Elasticsearch应用(六)
1.什么是分词器
ES文档的数据拆分成一个个有完整含义的关键词,并将关键词与文档对应,这样就可以通过关键词查询文档。要想正确的分词,需要选择合适的分词器
2.ES中的默认分词器
- fingerprint:删除所有符号,大写转小写,重复数据删除,排序,如果配置了停用词列表停用词也将被删除
- keyword:不分词
- language:用来分析特定语言文本的分析器
- pattern:使用java正则表达式,默认非字符分割
- english:英文分析器
- simple:非字母切分,符号被过滤,所有均小写
- standard:默认的,按词切分,所有均小写
- stop:停用词过滤,其他与simple一样
- whitespace:空格切分,不转小写
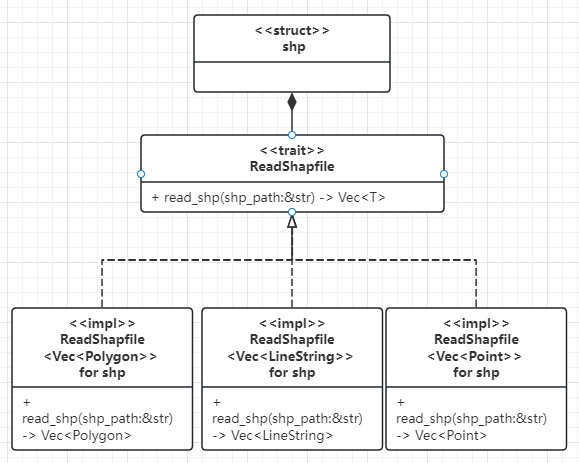
3.分词器的组成
介绍
- Character Filters: 在tokenizer之前对文本进行处理。例如删除字符、替换字符。主要是对原始文本的处理
- Tokenizer: 将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart,可以用java开发插,实现自己的Tokenizer
- Tokenizer Filter: 将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等。可能具有零个或多个按顺序应用的令牌过滤器
默认的Tokenizer
- standard:按照符号,空格拆分
- letter:非字母拆分为单词
- whitespace:空格拆分
- lowercase:等同于letter+lowercase token filter
- uax_url_email:等同于standard+识别URL Email为单个单词
- keyword:不做任何处理
- pattern:默认模式是\W+,它在遇到非单词字符时会拆分文本
- path_hierarchy:路径
- char_group
- simple_pattern
- simple_pattern_split
- classic(经典但是一般只适用于英文)
- Thai Tokenizer(泰文分词器)
- ngram
- edge_ngram
默认的Character Filters
- 可以配置多个,但会影响tokenizer的position和offset信息
- html_strip:去除HTML标签
- mapping:字符串替换
- pattern_replace:正则匹配替换
默认的Token Filters
- 将Tokenizer输出的单词,进行增加,修改,删除
- Lowercase
- stop
- synonym
4.分词器API
请求全局分词器
GET /_analyze
{
"analyzer":"分词器",
"text":"被分词的文本"
}
请求某个索引下的分词器
POST /<index>/_analyze
{
"field":"字段名",
"text":"被分词的文本"
}
自定义分词器
POST /_analyze
{
"tokenizer":"分词器",
"filter":"Token Filter",
"char_filter":"",
"text":"被分词的文本"
}
5.指定分析器
# 指定索引的默认分析器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
}
}
}
}
}
# 指定字段的分析器
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}
# 查询时指定分析器
GET my_index/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}
# 指定字段的搜索(search time)分析器
# 如果指定搜索分析器则必须指定索引分析器
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}
# 指定索引的默认分析器与搜索的默认分析器
# 如果提供了搜索分析器则必须指定默认的索引分析器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple"
},
"default_search": {
"type": "whitespace"
}
}
}
}
}
6.自定义分词器
说明
可以在创建索引库的时候,通过/settings来配置自定义的analyzer(分词器)
settings设置
PUT /<index>
{
"settings":{
"analysis":{
"analyzer":{ // 自定义分词器
"my_analyzer":{ // 自定义分词器名称
"tokenizer":"ik_max_word",
"filter":"pinyin"
}
}
}
}
}
自定义分词器
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{
"type":"custom",
"char_filter":["emoticons"],
"tokenizer":"punctuation",
"filter":["lowercase","english_stop"]
}
},
"tokenizer": {
"punctuation":{
"type":"pattern",
"pattern":[".",",","!","?"]
}
},
"char_filter": {
"emoticons":{
"type":"mapping",
"mappings":[":) => _happy_",":( => _sad_"]
}
},
"filter": {
"english_stop":{
"type":"stop",
"stopwords":"_english_"
}
}
}
}
}
POST /my_index/_analyze
{
"analyzer": "my_custom_analyzer",
"text":" I'm a :) person, and you? "
}
7.ES如何确定搜索分析器
- analyzer搜索查询中的参数
- search_analyzer字段的映射参数
- 默认分词器
- 字段分词器
- 如果这些都没指定就使用默认分词器
8.ES如何确定索引分析器
- analyzer字段的映射参数
- analysis.analyzer.default指数设置
- 如果未指定这些参数,则使用standard分析器
9.注意
- ES仅text字段支持analyzer映射参数
- analyzer参数指定索引或搜索字段时用于文本分析的分析器,除非使用search_analyzer映射参数覆盖,否则此分析器将同时用于索引和搜索分析
10.IK分词器
为什么需要
因为内置分词器不支持中文,可以看以下默认分词器对中文的效果展示

参考链接
ik分词器github地址:https://github.com/medcl/elasticsearch-analysis-ik/
介绍
- 是一个ES的插件
- 中文分词器
- 支持自定义词典
- ik有两种分词器分别是,ik_smart , ik_max_word
版本对应
| IK版本 | ES版本 |
|---|---|
| master | 7.x -> master |
| 6.x | 6.x |
| 5.x | 5.x |
| 1.10.6 | 2.4.6 |
| 1.9.5 | 2.3.5 |
| 1.8.1 | 2.2.1 |
| 1.7.0 | 2.1.1 |
| 1.5.0 | 2.0.0 |
| 1.2.6 | 1.0.0 |
| 1.2.5 | 0.90.x |
| 1.1.3 | 0.20.x |
| 1.0.0 | 0.16.2 -> 0.19.0 |
下载地址
进入该网址https://github.com/medcl/elasticsearch-analysis-ik/releases
安装到ES中
第一种方式(需要下载zip文件)
- 解压zip文件到ES目录下的plugins目录即可
- 重启ES
第二种方式(版本需要大于5.5.1)
- 进入到ES目录下的bin目录
- 执行命令(自己更换版本)
#注意,请将版本替换为自己所需要的版本
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.1/elasticsearch-analysis-ik-7.7.1.zip
# 其他命令扩展
# 查看已安装插件
elasticsearch‐plugin list
# 安装插件
elasticsearch‐plugin install analysis‐icu
# 删除插件
elasticsearch‐plugin remove analysis‐icu
- 重启ES
两种分词器介绍
- ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询
- ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query
什么是词典
IK分词器根据词典进行分词,词典文件在lK分词器的config目录中
- main.dic: IK中内置的词典。记录了IK统计的所有中文单词
- IKAnalyzer.cfg.xml: 扩展词典
扩展字典
为什么需要扩展字典
因为ik分词器只识别默认的一些词语,有一些自造词无法识别例如‘骚年,极客时间,朋友圈’
配置扩展字典
- 进入ik分词器目录下的config目录
- 创建xxx.dic文件
- 修改IKAnalyzer.cfg.xml文件
- 修改内容
- 重启ES
修改内容展示
#注意xxx.dic要与自己建立dic文件名一致
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">xxx.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
xx.dic格式如下
十多年
李白
传智慧
11.拼音分词器
为什么需要拼音分词器
要实现根据字母做补全,就必须对文档按照拼音分词
安装拼音分词器参考IK的安装方式
拼音分词器官网:https://github.com/medcl/elasticsearch-analysis-pinyin
拼音分词器测试
POST /_analyze
{
"text":"如家酒店还不错",
"analyzer":"pinyin"
}
拼音分词器的问题
- 默认情况下,不会进行分词类似于keyword
- 默认情况下,把文本的每一个字都分为了一个拼音
- 默认情况下,汉字去掉了
- 同音字问题
同音字问题
拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用,因为如果用户输入的是中文也会分词为拼音去匹配就会造成一些没用的文档,只希望输入中文就用中文查,用了拼音才用拼音分词器

自定义拼音分词器改造
- 使用自定义的分词器测试的时候需要指定索引库,里面不能直接去访问_analyzer那个API去测试,需要改为//_analyzer进行测试
- 在创建索引库的时候需要指定mapping中的某个字段的分词器为自定义分词器

创建和搜索使用不同的分词器解决同音字问题




![[Python] KDE图[作密度图(Kernel Density Estimate,核密度估计)]介绍和使用场景(案例)](https://img-blog.csdnimg.cn/direct/d35ada40125941039de193157095efa0.png)