大家好,我是小米,一个热爱技术分享的小伙伴。今天我们来聊一聊 Java 中的 Stream,以及如何通过 Stream 来提高遍历集合的效率。
什么是Stream?
在开始深入讨论之前,我们先来了解一下什么是 Stream。
Stream 是 Java 8 中引入的一种新的抽象概念,用于处理数据序列。它为我们提供了一种更加便捷、高效的方式来操作集合数据,实现了函数式编程的特性。在之前的 Java 版本中,我们通常使用迭代器或者循环来处理集合,代码显得冗长且难以阅读。而引入 Stream 后,我们可以采用声明式的方式描述数据的处理流程,使代码更加简洁、清晰。
Stream 的本质是一种数据流,它不是一种数据结构,因此不会改变原有的数据集合。相反,它提供了一系列的中间操作和终端操作,这些操作可以被串联起来形成一条处理流水线。中间操作用于对数据进行转换和处理,而终端操作则触发整个处理流程的执行,产生最终的结果。
使用 Stream,我们可以轻松进行各种操作,如筛选、映射、过滤、排序等,而无需手动编写繁琐的迭代代码。这种声明式的编程风格不仅提高了代码的可读性,还有助于并行处理,充分发挥多核 CPU 的性能优势。
以下是一个简单的代码示例,演示了使用Stream对集合进行过滤、映射和打印操作的好处:
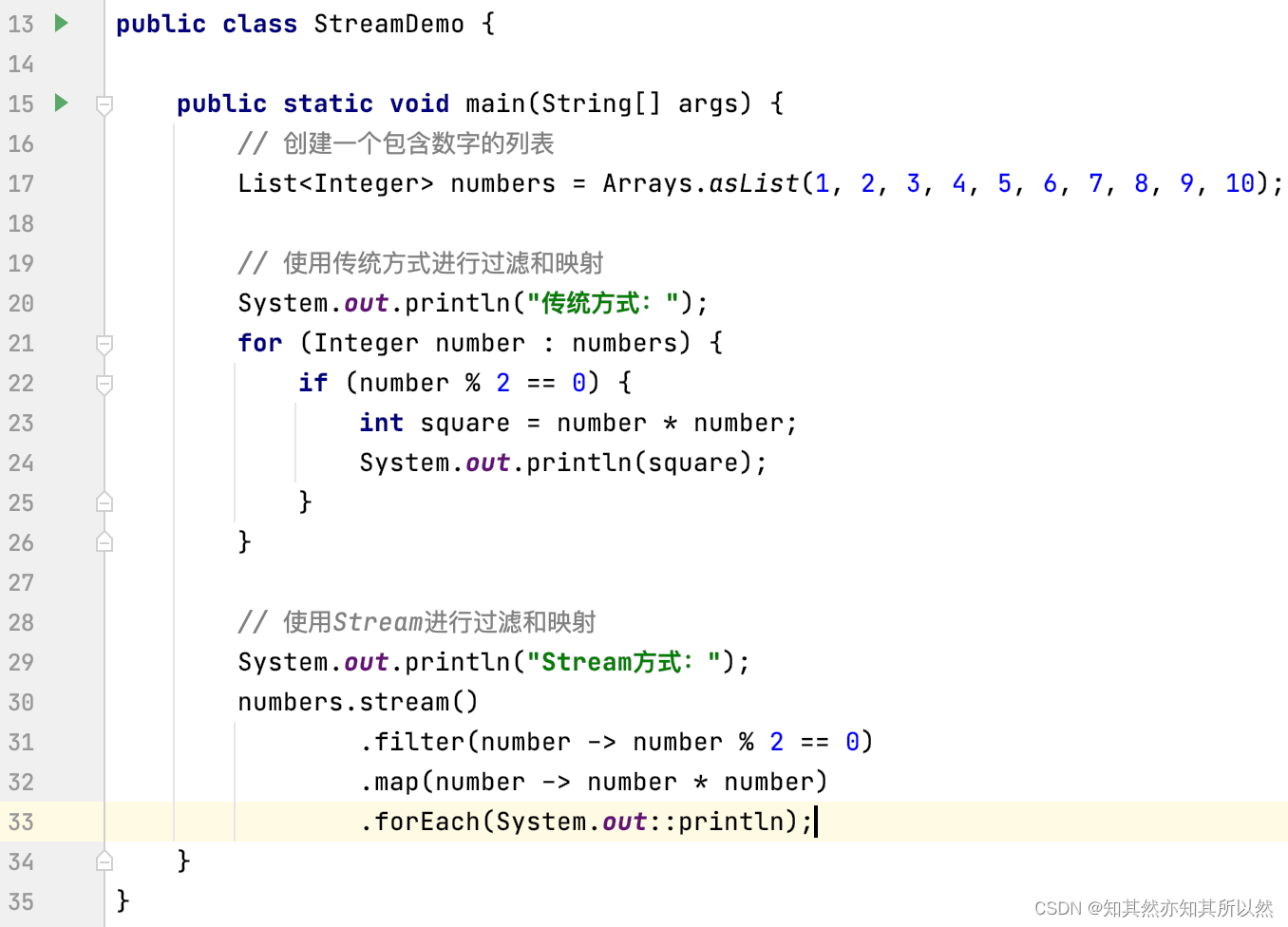
这个简单的示例展示了Stream的优势,实际应用中,Stream还可以进行更复杂的操作,如分组、排序等,为集合处理提供了更多灵活性。
Stream操作分类
在使用 Stream 进行集合操作时,我们通常将其分为两种操作:中间操作和终端操作。
中间操作是在数据源上进行的转换和处理,但并不立即触发流的遍历。这些操作包括 filter、map、distinct 等。通过 filter 我们可以轻松筛选出符合条件的元素,而 map 则用于转换元素,使得处理过程更为灵活。

在上述示例中,filter 用于选择偶数,map 则将这些偶数平方,形成了中间操作的链式调用。
终端操作是触发流的遍历并产生最终结果的操作,结束流的处理。这些操作包括 forEach、collect、reduce 等。通过 collect 我们可以将流中的元素收集到一个新的集合中。

在这个示例中,collect 将处理后的结果收集到一个新的列表中,结束了整个流的处理过程。
Stream源码实现
Stream 的源码实现是 Java 8 中引入的一项复杂而精妙的特性,它为处理集合数据提供了一种全新的方式。在深入探讨 Stream 的源码实现之前,我们首先需要了解几个关键的类和接口,它们构成了 Stream 操作的基础结构。
首先,BaseStream 接口是 Stream API 中的基础,它定义了一些基本的操作,例如串行执行和并行执行。这个接口为不同类型的 Stream,如 Stream、IntStream、DoubleStream 等提供了一致的接口定义,使得操作在不同类型的流之间能够得到复用。
接着,AbstractPipeline 类是 Stream 的核心类之一,它封装了操作的基本逻辑,包括遍历、过滤等。这个类为具体的操作提供了抽象基类,简化了新操作的添加。它还定义了流水线的基本结构,使得我们能够串联多个操作形成一个完整的处理流程。
在针对对象引用流的处理中,ReferencePipeline 继承自 AbstractPipeline,通过一系列方法(如 filter、map 等)生成不同类型的中间操作,形成操作链。而 Sink 类则负责接收元素并进行实际的处理。这种流水线的设计充分体现了函数式编程的思想,每个操作都是不可变的,而且在进行终端操作前,中间操作只是构建了一个操作链而并未实际执行。
在具体的操作实现中,以 filter 为例,通过 ReferencePipeline 类的 filter 方法生成一个新的流水线,其中定义了过滤的逻辑,形成了一个中间操作。这个设计使得我们能够以链式的方式组织多个操作,从而更加灵活地构建数据处理流程。
Stream操作叠加源码解析
在实际应用中,我们常常需要对集合进行多个操作,这时候就涉及到 Stream 操作的叠加。通过源码解析,我们可以深入了解这一过程的执行。
首先,让我们看一下一个简单的例子:

这个例子中,我们对数字集合进行了筛选(filter)和映射(mapToInt)的两个操作,然后求和。让我们逐步分析这个过程。
filter操作
首先,filter 操作创建了一个新的 Stream,其中包含了符合条件的元素。这是通过 ReferencePipeline 类的 filter 方法实现的,具体代码如下:

这段代码展示了如何创建一个新的 Stream,其中的 Sink 对象通过 predicate.test(u) 来判断是否满足条件,然后将符合条件的元素传递给下游。
mapToInt操作
接着,mapToInt 操作对上一个操作的结果进行了映射,将元素乘以2。这是通过 ReferencePipeline 类的 mapToInt 方法实现的,具体代码如下:

这段代码展示了如何创建一个新的 IntStream,其中的 Sink 对象通过 mapper.applyAsInt(u) 来进行映射操作,将元素乘以2后传递给下游。
sum操作
最后,sum 操作对上一个操作的结果进行了求和。这是通过 SummingInt 类的 evaluate 方法实现的,具体代码如下:

这段代码展示了如何对映射后的元素进行求和操作,最终得到结果。
通过这个简单的例子,我们可以看到 Stream 操作的叠加是通过创建新的 Stream,并在每个操作的 Sink 中对元素进行处理和传递的。这种链式调用的方式使得我们可以灵活组合多个操作,构建出复杂的数据处理流程。
Stream并行处理源码解析
Stream 的一个显著特点是能够支持并行处理。在多核 CPU 的环境下,Stream 的并行迭代方式可以显著提高性能。通过分析源码,我们可以了解并行处理是如何实现的,以及在何种场景下使用更为合适。
首先,让我们看一个简单的例子:

在这个例子中,我们使用了 parallelStream() 方法将 Stream 转换为并行流,然后进行映射和求和操作。接下来,我们将逐步分析这个过程。
parallelStream操作
首先,parallelStream() 方法是通过 BaseStream 接口的 parallel() 方法实现的,具体代码如下:

这段代码通过 StreamSupport.stream(spliterator(), true) 来创建一个支持并行的 Stream。
并行处理的实现
在并行处理过程中,Stream 会被分割成多个子任务,每个子任务在一个独立的线程中执行。这是通过 ForkJoinTask 框架实现的,具体代码如下:

invoke() 方法用于执行任务,每个子任务都是一个 ForkJoinTask,它们会在多个线程中同时执行,最后将结果合并起来。
并行处理的Sink
在并行处理中,每个子任务都有自己的 Sink 对象,用于处理元素。这是通过 ForkingSink 类实现的,具体代码如下:

ForkingSink 中的 accept() 方法用于接收元素,然后通过 split() 方法将任务进行分割。
通过这个简单的例子,我们可以看到 Stream 的并行处理是通过 ForkJoin 框架实现的,每个子任务都在独立的线程中执行,最后将结果合并。这种方式能够更好地利用多核 CPU 的性能,提高处理速度。
性能测试
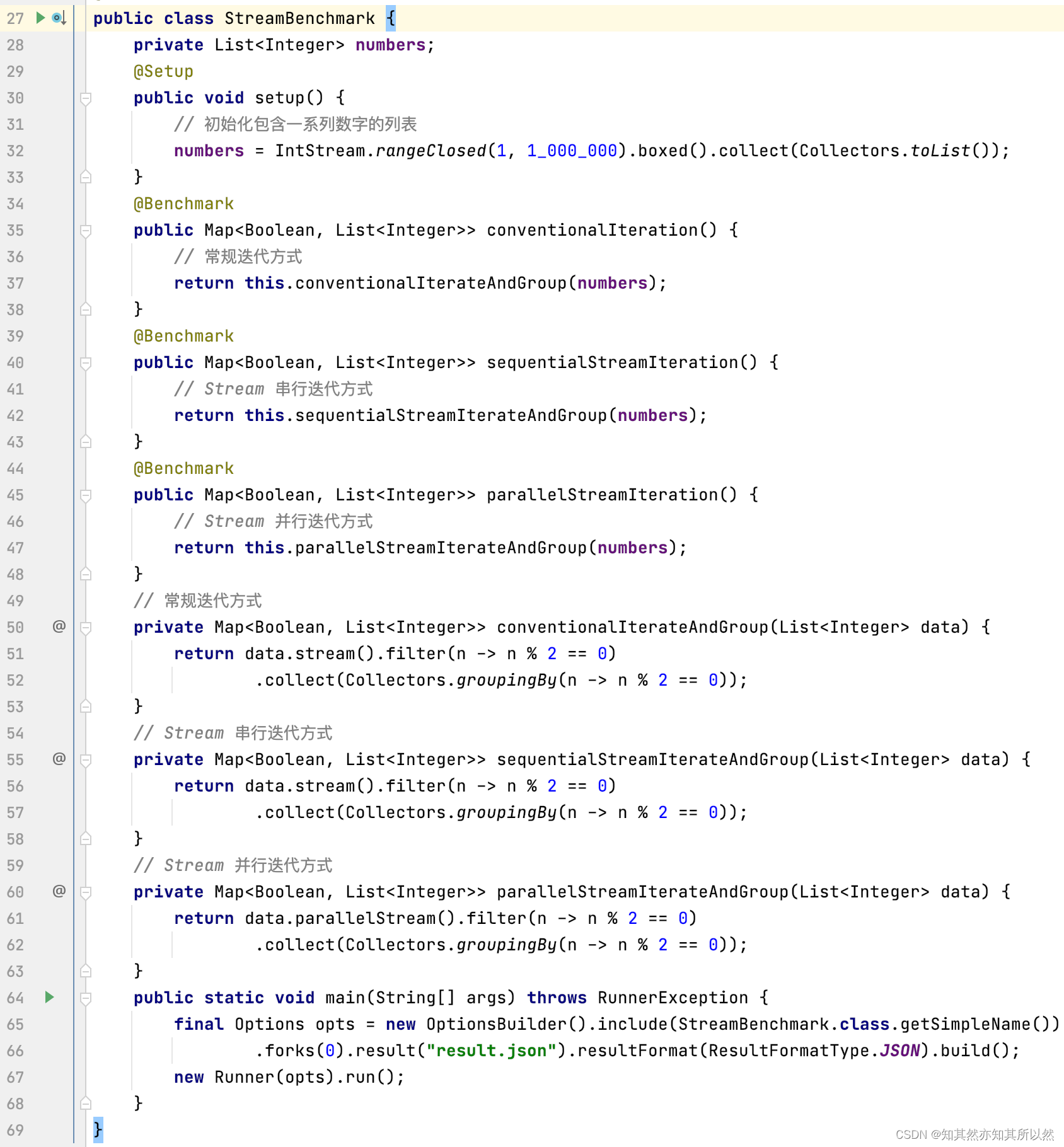
为了更直观地比较两者的性能,我们使用JMH(Java Microbenchmarking Harness)进行测试。
以下是一个简单的示例代码,假设我们有一个包含一系列数字的列表,我们将对这些数字进行过滤,然后按照奇偶性进行分组:
测试结论:
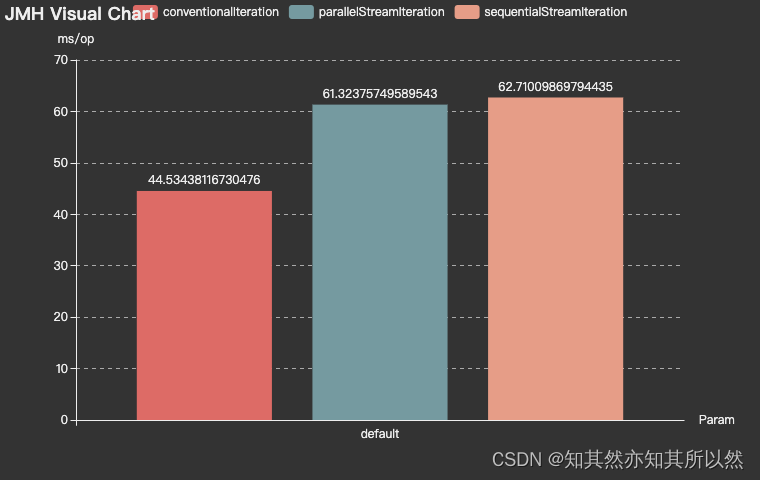
通过以上测试结果,我们可以看到:
- 在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;
- 在单核 CPU 服务器配置环境中,也是常规迭代方式更有优势;
- 而在大数据循环迭代中,如果服务器是多核 CPU 的情况下,Stream 的并行迭代优势明显。
所以我们在平时处理大数据的集合时,应该尽量考虑将应用部署在多核 CPU 环境下,并且使用 Stream 的并行迭代方式进行处理。
总结
用事实说话,我们看到其实使用 Stream 未必可以使系统性能更佳,还是要结合应用场景进行选择,也就是合理地使用 Stream。
总的来说,Stream 是一个强大而灵活的工具,但并不是适用于所有场景。在选择使用 Stream 时,我们需要根据实际情况进行权衡和取舍。
通过深入了解 Stream 的底层实现,我们可以更好地运用这一特性,提高代码的可读性和性能。
END
希望本篇文章能够帮助大家更好地理解和使用 Stream,欢迎大家在评论区分享自己的见解和经验。如果有其他技术话题感兴趣,也欢迎留言提出,我们一起探讨学习!感谢大家的阅读!
如有疑问或者更多的技术分享,欢迎关注我的微信公众号“知其然亦知其所以然”!













![[前 10 名] 最佳 Android 数据恢复软件免费下载](https://img-blog.csdnimg.cn/img_convert/7c62d4914ef8a266a01275c829b4e36d.jpeg)