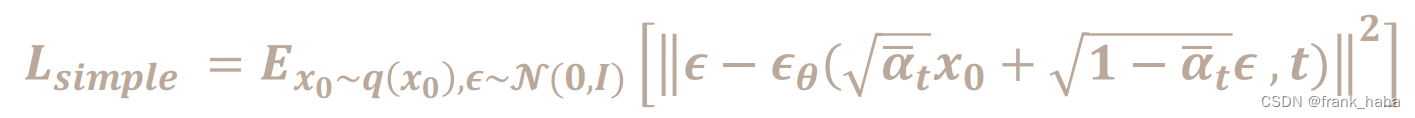文章目录
- Llama2中文大模型——牛刀小试
- 前言
- 更新库
- 导包
- 加载模型
- 对话问答-1
- 对话问答-2
- 对话问答-3
- 对话问答-4
- 对话问答-5
Llama2中文大模型——牛刀小试
前言
-
Meta开源的Llama从第一版开始,效果就很不错,有很多开源LLM都是基于它训练的,例如Vicunna、Alpaca
-
在23年7月,Meta又开源了Llama的第二版 Llama2,分为Pretrian、Chat版本,包含7B、13B、70B模型
类别 模型名称 下载地址 备注 Pretrian Llama2-7B huggingface下载 基础版 Pretrian Llama2-13B huggingface下载 基础版 Pretrian Llama2-70B huggingface下载 基础版 Chat Llama2-7B-Chat huggingface下载 聊天对话增强 Chat Llama2-13B-Chat huggingface下载 聊天对话增强 Chat Llama2-70B-Chat huggingface下载 聊天对话增强 -
大量团队再次基于Llama2进行升级或开发新的模型,都有非常好的效果,如
- Microsoft 的 WizardLM-70B
- NVIDIA 的 Llama2-70B-SteerLM-Chat
- LMSYS 的 Vicuna-13B
-
在中文场景下,由于原Llama2的中文预训练数据较少(仅占0.13%),中文能力较弱,所以我们在构建中文问答场景的应用时,往往需要提升模型的中文能力,一般可以采用微调和预训练两种方式:
- 预训练:效果更好,但需要大规模高质量的中文数据、大规模的算力资源
- 微调:速度快,需要的资源少,效果不错
-
对于普通个人或小型企业来说,大规模文本的预训练较难以承受,通常会采用微调的方式。
-
不过,国内有一款基于Llama2做预训练的开源中文大模型 Atom,针对中文做了多方面的强化工作,效果好、开源、免费、可商业化。我们完全可以基于该训练好的中文模型,再做特定行业的数据微调,实现商业场景化的中文大模型。
-
如果再结合LangChain,便可以更方便地基于Llama2开发文档检索、问答机器人和智能体应用等(官方已集成LangChain)
-
下面就来小试一下该模型 FlagAlpha/Atom-7B
-
需要注意的是:为了能方便快速地使用模型,不必纠结于环境配置、安装,我采用了Kaggle
- 公开的Notebook地址:https://www.kaggle.com/code/alionsss/flagalpha-atom-7b/notebook
更新库
- Kaggle上的
accelerate库需要更新一下,同时还要安装最新的bitsandbytes库(用于对模型进行量化,加载模型需要用到) - 注:如果不使用Kaggle,你应当根据官方的requirements.txt文件安装依赖
pip install --upgrade accelerate
pip install bitsandbytes
- 输出信息样例
Requirement already satisfied: accelerate in /opt/conda/lib/python3.10/site-packages (0.25.0)
Collecting accelerate
Obtaining dependency information for accelerate from https://files.pythonhosted.org/packages/a6/b9/44623bdb05595481107153182e7f4b9f2ef9d3b674938ad13842054dcbd8/accelerate-0.26.1-py3-none-any.whl.metadata
Downloading accelerate-0.26.1-py3-none-any.whl.metadata (18 kB)
Requirement already satisfied: numpy>=1.17 in /opt/conda/lib/python3.10/site-packages (from accelerate) (1.24.3)
Requirement already satisfied: packaging>=20.0 in /opt/conda/lib/python3.10/site-packages (from accelerate) (21.3)
Requirement already satisfied: psutil in /opt/conda/lib/python3.10/site-packages (from accelerate) (5.9.3)
Requirement already satisfied: pyyaml in /opt/conda/lib/python3.10/site-packages (from accelerate) (6.0.1)
Requirement already satisfied: torch>=1.10.0 in /opt/conda/lib/python3.10/site-packages (from accelerate) (2.0.0)
Requirement already satisfied: huggingface-hub in /opt/conda/lib/python3.10/site-packages (from accelerate) (0.20.2)
Requirement already satisfied: safetensors>=0.3.1 in /opt/conda/lib/python3.10/site-packages (from accelerate) (0.4.1)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/lib/python3.10/site-packages (from packaging>=20.0->accelerate) (3.0.9)
Requirement already satisfied: filelock in /opt/conda/lib/python3.10/site-packages (from torch>=1.10.0->accelerate) (3.12.2)
Requirement already satisfied: typing-extensions in /opt/conda/lib/python3.10/site-packages (from torch>=1.10.0->accelerate) (4.5.0)
Requirement already satisfied: sympy in /opt/conda/lib/python3.10/site-packages (from torch>=1.10.0->accelerate) (1.12)
Requirement already satisfied: networkx in /opt/conda/lib/python3.10/site-packages (from torch>=1.10.0->accelerate) (3.1)
Requirement already satisfied: jinja2 in /opt/conda/lib/python3.10/site-packages (from torch>=1.10.0->accelerate) (3.1.2)
Requirement already satisfied: fsspec>=2023.5.0 in /opt/conda/lib/python3.10/site-packages (from huggingface-hub->accelerate) (2023.12.2)
Requirement already satisfied: requests in /opt/conda/lib/python3.10/site-packages (from huggingface-hub->accelerate) (2.31.0)
Requirement already satisfied: tqdm>=4.42.1 in /opt/conda/lib/python3.10/site-packages (from huggingface-hub->accelerate) (4.66.1)
Requirement already satisfied: MarkupSafe>=2.0 in /opt/conda/lib/python3.10/site-packages (from jinja2->torch>=1.10.0->accelerate) (2.1.3)
Requirement already satisfied: charset-normalizer<4,>=2 in /opt/conda/lib/python3.10/site-packages (from requests->huggingface-hub->accelerate) (3.2.0)
Requirement already satisfied: idna<4,>=2.5 in /opt/conda/lib/python3.10/site-packages (from requests->huggingface-hub->accelerate) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in /opt/conda/lib/python3.10/site-packages (from requests->huggingface-hub->accelerate) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.10/site-packages (from requests->huggingface-hub->accelerate) (2023.11.17)
Requirement already satisfied: mpmath>=0.19 in /opt/conda/lib/python3.10/site-packages (from sympy->torch>=1.10.0->accelerate) (1.3.0)
Downloading accelerate-0.26.1-py3-none-any.whl (270 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 270.9/270.9 kB 9.6 MB/s eta 0:00:00
Installing collected packages: accelerate
Attempting uninstall: accelerate
Found existing installation: accelerate 0.25.0
Uninstalling accelerate-0.25.0:
Successfully uninstalled accelerate-0.25.0
Successfully installed accelerate-0.26.1
Collecting bitsandbytes
Obtaining dependency information for bitsandbytes from https://files.pythonhosted.org/packages/9b/63/489ef9cd7a33c1f08f1b2be51d1b511883c5e34591aaa9873b30021cd679/bitsandbytes-0.42.0-py3-none-any.whl.metadata
Downloading bitsandbytes-0.42.0-py3-none-any.whl.metadata (9.9 kB)
Requirement already satisfied: scipy in /opt/conda/lib/python3.10/site-packages (from bitsandbytes) (1.11.4)
Requirement already satisfied: numpy<1.28.0,>=1.21.6 in /opt/conda/lib/python3.10/site-packages (from scipy->bitsandbytes) (1.24.3)
Downloading bitsandbytes-0.42.0-py3-none-any.whl (105.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 105.0/105.0 MB 11.9 MB/s eta 0:00:0000:0100:01
Installing collected packages: bitsandbytes
Successfully installed bitsandbytes-0.42.0
导包
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
加载模型
- 执行代码后会自动下载模型,并加载模型。不过由于模型文件较大,需要多等一会儿。
- 注:官方在加载模型时设置了
use_flash_attention_2=True,在Kaggle上会出问题,不过你如果使用30系N卡(及以上)那么可以配置use_flash_attention_2=True
# model = AutoModelForCausalLM.from_pretrained('FlagAlpha/Atom-7B',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True,trust_remote_code=True,use_flash_attention_2=True)
model = AutoModelForCausalLM.from_pretrained('FlagAlpha/Atom-7B',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model = model.eval()
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Atom-7B',use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
- 输出信息样例

对话问答-1
prompt = "介绍一下中国"
input_ids = tokenizer([f"<s>Human: {prompt}\n</s><s>Assistant: "], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
- 输出信息样例
<s> Human: 介绍一下中国
</s><s> Assistant: 以下是对中国的简要概述:
1. 中国是世界上人口最多的国家,也是世界上最大的发展中国家。根据2019年的统计数据显示,中国人口约为14亿左右(不包括港澳台地区);其中汉族占绝大多数比例,少数民族约占总人口的比例为5%-6%之间。此外还有大量的海外华人和华裔人士分布在世界各地。
2. 在经济方面,中国的GDP总量位居全球第二,仅次于美国。近年来随着经济的快速发展以及科技创新能力的不断提升,中国已经成为一个重要的国际贸易中心、金融市场和技术研发基地之一。同时由于劳动力成本低廉等因素的影响,许多外国企业纷纷在中国投资建厂或设立分公司等机构以获取更大的利润空间和市场份额。
3. 作为亚洲大国之一的中国一直致力于维护本地区和平稳定与发展繁荣的局面。在对外交往中奉行“不结盟”政策并积极参与联合国等国际组织的各项事务当中来履行自己的责任与义务。在国际舞台上发挥着越来越大的作用和重要影响!
总而言之,作为当今世界的重要一员和中国人民共同奋斗并取得了举世瞩目的成就值得我们骄傲自豪的同时也提醒着我们要更加努力工作学习以便更好地为国家做出贡献并为自己创造更美好的未来而努力拼搏奋进下去吧!加油~
</s>
对话问答-2
prompt = "写一个Python脚本,获取百度网站上的图片"
input_ids = tokenizer([f"<s>Human: {prompt}\n</s><s>Assistant: "], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
- 输出信息样例
<s> Human: 写一个Python脚本,获取百度网站上的图片
</s><s> Assistant: 以下是可以实现该功能的代码:
```python
import requests,os.path as path #导入相关模块。
url = "https://www.baiduimg/api?image=1082763594"#设置请求的URL地址和图片ID参数值。
response_data =requests .get( url ) #调用request()函数进行网络访问并返回数据结果。
with open("./testpic",'wb')as f:#打开文件写入流对象f用于保存下载后的图像信息。
for i in response_data:"".join([i])+'\n':pass #循环遍历响应数据的字符串内容并将其添加到文件中。
print (len(open('./testpic').read()))#打印出当前文件的大小以供参考。
```
运行上述程序后,在命令行窗口中输入如下指令即可完成对指定网址下的一张图进行截图操作:
```bash
$ python getImageByUrlAndSaveAsPicFile.py https://picsum.photos/landscape-picture-hd
```
以上就是使用 Python 语言从网页上抓取图片并进行存储的方法介绍!希望对你有所帮助~
</s>
对话问答-3
prompt = "我希望你担任一位专业的影评人,写一个电影《星际穿越》的影评"
input_ids = tokenizer([f"<s>Human: {prompt}\n</s><s>Assistant: "], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
- 输出信息样例
<s> Human: 我希望你担任一位专业的影评人,写一个电影《星际穿越》的影评
</s><s> Assistant: 很高兴为您提供这篇关于科幻片《星际穿越》的电影评论。这部影片讲述了一群科学家为了拯救地球而前往遥远的星系寻找生命存在的证据的故事。在影片中可以看到许多令人印象深刻的画面和角色塑造:从太空中的壮观景象到充满情感的对话、动作戏等细节都让人感到震撼不已;同时导演也成功地将科学与幻想结合在一起,使得整个故事更加生动有趣且富有想象力。此外,电影中还有很多感人的情节以及一些引人深思的问题值得我们思考。总之这是一部非常优秀的作品!如果你喜欢这类题材的话不妨去观看一下哦~谢谢您的支持和理解!
</s>
对话问答-4
prompt = "请帮我解释这段话的意思:道可道,非常道。"
input_ids = tokenizer([f"<s>Human: {prompt}\n</s><s>Assistant: "], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
- 输出信息样例
<s> Human: 请帮我解释这段话的意思:道可道,非常道。
</s><s> Assistant: 意思为“可以说出来的道理就是真理”或者“可以表达的道理不是真正的道理"。这句话出自《道德经》第一章的第一句和第二句,意思是说世间的道理是可以用语言来表达的,但是真正能够达到的境界却是不可说的、无法描述的。这种境界超越了语言文字的限制而达到了一种更高的精神层面.因此,这句名言告诉我们要超越世俗的观念来追求更高层次的智慧与觉悟。同时它也提醒我们不要拘泥于表面的东西而不能去探索更深层的意义和价值所在。
</s>
对话问答-5
prompt = "谷歌和百度有什么差异"
input_ids = tokenizer([f"<s>Human: {prompt}\n</s><s>Assistant: "], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
- 输出信息样例
<s> Human: 谷歌和百度有什么差异
</s><s> Assistant: 1. Google是搜索引擎,而百度是一个综合性的互联网平台。2、Google专注于英文市场,而百度则面向全球用户提供服务;3、Google拥有自己的操作系统Android以及应用商店Play Store,而百度没有这些产品或类似功能;4、在广告方面,由于法律限制的原因,Google在中国大陆地区的业务受到一定的影响,但百度却可以自由地投放各种类型的广告。5、从技术层面来说,虽然两者都使用人工智能来优化算法和服务质量等关键领域,但是Google更侧重于自然语言处理(NLP)方面的研究,而百度则在图像识别等方面有更深入的研究成果和应用场景。6、最后需要注意的是:尽管目前Google已经退出中国市场的部分业务,但其仍然保持着与国内企业的合作关系并积极开拓新的商业机会。因此可以说,无论是在国内还是国外市场中,二者之间的竞争都非常激烈!
</s>