第五部分、数组和广义表详解

数组和广义表,都用于存储逻辑关系为“一对一”的数据。
数组存储结构,99% 的编程语言都包含的存储结构,用于存储不可再分的单一数据;而广义表不同,它还可以存储子广义表。
本章重点从矩阵的角度讨论二维数组的存储,同时讲解广义表的存储结构以及有关其广度和深度的算法实现。
十三、广义表的深度和长度(C语言)详解
前面学习了广义表及其对应的存储结构,本节来学习如何计算广义表的深度和长度,以及如何编写相应的 C 语言实现程序。
1、广义表的长度
广义表的长度,指的是广义表中所包含的数据元素的个数。
由于广义表中可以同时存储原子和子表两种类型的数据,因此在计算广义表的长度时规定,广义表中存储的每个原子算作一个数据,同样每个子表也只算作是一个数据。
例如,在广义表 {a,{b,c,d}} 中,它包含一个原子和一个子表,因此该广义表的长度为 2。
再比如,广义表 {{a,b,c}} 中只有一个子表 {a,b,c},因此它的长度为 1。
前面我们用 LS={a1,a2,...,an} 来表示一个广义表,其中每个 ai 都可用来表示一个原子或子表,其实它还可以表示广义表 LS 的长度为 n。
广义表规定,空表 {} 的长度为 0。
在编程实现求广义表长度时,由于广义表的存储使用的是链表结构,且有以下两种方式(如图 1 所示):

图 1 存储 {a,{b,c,d}} 的两种方式
对于图 1a) 来说,只需计算最顶层(红色标注)含有的节点数量,即可求的广义表的长度。
同理,对于图 1b) 来说,由于其最顶层(蓝色标注)表示的此广义表,而第二层(红色标注)表示的才是该广义表中包含的数据元素,因此可以通过计算第二层中包含的节点数量,即可求得广义表的长度。
由于两种算法的实现非常简单,这里只给出计算图 1a) 中广义表长度的 C 语言实现代码:
#include<stdio.h>
#include<stdlib.h>
typedef struct GLNode {
int tag;//标志域
union {
char atom;//原子结点的值域
struct {
struct GLNode* hp, * tp;
}ptr;//子表结点的指针域,hp指向表头;tp指向表尾
}subNode;
}*Glist;
Glist creatGlist(Glist C) {
//广义表C
C = (Glist)malloc(sizeof(Glist));
C->tag = 1;
//表头原子‘a’
C->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.hp->tag = 0;
C->subNode.ptr.hp->subNode.atom = 'a';
//表尾子表(b,c,d),是一个整体
C->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->tag = 1;
C->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->subNode.ptr.tp = NULL; /
/开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d)
C->subNode.ptr.tp->subNode.ptr.hp->tag = 1;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->tag = 0;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->subNode.atom = 'b';
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));
//存放子表(c,d),表头为c,表尾为d
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->tag = 1;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->tag = 0;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'c';
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));
//存放表尾d
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->tag = 1;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->tag = 0;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'd';
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.tp = NULL;
return C;
}
int GlistLength(Glist C) {
int Number = 0; Glist P = C;
while (P) {
Number++;
P = P->subNode.ptr.tp;
}
return Number;
}
int main() {
Glist C = NULL;
C = creatGlist(C);
printf("广义表的长度为:%d", GlistLength(C));
}
程序运行结果为:
广义表的长度为:2
2、广义表的深度
广义表的深度,可以通过观察该表中所包含括号的层数间接得到。
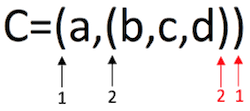
图 2 广义表示意图
从图 2 中可以看到,此广义表从左往右数有两层左括号(从右往左数也是如此),因此该广义表的深度为 2。
再比如,广义表 {{1,2},{3,{4,5}}} 中,子表 {1,2} 和 {3,{4,5}} 位于同层,此广义表中包含 3 层括号,因此深度为 3。
以上观察括号的方法需将广义表当做字符串看待,并借助栈存储结构实现,这里不做重点介绍。
编写程序计算广义表的深度时,以图 1a) 中的广义表为例,可以采用递归的方式:
- 依次遍历广义表 C 的每个节点,若当前节点为原子(tag 值为 0),则返回 0;若为空表,则返回 1;反之,则继续遍历该子表中的数据元素。
- 设置一个初始值为 0 的整形变量 max,每次递归过程返回时,令 max 与返回值进行比较,并取较大值。这样,当整个广义表递归结束时,max+1 就是广义表的深度。
其实,每次递归返回的值都是当前所在的子表的深度,原子默认深度为 0,空表默认深度为 1。
C 语言实现代码如下:
#include <stdio.h>
#include <stdlib.h>
typedef struct GLNode {
int tag;//标志域
union {
char atom;//原子结点的值域
struct {
struct GLNode* hp, * tp;
}ptr;//子表结点的指针域,hp指向表头;tp指向表尾
}subNode;
}*Glist, GNode;
Glist creatGlist(Glist C) {
//广义表C
C = (Glist)malloc(sizeof(Glist));
C->tag = 1;
//表头原子‘a’
C->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.hp->tag = 0;
C->subNode.ptr.hp->subNode.atom = 'a';
//表尾子表(b,c,d),是一个整体
C->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->tag = 1;
C->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->subNode.ptr.tp = NULL;
//开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d)
C->subNode.ptr.tp->subNode.ptr.hp->tag = 1;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->tag = 0;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->subNode.atom = 'b';
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));
//存放子表(c,d),表头为c,表尾为d
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->tag = 1;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->tag = 0;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'c';
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));
//存放表尾d
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->tag = 1;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->tag = 0;
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'd';
C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.tp = NULL;
return C;
}
int GlistDepth(Glist C) {
//如果表C为空表时,直接返回长度1;
if (!C) {
return 1;
}
//如果表C为原子时,直接返回0;
if (C->tag == 0) {
return 0;
}
int max = 0;//设置表C的初始长度为0;
for (Glist pp = C; pp; pp = pp->subNode.ptr.tp) {
int dep = GlistDepth(pp->subNode.ptr.hp);
if (dep > max) {
max = dep;//每次找到表中遍历到深度最大的表,并用max记录
}
}
//程序运行至此处,表明广义表不是空表,由于原子返回的是0,而实际长度是1,所以,此处要+1;
return max + 1;
}
int main(int argc, const char* argv[]) {
Glist C = NULL;
C = creatGlist(C);
printf("广义表的深度为:%d", GlistDepth(C));
return 0;
}
程序运行结果:
广义表的深度为:2
十四、广义表的复制详解(含C语言代码实现)
对于任意一个非空广义表来说,都是由两部分组成:表头和表尾。反之,只要确定的一个广义表的表头和表尾,那么这个广义表就可以唯一确定下来。
复制一个广义表,也是不断的复制表头和表尾的过程。如果表头或者表尾同样是一个广义表,依旧复制其表头和表尾。
所以,复制广义表的过程,其实就是不断的递归,复制广义表中表头和表尾的过程。
递归的出口有两个:
- 如果当前遍历的数据元素为空表,则直接返回空表。
- 如果当前遍历的数据元素为该表的一个原子,那么直接复制,返回即可。
还拿广义表 C 为例:
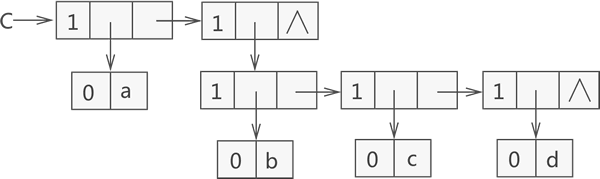
图1 广义表 C 的结构示意图
代码实现:
#include <stdio.h>
#include <stdlib.h>
typedef struct GLNode{
int tag;//标志域
union{
char atom;//原子结点的值域
struct{
struct GLNode * hp,*tp;
}ptr;//子表结点的指针域,hp指向表头;tp指向表尾
};
}*Glist,GNode;
Glist creatGlist(Glist C){
//广义表C
C=(Glist)malloc(sizeof(GNode));
C->tag=1;
//表头原子‘a’
C->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.hp->tag=0;
C->ptr.hp->atom='a';
//表尾子表(b,c,d),是一个整体
C->ptr.tp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->tag=1;
C->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->ptr.tp=NULL;
//开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d)
C->ptr.tp->ptr.hp->tag=1;
C->ptr.tp->ptr.hp->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->ptr.hp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.hp->atom='b';
C->ptr.tp->ptr.hp->ptr.tp=(Glist)malloc(sizeof(GNode));
//存放子表(c,d),表头为c,表尾为d
C->ptr.tp->ptr.hp->ptr.tp->tag=1;
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.tp->ptr.hp->atom='c';
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp=(Glist)malloc(sizeof(GNode));
//存放表尾d
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->tag=1;
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp=(Glist)malloc(sizeof(GNode));
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp->tag=0;
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.hp->atom='d';
C->ptr.tp->ptr.hp->ptr.tp->ptr.tp->ptr.tp=NULL;
return C;
}
void copyGlist(Glist C, Glist *T){
//如果C为空表,那么复制表直接为空表
if (!C) {
*T=NULL;
}
else
{
*T=(Glist)malloc(sizeof(GNode));//C不是空表,给T申请内存空间
//申请失败,程序停止
if (!*T) {
exit(0);
}
(*T)->tag=C->tag;//复制表C的tag值
//判断当前表元素是否为原子,如果是,直接复制
if (C->tag==0) {
(*T)->atom=C->atom;
}else{
//运行到这,说明复制的是子表
copyGlist(C->ptr.hp, &((*T)->ptr.hp));//复制表头
copyGlist(C->ptr.tp, &((*T)->ptr.tp));//复制表尾
}
}
}
int main(int argc, const char * argv[]) {
Glist C=NULL;
C=creatGlist(C);
Glist T=NULL; copyGlist(C,&T);
printf("%c",T->ptr.hp->atom);
return 0;
}
运行结果:
a
1、总结
在实现复制广义表的过程中,实现函数为:
void copyGlist(Glist C, Glist *T);
其中,Glist *T,等同于: struct GLNode* *T,此为二级指针,不是一级指针。在主函数中,调用此函数时,传入的是指针 T 的地址,而不是 T 。
这里使用的是地址传递,而不是值传递。如果在这里使用值传递,会导致广义表 T 丢失结点,复制失败。
![[pytorch入门] 2. tensorboard](https://img-blog.csdnimg.cn/direct/81e5d2ae868f4f7787eaefef0fe0056b.png)