项目主页:https://humanaigc.github.io/animate-anyone/
论文: Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
摩尔线程复现代码:https://github.com/MooreThreads/Moore-AnimateAnyone
摩尔windows一键运行包:https://www.bilibili.com/video/BV1S5411i7Cn/
原作者讲解(需要手机端看): https://mp.weixin.qq.com/s/bSV-dxA618LvN76tg4Z0kQ
其他教程视频: 用Comfy UI + Animate Anyone来一键制作抖音视频
demo:在通义前问app上可以试用 (可生成12秒)

文章目录
- 简介
- 实测: 鸣人跳兔子舞
- 相关研究
- 方法
- Image Animation
- 基于diffusion的图片生成模型0
- 基于diffusion的视频生成
- (DreamPose )
- 23.07 DicCo(跳舞)
- 图像生成一致性改进:TryonDiffusion
- 视觉内容一致性: Emu Video
- *时序的diffusion model (逐渐成熟)
- 对上面方法总结
- Animate Anyone 算法原理
- 驱动2次元受到用户欢迎
- 在量化的模特视频上
- 应用案例
- 试穿+电商
- 数字人相关
- 团队建设
简介
角色动画(Character Animation)是指在通过驱动信号从静止图像中生成角色视频。
图片到视频的难点在于:保持角色详细信息的一致性(consistency)

实测: 鸣人跳兔子舞

相关研究
-
DreamPose 专注于时尚图像到视频的合成,并提出了一个适应模块来融合图像中的CLIP和VAE特征。但是缺点是需要
微调模型来保持生成图片的一致性。 -
DisCo : 探索人类的舞蹈生成,通过CLIP整合角色的特征(integrating character features),并通过ControlNet结合·背景特征·。然而,它在保留角色的细节方面存在缺陷,并且存在
帧间抖动问题。 -
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
能根据给的静态图片生成图片,未能从图像中捕获复杂的细节,提供更多的多样性,但缺乏精度,特别是在应用于角色动画时,导致角色外观的细粒度细节的时间变化 -
ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models 和T2I-Adapter
通过在stable diffusion上添加额外的编码层来生成视觉的可控性。促进各种条件下的受控生成,如姿势、蒙版、边缘和深度 -
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
使扩散模型能够保持给定图像的特点,生成提示指定的内容的图像。 -
23.02
GEN1: Runway : 基于扩散模型的结构和内容引导视频合成 Structure and Content-Guided Video Synthesis with Diffusion Models -
TryOnDiffusion: 23.06 A Tale of Two UNets
将扩散模型应用于虚拟服装试穿任务,并引入并行unet结构。 -
Emu Video:Meta提出 23.11 Factorizing Text-to-Video Generation by Explicit Image Conditioning
与之前的作品相比,该方法生成512像素、每秒16帧、4秒长视频,在Quality和Faithfulness上都取得了胜利:制作视频(MAV)、图像视频(Imagen)、Align Your Latents (AYL)、Reuse & Diffuse (R&D)、Cog Video (Cog)、Gen2和Pika Lab(Pika)
.
方法
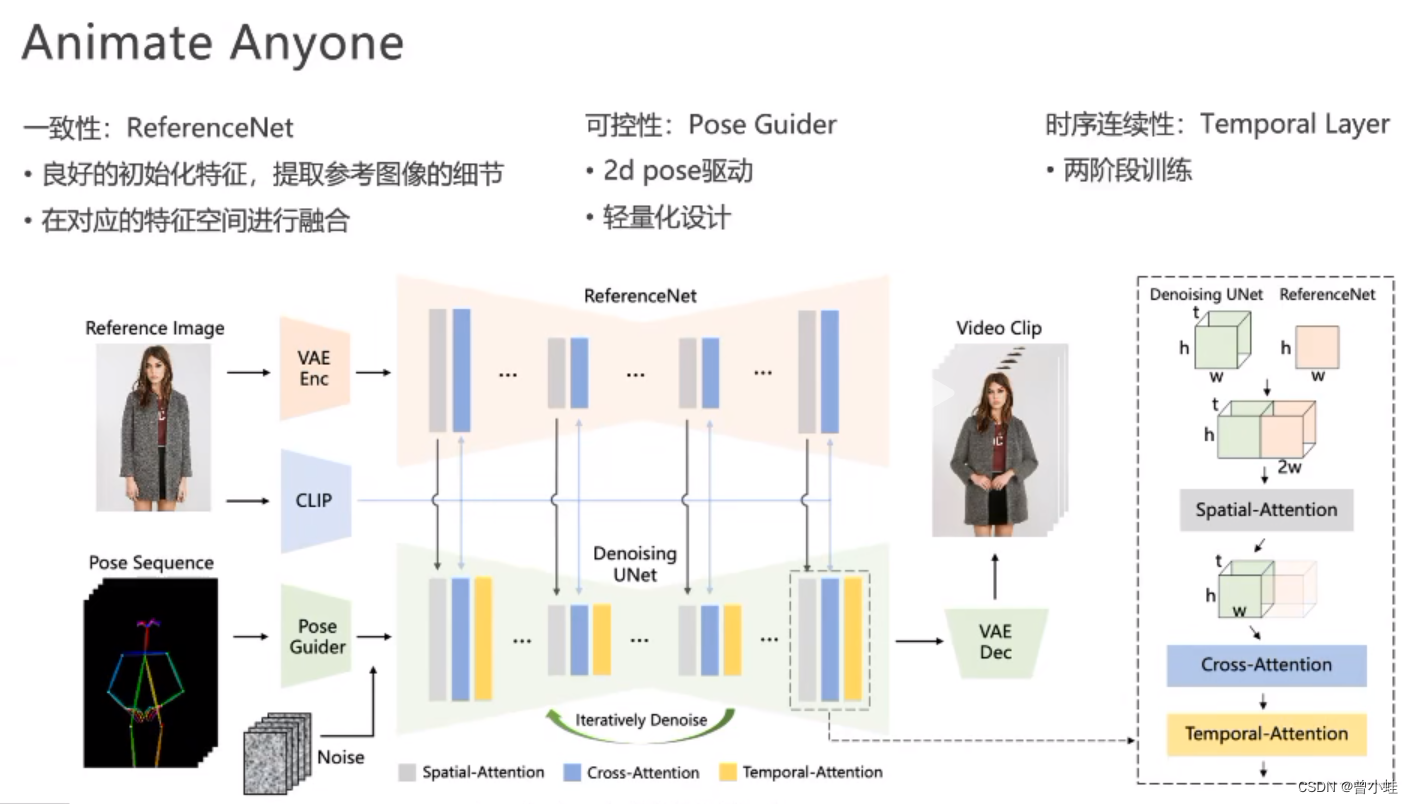
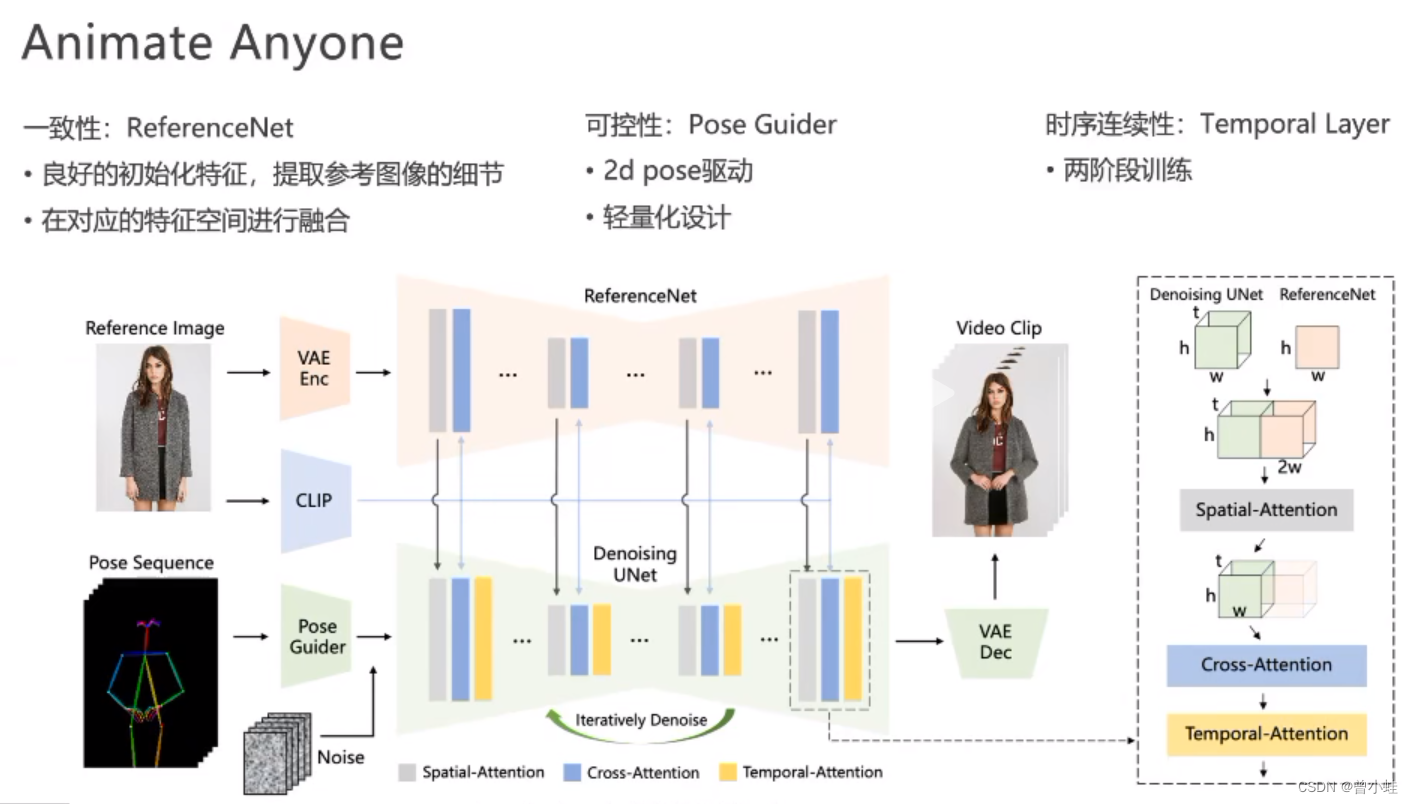
- 为了解决复杂的(intricate)外观特征的
一致性(appearance features),设计了ReferenceNet,并通过空间注意力模块(spatial attention)合并细节特征。
2.为了确保视频可控性和连续性(controllability and continuity),设计了姿态引导模块(pose guider)来指导角色的运动. - 为了确保视频帧之间的
平滑帧间转换(smooth inter-frame transitions),采用一种有效的时间建模(temporal modeling)方法
姿态序列(pose sequence)最初使用Pose Guider进行编码,并与多帧噪声融合,然后进行去噪UNet进行视频生成去噪过程。去噪UNet的计算块由空间注意、交叉注意和时间注意组成,如右边的虚线框所示。参考图像的集成涉及两个方面。首先,通过 ReferenceNet 提取详细的特征并用于 Spatial-Attention。其次,通过CLIP图像编码器提取语义特征进行交叉注意。时间注意在时间维度上运行。最后,VAE 解码器将结果解码为视频剪辑。
原作者胡立讲解
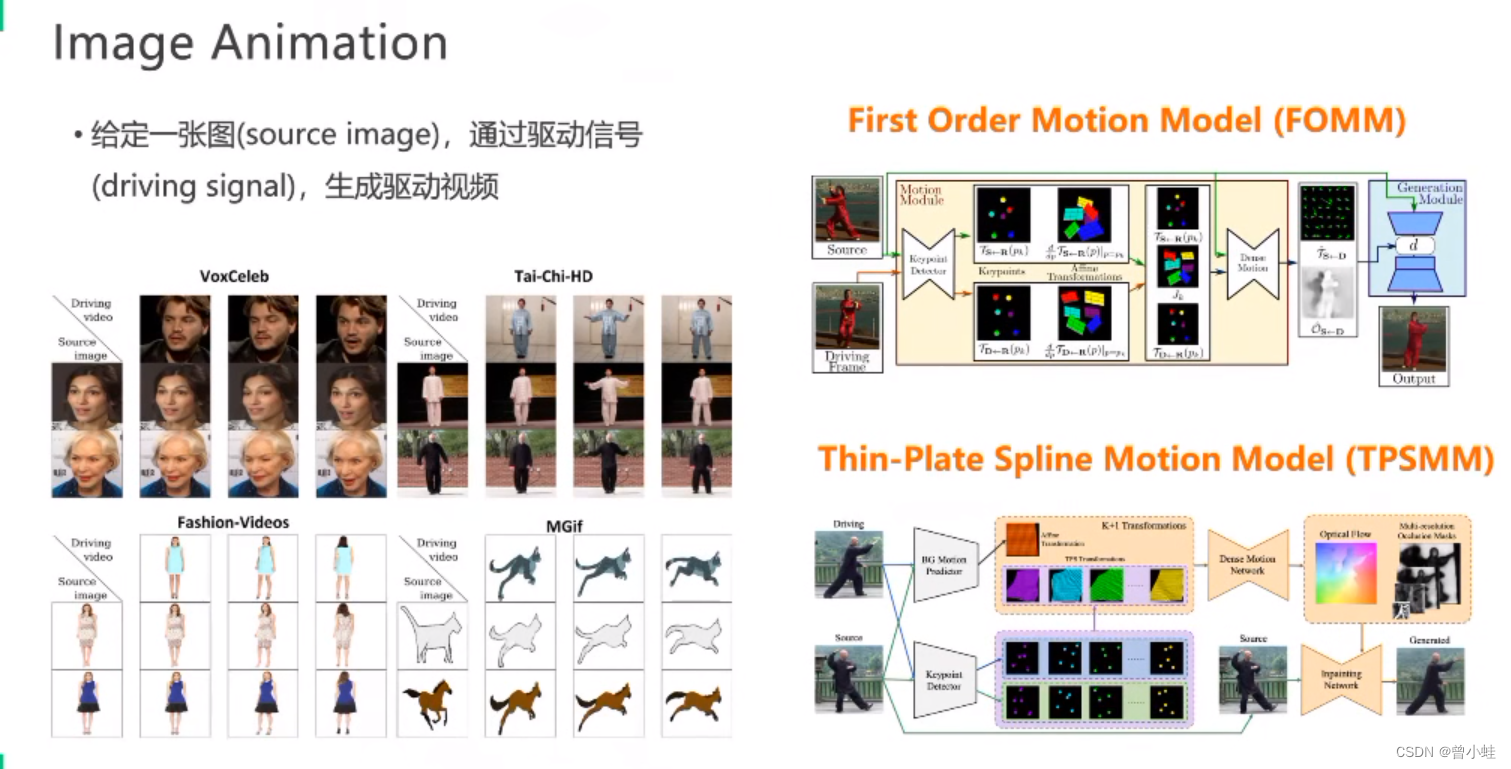
Image Animation
分析关键点、对运动过程建模、驱动
2019 FOMM
2022 TPSMM
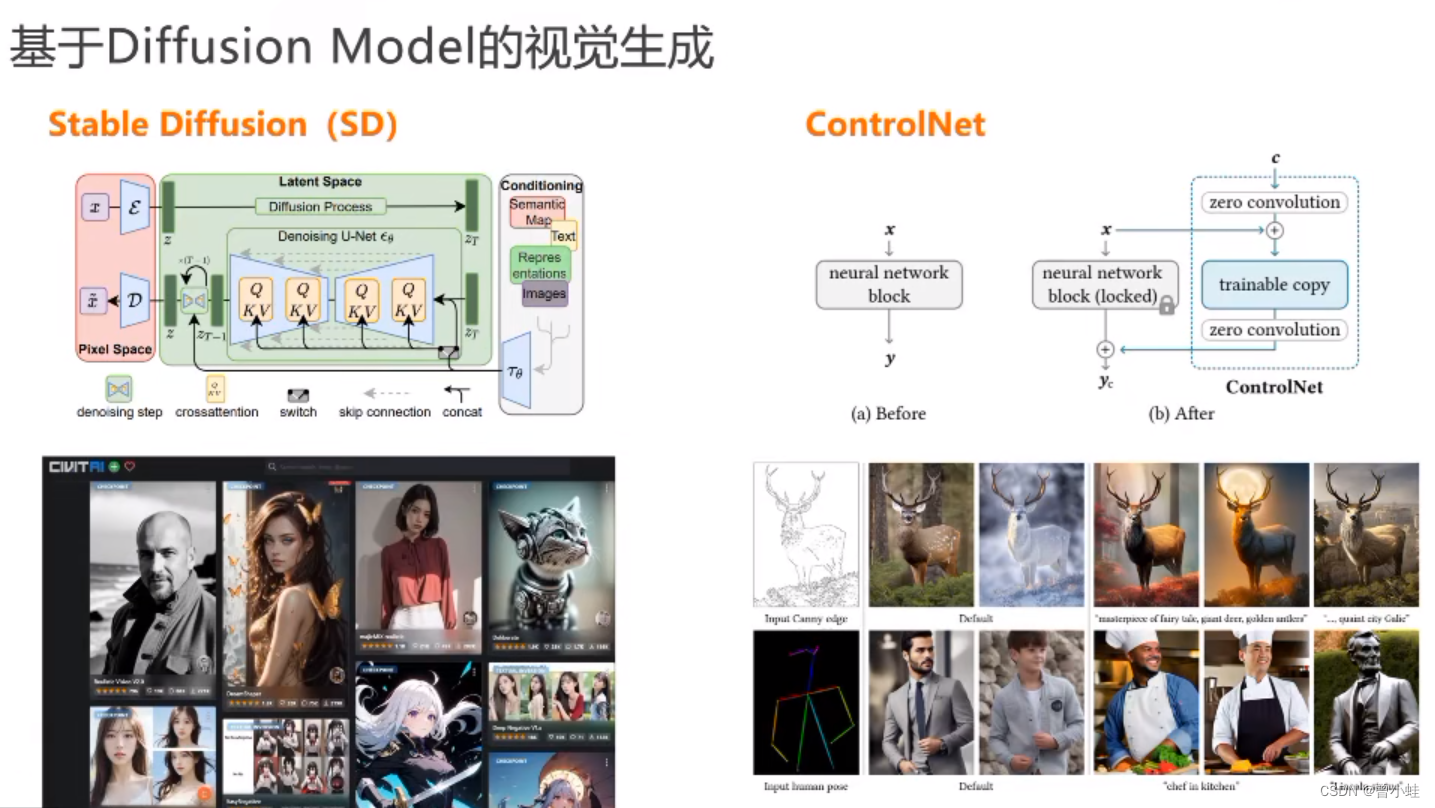
基于diffusion的图片生成模型0
代表工作为 stable diffusion +ControlNet (可控)
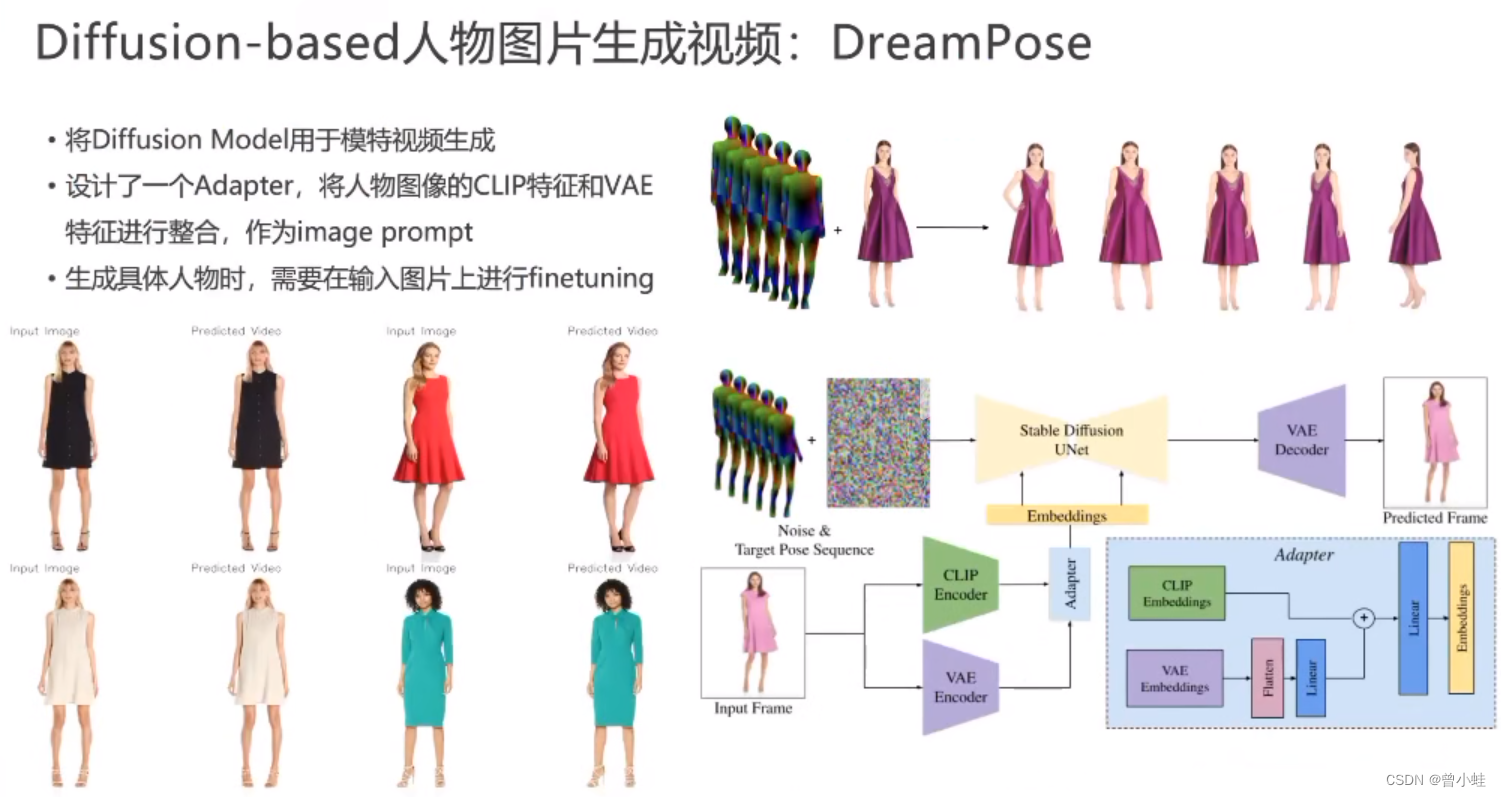
基于diffusion的视频生成
(DreamPose )
输入tuning
主要还是模特、连续性不好
23.07 DicCo(跳舞)
驱动跳舞、视频不连续, 一致性不好

图像生成一致性改进:TryonDiffusion
生成的效果特别好
有效的图片特征

视觉内容一致性: Emu Video
人物效果一般,长时一致性不厚好

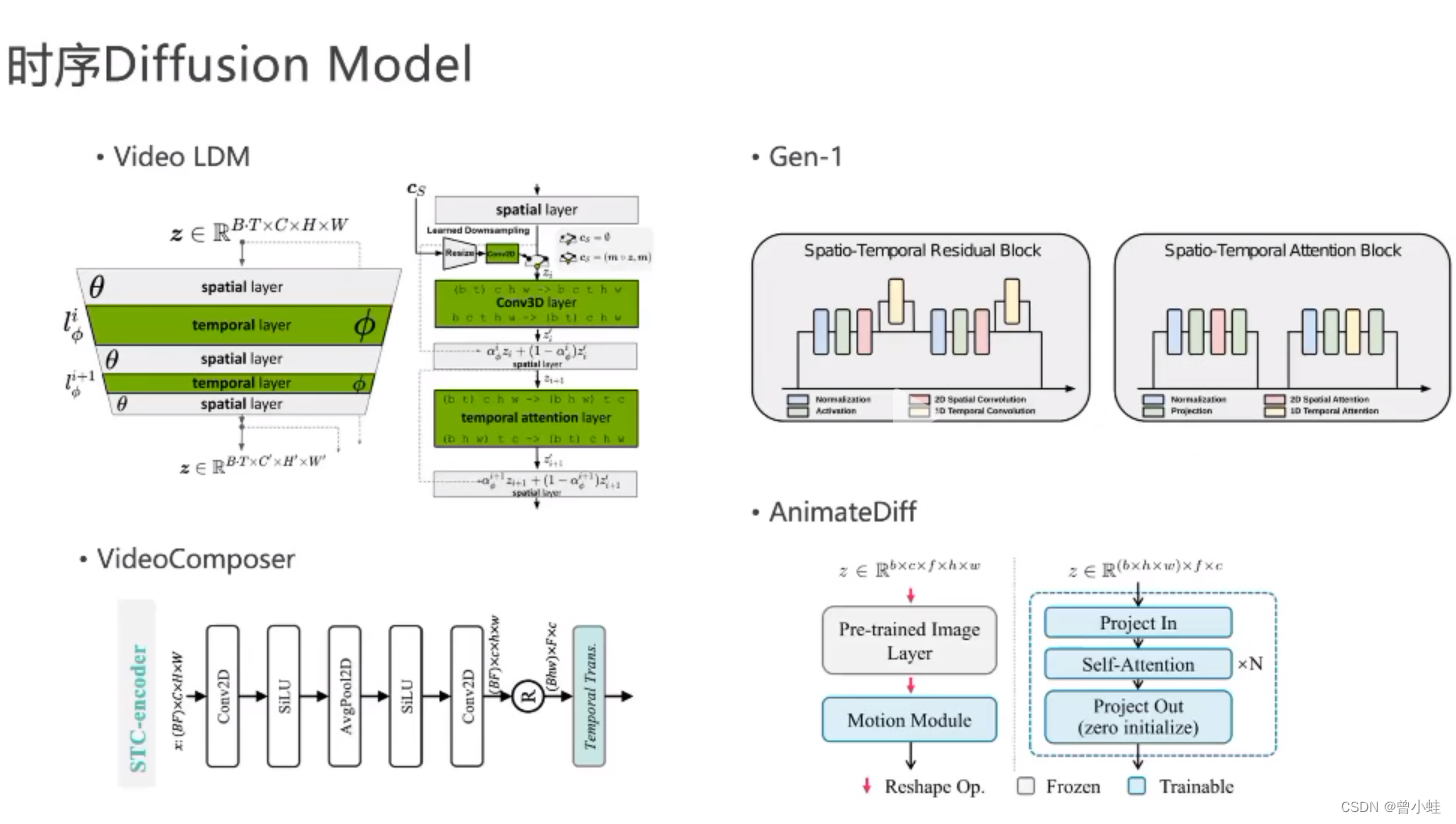
*时序的diffusion model (逐渐成熟)
video LDM
Gen-1
videoComposer
AnimateDiff
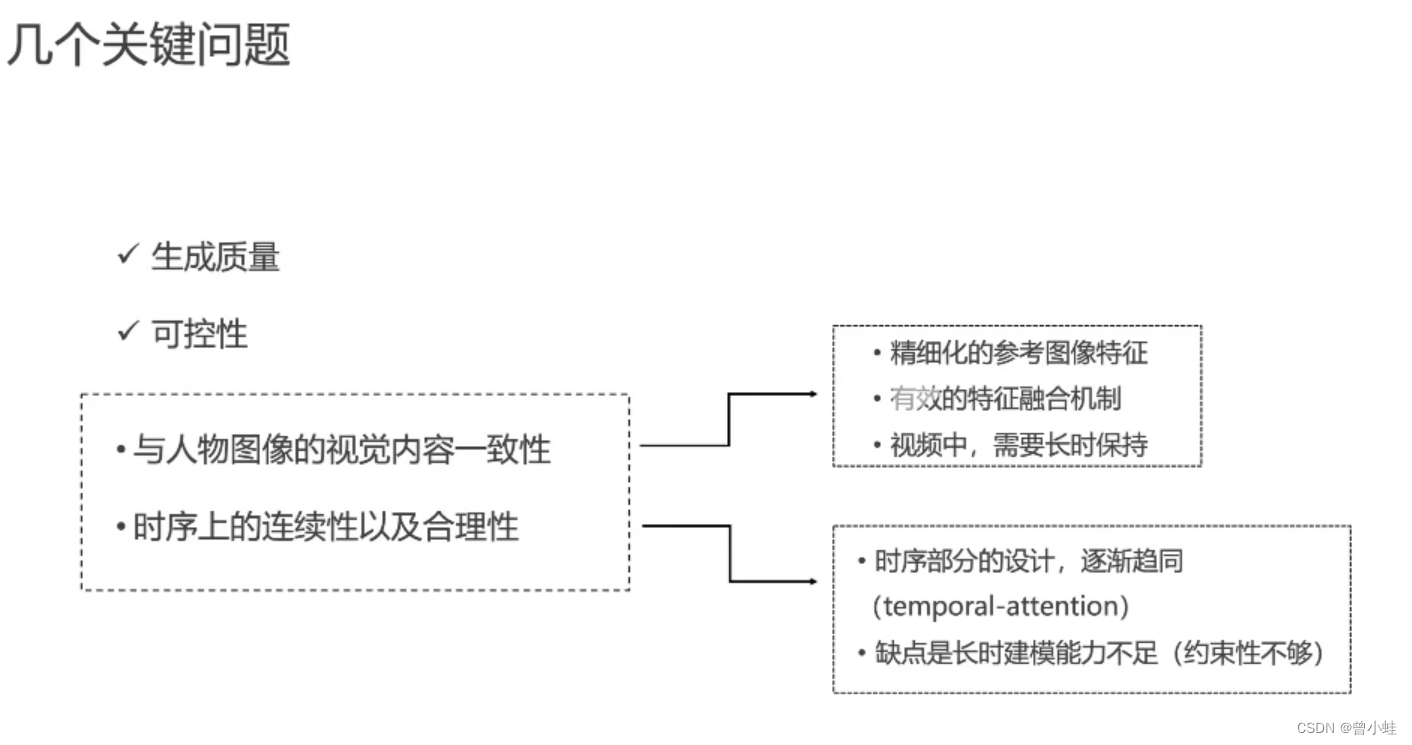
对上面方法总结
diffusion模型的生成与可控能力,但是之前的方法效果不稳定
Animate Anyone 算法原理
ReferenceNet 、PoseGuider 、Temporal Layer
输入:任务参考图片、驱动任务pose序列
denosing unet 就是stable diffusion的扩展
CLIP 提取图片语意特征、ReferenceNet 提取的是图像细节
问题:看不见地方,手部的精细度
效果

驱动2次元受到用户欢迎

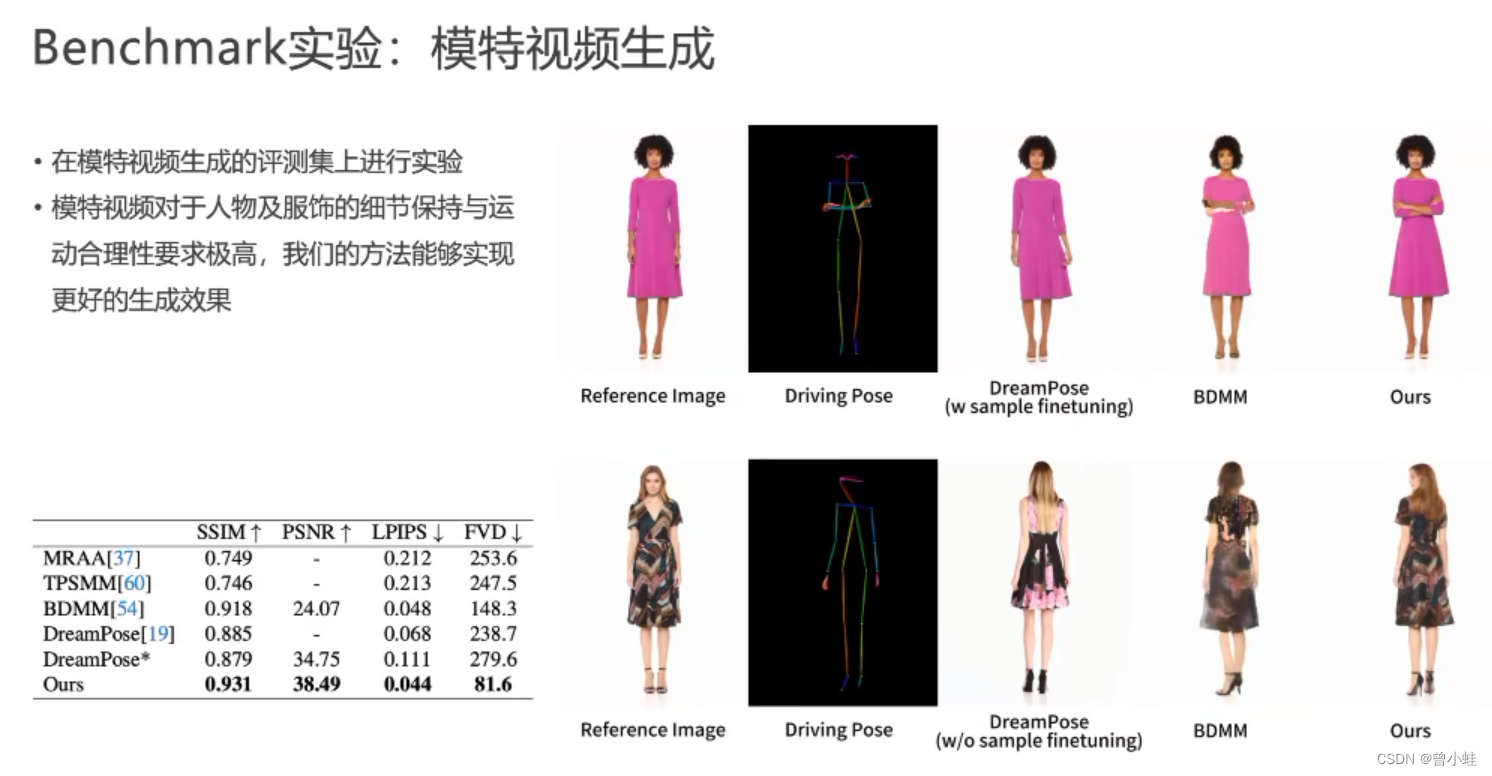
在量化的模特视频上
应用案例
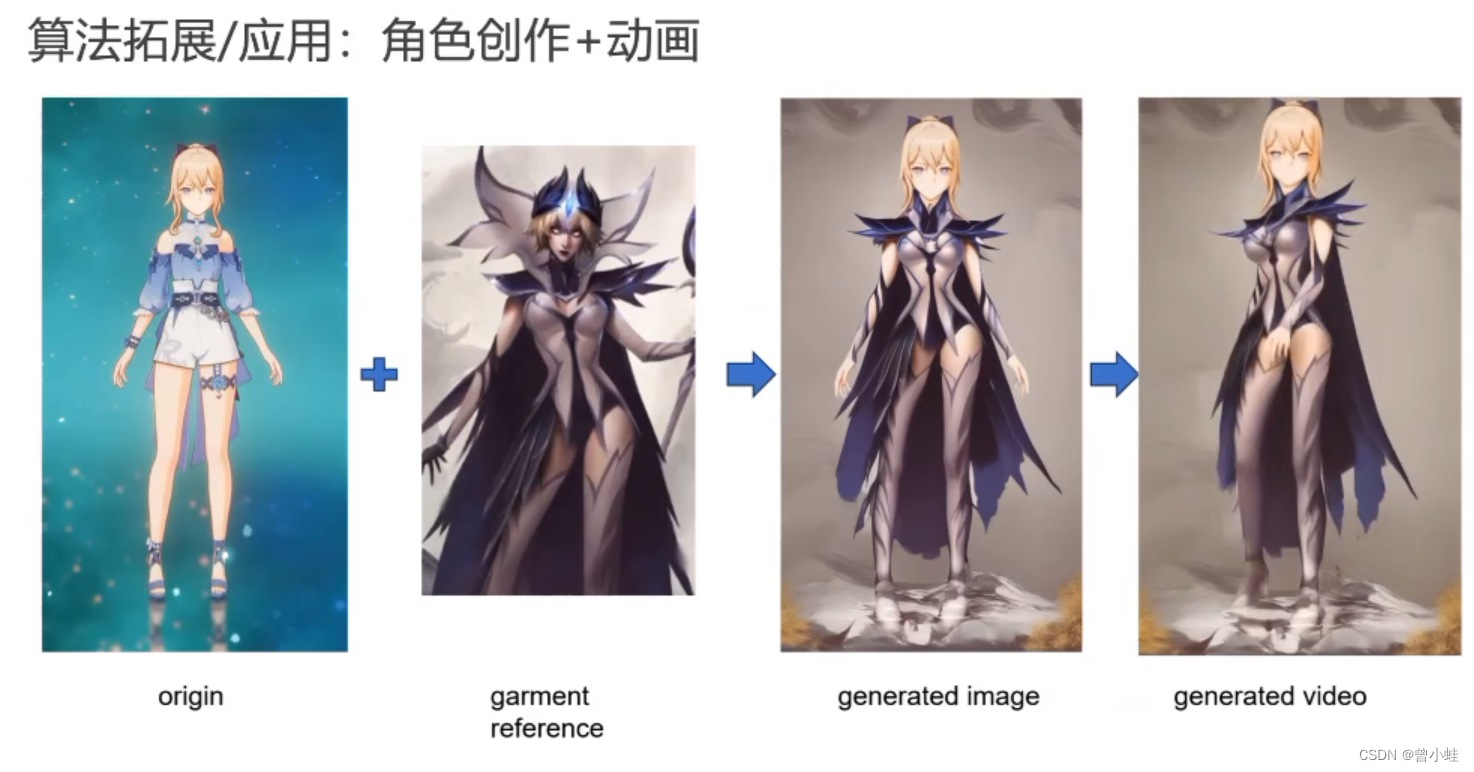
结合换衣(outfit-anything),角色皮肤设计
试穿+电商

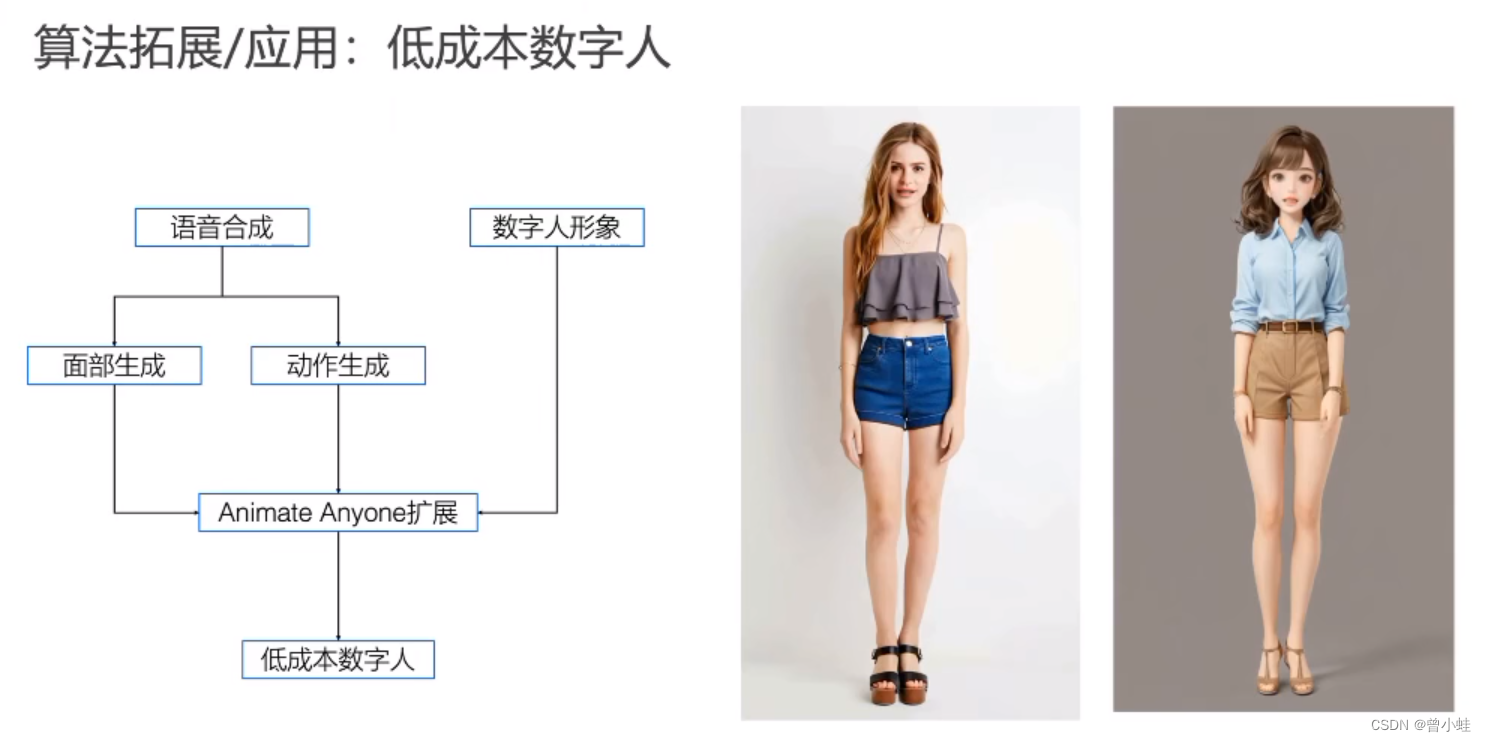
数字人相关
团队建设

![[蓝桥杯]真题讲解:飞机降落(DFS枚举)](https://img-blog.csdnimg.cn/direct/f50adb77971e43cbb10e9f003690f064.png)






![[蓝桥杯]真题讲解:景区导游(DFS遍历、图的存储、树上前缀和与LCA)](https://img-blog.csdnimg.cn/direct/a3ab31c6740240ffba2b08041a19000d.png)