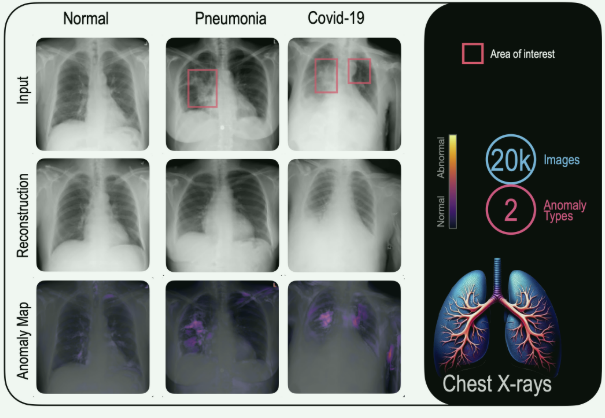
FastDeploy是一款全场景、易用灵活、极致高效的AI推理部署工具, 支持云边端部署。提供超过 🔥160+ Text,Vision, Speech和跨模态模型📦开箱即用的部署体验,并实现🔚端到端的推理性能优化。包括 物体检测、字符识别(OCR)、人脸、人像扣图、多目标跟踪系统、NLP、Stable Diffusion文图生成、TTS 等几十种任务场景,满足开发者多场景、多硬件、多平台的产业部署需求。

1、FastDeploy支持的环境
1.1 芯片支持
FastDeploy支持各个常见的硬件平台和各种国产化的芯片。例如华为的ascend

| X86_64 CPU | | ||||||
| NVDIA GPU | |||||||
| 飞腾 CPU | |||||||
| 昆仑芯 XPU | |||||||
| 华为昇腾 NPU | |||||||
| Graphcore IPU | |||||||
| 算能 | |||||||
| Intel 显卡 | |||||||
| Jetson | |||||||
| ARM CPU | |||||||
| RK3588等 | |||||||
| RV1126等 | |||||||
| 晶晨 | |||||||
| 恩智浦 |
1.2 编程语言支持
FastDeploy支持python、c++、java等开发语言,同时还支持web与小程序部署。
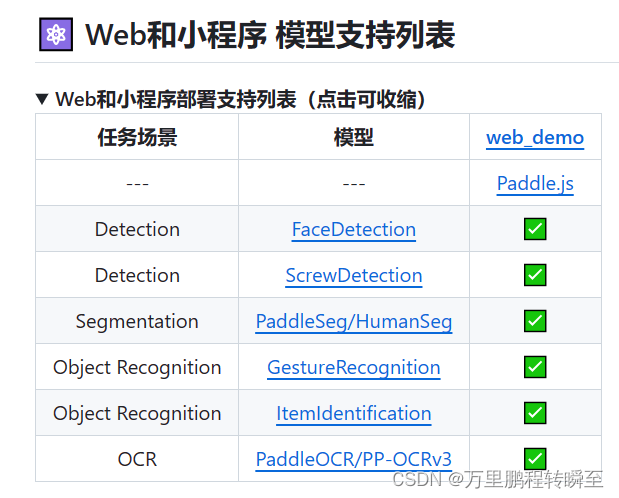
1.3 操作系统支持
FastDeploy支持linux、windows、mac、安卓部署。

1.4 推理后端支持
FastDeploy对各种推理后端接口均做了封装,可以以一种代码风格同时调用onnx、paddle infer、tensorrt、openvino等推理框架。

2、安装与使用
本博文对应的代码和模型资源可以进行付费下载,也可以参考博文资料轻松实现复现。
2.1 安装命令
🔸 前置依赖
- CUDA >= 11.2、cuDNN >= 8.0、Python >= 3.6
- OS: Linux x86_64/macOS/Windows 10
🔸 安装GPU版本
pip install numpy opencv-python fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
🔸 Conda安装(推荐✨)
conda config --add channels conda-forge && conda install cudatoolkit=11.2 cudnn=8.2
🔸 安装CPU版本
pip install numpy opencv-python fastdeploy-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
最终安装成功的输出如下所示
2.2 部署图像分类模型
下载paddle官方的预训练模型,https://bj.bcebos.com/paddlehub/fastdeploy/ResNet50_vd_infer.tgz,也可以使用自己基于paddleclas训练的模型
将以下图片保存为000000014439.jpg

预测代码如下所示,使用onnxruntime-gpu进行推理
# GPU/TensorRT部署参考 examples/vision/detection/paddledetection/python
import cv2
import fastdeploy as fd
import fastdeploy.vision as vision
import ipdb
option = fd.RuntimeOption()
#option.use_trt_backend()
option.use_gpu(device_id=0) #使用0号gpu进行预测
option.use_ort_backend() #使用onnxruntime作为后端
model_file="ResNet50_vd_infer/inference.pdmodel"
params_file="ResNet50_vd_infer/inference.pdiparams"
config_file="ResNet50_vd_infer/inference_cls.yaml"
model = fd.vision.classification.PaddleClasModel(
model_file, params_file, config_file, runtime_option=option)
im = cv2.imread("000000014439.jpg")
result = model.predict(im, topk=5)
print(type(result),dir(result))
print(result)
程序运行后输出如下所示:
[INFO] fastdeploy/vision/common/processors/transform.cc(93)::fastdeploy::vision::FuseNormalizeHWC2CHW Normalize and HWC2CHW are fused to NormalizeAndPermute in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::fastdeploy::vision::FuseNormalizeColorConvert BGR2RGB and NormalizeAndPermute are fused to NormalizeAndPermute with swap_rb=1
[INFO] fastdeploy/runtime/runtime.cc(300)::fastdeploy::Runtime::CreateOrtBackend Runtime initialized with Backend::ORT in Device::GPU.
<class 'fastdeploy.libs.fastdeploy_main.vision.ClassifyResult'> ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', 'feature', 'label_ids', 'scores']
ClassifyResult(
label_ids: 701, 879, 417, 645, 723,
scores: 0.424514, 0.084369, 0.058738, 0.016847, 0.013349,
)
从以上输出中可以看到,预测结果又’feature’, ‘label_ids’, 'scores’三个属性。
2.2 部署目标检测模型
下载paddle官方的预训练模型,也可以使用自己导出的paddle infer模型。
https://bj.bcebos.com/paddlehub/fastdeploy/ppyoloe_crn_l_300e_coco.tgz
将以下图片保存为000000014439.jpg
预测代码如下所示
# GPU/TensorRT部署参考 examples/vision/detection/paddledetection/python
import cv2
import fastdeploy.vision as vision
model = vision.detection.PPYOLOE("ppyoloe_crn_l_300e_coco/model.pdmodel",
"ppyoloe_crn_l_300e_coco/model.pdiparams",
"ppyoloe_crn_l_300e_coco/infer_cfg.yml")
im = cv2.imread("000000014439.jpg")
result = model.predict(im)
print(result)
vis_im = vision.vis_detection(im, result, score_threshold=0.5)
cv2.imshow("vis_image.jpg", vis_im)
cv2.waitKey()
#cv2.imwrite("vis_image.jpg", vis_im)
程序运行时的输出如下所示,可见默认是使用OPENVINO cpu进行推理。其返回结果为DetectionResult对象,其一共有’boxes’, ‘contain_masks’, ‘label_ids’, ‘masks’, ‘rotated_boxes’, 'scores’等属性。其中boxes是xmin, ymin, xmax, ymax,格式的数据,其默认只返回nms操作后的top 300个结果,后续需要自己根据scores进行结果过滤。
[INFO] fastdeploy/vision/common/processors/transform.cc(45)::fastdeploy::vision::FuseNormalizeCast Normalize and Cast are fused to Normalize in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(93)::fastdeploy::vision::FuseNormalizeHWC2CHW Normalize and HWC2CHW are fused to NormalizeAndPermute in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::fastdeploy::vision::FuseNormalizeColorConvert BGR2RGB and NormalizeAndPermute are fused to NormalizeAndPermute with swap_rb=1
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(218)::fastdeploy::OpenVINOBackend::InitFromPaddle number of streams:1.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(228)::fastdeploy::OpenVINOBackend::InitFromPaddle affinity:YES.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(240)::fastdeploy::OpenVINOBackend::InitFromPaddle Compile OpenVINO model on device_name:CPU.
[INFO] fastdeploy/runtime/runtime.cc(286)::fastdeploy::Runtime::CreateOpenVINOBackend Runtime initialized with Backend::OPENVINO in Device::CPU.
DetectionResult: [xmin, ymin, xmax, ymax, score, label_id]
415.047180,89.311569, 506.009613, 283.863098, 0.950423, 0
163.665710,81.914932, 198.585342, 166.760895, 0.896433, 0
581.788635,113.027618, 612.623474, 198.521713, 0.842596, 0
267.217224,89.777306, 298.796051, 169.361526, 0.837951, 0
104.465584,45.482422, 127.688850, 93.533867, 0.773348, 0
348.902130,44.059338, 367.541687, 98.403542, 0.767127, 0
363.889740,58.385532, 381.397522, 114.652367, 0.756467, 0
504.843811,114.531601, 612.280945, 271.292572, 0.714129, 0
2.4 部署语义分割模型
下载paddle发布的预训练模型SegFormer_B0,也可以使用paddleseg训练后导出模型。
https://bj.bcebos.com/paddlehub/fastdeploy/ppyoloe_crn_l_300e_coco.tgz
将以下图片保存为000000014439.jpg
预测代码如下所示
# GPU/TensorRT部署参考 examples/vision/detection/paddledetection/python
import cv2
import fastdeploy as fd
import fastdeploy.vision as vision
import numpy as np
import ipdb
def get_color_map_list(num_classes):
"""
Args:
num_classes (int): number of class
Returns:
color_map (list): RGB color list
"""
color_map = num_classes * [0, 0, 0]
for i in range(0, num_classes):
j = 0
lab = i
while lab:
color_map[i * 3] |= (((lab >> 0) & 1) << (7 - j))
color_map[i * 3 + 1] |= (((lab >> 1) & 1) << (7 - j))
color_map[i * 3 + 2] |= (((lab >> 2) & 1) << (7 - j))
j += 1
lab >>= 3
color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
return color_map
color_map=get_color_map_list(80) #80个类别
color_map=np.array(color_map).astype(np.uint8)
option = fd.RuntimeOption()
#option.use_kunlunxin() #使用昆仑芯片进行部署
#option.use_lite_backend()
option.use_paddle_infer_backend()
model_file="SegFormer_B0-cityscapes-with-argmax/model.pdmodel"
params_file="SegFormer_B0-cityscapes-with-argmax/model.pdiparams"
config_file="SegFormer_B0-cityscapes-with-argmax/deploy.yaml"
model = fd.vision.segmentation.PaddleSegModel(
model_file, params_file, config_file, runtime_option=option)
im = cv2.imread("000000014439.jpg")
result = model.predict(im)
print(type(result),dir(result))
print(result)
#ipdb.set_trace()
res=np.array(result.label_map,np.uint8)
res=res.reshape(result.shape)
res=color_map[res] #为结果上色
cv2.imshow("label_map",res)
cv2.waitKey()
代码运行时输出如下所示:
[INFO] fastdeploy/vision/common/processors/transform.cc(93)::fastdeploy::vision::FuseNormalizeHWC2CHW Normalize and HWC2CHW are fused to NormalizeAndPermute in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::fastdeploy::vision::FuseNormalizeColorConvert BGR2RGB and NormalizeAndPermute are fused to NormalizeAndPermute with swap_rb=1
WARNING: Logging before InitGoogleLogging() is written to STDERR
W0125 21:32:56.195503 5356 analysis_config.cc:971] It is detected that mkldnn and memory_optimize_pass are enabled at the same time, but they are not supported yet. Currently, memory_optimize_pass is explicitly disabled
[INFO] fastdeploy/runtime/runtime.cc(273)::fastdeploy::Runtime::CreatePaddleBackend Runtime initialized with Backend::PDINFER in Device::CPU.
<class 'fastdeploy.libs.fastdeploy_main.vision.SegmentationResult'> ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', 'contain_score_map', 'label_map', 'score_map', 'shape']
SegmentationResult Image masks 10 rows x 10 cols:
[4, 4, 4, 4, 4, 2, 2, 2, 2, 2, .....]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, .....]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, .....]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, .....]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, .....]
[2, 2, 2, 2, 2, 2, 2, 4, 4, 4, .....]
[4, 4, 4, 4, 4, 4, 4, 4, 4, 4, .....]
[4, 4, 2, 2, 2, 2, 2, 2, 2, 2, .....]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, .....]
[2, 2, 2, 2, 2, 2, 2, 2, 2, 2, .....]
...........
result shape is: [404 640]
运行效果如下所示

2.5 部署文本识别模型
进行全流程文本识别
首先下载以下模型,可以手动打开http链接进行下载。
下载PP-OCRv3文字检测模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
tar -xvf ch_PP-OCRv3_det_infer.tar
下载文字方向分类器模型
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
tar -xvf ch_ppocr_mobile_v2.0_cls_infer.tar
下载PP-OCRv3文字识别模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
tar -xvf ch_PP-OCRv3_rec_infer.tar
准备label文件
下载ppocr_keys_v1.txt,保存到代码目录下。
准备测试文件
将以下图片保存为12.jpg 
测试代码如下所示;
# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import fastdeploy as fd
import cv2
import os
def parse_arguments():
import argparse
import ast
parser = argparse.ArgumentParser()
parser.add_argument(
"--det_model", default="ch_PP-OCRv3_det_infer", help="Path of Detection model of PPOCR.")
parser.add_argument(
"--cls_model",default="ch_ppocr_mobile_v2.0_cls_infer",
help="Path of Classification model of PPOCR.")
parser.add_argument(
"--rec_model",default="ch_PP-OCRv3_rec_infer",
help="Path of Recognization model of PPOCR.")
parser.add_argument(
"--rec_label_file",
default="ppocr_keys_v1.txt",
help="Path of Recognization model of PPOCR.")
parser.add_argument(
"--image", type=str, default="12.jpg", help="Path of test image file.")
parser.add_argument(
"--device",
type=str,
default='cpu',
help="Type of inference device, support 'cpu' or 'gpu'.")
parser.add_argument(
"--device_id",
type=int,
default=0,
help="Define which GPU card used to run model.")
parser.add_argument(
"--cls_bs",
type=int,
default=1,
help="Classification model inference batch size.")
parser.add_argument(
"--rec_bs",
type=int,
default=6,
help="Recognition model inference batch size")
parser.add_argument(
"--backend",
type=str,
default="openvino",
help="Type of inference backend, support ort/trt/paddle/openvino, default 'openvino' for cpu, 'tensorrt' for gpu"
)
return parser.parse_args()
def build_option(args):
det_option = fd.RuntimeOption()
cls_option = fd.RuntimeOption()
rec_option = fd.RuntimeOption()
if args.device.lower() == "gpu":
det_option.use_gpu(args.device_id)
cls_option.use_gpu(args.device_id)
rec_option.use_gpu(args.device_id)
if args.backend.lower() == "trt":
assert args.device.lower(
) == "gpu", "TensorRT backend require inference on device GPU."
det_option.use_trt_backend()
cls_option.use_trt_backend()
rec_option.use_trt_backend()
# If use TRT backend, the dynamic shape will be set as follow.
# We recommend that users set the length and height of the detection model to a multiple of 32.
# We also recommend that users set the Trt input shape as follow.
det_option.set_trt_input_shape("x", [1, 3, 64, 64], [1, 3, 640, 640],
[1, 3, 960, 960])
cls_option.set_trt_input_shape("x", [1, 3, 48, 10],
[args.cls_bs, 3, 48, 320],
[args.cls_bs, 3, 48, 1024])
rec_option.set_trt_input_shape("x", [1, 3, 48, 10],
[args.rec_bs, 3, 48, 320],
[args.rec_bs, 3, 48, 2304])
# Users could save TRT cache file to disk as follow.
det_option.set_trt_cache_file(args.det_model + "/det_trt_cache.trt")
cls_option.set_trt_cache_file(args.cls_model + "/cls_trt_cache.trt")
rec_option.set_trt_cache_file(args.rec_model + "/rec_trt_cache.trt")
elif args.backend.lower() == "pptrt":
assert args.device.lower(
) == "gpu", "Paddle-TensorRT backend require inference on device GPU."
det_option.use_paddle_infer_backend()
det_option.paddle_infer_option.collect_trt_shape = True
det_option.paddle_infer_option.enable_trt = True
cls_option.use_paddle_infer_backend()
cls_option.paddle_infer_option.collect_trt_shape = True
cls_option.paddle_infer_option.enable_trt = True
rec_option.use_paddle_infer_backend()
rec_option.paddle_infer_option.collect_trt_shape = True
rec_option.paddle_infer_option.enable_trt = True
# If use TRT backend, the dynamic shape will be set as follow.
# We recommend that users set the length and height of the detection model to a multiple of 32.
# We also recommend that users set the Trt input shape as follow.
det_option.set_trt_input_shape("x", [1, 3, 64, 64], [1, 3, 640, 640],
[1, 3, 960, 960])
cls_option.set_trt_input_shape("x", [1, 3, 48, 10],
[args.cls_bs, 3, 48, 320],
[args.cls_bs, 3, 48, 1024])
rec_option.set_trt_input_shape("x", [1, 3, 48, 10],
[args.rec_bs, 3, 48, 320],
[args.rec_bs, 3, 48, 2304])
# Users could save TRT cache file to disk as follow.
det_option.set_trt_cache_file(args.det_model)
cls_option.set_trt_cache_file(args.cls_model)
rec_option.set_trt_cache_file(args.rec_model)
elif args.backend.lower() == "ort":
det_option.use_ort_backend()
cls_option.use_ort_backend()
rec_option.use_ort_backend()
elif args.backend.lower() == "paddle":
det_option.use_paddle_infer_backend()
cls_option.use_paddle_infer_backend()
rec_option.use_paddle_infer_backend()
elif args.backend.lower() == "openvino":
assert args.device.lower(
) == "cpu", "OpenVINO backend require inference on device CPU."
det_option.use_openvino_backend()
cls_option.use_openvino_backend()
rec_option.use_openvino_backend()
elif args.backend.lower() == "pplite":
assert args.device.lower(
) == "cpu", "Paddle Lite backend require inference on device CPU."
det_option.use_lite_backend()
cls_option.use_lite_backend()
rec_option.use_lite_backend()
return det_option, cls_option, rec_option
args = parse_arguments()
det_model_file = os.path.join(args.det_model, "inference.pdmodel")
det_params_file = os.path.join(args.det_model, "inference.pdiparams")
cls_model_file = os.path.join(args.cls_model, "inference.pdmodel")
cls_params_file = os.path.join(args.cls_model, "inference.pdiparams")
rec_model_file = os.path.join(args.rec_model, "inference.pdmodel")
rec_params_file = os.path.join(args.rec_model, "inference.pdiparams")
rec_label_file = args.rec_label_file
det_option, cls_option, rec_option = build_option(args)
det_model = fd.vision.ocr.DBDetector(
det_model_file, det_params_file, runtime_option=det_option)
cls_model = fd.vision.ocr.Classifier(
cls_model_file, cls_params_file, runtime_option=cls_option)
rec_model = fd.vision.ocr.Recognizer(
rec_model_file, rec_params_file, rec_label_file, runtime_option=rec_option)
# Parameters settings for pre and post processing of Det/Cls/Rec Models.
# All parameters are set to default values.
det_model.preprocessor.max_side_len = 960
det_model.postprocessor.det_db_thresh = 0.3
det_model.postprocessor.det_db_box_thresh = 0.6
det_model.postprocessor.det_db_unclip_ratio = 1.5
det_model.postprocessor.det_db_score_mode = "slow"
det_model.postprocessor.use_dilation = False
cls_model.postprocessor.cls_thresh = 0.9
# Create PP-OCRv3, if cls_model is not needed, just set cls_model=None .
ppocr_v3 = fd.vision.ocr.PPOCRv3(
det_model=det_model, cls_model=cls_model, rec_model=rec_model)
# Set inference batch size for cls model and rec model, the value could be -1 and 1 to positive infinity.
# When inference batch size is set to -1, it means that the inference batch size
# of the cls and rec models will be the same as the number of boxes detected by the det model.
ppocr_v3.cls_batch_size = args.cls_bs
ppocr_v3.rec_batch_size = args.rec_bs
# Read the input image
im = cv2.imread(args.image)
# Predict and reutrn the results
result = ppocr_v3.predict(im)
print(result)
# Visuliaze the results.
vis_im = fd.vision.vis_ppocr(im, result)
cv2.imwrite("visualized_result.jpg", vis_im)
cv2.imshow("visualized_result.jpg", vis_im)
cv2.waitKey()
print("Visualized result save in ./visualized_result.jpg")
以上代码基于paddleocr的官方代码改进而来,故而可以参考官方的命令参数进行使用
```# 在CPU上使用Paddle Inference推理
python infer.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image 12.jpg --device cpu --backend paddle
# 在CPU上使用OenVINO推理
python infer.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image 12.jpg --device cpu --backend openvino
# 在CPU上使用ONNX Runtime推理
python infer.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image 12.jpg --device cpu --backend ort
# 在CPU上使用Paddle Lite推理
python infer.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image 12.jpg --device cpu --backend pplite
# 在GPU上使用Paddle Inference推理
python infer.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image 12.jpg --device gpu --backend paddle
# 在GPU上使用Paddle TensorRT推理
python infer.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image 12.jpg --device gpu --backend pptrt
# 在GPU上使用ONNX Runtime推理
python infer.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image 12.jpg --device gpu --backend ort
# 在GPU上使用Nvidia TensorRT推理
python infer.py --det_model ch_PP-OCRv3_det_infer --cls_model ch_ppocr_mobile_v2.0_cls_infer --rec_model ch_PP-OCRv3_rec_infer --rec_label_file ppocr_keys_v1.txt --image 12.jpg --device gpu --backend trt
代码运行效果图如下所示

程序运行时输出如下所示,可以看到大部分文字都准确识别了。
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(218)::fastdeploy::OpenVINOBackend::InitFromPaddle number of streams:1.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(228)::fastdeploy::OpenVINOBackend::InitFromPaddle affinity:YES.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(240)::fastdeploy::OpenVINOBackend::InitFromPaddle Compile OpenVINO model on device_name:CPU.
[INFO] fastdeploy/runtime/runtime.cc(286)::fastdeploy::Runtime::CreateOpenVINOBackend Runtime initialized with Backend::OPENVINO in Device::CPU.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(218)::fastdeploy::OpenVINOBackend::InitFromPaddle number of streams:1.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(228)::fastdeploy::OpenVINOBackend::InitFromPaddle affinity:YES.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(240)::fastdeploy::OpenVINOBackend::InitFromPaddle Compile OpenVINO model on device_name:CPU.
[INFO] fastdeploy/runtime/runtime.cc(286)::fastdeploy::Runtime::CreateOpenVINOBackend Runtime initialized with Backend::OPENVINO in Device::CPU.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(218)::fastdeploy::OpenVINOBackend::InitFromPaddle number of streams:1.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(228)::fastdeploy::OpenVINOBackend::InitFromPaddle affinity:YES.
[INFO] fastdeploy/runtime/backends/openvino/ov_backend.cc(240)::fastdeploy::OpenVINOBackend::InitFromPaddle Compile OpenVINO model on device_name:CPU.
[INFO] fastdeploy/runtime/runtime.cc(286)::fastdeploy::Runtime::CreateOpenVINOBackend Runtime initialized with Backend::OPENVINO in Device::CPU.
det boxes: [[42,413],[483,391],[484,428],[43,450]]rec text: 上海斯格威铂尔大酒店 rec score:0.989301 cls label: 0 cls score: 1.000000
det boxes: [[187,456],[399,448],[400,480],[188,488]]rec text: 打浦路15号 rec score:0.994266 cls label: 0 cls score: 1.000000
det boxes: [[23,507],[513,488],[515,529],[24,548]]rec text: 绿洲仕格维花园公寓 rec score:0.984679 cls label: 0 cls score: 1.000000
det boxes: [[74,553],[427,542],[428,571],[75,582]]rec text: 打浦路252935号 rec score:0.996439 cls label: 0 cls score: 1.000000
Visualized result save in ./visualized_result.jpg
对文本切片进行识别
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量PP-OCRv4模型(15.8M) | ch_PP-OCRv4_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
各位可以自行截图生成如下图片,保存为13.jpg

识别代码如下所示,识别效果十分棒,各位可以换成自己的文本切片。
import fastdeploy as fd
import cv2
import os
rec_model_file = os.path.join('ch_ppocr_mobile_v2.0_cls_infer', "inference.pdmodel")
rec_params_file = os.path.join('ch_ppocr_mobile_v2.0_cls_infer', "inference.pdiparams")
rec_label_file = "ppocr_keys_v1.txt"
# Set the runtime option
rec_option = fd.RuntimeOption()
rec_option.use_ort_backend()
# Create the rec_model
rec_model = fd.vision.ocr.Recognizer(
rec_model_file, rec_params_file, rec_label_file, runtime_option=rec_option)
# Read the image
im = cv2.imread("13.jpg")
# Predict and return the result
result = rec_model.predict(im)
print(type(result),dir(result))
# User can infer a batch of images by following code.
# result = rec_model.batch_predict([im])
print(result)
识别结果如下所示,可以看到识别结果完全正确。
[INFO] fastdeploy/runtime/runtime.cc(300)::fastdeploy::Runtime::CreateOrtBackend Runtime initialized with Backend::ORT in Device::CPU.
<class 'fastdeploy.libs.fastdeploy_main.vision.OCRResult'> ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'boxes', 'cls_labels', 'cls_scores', 'rec_scores', 'text']
rec text: 绿洲仕格维花园公寓 rec score:0.988077
3、其他功能
前文仅描述了常见功能的python使用,在faskdeploy还提供了c++部署案列,其python接口与c++接口基本一致。
除了图像分类、目标检测、语义分割、文本识别等功能外,faskdeploy还提供了人脸检测、人脸特征点、人脸识别、生成式模型、姿态检测、扣图、图像超分、目标跟踪等功能的部署案例。后续有使用到会在这里补充案例。