大型语言模型 (LLM) 的兴起一直是自然语言处理 (NLP) 领域的一个决定性趋势,导致它们在各种应用程序中的广泛采用。然而,这种进步往往是排他性的,大多数由资源丰富的组织开发的 LLM 仍然无法向公众开放。
这种排他性提出了一个重要的问题:如果有一种方法可以使对这些强大的语言模型的访问民主化,那会怎样?这就是 BLOOM 出现的原因。
本文首先提供了有关其起源的更多详细信息,从而全面概述了 BLOOM 是什么。然后,它介绍了 BLOOM 的技术规范以及如何使用它,然后强调了它的局限性和道德考虑。
什么是BLOOM?
BigScience 大型开放科学开放获取多语言模型(简称 BLOOM)代表了语言模型技术民主化的重大进步。
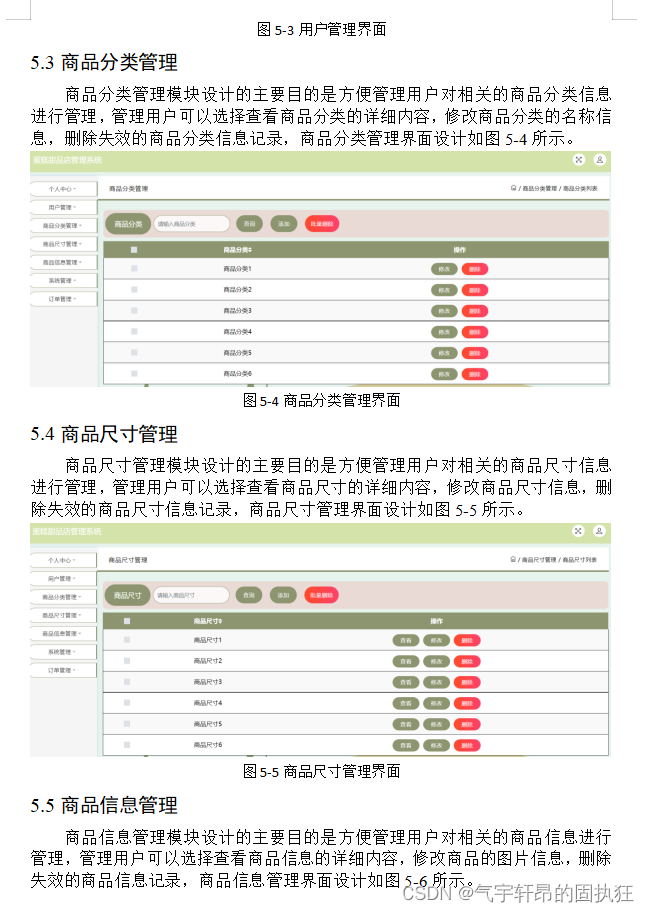
BLOOM由来自39个国家的1200多名参与者共同开发,是全球努力的产物。该项目由 BigScience 与 Hugging Face 和法国 NLP 社区合作协调,超越了地理和机构的界限。
它是一个开源的、仅解码器的转换器模型,具有 176B 参数,在 ROOTS 语料库上训练,该语料库是 59 种语言的数百个来源的数据集:46 种口语和 13 种编程语言。
下面是训练语言分布的饼图。
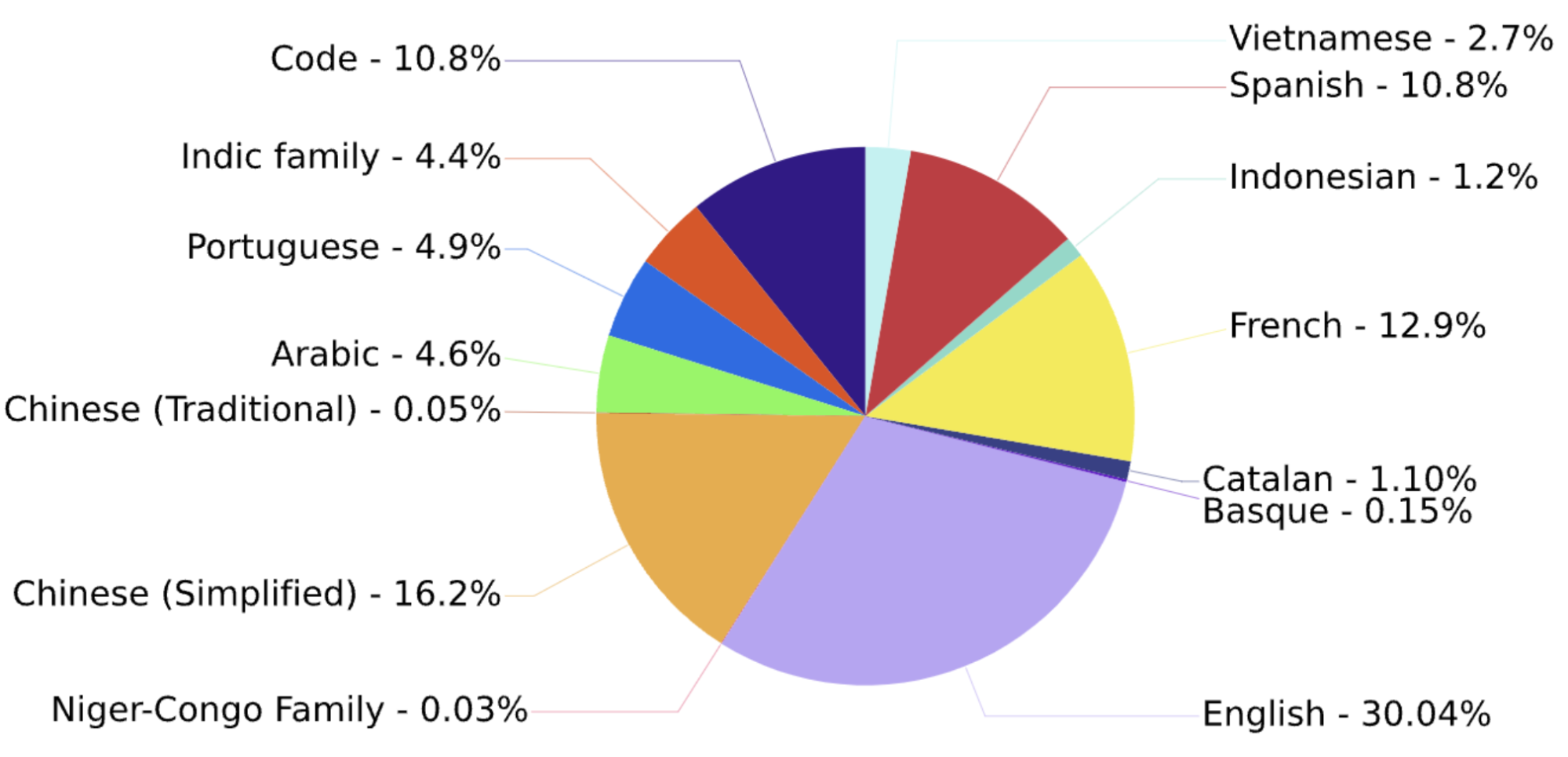
训练语言的分布
该模型被发现在各种基准测试中都取得了显着的性能,并且在多任务提示微调后获得了更好的结果。
该项目在巴黎的Jean Zay超级计算机上进行了为期117天(3月11日至7月6日)的培训课程,并得到了法国研究机构CNRS和GENCI的大量计算资助。
BLOOM不仅是一个技术奇迹,也是国际合作和集体科学追求力量的象征。
BLOOM 模型架构
现在,让我们更详细地描述一下 BLOOM 的架构,它涉及多个组件。
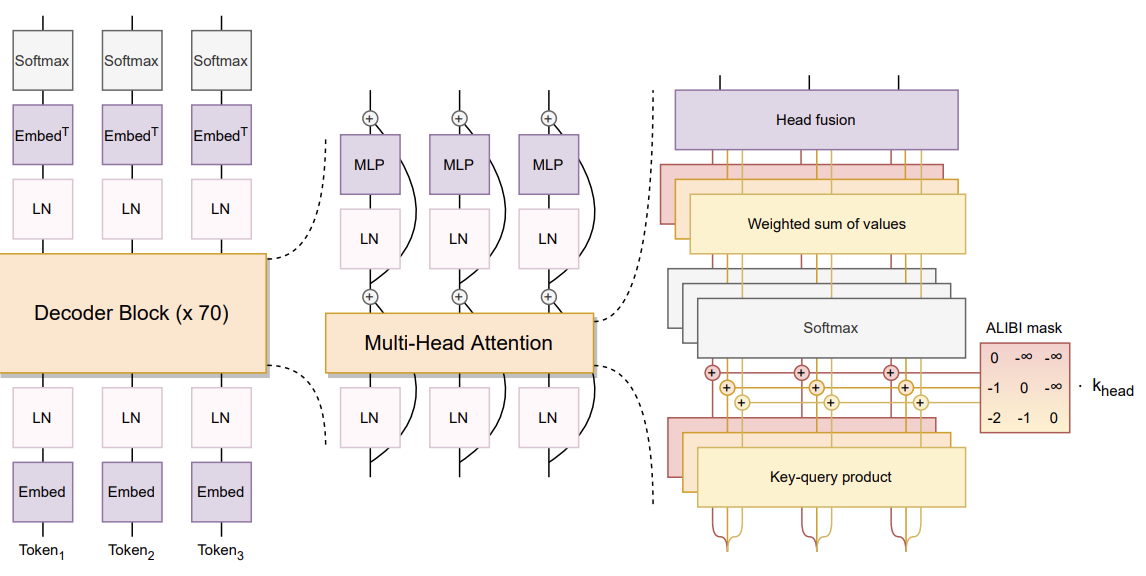
Bloom 架构
如本文所述,BLOOM 模型的架构包括几个值得注意的方面:
- 设计方法: 该团队专注于支持公开可用工具和代码库的可扩展模型系列,并在较小的模型上进行了消融实验,以优化组件和超参数。零样本泛化是评估架构决策的关键指标。
- 架构和预训练目标:BLOOM 基于 Transformer 架构,特别是仅因果解码器模型。与编码器-解码器和其他仅解码器架构相比,这种方法被验证为零样本泛化功能最有效的方法。
- 建模细节:
- ALiBi 位置嵌入:ALiBi 之所以选择传统的位置嵌入,是因为它根据按键和查询之间的距离直接削弱注意力分数。这导致了更顺畅的训练和更好的表现。
- 嵌入 LayerNorm: 在嵌入层之后立即包含额外的层归一化,这提高了训练稳定性。这一决定在一定程度上受到在最终训练中使用 bfloat16 的影响,它比 float16 更稳定。
这些组件反映了团队专注于平衡创新与成熟技术,以优化模型的性能和稳定性。
除了 BLOOM 的架构组件之外,让我们了解另外两个相关组件:数据预处理和提示数据集。
- 数据预处理:这涉及重复数据删除和隐私编辑等关键步骤,特别是对于隐私风险较高的来源。
- 提示数据集:BLOOM采用多任务提示微调,显示出强大的零样本任务泛化能力。
如何使用 BLOOM
在此示例中,我们将使用 BLOOM 生成创意故事。提供的代码结构用于设置环境、准备模型并根据给定提示生成文本。相应的源代码可在 GitHub 上找到,它在很大程度上受到了 amrrs 教程的启发。
配置工作区
BLOOM 模型是资源密集型的,因此正确配置工作区至关重要,主要步骤如下所述。
首先,Transformer 库用于提供用于处理 BLOOM 模型和其他基于 transformer 的节点的接口。
pip install transformers -q使用 nvidia-smi,我们检查可用 GPU 的属性,以确保我们拥有运行模型所需的计算资源
nvidia-smi
我们从 transformers 和 torch 中导入所需的模块。torch 用于设置默认张量类型以利用 GPU 加速。
然后,由于我们使用的是 GPU,因此使用 set_default_tensor_type 函数设置 torch 库以确保使用 GPU。
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
import torch
torch.set_default_tensor_type(torch.cuda.FloatTensor)使用 BLOOM 模型
正在使用的目标模型是 70 亿参数的 BLOOM 模型,可以从 bigscience/bloom-1b7 下的 BigScience 的 Hubbing Face 存储库访问它,该存储库对应于模型的唯一标识符。
model_ID = "bigscience/bloom-1b7"接下来,我们从 Hugging Face 加载预训练的 BLOOM 模型和分词器,并使用具有任意数字的 set_seed 函数为可重复性设置种子。数字本身的值并不重要,但使用非浮动值很重要。
model = AutoModelForCausalLM.from_pretrained(model_ID, use_cache=True)
tokenizer = AutoTokenizer.from_pretrained(model_ID)
set_seed(2024)现在,我们可以定义要生成的故事的标题以及提示。
story_title = 'An Unexpected Journey Through Time'
prompt = f'This is a creative story about {story_title}.\n'最后,我们将提示标记化并映射到适当的模型设备,然后在解码后生成模型的结果。
input_ids = tokenizer(prompt, return_tensors="pt").to(0)
sample = model.generate(**input_ids,
max_length=200, top_k=1,
temperature=0, repetition_penalty=2.0)
generated_story = tokenizer.decode(sample[0], skip_special_tokens=True)最终结果使用 textwrap 模块进行格式化,以确保每行的最大字符数为 80 个,以提高可读性。
import textwrap
wrapper = textwrap.TextWrapper(width=80)import textwrap
wrapper = textwrap.TextWrapper(width=80)最终结果如下:
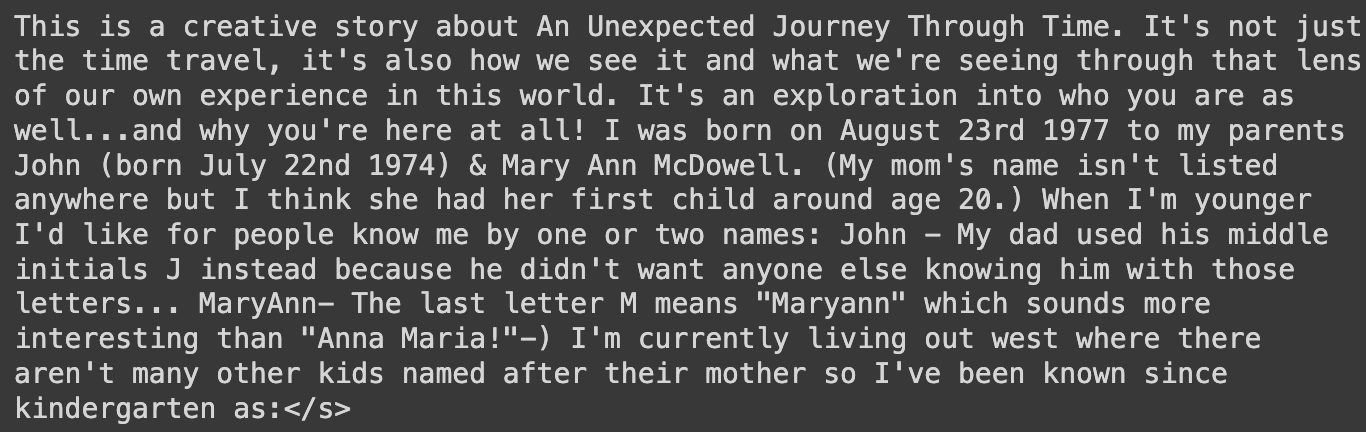
使用 BLOOM 模型生成的故事
只需几行代码,我们就能够使用 BLOOM 模型生成有意义的内容。
预期用途和范围外用途
像所有技术进步一样,BLOOM也有自己的一套合适和不合适的应用程序。本节深入探讨了其适当和不适当的用例,重点介绍了哪些方面可以最好地利用其功能,哪些地方建议谨慎行事。了解这些界限对于负责任和有效地利用 BLOOM 的潜力至关重要。
BLOOM的预期用途
BLOOM 是一个多功能工具,旨在突破语言处理和生成的界限。它的预期用途跨越各个领域,每个领域都利用其广泛的语言功能。
- 多语言内容生成:BLOOM 精通 59 种语言,擅长创造多样化和包容性的内容。这种能力在全球传播、教育和媒体中尤为重要,在这些领域,语言包容性至关重要。
- 编码和软件开发:BLOOM在编程语言方面的培训将其定位为软件开发的资产。它可以协助完成代码生成、调试等任务,并作为新程序员的教育工具。
- 研究与学术: 在学术界,BLOOM 是语言分析和 AI 研究的强大资源,提供对语言模式、AI 行为等的见解。
超出 BLOOM 的范围使用
了解 BLOOM 的局限性对于确保其合乎道德和实际应用至关重要。一些用例超出了 BLOOM LLM 的适用范围,主要是出于道德考虑或技术限制。
- 敏感数据处理:BLOOM 并非专为处理敏感个人数据或机密信息而设计。此类数据可能侵犯隐私或滥用,因此不适合用于这些目的。
- 高风险决策:不建议在需要关键准确性的场景中使用 BLOOM,例如医疗诊断或法律决策。与大多数大型语言模型一样,该模型的局限性可能会导致这些敏感领域的不准确或误导性结果。
- 人机交互替代:BLOOM不应被视为人际互动的替代品,尤其是在需要情商的领域,如咨询、外交或个性化教学。该模型缺乏人类互动提供的细致入微的理解和同理心。
直接和间接用户
BLOOM 作为一种先进的大型语言模型 (LLM),提供了广泛的优势,可以扩展到各种用户群。它的能力不仅直接影响某些专业人士和部门,而且具有更广泛的影响,间接影响更广泛的利益相关者。
对 BLOOM 用户的探索旨在强调不同群体如何利用这一创新工具并受到其影响。
通过了解 BLOOM 的直接和间接用户,我们可以欣赏该模型的广泛影响力以及它为推动技术和社会进步做出贡献的多种方式。
BLOOM的直接用户
- 开发人员和数据科学家:软件开发和数据科学领域的专业人士是主要用户。他们利用 BLOOM 完成编码辅助、调试和数据分析等任务。
- 研究人员和学者:该小组包括语言学家、人工智能研究人员和学者,他们使用 BLOOM 进行语言研究、人工智能行为分析和推进 NLP 研究。
- 内容创作者和翻译人员: 作家、记者和翻译人员使用 BLOOM 生成和翻译不同语言的内容,从而提高他们的工作效率和影响力。
BLOOM的间接用户
- 企业和组织: 各行各业的公司通过增强的人工智能驱动服务、改进的客户互动和高效的数据处理,间接受益于 BLOOM。
- 教育机构:学生和教育工作者通过教育工具和资源间接体验 BLOOM 的好处,这些工具和资源结合了其语言处理能力进行学习和教学。
- 公众:更广泛的社区通过改进的技术体验、访问多语言内容和增强的软件应用程序成为 BLOOM 的间接受益者。
道德考虑和限制
与任何大型语言模型 (LLM) 一样,BLOOM 的部署会带来一系列伦理方面的考虑和限制。这些方面对于了解负责任的使用和预测该技术的更广泛影响至关重要。本节介绍与使用 BLOOM 相关的伦理影响、风险和固有限制。
道德考量
- 数据偏差和公平性: 主要的伦理问题之一是 BLOOM 有可能延续或放大其训练数据中存在的偏见。这可能会影响其输出的公平性和中立性,从而在公正处理至关重要的情况下导致道德挑战。
- 隐私问题:虽然 BLOOM 没有明确设计用于处理敏感的个人信息,但其庞大的训练数据可能会无意中包含此类信息。如果 BLOOM 基于敏感数据生成输出或泄露敏感数据,则存在侵犯隐私的风险。
与使用相关的风险
- 错误信息和操纵: BLOOM 的高级功能可能会被滥用于生成误导性信息或操纵性内容,从而在媒体、政治和舆论等领域构成重大风险。
- 依赖和技能退化:过度依赖 BLOOM 来完成内容创作或翻译等任务可能会导致人类这些技能的退化,从而影响创造力和语言能力。
BLOOM的局限性
- 上下文理解:尽管 BLOOM 很复杂,但它可能缺乏某些任务所需的深刻背景和文化理解,导致在细微的场景中出现不准确或不适当的输出。
- 语言的演变性质: BLOOM在静态数据集上的训练意味着它可能无法跟上语言不断发展的步伐,包括新的俚语、术语或文化参考。
现实世界的影响和争议
BLOOM 的开发和发布在现实世界中具有重大影响,无论是在其影响方面还是在它引发的争议方面。本节以 BLOOM 研究论文的见解为基础,讨论了这些方面。
BLOOM对现实世界的影响
- 人工智能技术的民主化:BLOOM代表了人工智能技术民主化的一步。BLOOM 由 BigScience 开发,是一项涉及来自 38 个国家/地区的 1200 多人的协作成果,是一个开放获取模型,在涵盖 59 种语言的多样化语料库上进行训练。这种广泛的参与和可访问性标志着大型语言模型开发中通常出现的排他性的转变。
- 多样性和包容性: 该项目对语言、地理和科学多样性的承诺是值得注意的。用于训练 BLOOM 的 ROOTS 语料库涵盖了广泛的语言和编程语言,反映了对 AI 开发中包容性和代表性的重视
争议和挑战
- 社会和道德问题: BLOOM的开发承认了大型语言模型开发中的社会局限性和伦理挑战。BigScience 研讨会采用了道德宪章来指导该项目,强调包容性、多样性、开放性、可重复性和责任感。这些原则被整合到项目的各个方面,从数据集管理到模型评估。
- 环境和资源问题: 由于需要大量的计算资源,像BLOOM这样的大型语言模型的开发引起了环境问题。这些模型的训练通常只有资源丰富的组织才能负担得起,但对能源消耗和碳足迹有影响
BLOOM在今天仍然适用吗?
在快节奏的人工智能 (AI) 世界中,像 BLOOM 这样的大型语言模型 (LLM) 的相关性是一个持续讨论的话题。
BLOOM由庞大的国际研究人员团队开发,是语言处理领域的重大飞跃。然而,人工智能领域在不断发展,新模型的出现并转移了焦点。
让我们来看看 BLOOM 是否仍然在这个竞争激烈的领域站稳脚跟。
- 焦点转移:BLOOM最初是一个重大突破,现在发现自己处于新模型的阴影下。与 ChatGPT 等对话式 AI 不同,BLOOM 是为内容完成而不是交互式交流量身定制的。
- 硬件限制: 与 GPT-3.5 和 GPT4 等更用户友好的 LLM 相比,BLOOM 的高硬件需求限制了其可访问性,后者更容易集成到各种应用程序中。
- 日益激烈的竞争: 像 LLaMA 这样的模型和 Alpaca 这样的工具的出现使 LLM 的访问民主化,以更少的资源需求提供功能,从而扩大了它们的吸引力和使用。
- 多语言能力:BLOOM的独特卖点是其对多种语言的广泛培训,使其成为翻译和多语言内容创作的宝贵资源。
结论
本文概述了 BLOOM 项目,该项目对不断发展的大型语言模型领域做出了重大贡献。
我们探讨了 BLOOM 的发展,重点介绍了其技术规格及其创建背后的合作。该文章还作为访问和有效利用 BLOOM 的指南,强调了其适当的用途和局限性。
此外,它还涵盖了 BLOOM AI 项目的伦理影响和现实世界影响,反映了其在当今 AI 领域的接受度和相关性。无论您是直接参与 AI 还是爱好者,对 BLOOM 的探索都为驾驭大型语言模型的复杂世界提供了重要的视角。