为了能够提前发现kubernetes集群的问题以及方便快捷的查询容器的各类参数,比如,某个pod的内存使用异常高企 等等这样的异常状态(虽然kubernetes有自动重启或者驱逐等等保护措施,但万一没有配置或者失效了呢),容器的内存使用量限制,过去10秒容器CPU的平均负载等等容器的运行参数,这些情况我们自然还是将kubernetes集群纳入到监控系统中好些,毕竟能够发现问题和解决问题更加的优雅嘛。
因此,我们需要能够有一个比较全面的监测容器运行的实时的监控系统,版本答案当然就是Prometheus了。Prometheus监控系统可以多维度的,方便的将我们需要的信息收集起来,然后通过Grafana做一个华丽的展示。
那么,对于容器这个对象来说,我们要使用的收集器就是cAdvisor啦,但cAdvisor这个收集器和node_exporter,mysqld_exporter 这些收集器不太一样,它是集成在kubelet这个服务内的,因此,我们不需要额外的安装cAdvisor收集器,也就是说不需要像node_exporter这样的系统信息收集器一样单独部署了,只要kubernetes的节点上有运行kubelet这个服务就可以了。
下面就kubernetes集群的Prometheus专用于容器的实时信息收集器cAdvisor如何认识它,如何部署它并集成到Prometheus内做一个详细的介绍。
一,
cAdvisor的简介
cAdvisor是一个谷歌开发的容器监控工具,它被内嵌到k8s中作为k8s的监控组件。cAdvisor对Node机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况,由于cAdvisor是集成在Kubelet中的,因此,当kubelet启动时会自动启动cAdvisor,即一个cAdvisor仅对一台Node机器进行监控。
当然也可以单独安装 cAdvisor 来监控只有docekr容器的机器而没有k8s集群环境的监控
二,其它的用于收集容器信息的信息收集器
heapster和Metrics server以及kube-state-metrics都可用于提供容器信息,但它们所提供的信息维度是不同的,heapster已经被Metrics server所取代 了,如果没记错的话,应该是从k8s的1.16版本后放弃了heapster。
Metrics server作为新的容器信息收集器,是从 api-server 中获取容器的 cpu、内存使用率这种监控指标,并把他们发送给存储后端,可以算作一个完整的监控系统。cAdvisor是专有的容器信息收集,是一个专有工具的地位,而kube-state-metrics是偏向于kubernetes集群内的资源对象,例如deployment,StateFulSet,daemonset等等资源,可以算作一个特定的数据源
三,cAdvisor的初步使用
kubelet是kubernetes集群中真正维护容器状态,负责主要的业务的一个关键组件。每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口,接收并执行 master 发来的指令,管理 Pod 及 Pod 中的容器。kubernetes的节点IP+10250端口就是kubelet的API。
几个重要的端口:
A:
10250(kubelet API):kubelet server 与 apiserver 通信的端口,定期请求 apiserver 获取自己所应当处理的任务,通过该端口可以访问获取 node 资源以及状态。kubectl查看pod的日志和cmd命令,都是通过kubelet端口10250访问。
10248端口是什么呢?是kubelet的健康检查端口,可以通过 kubelet 的启动参数 –healthz-port 和 –healthz-bind-address 来指定监听的地址和端口。
需要注意的是,Kubernetes 1.11+ 版本以后,kubelet 就移除了 10255 端口, metrics 接口又回到了 10250 端口中。
版本的kubernetes还有一个4194端口,此端口是cAdvisor的web管理界面的端口,可能是出于安全漏洞的考虑,后续版本移除了此端口,因此,此端口在我这个版本内并没有开启。
B:API的使用
既然都说了节点IP+10250是kubelet的API了,那么,我们肯定可以从这个API里获取到一些信息了,这些信息其实就是cAdvisor收集到的,如何使用这个API呢?这个API可是需要使用证书的https哦。因此,计划建立一个sa,通过sa的token来登陆这个API
1)利用ServiceAccount访问API
利用ServiceAccount访问API
找一个具有cluster-admin权限的ServiceAccount,其实每个集群内都很容易找到这样的sa,但为了说明问题还是新建一个任意的具有最高权限的sa吧,实际的生产中可不要这么搞哦。
新建一个sa:
kubectl create ns monitor-sa #创建一个monitor-sa的名称空间
kubectl create serviceaccount monitor -n monitor-sa #创建一个sa账号
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
查看secret:
[root@node3 ~]# k get secrets -n monitor-sa
NAME TYPE DATA AGE
default-token-fw7pq kubernetes.io/service-account-token 3 81s
monitor-token-tf48k kubernetes.io/service-account-token 3 81s
获取登录用的token:
[root@node3 ~]# k describe secrets -n monitor-sa monitor-token-tf48k 使用10250这个API:
将token保存到变量TOKEN里面,然后下面的API调试接口命令里面引用
[root@node3 ~]# TOKEN=“”
curl https://127.0.0.1:10250/metrics/cadvisor -k -H "Authorization: Bearer $TOKEN"
OK,输出茫茫多,稍微截一点吧,剩下的就不贴了,具体的含义后面在说吧:
[root@node3 ~]# curl https://127.0.0.1:10250/metrics/cadvisor -k -H "Authorization: Bearer $TOKEN" |less将上面的命令改造一下,使用kube-apiserver 的服务来访问kube-apiserver 的API接口:
curl https://10.96.0.1/api/v1/nodes/node3/proxy/metrics -k -H "Authorization: Bearer $TOKEN"
[root@node3 ~]# curl https://10.96.0.1/api/v1/nodes/node3/proxy/metrics -k -H "Authorization: Bearer $TOKEN" |lessOK,以上是通过一个具有admin权限的serviceAccount账户直接连接cadvisor和kube-apiserver的API动态获得节点的pod,endpoint等等资源的各个维度的数据。
现在需要将这些集成到Prometheus server里了。
Kubernetes监控体系总结_kube-state-metrics 代替了cadvisor吗-CSDN博客
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux/Windows/Mac 机器上。容器镜像正成为一个新的标准化软件交付方式。为了能够获取到 Docker 容器的运行状态,用户可以通过 Docker 的 stats 命令获取到当前主机上运行容器的统计信息,可以查看容器的 CPU 利用率、内存使用量、网络 IO 总量以及磁盘 IO 总量等信息。
显然如果我们想对监控数据做存储以及可视化的展示,那么 docker 的 stats 是不能满足的。
为了解决 docker stats 的问题(存储、展示),谷歌开源的 cadvisor 诞生了,cadvisor 不仅可以搜集一台机器上所有运行的容器信息,还提供基础查询界面和 http 接口,方便其他组件如 Prometheus 进行数据抓取,或者 cAdvisor + influxDB + grafana 搭配使用。cAdvisor 可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括 CPU 使用情况、内存使用情况、网络吞吐量及文件系统使用情况
监控原理
cAdvisor 使用 Go 语言开发,利用 Linux 的 cgroups 获取容器的资源使用信息,在 K8S 中集成在 Kubelet 里作为默认启动项,官方标配。
Docker 是基于 Namespace、Cgroups 和联合文件系统实现的
Cgroups 不仅可以用于容器资源的限制,还可以提供容器的资源使用率。不管用什么监控方案,底层数据都来源于 Cgroups
Cgroups 的工作目录 /sys/fs/cgroup 下包含了 Cgroups 的所有内容。Cgroups 包含了很多子系统,可以对 CPU,内存,PID,磁盘 IO 等资源进行限制和监控。
Heapster
Heapster 是容器集群监控和性能分析工具,天然的支持 Kubernetes 和 CoreOS。
Heapster 首先从 K8S Master 获取集群中所有 Node 的信息,然后通过这些 Node 上的 kubelet 获取有用数据,而 kubelet 本身的数据则是从 cAdvisor 得到。所有获取到的数据都被推到 Heapster 配置的后端存储中,并还支持数据的可视化。现在后端存储 + 可视化的方法,如 InfluxDB + grafana。
Heapster 可以收集 Node 节点上的 cAdvisor 数据,还可以按照 kubernetes 的资源类型来集合资源,比如 Pod、Namespace 域,可以分别获取它们的 CPU、内存、网络和磁盘的 metric。默认的 metric 数据聚合时间间隔是 1 分钟。
注意 :Kubernetes 1.11 不建议使用 Heapster,就 SIG Instrumentation 而言,这是为了转向新的 Kubernetes 监控模型的持续努力的一部分。仍使用 Heapster 进行自动扩展的集群应迁移到 metrics-server 和自定义指标 API。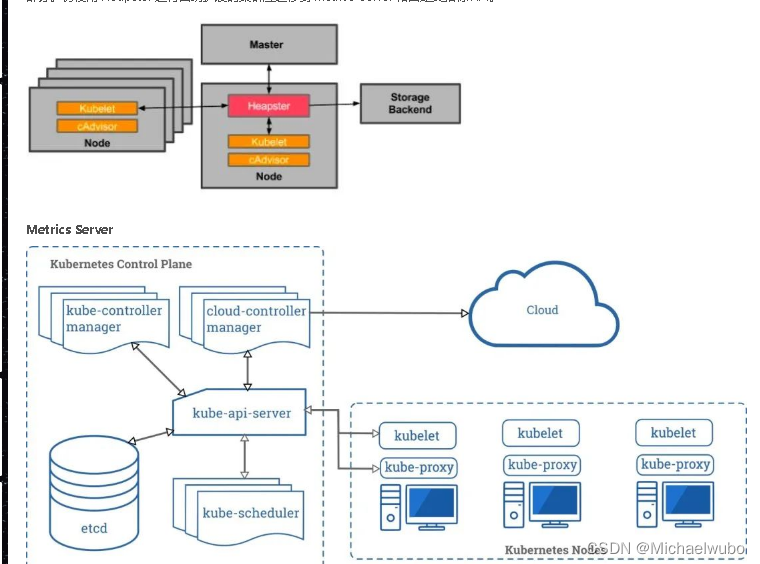
kubernetes 集群资源监控之前可以通过 heapster 来获取数据,在 1.11 开始开始逐渐废弃 heapster 了,采用 metrics-server 来代替,metrics-server 是集群的核心监控数据的聚合器,它从 kubelet 公开的 Summary API 中采集指标信息,metrics-server 是扩展的 APIServer,依赖于 kube-aggregator,因为我们需要在 APIServer 中开启相关参数。
Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
Aggregator
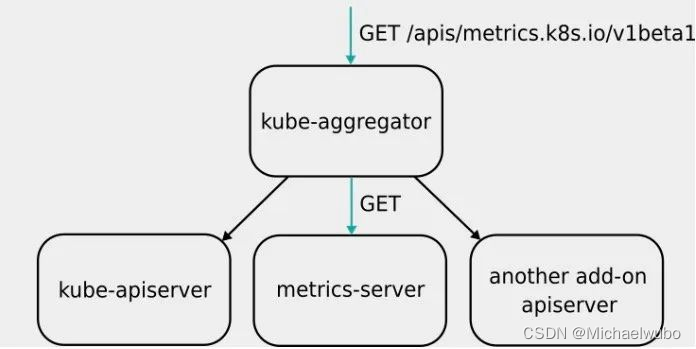
通过聚合层扩展 Kubernetes API使用聚合层(Aggregation Layer),用户可以通过额外的 API 扩展 Kubernetes, 而不局限于 Kubernetes 核心 API 提供的功能。这里的附加 API 可以是现成的解决方案比如 metrics server, 或者你自己开发的 API。聚合层不同于 定制资源(Custom Resources)。后者的目的是让 kube-apiserver 能够认识新的对象类别(Kind)。
聚合层聚合层在 kube-apiserver 进程内运行。在扩展资源注册之前,聚合层不做任何事情。要注册 API,用户必须添加一个 APIService 对象,用它来“申领” Kubernetes API 中的 URL 路径。自此以后,聚合层将会把发给该 API 路径的所有内容(例如 /apis/myextension.mycompany.io/v1/…) 转发到已注册的 APIService。
APIService 的最常见实现方式是在集群中某 Pod 内运行 扩展 API 服务器。如果你在使用扩展 API 服务器来管理集群中的资源,该扩展 API 服务器(也被写成“extension-apiserver”) 一般需要和一个或多个控制器一起使用。apiserver-builder 库同时提供构造扩展 API 服务器和控制器框架代码。
这里,Aggregator APIServer 的工作原理,可以用如下所示的一幅示意图来表示清楚 :
因为 k8s 的 api-server 将所有的数据持久化到了 etcd 中,显然 k8s 本身不能处理这种频率的采集,而且这种监控数据变化快且都是临时数据,因此需要有一个组件单独处理他们,于是 metric-server 的概念诞生了。
Metrics server 出现后,新的 Kubernetes 监控架构将变成下图的样子
- 核心流程(黑色部分):这是 Kubernetes 正常工作所需要的核心度量,从 Kubelet、cAdvisor 等获取度量数据,再由 metrics-server 提供给 Dashboard、HPA 控制器等使用。
- 监控流程(蓝色部分):基于核心度量构建的监控流程,比如 Prometheus 可以从 metrics-server 获取核心度量,从其他数据源(如 Node Exporter 等)获取非核心度量,再基于它们构建监控告警系统。
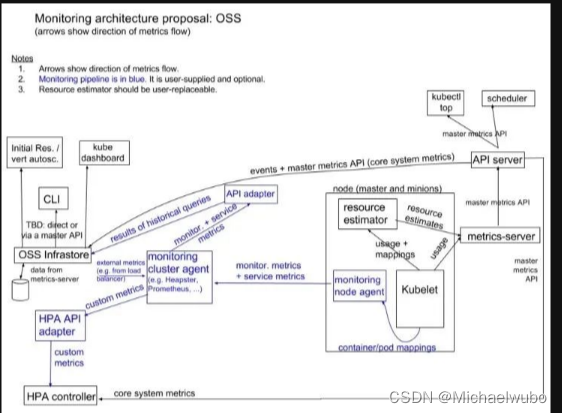
注意:
-
metrics-sevrer 的数据存在内存中。
-
metrics-server 主要针对 node、pod 等的 cpu、网络、内存等系统指标的监控
kube-state-metrics
已经有了 cadvisor、heapster、metric-server,几乎容器运行的所有指标都能拿到,但是下面这种情况却无能为力:
- 我调度了多少个 replicas?现在可用的有几个?
- 多少个 Pod 是 running/stopped/terminated 状态?
- Pod 重启了多少次?
- 我有多少 job 在运行中
而这些则是 kube-state-metrics 提供的内容,它基于 client-go 开发,轮询 Kubernetes API,并将 Kubernetes 的结构化信息转换为 metrics。
kube-state-metrics 与 metrics-server 对比
我们服务在运行过程中,我们想了解服务运行状态,pod 有没有重启,伸缩有没有成功,pod 的状态是怎么样的等,这时就需要 kube-state-metrics,它主要关注 deployment,、node 、 pod 等内部对象的状态。而 metrics-server 主要用于监测 node,pod 等的 CPU,内存,网络等系统指标。
- metric-server(或 heapster)是从 api-server 中获取 cpu、内存使用率这种监控指标,并把他们发送给存储后端,如 influxdb 或云厂商,他当前的核心作用是:为 HPA 等组件提供决策指标支持。
- kube-state-metrics 关注于获取 k8s 各种资源的最新状态,如 deployment 或者 daemonset,之所以没有把 kube-state-metrics 纳入到 metric-server 的能力中,是因为他们的关注点本质上是不一样的。metric-server 仅仅是获取、格式化现有数据,写入特定的存储,实质上是一个监控系统。而 kube-state-metrics 是将 k8s 的运行状况在内存中做了个快照,并且获取新的指标,但他没有能力导出这些指标
- 换个角度讲,kube-state-metrics 本身是 metric-server 的一种数据来源,虽然现在没有这么做。
- 另外,像 Prometheus 这种监控系统,并不会去用 metric-server 中的数据,他都是自己做指标收集、集成的(Prometheus 包含了 metric-server 的能力),但 Prometheus 可以监控 metric-server 本身组件的监控状态并适时报警,这里的监控就可以通过 kube-state-metrics 来实现,如 metric-serverpod 的运行状态。
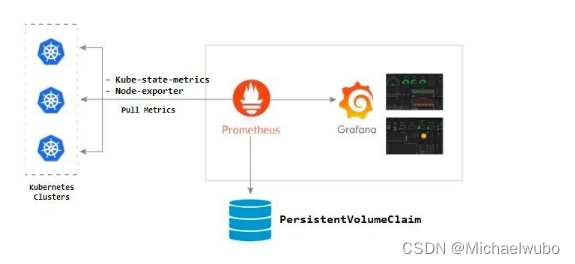
custom-metrics-apiserver
kubernetes 的监控指标分为两种
- Core metrics(核心指标):从 Kubelet、cAdvisor 等获取度量数据,再由 metrics-server 提供给 Dashboard、HPA 控制器等使用。
- Custom Metrics(自定义指标):由 Prometheus Adapter 提供 API custom.metrics.k8s.io,由此可支持任意 Prometheus 采集到的指标。
以下是官方 metrics 的项目介绍:
Resource Metrics API(核心 api)
-
Heapster
-
Metrics Server
Custom Metrics API:
-
Prometheus Adapter
-
Microsoft Azure Adapter
-
Google Stackdriver
-
Datadog Cluster Agent
核心指标只包含 node 和 pod 的 cpu、内存等,一般来说,核心指标作 HPA 已经足够,但如果想根据自定义指标:如请求 qps/5xx 错误数来实现 HPA,就需要使用自定义指标了,目前 Kubernetes 中自定义指标一般由 Prometheus 来提供,再利用 k8s-prometheus-adpater 聚合到 apiserver,实现和核心指标(metric-server) 同样的效果。
HPA 请求 metrics 时,kube-aggregator(apiservice 的 controller) 会将请求转发到 adapter,adapter 作为 kubernentes 集群的 pod,实现了 Kubernetes resource metrics API 和 custom metrics API,它会根据配置的 rules 从 Prometheus 抓取并处理 metrics,在处理(如重命名 metrics 等)完后将 metric 通过 custom metrics API 返回给 HPA。最后 HPA 通过获取的 metrics 的 value 对 Deployment/ReplicaSet 进行扩缩容。
adapter 作为 extension-apiserver(即自己实现的 pod),充当了代理 kube-apiserver 请求 Prometheus 的功能。
adapter 作为 extension-apiserver(即自己实现的 pod),充当了代理 kube-apiserver 请求 Prometheus 的功能

其实 k8s-prometheus-adapter 既包含自定义指标,又包含核心指标,即如果安装了 prometheus,且指标都采集完整,k8s-prometheus-adapter 可以替代 metrics server。
Prometheus 部署方案
prometheus operator
- https://github.com/prometheus-operator/prometheus-operator
kube-prometheus
- https://github.com/prometheus-operator/kube-prometheus
在集群外部署
- https://www.qikqiak.com/post/monitor-external-k8s-on-prometheus/
kube-prometheus 既包含了 Operator,又包含了 Prometheus 相关组件的部署及常用的 Prometheus 自定义监控,具体包含下面的组件
- The Prometheus Operator:创建 CRD 自定义的资源对象
- Highly available Prometheus:创建高可用的 Prometheus
- Highly available Alertmanager:创建高可用的告警组件
- Prometheus node-exporter:创建主机的监控组件
- Prometheus Adapter for Kubernetes Metrics APIs:创建自定义监控的指标工具(例如可以通过 nginx 的 request 来进行应用的自动伸缩)
- kube-state-metrics:监控 k8s 相关资源对象的状态指标
- Grafana:进行图像展示
我们的做法
我们的做法,其实跟 kube-prometheus 的思路差不多,只不过我们没有用 Operator ,是自己将以下这些组件的 yaml 文件用 helm 组织了起来而已:
- kube-state-metrics
- prometheus
- alertmanager
- grafana
- k8s-prometheus-adapter
- node-exporter
当然 kube-prometheus 也有 helm charts 由 prometheus 社区提供:https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
这么干的原因是:这样的灵活度是最高的,虽然在第一次初始化创建这些脚本的时候麻烦了些。不过还有一个原因是我们当时部署整个基于 prometheus 的监控体系时,kube-prometheus 这个项目还在早期,没有引起我们的关注。如果在 2021 年年初或 2020 年年底的时候创建的话,可能就会直接上了。
参考
- https://blog.opskumu.com/cadvisor.html
- https://prometheus.io/
- https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale/
- https://www.cnblogs.com/chenqionghe/p/10494868.html
- https://www.qikqiak.com/post/k8s-operator-101/
- https://kubernetes.io/zh/docs/concepts/extend-kubernetes/api-extension/apiserver-aggregation/
- https://segmentfault.com/a/1190000017875641
- https://segmentfault.com/a/1190000038888544
- https://yasongxu.gitbook.io/
- https://mp.weixin.qq.com/s/p4FAFKHi8we4mrD7OIk7IQ
- https://kubernetes.feisky.xyz/apps/index/operator
- https://yunlzheng.gitbook.io/prometheus-book/part-iii-prometheus-shi-zhan/operator/what-is-prometheus-operator
1.k8s原生api地址
k8s的REST API:
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes/<node-name>
http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespace/<namespace-name>/pods/<pod-name>
2.rancher看k8s接口地址
2.1)看集群的api
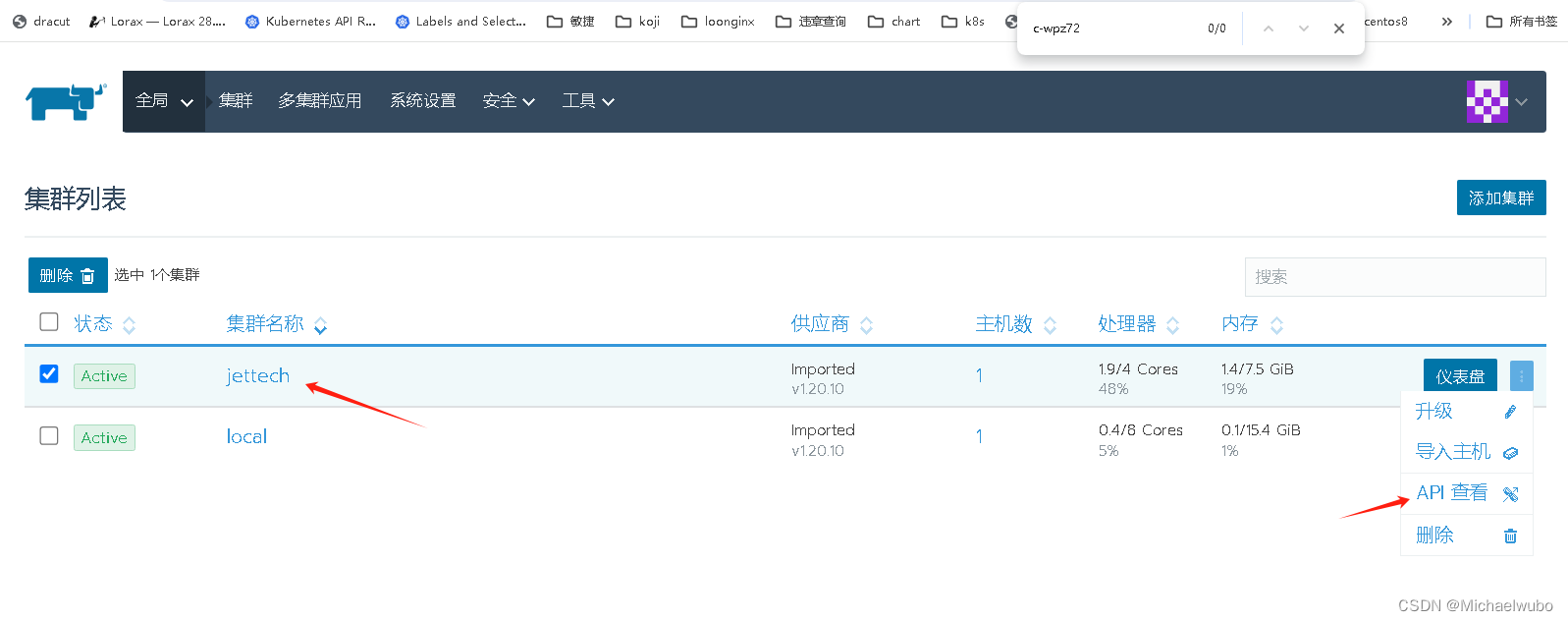
2.2)通过集群api查看id

2.3)通过rancher看k8s的api地址
rancher的REST API:
总接口:https://rancher.jettech.cn/k8s/clusters/c-wpz72/
node:https://rancher.jettech.cn/k8s/clusters/c-wpz72/apis/metrics.k8s.io/v1beta1/nodes
pod:https://rancher.jettech.cn/k8s/clusters/c-wpz72/apis/metrics.k8s.io/v1beta1/pods
细说k8s监控架构 - 知乎









![[计算机提升] 切换(域)用户](https://img-blog.csdnimg.cn/direct/ea19c2550fc846a0b58d62a8dea898ac.png)