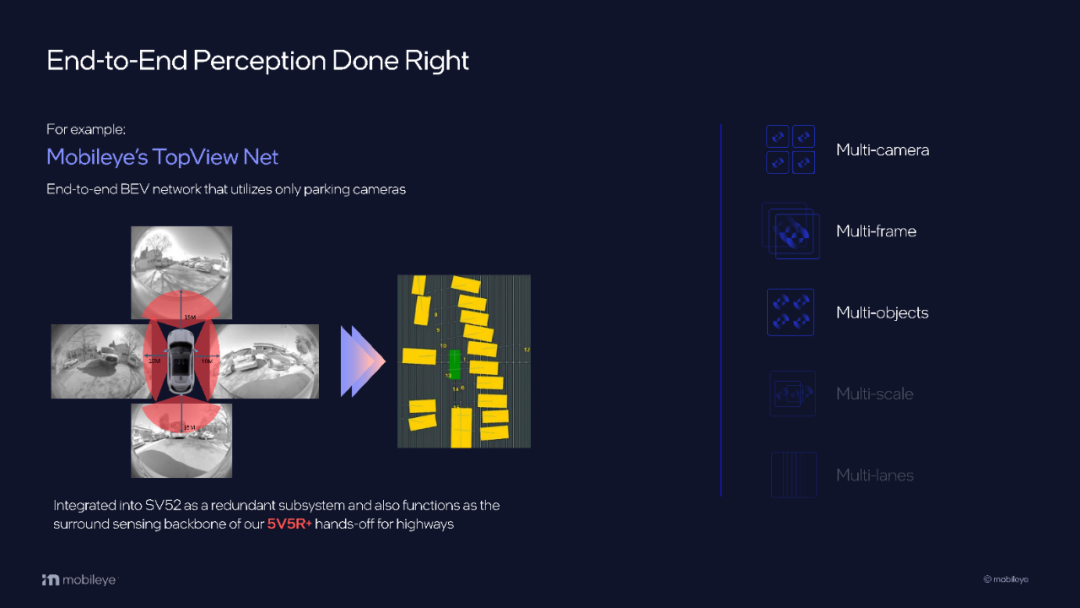
前面已经讲过了Java-NIO中的三大核心组件Selector、Channel、Buffer,现在组件我们回了,但是如何实现一个超级高并发的socket网络通信程序呢?假设,我们只有一台内存为32G的Intel-i710八核的机器,如何实现同时2万个客户端高并发非阻塞通信?可能你会说不可能实现,答案是2万的并发可能都低估了,Redis单机通信20万的并发都是可以的,当然达到20万的并发对机器性能以及带宽都需要非常高的要求。那么就不得不引出今天讲解的Reactor反应器模式,它可以说是一种高并发网络编程中的设计模式,不包括在我们常说的23中设计模式之中。Netty网络框架、Nginx服务器、Reids缓存等大名鼎鼎的中间件都是基于Reactor反应器模式设计的,它就能提供超高并发的网络通信,我学过之后一直感叹这些大佬都是奇才,学这些思想精彩万分!下面具体进行介绍:
Reactor是什么?
Reactor就是一种网络编程的设计模式,如果不知道Reactor那么学Netty的时候会非常困难,因为很多概念就是Reactor,因此学会了Reactor在学Netty就非常简单。其次,懂得高并发中间件的网络通信设计的底层原理对提升自己的技术也是非常重要的,所以,学习像Netty这样的“精品中的精品”框架,肯定也是需要先从设计模式入手的。而Netty的整体架构,就是基于这个著名反应器模式。所以,学习和掌握反应器模式,对于开始学习高并发通信(包括Netty框架)的人来说,一定是磨刀不误砍柴工,况且很多中间件都是基于Netty来设计网络通信模块的。
思维风暴开启Reactor之路
好的,我们用一个例子开始讲解Reactor原理,假设你是Doug Lea,Java JUC包的作者, 也是Reactor设计模式的提出者之一。现在面临的一个问题就是现在的软件系统不能够满足日益增长的并发量,很多软件系统一旦人访问数多了要么卡死要么阻塞一段时间才有响应,用户体验非常差,现在公司提出了这个需求需要你解决。请你思考:
单线程阻塞模式
首先TCP网络通信需要先建立连接(三次握手)然后才可以传输数据,于是你写下了第一行解决的代码:
1 while(true){
2 socket = accept(); //阻塞,接收连接
3 handle(socket) ; //读取数据、业务处理、写入结果
4 }
5 private void handle(socket){
6 String msg = socket.read(); //阻塞,读取客户端发送过来的数据
7 System.out.println(msg);
8 .... // 其他处理
9 }
解释一下,上面采用一个循环的方式来解决这个问题,程序占用一个主线程不断执行while循环中的代码,当代码执行到第2行时如果没有客户端发生连接的请求则阻塞,不继续向下执行。直到某个客户端发生连接请求,于是获得了socket对象,这个对象假设包括客户端的ip地址和端口号,并且可以通过socket与客户端接受和发送数据。之后执行到第6行代码,这里也会阻塞直到用户发生了数据。上面的服务器代码如果只有一个客户端与它交互是没有问题的,如果超过一个用户与之交互则会发生阻塞的情况,假设有两个客户A和B,A已经连接好了服务器也就是上面代码执行到了第6行代码进行阻塞,此时服务器希望收到客户发送的数据。就在阻塞的这个时候,如果B想要连接服务器,发送了连接请求,但是服务器代码一直卡在第6行等待获取客户端的发生数据,如果A一直不发送数据则B永远连不上服务器。除非等到A发送了一个数据,于是程序运行到第2行,然后接受B的连接请求,然后又卡在了第6行。很明显,上面的网络编程服务程序很糟糕,非常卡,连得上连不上完全看运气。失败!
这个时候,Doug Lea进行思考,阻塞是因为网络编程就是基于事件触发的,也就是说接受连接的第二行代码和读取数据的第六行代码完全取决于客户端,什么时候触发完全随机,因此很难搞。另外一个最主要的原因是这个是单线程程序,那么使用多线程能不能解决呢?答案是基本上可以解决,而且早期的Tomcat服务器就是这样设计的,这个模式就叫做 Connection Per Thread模式。下面进行详细介绍!
多线程经典Connection Per Thread模式
Connection Per Thread 即一个连接创建一个线程来处理,首先我们分析一下一台上述的内存32G的机器可以创建多少个线程,Java虚拟机默认一个线程占用1MB的栈内存,在不考虑其他情况下,假设分配给了虚拟机栈20G的空间,那么可以创建20*1024个线程来应对网络连接,也就是可以同时并发20480个客户端的请求。我们先看如何实现,再看它的缺点是什么,实现代码如下:
public class ConnectionPerThread implements Runnable {
@Override
public void run(){
Socket socket = new Socket();
while(true){
acceptedSocket = socket.accept(); //依旧是阻塞方法,接受客户端的连接请求
// 如果有一个连接就立即创建一个线程为这个连接服务,直到连接断开
Handler handler = new Handler(socket);
new Thread(handler).start(); // 启动新线程执行run方法
}
}
class Handler implements Runnable{
Socket socket;
public Handler(Socket socket){
this.socket = socket;
}
@Override
public void run() {
while (true){
String msg = socket.read(); //依旧是阻塞方法,接受客户端的发送的数据
if("close".equals(msg)){ // 假设客户端主动断开发送`close`字符,NIO中是空字符串表示断开
break; // 终止线程
}
// 也可以执行写操作,如果是发送大数据会明显阻塞,如果小文件可视为非阻塞,本质还是会阻塞
socket.write("hello 用户!");
}
}
}
}
以上的Socket使用的是伪代码,实际上需要使用OIO或者NIO的ServerSocket对象,反正能够表达这个意思就行。其实上面的代码还可以使用线程池来维护线程进行优化,但是这里只是为了举例说明多线程也是可以的实现较高并发的网络通信。下面来具体分析:
以上示例代码中,对于每一个新的网络连接都分配给一个线程。每个线程都独自处理自己负责的socket连接的输入和输出。当然,服务器的监听线程也是独立的,任何的socket连接的输入和输出处理,不会阻塞到后面新socket连接的监听和建立,这样,服务器的吞吐量就得到了提升。早期版本的Tomcat服务器,就是这样实现的。Connection Per Thread模式(一个线程处理一个连接)的优点是:解决了前面的新连接被严重阻塞的问题,在一定程度上,较大的提高了服务器的吞吐量。Connection Per Thread模式的缺点是:对应于大量的连接,需要耗费大量的线程资源,对线程资源要求太高。在系统中,线程是比较昂贵的系统资源。如果线程的数量太多,系统无法承受。而且,线程的反复创建、销毁、线程的切换也需要代价。因此,在高并发的应用场景下,多线程OIO的缺陷是致命的。新的问题来了:如何减少线程数量,比如说让一个线程同时负责处理多个socket连接的输入和输出,行不行呢? 可以的,一个有效途径是:使用Reactor反应器模式。用反应器模式对线程的数量进行控制,做到一个线程处理大量的连接。它是如何做到呢?直接上正餐——多线程的Reactor反应器模式。
多线程Reactor反应器模式
唤醒你的回忆,还记得Selector和IO多路复用不?不记得的话请访问:https://blog.csdn.net/cj151525/article/details/135695467 查看!我们前面讲到,客户端的连接和发送数据等行为是以IO事件的方式触发Selector的查询的,仅仅使用一个线程的Selector模式,就可以应付大量的访问,其主旨就是:如果某个用户阻塞了那本线程就去为别的需要服务的用户服务,而不是傻傻等待你阻塞解除,总而言之就是线程只为通过Selector.select()查询出来的需要执行的事件服务。因此,单线程下效率就非常高,例如Redis的数据处理模块就是单线程的,单线程的优点就是线程安全,CPU不需要频繁上下文切换。这种模式下,并发量上10万都是简简单单的。那么你敢想想如果我们引进多线程将会有多高的并发量吗?线程并不是越多越好,当你的线程数量和你的CPU核心数相同时就不会频繁发生CPU上下文切换,当线程数远远超过CPU核心数才会频繁发生导致执行效率不高,甚至阻塞等问题。好的,目前基础已经讲解完毕,下面正式引入Reactor反应器模式。
引用一下Doug Lea大师在文章《Scalable IO in Java》中对反应器模式的定义,具体如下:Reactor反应器模式由Reactor反应器线程、 Handlers处理器两大角色组成,两大角色的职责分别如下:
(1) Reactor反应器线程的职责:负责响应IO事件,并且分发到Handlers处理器。
(2) Handlers处理器的职责:非阻塞的执行业务处理逻辑。
每一个单独线程执行的Selector我们就叫做Reactor反应器。一个Reactor反应器包括一个Selector对象,另外还有需要干的活儿,也就是run方法中需要执行的逻辑,这个逻辑叫做Handler处理器。因此,如何理解Reactor反应器,就是单独线程来执行的Selector。明白了这些之后,那么我们将Selector分为Boss和Worker,Boss只有一位负责用户的连接请求与任务分发,Worker可以有很多,负责发送和接受用户的数据以及处理这些数据的中间过程。Boss和每个Worker就是一个Reactor,多线程Reactor反应器模式的模型如下(黄色的是方法,橙色是对象):

下面是代码实现,注意为了和Netty中EventLoop概念一致,这里Reactor使用EventLoop替代,你只要知道这两的概念是同一个,就是单独线程执行的Selector。代码如下:
package com.cheney.nioBaseTest;
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @version 1.0
* @Author Chenjie
* @Date 2024-01-21 18:39
* @注释
*/
public class ReactorTest {
public static void main(String[] args) throws IOException {
new BossEventLoop().register();
}
/**
* BossReactor,EventLoop和Reactor是同一个概念
*/
@Slf4j
static class BossEventLoop implements Runnable {
private Selector bossSelector;
private WorkerEventLoop[] workers; // 一个boss负责分配任务,worker负责执行任务
private volatile boolean start = false; // 对象的方法只能执行一次
AtomicInteger index = new AtomicInteger(); // WorkerEventLoop[]数组的下标
public void register() throws IOException {
if (!start) {
// 连接Channel
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(8080));
ssc.configureBlocking(false);
bossSelector = Selector.open();
// Boss 注册连接事件
SelectionKey ssckey = ssc.register(bossSelector, 0, null);
ssckey.interestOps(SelectionKey.OP_ACCEPT);
// 创建若干个WorkerReactor来读取发送数据
workers = initEventLoops();
// 本Boss一个线程启动起来先
new Thread(this, "boss").start();
log.debug("boss start...");
start = true;
}
}
/**
* 创建若干个WorkerEventLoop
* @return
*/
public WorkerEventLoop[] initEventLoops() {
// EventLoop[] eventLoops = new EventLoop[Runtime.getRuntime().availableProcessors()];
WorkerEventLoop[] workerEventLoops = new WorkerEventLoop[2];
for (int i = 0; i < workerEventLoops.length; i++) {
workerEventLoops[i] = new WorkerEventLoop(i);
}
return workerEventLoops;
}
/**
* Boss需要执行连接和任务分发,就是概念中的Handler处理器,图中的AcceptorHandler
*/
@Override
public void run() {
while (true) {
try {
bossSelector.select();
Iterator<SelectionKey> iter = bossSelector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isAcceptable()) {
// 前面只注册了连接事件,因此只要负责建立连接并将后续的任务分发给Worker就行
ServerSocketChannel c = (ServerSocketChannel) key.channel();
SocketChannel sc = c.accept();// 建立连接
sc.configureBlocking(false);
log.debug("{} connected", sc.getRemoteAddress());
// 分发给Worker来处理,这里是公平地轮询,即每个Worker公平循环领取任务去执行
// 因为每个Worker其实就是一个Selector,而每个Selector可以管理多个Channel(用户交互)
workers[index.getAndIncrement() % workers.length].register(sc);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* WorkerReactor,主要负责读取用户发来的数据
*/
@Slf4j
static class WorkerEventLoop implements Runnable {
private Selector workerSelector;
private volatile boolean start = false;
private int index;
// 任务队列,存放可执行的命令,两个线程需要传参的话通过队列来实现执行逻辑解耦
private final ConcurrentLinkedQueue<Runnable> tasks = new ConcurrentLinkedQueue<>();
public WorkerEventLoop(int index) {
this.index = index;
}
public void register(SocketChannel sc) throws IOException {
if (!start) {
workerSelector = Selector.open();
// 启动一个新线程执行本类的run方法
new Thread(this, "worker-" + index).start();
start = true;
}
tasks.add(() -> {
// 向任务队列中添加任务(即需要执行的指令)
try {
SelectionKey sckey = sc.register(workerSelector, 0, null);
sckey.interestOps(SelectionKey.OP_READ);
workerSelector.selectNow();
} catch (IOException e) {
e.printStackTrace();
}
});
// 唤醒Selector
workerSelector.wakeup();
}
/**
* WorkerReactor 的Handler处理器,负责读取用户发过来的数据
*/
@Override
public void run() {
while (true) {
try {
workerSelector.select();
// 从任务队列中获取一个任务并执行
Runnable task = tasks.poll();
if (task != null) {
task.run();
}
Set<SelectionKey> keys = workerSelector.selectedKeys();
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
if (key.isReadable()) {
// 读取客户端发生过来的数据
SocketChannel sc = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(128);
try {
int read = sc.read(buffer);
if (read == -1) { // 如果-1则是用户断开连接触发的读事件
key.cancel();
sc.close();
} else {
buffer.flip();
log.debug("{} message:", sc.getRemoteAddress());
}
} catch (IOException e) {
e.printStackTrace();
key.cancel();
sc.close();
}
}
iter.remove();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
总结
什么是Reactor?答:一个线程对应一个Selector模式的对象,Reactor模式其中BossReactor负责客户端连接与任务分发给WorkerReactor对象,WorkerReactor负责具体的数据发送与接受等操作。而各自所负责的任务也被叫做Handler(处理器)。相信看完上面的讲解和代码,你已经知道了什么是Reactor模式了!
Reactor反应器模式和优点和缺点
反应器模式和生产者消费者模式有点相似,不过反应器模式没有生产者,而是通过Selector查询已经发生的事件从而委派给Worker进行消费,可以认为是只有消费者的一种模式。反应器模式和观察者模式也有点相似,不同的是观察者模式一旦发布者状态变化时,其他的所有观察者都会收到通知从而执行相应的处理。而反应器模式是一旦Selector查询到了IO事件时只会指定某个Worker进行处理而不是所有的Worker。
优点
- 响应快,虽然同一反应器线程本身是同步的,但不会被单个连接的IO操作所阻塞;
- 编程相对简单,最大程度避免了复杂的多线程同步,也避免了多线程的各个进程之间切换的开销;
- 可扩展,可以方便地通过增加反应器线程的个数来充分利用CPU资源。
缺点
- 反应器模式增加了一定的复杂性,因而有一定的门槛,并且不易于调试。
- 反应器模式依赖于操作系统底层的IO多路复用系统调用的支持,如Linux中的epoll系统调用。如果操作系统的底层不支持IO多路复用,反应器模式不会有那么高效。
- 同一个Handler业务线程中,如果出现一个长时间的数据读写,会影响这个反应器中其他通道的IO处理。例如在大文件传输时, IO操作就会影响其他客户端(Client)的响应时间。因而对于这种操作,还需要进一步对反应器模式进行改进。


![P4769 [NOI2018] 冒泡排序 洛谷黑题题解附源码](https://img-blog.csdnimg.cn/img_convert/323dd164e2dd3ad46800446b78d7ada2.png)








![[BJDCTF2020]ZJCTF,不过如此(特详解)](https://img-blog.csdnimg.cn/img_convert/3b5dd69949e55aba44679863daea5f13.png)