
虽然在开头并未匹配到 a ,但是整个字符串中存在 a ,所以也会成功匹配
3、compile 函数
该函数用于编译正则表达式,生成一个正则表达式(Pattern)对象,re.compile 返回一个正则表达式对象,对象具有 match、search、findall 等方法,用于提高匹配效率。
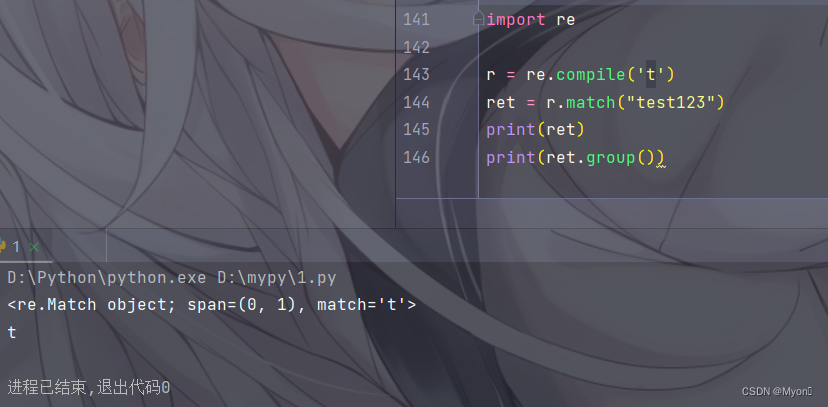
测试代码:
这里以 match 匹配成功为例
import re
r = re.compile('t')
ret = r.match("test123")
print(ret)
print(ret.group())运行结果:
4、findall 和 finditer 函数
re.findall 用于在字符串中找到正则表达式所匹配的所有子串,并返回一个列表;re.finditer 与 re.findall 类似,但返回一个迭代器,我们使用 for 循环读出。
测试代码:
其中 '[\d]' 表示匹配任意一个数字,即 [0-9] 都会匹配成功。
更保险规范的写法是在 '[\d]' 前面加上一个小 r ,即 r '[\d]'
主要是因为我们用到了转义符,加上 r 的话,反斜杠就不会被当做转义符,而是单纯的反斜杠符号
import re
ret = re.findall('[\d]','asd123zxc456qwe789')
print(ret)
ret2 = re.finditer('[\d]', 'asd123zxc456qwe789')
print(ret2)
for i in ret2:
print(i.group())运行结果:

5、sub 函数和 subn 函数
re.sub 函数用于将匹配到的数据进行替换,re.subn 函数与 re.sub 类似,但返回一个元组,包括替换后的字符串和替换次数。
这个函数就一定需要指定三个参数了,分别对应:(正则匹配规则, 要替换的内容, 被替换的内容)
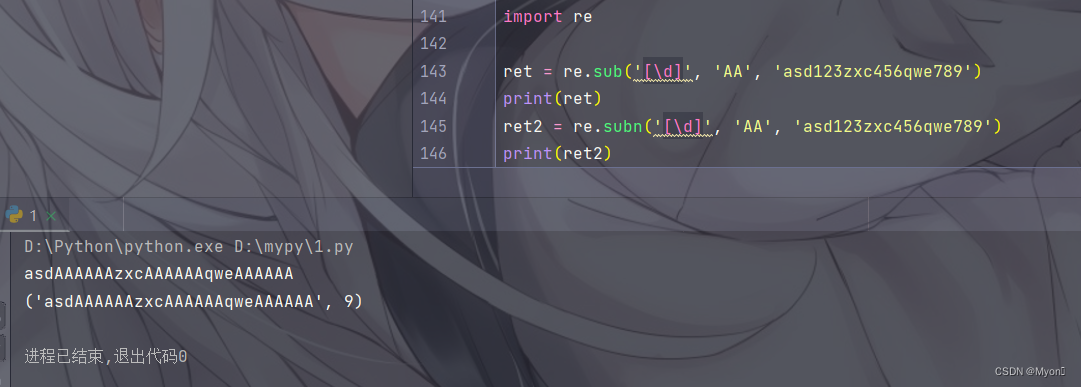
测试代码:
我们匹配数字,将数字都替换为 'AA'
import re
ret = re.sub('[\d]', 'AA', 'asd123zxc456qwe789')
print(ret)
ret2 = re.subn('[\d]', 'AA', 'asd123zxc456qwe789')
print(ret2)运行结果:
在 sunb 函数中,这里替换了 9 个数字,因此返回元组的第二个参数为 9 。
6、split 函数
re.split 函数根据匹配进行切割字符串,并返回一个列表。
split 函数也是有三个参数:('正则匹配规则', '字符串', '分割次数')
分割次数如果不指定,则默认为 0 ,匹配到多少次分割多少次。
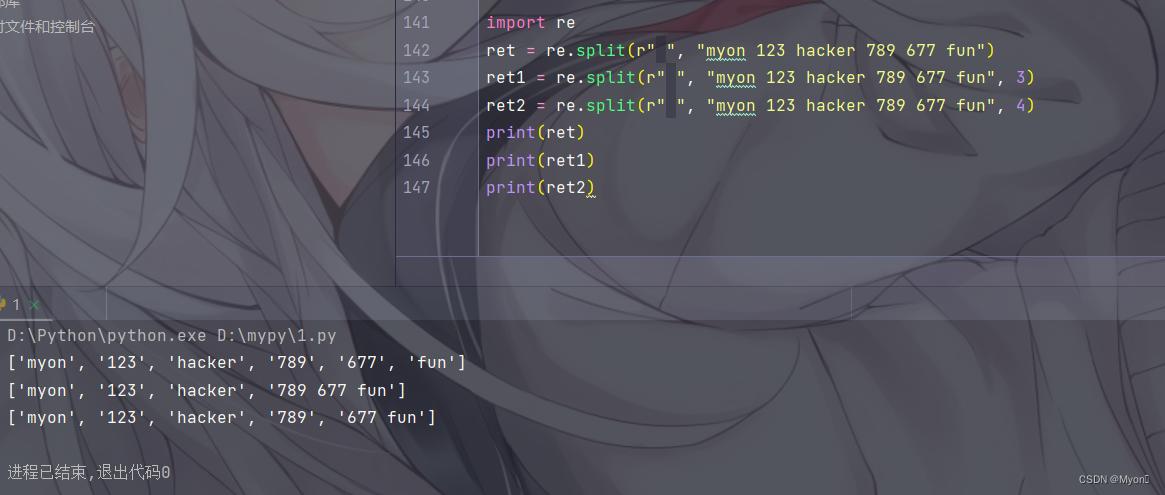
测试代码:
这里匹配空格(匹配到空格的地方我们就分割一次)
import re
ret = re.split(r" ", "myon 123 hacker 789 677 fun")
ret1 = re.split(r" ", "myon 123 hacker 789 677 fun", 3)
ret2 = re.split(r" ", "myon 123 hacker 789 677 fun", 4)
print(ret)
print(ret1)
print(ret2)运行结果:
关于 re 库正则匹配的基本用法以及一些常用方法函数的介绍就是这些
下一篇博客我们将继续介绍 re 库正则匹配常用的匹配规则和一些常见操作
希望上述讲解对大家理解和学习Python有帮助!
期待大家的关注与支持!