JVM/GC
- JVM
- GC
- 垃圾回收算法
- 1.引用计数法
- 2.标记清除发
- 3.标记压缩算法
- 4.复制算法
- 5.分代算法
- 收集器
- 1.串行垃圾收集器
- 2.并行垃圾收集器
- 2.CMS垃圾收集器
- 3.G1垃圾收集器(重点)jdk1.7开始1.9默认的回收器
- Young GC模式
- Mixed GC
- Full GC
JVM
待更新中ing
GC
垃圾回收:程序运行的时候必然需要申请内存的资源,无效的对象资源如果不及时进行处理的就会一直占用内存资源,最终导致内存溢出
java语言中有自动的垃圾回收机制就是GC
垃圾回收算法
1.引用计数法
原理:假设有一个对象A,任何一个对象对A的引用,那么对象A的引用计数器+1,当引用失败的时候,对象A的引用计数器就-1,如果对象A的计数器值为0,就是说明A没有被引用,可以被回收了
优点:
1.实用性较高,无需等到内存不够的时候,才可以进行回收,运行的时候根据对象的计数器是否为0,就可以直接进行回收了
2.在垃圾回收的过程中,引用无需挂起,如果申请内存的时候内存不足,则会立即outofmenber错误
3.区域性,更新对象的计数器的时候,只是影响到该对象,不会扫描全部的对象
缺点:
1.对象每次被引用的时候,都需要去更新计数器,有一定时间的开销
2.浪费cpu资源,即使是内存足够的情况下,任然运行时进行着计数器的统计
3.无法解决循环引用的问题(最大的缺点)
循环引用
A a = new A();
B b = new B();
a.b=b;
b.a=a;
a=null;
b=null;
2.标记清除发
是将垃圾护手分为2个阶段,分别为标记和清除
1.标记:从根节点开始标记引用的对象
2.清除:未被标记引用的对象就是垃圾回收对象,可以被清理
暂停程序线程,没有被标记的对象会被回收清除掉然后被标记的对象留下来并进行重置变为未标记的状态,恢复程序线程,程序继续运行
优点:
1.解决了循环引用的问题
缺点:
1.效率比较低,标记和清除2个动作都是需要遍历所有的对象,并且再GC的时候需要暂停应用程序,对于交互性要求高的应用而言这个体验是非常差的
2.通过标记清除的算法清理出来的内存,碎片化比较严重,因为被回收的对象可能存在于内存的各个角落,所以清理出来内存是不连贯的
3.标记压缩算法
再标记清除算法的基础之上做的优化,和标记清除算法一样,也是从根节点开始,对对象的应用进行标记,在清理的阶段,并不是简单地清理未标记的对象,而是将存货的对象压缩到哦内存的一段,然后清理边界意外的垃圾,从而解决碎片化的问题
优点:解决了标记清除法里面而定碎片化问题
缺点:标记压缩算法多了一个压缩的步骤,这样就会导致其中的清除的整体效率受到了影响
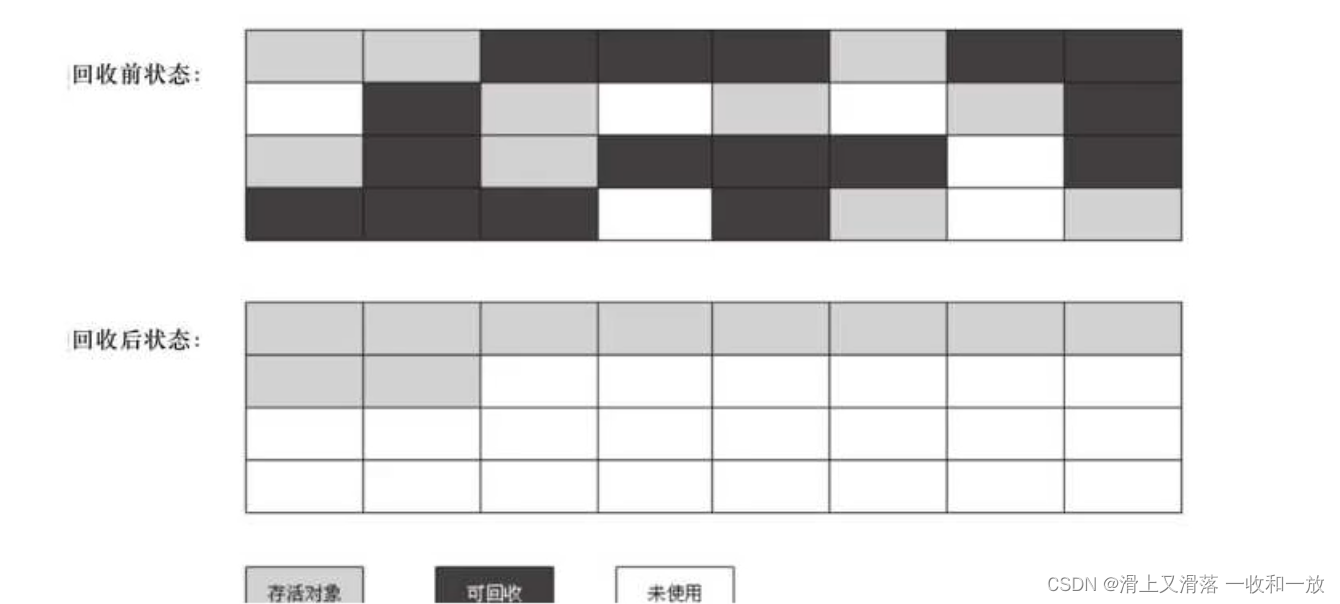
4.复制算法
复制算法的核心是:将原有的内存空间一分为二,每次只用到其中的一块,在垃圾回收的时候,将正在使用的对象复制到另一个内存空间中,然后将该内存空间清空,交换内存的角色,完成垃圾回收
如果内存的垃圾对象比较多的情况下需要复制的对象比较少,这种情况下是和使用这个方式并且效率比较高反之不适用
优点:
1.在垃圾对象多的情况下,效率高
2.清理以后,内存无碎片
缺点:
1.再垃圾对象少的时候不适合
2.分配的2块内存空间,再同一时刻只能使用一半,内存使用率较低
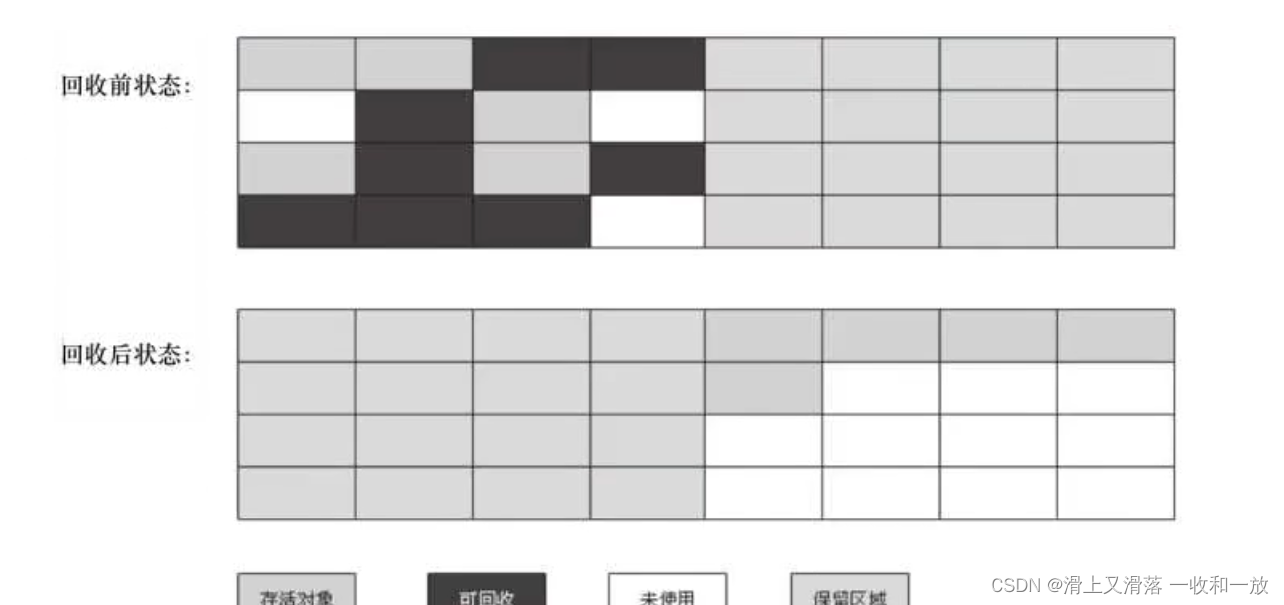
5.分代算法
分代算法指的是根据回收对象的特点进行选择,再jvm中,年轻代适合复制算法,老年代适合标记清除或者标记压缩算法
| 算法 | 优点 | 缺点 | 说明 |
|---|---|---|---|
| 引用计数法 | 1.实用性较高,无需等到内存不够的时候,才可以进行回收,运行的时候根据对象的计数器是否为0,就可以直接进行回收了 2.在垃圾回收的过程中,引用无需挂起,如果申请内存的时候内存不足,则会立即outofmenber错误 3.区域性,更新对象的计数器的时候,只是影响到该对象,不会扫描全部的对象 | 1.对象每次被引用的时候,都需要去更新计数器,有一定时间的开销2.浪费cpu资源,即使是内存足够的情况下,任然运行时进行着计数器的统计 3.无法解决循环引用的问题(最大的缺点) | 假设有一个对象A,任何一个对象对A的引用,那么对象A的引用计数器+1,当引用失败的时候,对象A的引用计数器就-1,如果对象A的计数器值为0,就是说明A没有被引用,可以被回收了 |
| 标记清除算法 | 1.解决了循环引用的问题 | 1.效率比较低,标记和清除2个动作都是需要遍历所有的对象,并且再GC的时候需要暂停应用程序,对于交互性要求高的应用而言这个体验是非常差的 2.通过标记清除的算法清理出来的内存,碎片化比较严重,因为被回收的对象可能存在于内存的各个角落,所以清理出来内存是不连贯的 | 是将垃圾护手分为2个阶段,分别为标记和清除1.标记:从根节点开始标记引用的对象2.清除:未被标记引用的对象就是垃圾回收对象,可以被清理;暂停程序线程,没有被标记的对象会被回收清除掉然后被标记的对象留下来并进行重置变为未标记的状态,恢复程序线程,程序继续运行 |
| 标记压缩算法 | 解决了标记清除法里面而定碎片化问题 | 标记压缩算法多了一个压缩的步骤,这样就会导致其中的清除的整体效率受到了影响 | 再标记清除算法的基础之上做的优化,和标记清除算法一样,也是从根节点开始,对对象的应用进行标记,在清理的阶段,并不是简单地清理未标记的对象,而是将存货的对象压缩到哦内存的一段,然后清理边界意外的垃圾,从而解决碎片化的问题 |
| 复制算法 | 1.在垃圾对象多的情况下,效率高 2.清理以后,内存无碎片 | 1.再垃圾对象少的时候不适合 2.分配的2块内存空间,再同一时刻只能使用一半,内存使用率较低 | 将原有的内存空间一分为二,每次只用到其中的一块,在垃圾回收的时候,将正在使用的对象复制到另一个内存空间中,然后将该内存空间清空,交换内存的角色,完成垃圾回收 |
| 分代算法 | – | – | 分代算法指的是根据回收对象的特点进行选择,再jvm中,年轻代适合复制算法,老年代适合标记清除或者标记压缩算法 |
收集器
| 参数 | 说明 |
|---|---|
| -XX:UseSerialGC | 指定的年轻代和老年代都使用串行垃圾收集器 |
| -XX:+PrintGCDetails | 打印垃圾回收的详细信息 |
| -XX:UseParallelGC | 年轻代使用ParallelGC垃圾回收期,老年代使用串行回收器 |
| -XX:UseParallelOldGC | 年轻代使用ParallelGC垃圾回收期,老年代使用ParallelOld垃圾回收器 |
| -XX:MaxGCPauseMillis | (设置最大的垃圾收集时候的停顿时间,单位毫秒,需要注意的是ParallelGC为了达到设置的停顿时间,可能会调整堆的大小或者其他的参数,如果堆的大小设置的比较小,就会导致GC工作变得很频繁,反而可能会影响到性能,这个参数使用的时候需要谨慎处理) |
| -XX:GCTimeRatio | (设置垃圾回收时间占程序运行时间的百分比,公式:1/(1+n),他的值为0~100之间的数字,默认值为99,也就是垃圾回收事假不能超过1%) |
| -XX:UseAdaptiveSizePolicy | (自适应GC模式,垃圾回收器将会自动的调整新生代,老年代等参数,达到吞吐量,堆大小,停顿时间之间的平衡;一般用于手动的调整比较困难的场景,让收集器自动的进行调整) |
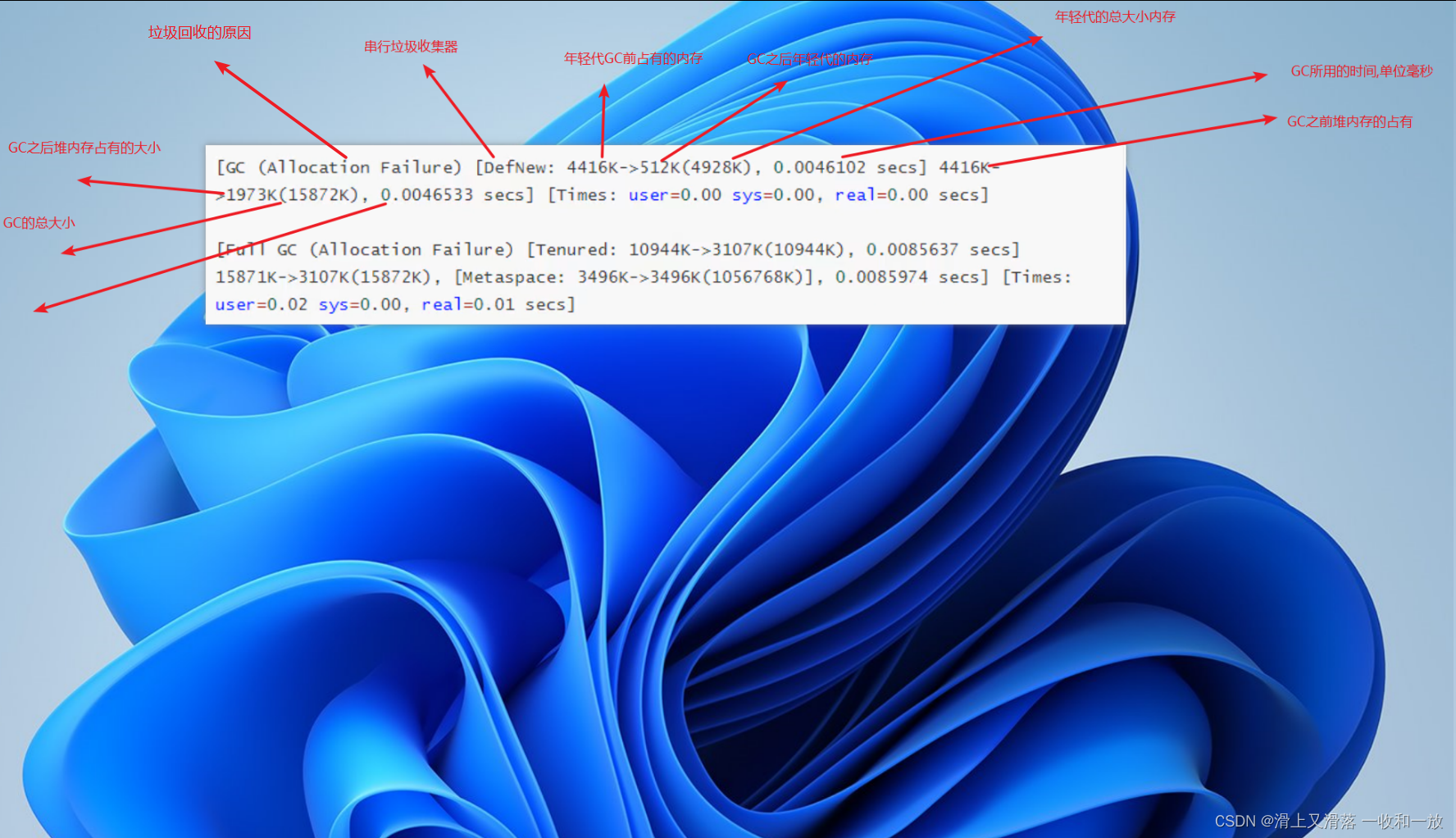
| 参数 | 解读 | 冒号后面的内容解释 |
|---|---|---|
| DefNew | 表示使用的是串行垃圾收集器 | 4416K->512K(4928K)====>表示年轻代GC占用的内存是4416K内存,GC之后占用512K内存总大小4928K;0.0046102 secs =====>表示的是GC所用的时间单位毫秒 ; |
| -XX:+PrintGCDetails | 打印垃圾回收的详细信息 | – |
1.串行垃圾收集器
指的是单线程进行的垃圾回收,垃圾回收的时候只有一个线程在进行工作,并且java应用中的所有的线程都需要进行暂停,等待垃圾回收的完成这个现象叫做STW-----这个应用的场景特别少
在程序运行的过程中添加2个参数即可
1.-XX:+UseSerialGC(指定的年轻代和老年代都使用串行垃圾收集器)
2.-XX:+PrintGCDetails(打印垃圾回收的详细信息)

//设置堆的初始和最大内存值为16M 串行收集器
-XX:+UseSerialGC -XX:+PrintGCDetails -Xms16m -Xmx16m
2.并行垃圾收集器
并行的垃圾收集器再创航的垃圾收集器的基础上做的改进,将单线程改为多线程的垃圾回收,这样缩短回收的时间,这里的手机过程也是会暂停应用程序的
1.ParNew垃圾收集器
ParNew垃圾收集器是工作再年轻代上的,只是将串行的垃圾收集器改为并行的
通过:-XX:+UseParNewGC参数设置年轻代使用ParNew回收期,老年代使用的依然是串行收集器
2.ParallelGC垃圾收集器
ParallelGC收集器工作机制和ParNew收集器一样,只是在此基础上,新增了2个和系统吞吐量相关的参数,使得其使用起来更加的灵活和高效
相关参数:
-XX:UseParallelGC(年轻代使用ParallelGC垃圾回收期,老年代使用串行回收器)
-XX:UseParallelOldGC(年轻代使用ParallelGC垃圾回收期,老年代使用ParallelOld垃圾回收器)
-XX:MaxGCPauseMillis(设置最大的垃圾收集时候的停顿时间,单位毫秒,需要注意的是ParallelGC为了达到设置的停顿时间,可能会调整堆的大小或者其他的参数,如果堆的大小设置的比较小,就会导致GC工作变得很频繁,反而可能会影响到性能,这个参数使用的时候需要谨慎处理)
-XX:GCTimeRatio(设置垃圾回收时间占程序运行时间的百分比,公式:1/(1+n),他的值为0~100之间的数字,默认值为99,也就是垃圾回收事假不能超过1%)
-XX:UseAdaptiveSizePolicy(自适应GC模式,垃圾回收器将会自动的调整新生代,老年代等参数,达到吞吐量,堆大小,停顿时间之间的平衡;一般用于手动的调整比较困难的场景,让收集器自动的进行调整)

2.CMS垃圾收集器
是一款并发,使用标记清除算法的垃圾回收器该回收器是针对老年代垃圾回收的,通过参数-XX:+UseConcMarkSweepGC进行设置的
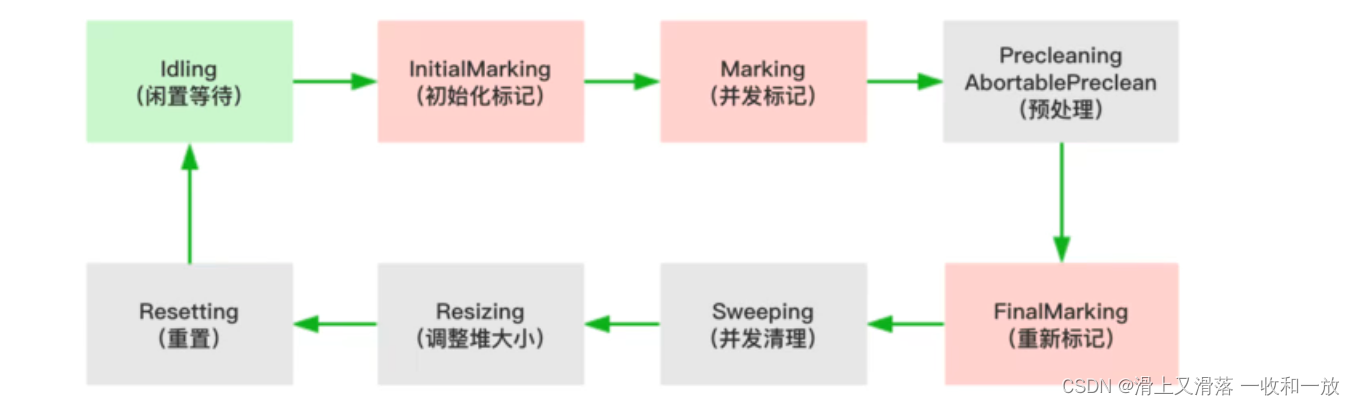
CMS垃圾回收器的执行过程如下
初始化标记:标记root,会导致stw(程序暂停上面有解释)
并发标记,与用户线程同时运行
预清理与用户线程同时运行
重新标记,会导致stw
并发清除,与用户线程同时运行
调整堆大小,设置CMS再清理之后进行内存压缩,目的是清理内存中的碎片
并发重置状态等待下次CMS的触发,与用户线程同时运行

3.G1垃圾收集器(重点)jdk1.7开始1.9默认的回收器
G1的设计原则就是简化jvm性能调优,三步调优
1.开启G1垃圾收集器
2.设置堆的最大内存
3.设置最大的停顿时间
三种模式Young GC ,Mixed GC 和Full GC
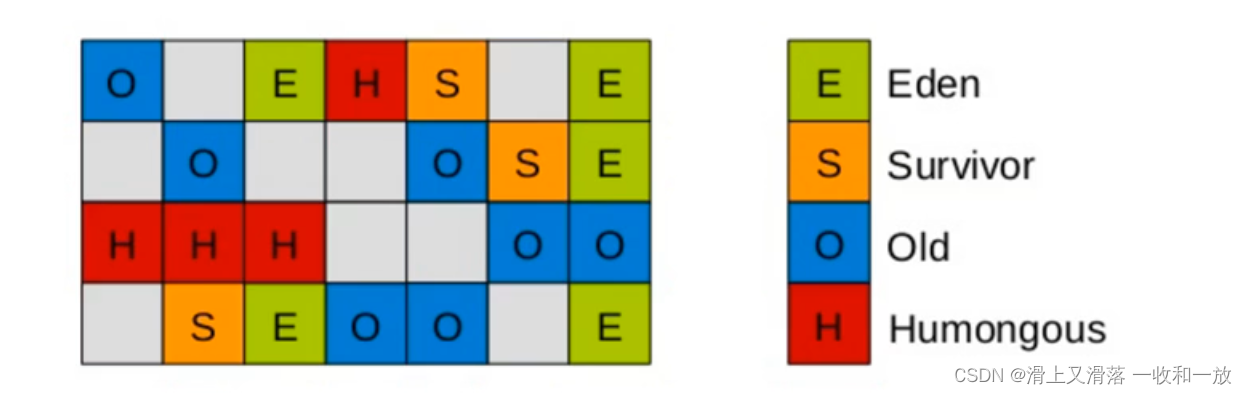
相比于其他的垃圾收集器,最大的区别在于他取消了年轻代,老年代的物理划分,取而代之的是将堆划分为若干个区域,这些区域中包含了有逻辑上的年轻代和老年代区域
这样做的好处就是,不需要单独的空间对每一个代进行设置,不需要担心每个代内存是否足够的问题
在G1划分的区域中,年轻代的垃圾收集器依然是采用stw的方式,将存活对象拷贝到老年代或者Survivor空间,G1收集器通过将对象从一个区域复制到另外一个区域完成清理的工作
这就意味着在正常处理过程中,G1完成了堆的压缩,这样也就不会有cms内存碎片的问题存在了
Humongous
1.如果一个对象占用的空间超过了分区容量的50%以上,G1收集器就认为这是一个巨型对象
2.这些巨型对象,默认直接会被分配到老年代,但是如果他是一个短期存在的巨型对象,就会对垃圾收集器造成负面的影响
3.为了解决这个问题,G1划分了一个Humongous区,他是专门的存放巨型对象的,如果一个H村放不下巨型对象,那么就会寻找连续的H分区来进行存储,为了能找到连续的H区有时候就得启动Full GC
Young GC模式
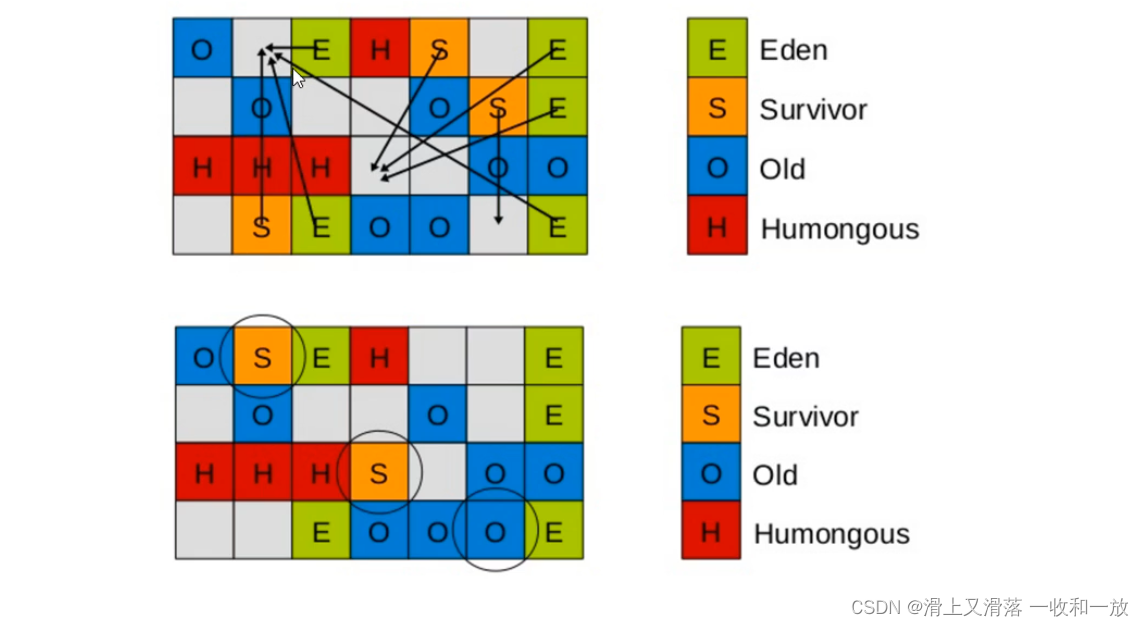
主要是对Eden区进行GC,他在Eden空间耗尽时候会被触发
1.Eden空间的数据移动到Survivor空间中,如果Survivor空间不够,Eden空间的部分数据会直接晋升为老年代空间
2.Survivor区的数据移动到新的Survivor区中,也会有部分的数据晋升为老年代空间中
3.最终Eden空间的数据为空,GC停止空间,应用线程继续执行






![[pytorch入门] 2. tensorboard](https://img-blog.csdnimg.cn/direct/81e5d2ae868f4f7787eaefef0fe0056b.png)