🕺作者: 主页
我的专栏 C语言从0到1 探秘C++ 数据结构从0到1 探秘Linux 😘欢迎关注:👍点赞🙌收藏✍️留言
🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的很重要,有问题可在评论区提出,感谢支持!!!
文章目录
- 前言
- 实验六
- 实验内容:
- 实验过程:
- 1. 下载内核源码
- 2. 进程调度队列是如何组织的?
- 3. 三种调度类型(SCHED_FIFO, SCHED_RR, SCHED_OTHER)的实现过程?
- 4. 优先级是如何定义和动态变化的?
- 5. 时间片的赋值?它与优先级的关系?
- 6. 对实时进程和多CPU的支持?
- 7. 评价Linux的调度策略,提出改进意见。
- 实验小结
前言
本实验结论没有标准答案,请自行判断。
实验六
实验内容:
- 实验名称:分析源代码
- 实验任务:
通过阅读源代码,分析研究linux的进程调度策略和算法。要求以源码为依据,回答下面的问题:
- 进程调度队列是如何组织的
- 三种调度类型(SCHED_FIFO, SCHED_RR, SCHED_OHTER)的实现过程
- 优先级是如何定义和动态变化的
- 时间片的赋值?它与优先级的关系?
- 对实时进程和多CPU的支持
- 评价linux的调度策略,提出改进意见。
- 源码版本
Linux 5.15.1
实验过程:
1. 下载内核源码
使用这个网站下载:https://mirrors.edge.kernel.org/pub/linux/kernel
2. 进程调度队列是如何组织的?
在新版本的Linux内核中,比如说我的版本5.15.1,进程调度队列是由红黑树(rbtree)实现的。每个CPU都有一个运行队列(runqueue),其中包含了所有处于可运行状态的进程。每个进程都通过一个task_struct结构来表示,其中的调度信息存储在sched_entity和sched_rt_entity结构中。
在Linux内核的源码中,调度队列的结构定义在include/linux/sched.h文件中。这个文件包含了与进程调度相关的各种数据结构和函数声明。如图1 源码中task_struct的结构。

图1 源码中task_struct结构
以下是一个简化的sched.h文件片段,展示了与调度队列相关的数据结构:
struct task_struct { /* ... */
struct sched_entity se;
struct sched_rt_entity rt;
/* ... */
};
struct sched_entity {
/* ... */
struct rb_node run_node;
/* ... */
};
struct rb_root runqueues[NR_CPUS];
在这个片段中,task_struct结构表示一个进程,其中包含了两个与调度相关的结构:se和rt。se表示一个普通的调度实体,用于实现基于优先级的调度,而rt表示一个实时调度实体,用于实现基于时间的调度。
每个CPU都有一个runqueues数组,这是一个红黑树(rbtree),用于存储所有处于可运行状态的进程。每个进程通过其se或rt结构中的run_node域链接到红黑树中。
下面是源码中rb_node的实现:
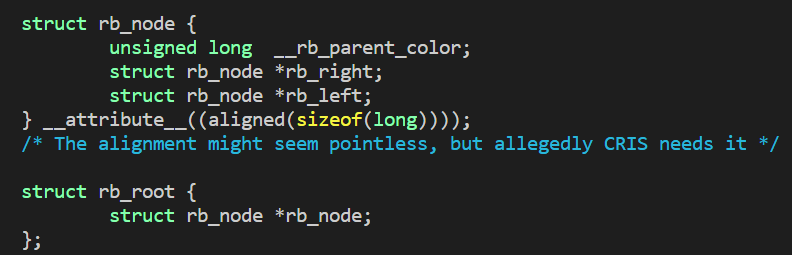
图2 源码中rb_node的结构
在运行队列中,进程按照优先级(对于se)或时间(对于rt)进行排序。调度器在调度时,会遍历红黑树,选择最高优先级(或最早到期时间)的进程进行执行。
3. 三种调度类型(SCHED_FIFO, SCHED_RR, SCHED_OTHER)的实现过程?
SCHED_FIFO和SCHED_RR是实时调度策略,它们都基于优先级调度,只是SCHED_FIFO是无时间片的,而SCHED_RR是有时间片的。SCHED_OTHER是普通的分时调度策略。调度类型在源码中的表示和优先级在源码中的表示如图3、4所示。

图3 调度类型在源码中的表示

图4 优先级在源码中的表示
SCHED_FIFO的实现过程:当一个进程被设置为SCHED_FIFO时,它的sched_priority字段会被设置为一个正值,表示其优先级。当调度器选择进程时,它会从最高优先级的进程开始,直到找到一个可运行的进程。如果最高优先级的进程不可运行,那么它会继续查找次高优先级的进程,以此类推。
SCHED_RR的实现过程:当一个进程被设置为SCHED_RR时,它的sched_priority字段也会被设置为一个正值,表示其优先级。此外,它还有一个时间片(time slice),用于限制它运行的时间。当调度器选择进程时,它会从最高优先级的进程开始,直到找到一个可运行的进程。如果最高优先级的进程不可运行,那么它会继续查找次高优先级的进程,以此类推。当一个进程用完了它的时间片后,它会被放入队列的尾部,等待下一次调度。
SCHED_OTHER的实现过程:当一个进程被设置为SCHED_OTHER时,它的sched_priority字段会被设置为一个负值,表示其优先级。当调度器选择进程时,它会从最低优先级的进程开始,直到找到一个可运行的进程。如果最低优先级的进程不可运行,那么它会继续查找次低优先级的进程,以此类推。
调度器从最低优先级的进程开始选择,主要是为了实现公平调度。这种做法可以确保每个进程都有机会得到执行,避免高优先级的进程长时间独占CPU资源,导致低优先级的进程饥饿。
在许多操作系统中,调度策略都会考虑到进程的优先级,以确保系统资源的合理分配。通过设置进程的优先级,可以控制进程的执行顺序,从而使得系统资源得到更加有效的利用。
操作系统通过判断在不同的策略下进行不同的行为,如图5所示:

图 5 某个函数根据调度策略不同进行选择
4. 优先级是如何定义和动态变化的?
我们可以在sched.c文件中搜索nice,可以看到如图6的描述:

图 6 源码中对nice值的描述
在Linux内核中,进程优先级是通过sched_priority字段定义的,该字段是一个32位的整数,范围从-20(最高优先级)到+19(最低优先级)。
进程的优先级可以通过系统调用nice()和setpriority()来动态调整。nice()系统调用可以调整进程的nice值(nice值与优先级之间的关系是nice值越低,优先级越高)。setpriority()系统调用可以直接调整进程的优先级。
通过命令man nice 命令查看,如图7所示。
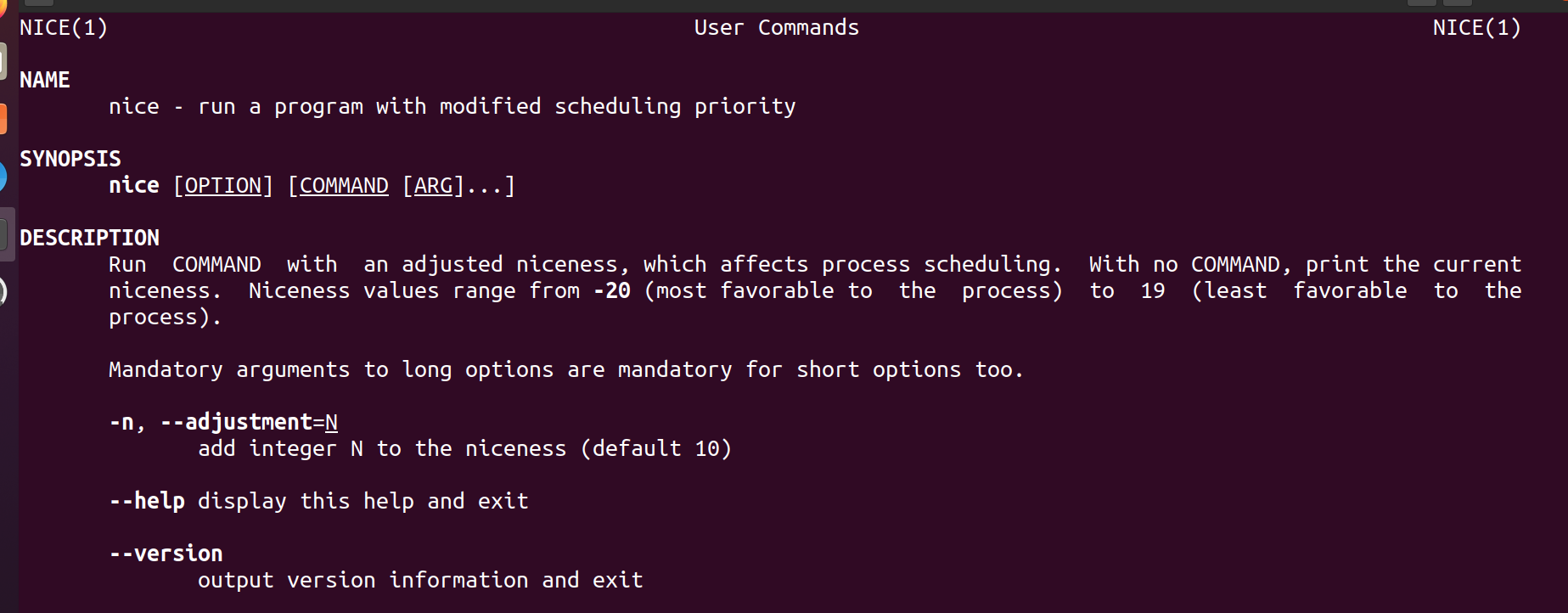
图 7 查看手册中对nice值的描述
通过命令man setpriority查看,如图 8 所示。

图 8 查看手册中对setpriority值的描述
5. 时间片的赋值?它与优先级的关系?
在 Linux 内核中,时间片的赋值主要跟以下几个因素有关:
1.调度策略:针对不同的调度策略,比如 SCHED_OTHER、SCHED_BATCH、SCHED_IDLE、SCHED_FIFO、SCHED_RR,时间片的赋值是不同的。CFS(完全公平调度算法)用于 SCHED_OTHER、SCHED_BATCH、SCHED_IDLE 调度策略,而 SCHED_FIFO、SCHED_RR 则是实时调度策略。
2.进程优先级:对于 SCHED_FIFO 和 SCHED_RR 的实时任务,优先级(在 Linux 中表现为 rt_priority)是静态设定的,不过所有实时进程的优先级都高于普通进程。优先级越高的进程越先被调度,直到它完成任务或者出现更高优先级的线程抢占。
对于 CFS 调度的普通进程,优先级(在 Linux 中通过 nice 值来派生)影响的是每个进程的权重,即与每个进程关联的运行时长。nice 值越小,优先级越高,分配的 CPU 时间越多。
在新版 Linux 内核中,进程的时间片并不是固定的,不像早期的 O(1) 调度器有明确定义的时间片概念。CFS 调度器更注重进程之间的公平性,它使用虚拟运行时间(虚拟时钟)来度量进程的运行时间并按此公平调度。
以下是在 Linux 内核代码中找到的一些相关的源码部分:
普通任务的运行时间:CFS 调度器的运行时间(可以理解为时间片)在 kernel/sched/fair.c 这个文件中进行计算和更新,比如函数 entity_tick 中就更新了进程的虚拟运行时间,如图9所示。

图 9 函数 entity_tick的内容
此外,需要注意的是,调度策略、优先级、时间片等可以通过sched_setparam、sched_setattr 等系统调用进行设置。但这些调用主要用于设置调度策略和优先级,而非直接设置时间片长度。
在kernel/sched/sched.h文件中,可以找到关于优先级的定义:
#define MAX_PRIO 140#define DEFAULT_PRIO 120
struct sched_param {
int sched_priority;
};
其中,MAX_PRIO是优先级的最大值,DEFAULT_PRIO是默认的优先级。
在kernel/sched/core.c文件中,可以找到关于nice值来调整优先级的代码:
static voidset_user_nice(struct task_struct *p, long nice)
{
int old_prio, delta;
if (nice < -20 || nice > 19)
return;
old_prio = p->static_prio;
delta = 20 - nice;
if (delta < 0) {
delta = -delta;
p->static_prio = old_prio - delta;
} else {
p->static_prio = old_prio + delta;
}
}
这段代码展示了如何根据nice值(表示优先级)来调整静态优先级(static_prio)。
6. 对实时进程和多CPU的支持?
Linux内核支持实时进程和多CPU。实时进程可以通过sched_setscheduler()系统调用来设置调度策略(SCHED_FIFO或SCHED_RR)。多CPU支持通过每个CPU都有自己的运行队列来实现,每个运行队列都包含了所有在该CPU上可运行的进程。
以下是Linux内核代码中的一些部分,这些部分展示了对实时进程和多CPU的支持:
实时进程调度:在kernel/sched/sched.h文件中,定义了实时进程的宏,如图10所示。
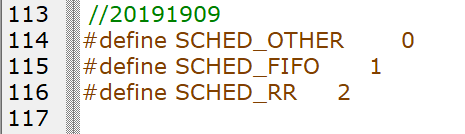
图 10 调动策略的宏定义
在kernel/sched/sched.c文件中,实现了实时进程的调度函数:
static void sched_rt_period_timer(struct rq *rq){
struct task_struct *curr = rq->curr;
struct task_struct *next;
if (curr->policy != SCHED_FIFO && curr->policy != SCHED_RR)
return;
/*
* Reevaluate all tasks with equal priorities:
*/
for_each_task_in_rq(rq, next) {
if (next->prio == curr->prio)
resched_task(rq, next);
}
}
多CPU支持:在kernel/sched/core.c文件中,实现了多CPU调度的代码:
void __sched __schedule(void){
...
cpu = smp_processor_id();
rq = cpu_rq(cpu);
...
}
这个函数在选择下一个要运行的进程时,会首先获取当前CPU的ID,然后获取与该CPU对应的运行队列。
7. 评价Linux的调度策略,提出改进意见。
Linux的调度策略已经比较成熟,但是仍然有改进的空间。例如,可以通过引入更精细的优先级机制,如按进程组、用户或进程类型来设置优先级,以提高调度的公平性和效率。此外,还可以考虑引入更先进的调度算法,如基于反馈的控制理论或机器学习的方法,以实现更智能的调度决策。
实验小结
在本次实验中,我们通过分析 Linux 内核源码,探索了 Linux 的进程调度策略和算法。尽管我们已经对源码做了深入的研究,但是遇到了一些问题,也产生了一些值得注意的事项,以及识别了一些待提高的能力。
存在问题:
- 源代码理解难度大:Linux 内核源代码是底层的操作系统代码,其复杂性和深度使得对其的理解和分析较为困难。其中涉及的概念,如调度算法、优先级和时间片等,需要具备扎实的操作系统理论知识和强大的代码阅读能力。
- 实验结果的实用性:尽管我们对源代码有了一定的理解,但如何将这些理解转化为改进 Linux 内核的实际操作尚不清楚。
注意事项:
- 源码版本:Linux 内核源码更新频繁,新的版本可能会包含新的调度算法或策略,因此我们需要时刻关注内核源码的更新,理解新版本的特性和变化。
- 细节分析:在阅读源码时,需要注意细节,理解代码的功能,以便更准确地理解 Linux 的调度策略。
有待提高的能力:
- 深入理解底层代码:更好地理解 Linux 内核源代码,理解其背后的设计思想和实现细节,是需要长期磨练的技能。我们需要进一步提高我们阅读和理解底层代码的能力。
- 实践转化:如何把对源码的理解转化为实际的改进或应用,这是一个值得我们深思的问题,也是我们需要努力提升的能力。