传奇开心果短博文系列
- 系列短博文目录
- Python的OpenCV库技术点案例示例短博文系列
- 短博文目录
- 一、项目目标
- 二、OpenCV物体检测与识别介绍
- 三、分别示例代码
- 四、扩展示例代码
系列短博文目录
Python的OpenCV库技术点案例示例短博文系列
短博文目录
一、项目目标
 物体检测与识别:包括人脸识别、目标检测、目标跟踪等功能。OpenCV
物体检测与识别:包括人脸识别、目标检测、目标跟踪等功能。OpenCV
二、OpenCV物体检测与识别介绍
 OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。在物体检测与识别领域,OpenCV可以用于实现包括人脸识别、目标检测、目标跟踪等功能。
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。在物体检测与识别领域,OpenCV可以用于实现包括人脸识别、目标检测、目标跟踪等功能。
以下是一些常见的物体检测与识别功能,可以使用OpenCV实现:
-
人脸检测与识别:OpenCV提供了基于Haar特征的级联分类器(Cascade Classifier),可以用于检测和识别人脸。通过使用训练好的级联分类器,可以在图像或视频中检测出人脸,并进行人脸识别和人脸特征提取。
-
目标检测:OpenCV提供了多种目标检测算法,如基于Haar特征的级联分类器、HOG(Histogram of Oriented Gradients)、DNN(Deep Neural Networks)等。这些算法可以用于检测图像或视频中的不同类型的目标,如车辆、行人、动物等。
-
目标跟踪:OpenCV提供了多种目标跟踪算法,如基于光流的方法(如Lucas-Kanade光流算法)、基于特征匹配的方法(如SIFT、SURF)以及基于深度学习的方法(如DeepSORT)。这些算法可以用于跟踪目标在视频序列中的位置和运动。
除了上述功能,OpenCV还提供了其他图像处理和计算机视觉的功能,如图像滤波、边缘检测、图像分割、特征提取、图像配准等。它支持多种5编程语言,如C++、Python、Java等,并且具有跨平台的特性,可以在不同的操作系统上使用。
三、分别示例代码
以下是使用OpenCV进行人脸识别、目标检测和目标跟踪的示例代码:
 1. 人脸识别示例代码:
1. 人脸识别示例代码:
import cv2
# 加载级联分类器
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 加载图像
image = cv2.imread('face_image.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 标记人脸
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Face Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
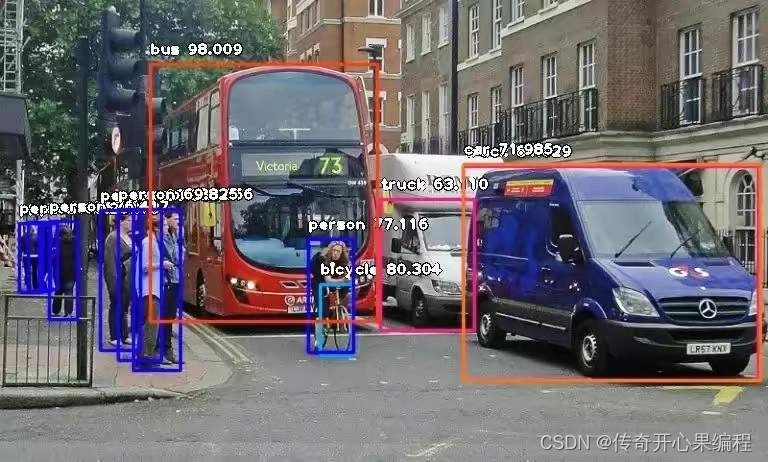 2. 目标检测示例代码:
2. 目标检测示例代码:
import cv2
# 加载级联分类器
car_cascade = cv2.CascadeClassifier('cars.xml')
# 加载视频
video = cv2.VideoCapture('car_video.mp4')
while True:
# 读取视频帧
ret, frame = video.read()
if not ret:
break
# 转换为灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 检测车辆
cars = car_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 标记车辆
for (x, y, w, h) in cars:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Car Detection', frame)
if cv2.waitKey(1) == ord('q'):
break
# 释放资源
video.release()
cv2.destroyAllWindows()
 3. 目标跟踪示例代码:
3. 目标跟踪示例代码:
import cv2
import dlib
# 加载目标跟踪器
tracker = dlib.correlation_tracker()
# 加载视频
video = cv2.VideoCapture('object_video.mp4')
# 读取第一帧
ret, frame = video.read()
if not ret:
exit()
# 选择目标区域
bbox = cv2.selectROI(frame, False)
# 初始化目标跟踪器
tracker.start_track(frame, dlib.rectangle(*bbox))
while True:
# 读取视频帧
ret, frame = video.read()
if not ret:
break
# 更新目标跟踪器
tracker.update(frame)
pos = tracker.get_position()
# 提取目标位置
x = int(pos.left())
y = int(pos.top())
w = int(pos.width())
h = int(pos.height())
# 标记目标
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Object Tracking', frame)
if cv2.waitKey(1) == ord('q'):
break
# 释放资源
video.release()
cv2.destroyAllWindows()
请注意,示例代码中使用的级联分类器和训练数据文件(如haarcascade_frontalface_default.xml和cars.xml)可以从OpenCV官方网站或其他资源库中获取。目标跟踪示例中使用了dlib库,你需要确保已经安装了dlib库。
四、扩展示例代码
当涉及到物体检测与识别时,OpenCV提供了许多功能和算法,可以根据不同的需求进行扩展和定制。以下是一些示例代码,演示了如何使用OpenCV进行更高级的物体检测与识别:
 1. 使用深度学习模型进行目标检测:
1. 使用深度学习模型进行目标检测:
import cv2
# 加载预训练的深度学习模型
net = cv2.dnn.readNetFromCaffe('deploy.prototxt', 'model.caffemodel')
# 加载图像
image = cv2.imread('object_image.jpg')
# 创建一个blob,将图像输入到网络中
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300), 127.5)
# 设置输入层
net.setInput(blob)
# 运行前向传播,获取输出层
detections = net.forward()
# 解析检测结果
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.5:
# 提取边界框坐标
box = detections[0, 0, i, 3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
(startX, startY, endX, endY) = box.astype("int")
# 绘制边界框和置信度
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.putText(image, text, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 显示结果
cv2.imshow("Object Detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
 2. 使用深度学习模型进行人脸识别:
2. 使用深度学习模型进行人脸识别:
import cv2
# 加载预训练的深度学习模型和人脸特征向量
net = cv2.dnn.readNetFromTorch('model.t7')
embeddings = np.load('embeddings.npy')
# 加载图像
image = cv2.imread('face_image.jpg')
# 人脸检测
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 对每个人脸进行识别
for (x, y, w, h) in faces:
face = image[y:y+h, x:x+w]
face_blob = cv2.dnn.blobFromImage(face, 1.0, (96, 96), (0, 0, 0), swapRB=True, crop=False)
# 提取人脸特征向量
net.setInput(face_blob)
vec = net.forward().flatten()
# 计算与已知特征向量的欧氏距离
dists = np.linalg.norm(embeddings - vec, axis=1)
min_dist_idx = np.argmin(dists)
min_dist = dists[min_dist_idx]
# 判断是否匹配
if min_dist < threshold:
label = labels[min_dist_idx]
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(image, label, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
else:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 2)
cv2.putText(image, 'Unknown', (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)
# 显示结果
cv2.imshow("Face Recognition", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
这些示例代码展示了如何使用OpenCV结合深度学习模型进行目标检测和人脸识别。你可以根据自己的需求,选择适合的深度学习模型和训练数据,并根据实际情况进行相应的调整和定制。
 3.使用OpenCV进行目标跟踪的示例代码:
3.使用OpenCV进行目标跟踪的示例代码:
import cv2
# 创建跟踪器
tracker = cv2.TrackerCSRT_create()
# 加载视频
video = cv2.VideoCapture('object_video.mp4')
# 选择初始目标区域
ret, frame = video.read()
bbox = cv2.selectROI(frame, False)
# 初始化跟踪器
tracker.init(frame, bbox)
while True:
# 读取视频帧
ret, frame = video.read()
if not ret:
break
# 跟踪目标
success, bbox = tracker.update(frame)
if success:
# 绘制跟踪结果
(x, y, w, h) = [int(v) for v in bbox]
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
else:
cv2.putText(frame, "Tracking failure detected", (100, 80), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
# 显示结果
cv2.imshow("Object Tracking", frame)
if cv2.waitKey(1) == ord('q'):
break
# 释放资源
video.release()
cv2.destroyAllWindows()
在这个示例中,我们使用了OpenCV的TrackerCSRT跟踪器来实现目标跟踪。首先,我们从视频中选择了一个初始目标区域,并使用该区域初始化跟踪器。然后,我们在每一帧中更新跟踪器,并绘制跟踪结果。
请注意,OpenCV还提供了其他几种跟踪器,如TrackerKCF、TrackerMOSSE等。你可以根据具体的需求选择最适合的跟踪器。
希望这个示例代码对你有所帮助。如果你有更多问题,请随时提问。