1. RNN循环神经网络
1.1 结构
循环神经网络(recurrent neural network,RNN)源自于1982年由Saratha Sathasivam 提出的霍普菲尔德网络。RNN的主要用途是处理和预测序列数据。全连接的前馈神经网络和卷积神经网络模型中,网络结构都是从输入层到隐藏层再到输出层,层与层之间是全连接或部分连接的,但每层之间的节点是无连接的。
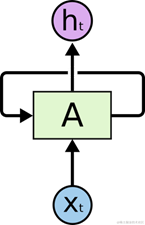
图 11 RNN-rolled
如图 11所示是一个典型的循环神经网络。对于循环神经网络,一个非常重要的概念就是时刻。循环神经网络会对于每一个时刻的输入结合当前模型的状态给出一个输出。从图 11中可以看到,循环神经网络的主体结构A的输入除了来自输入层Xt,还有一个循环的边来提供当前时刻的状态。在每一个时刻,循环神经网络的模块A会读取t时刻的输入Xt,并输出一个值Ht。同时A的状态会从当前步传递到下一步。因此,循环神经网络理论上可以被看作是同一神经网络结构被无限复制的结果。但出于优化的考虑,目前循环神经网络无法做到真正的无限循环,所以,现实中一般会将循环体展开,于是可以得到图 12所示的展示结构。
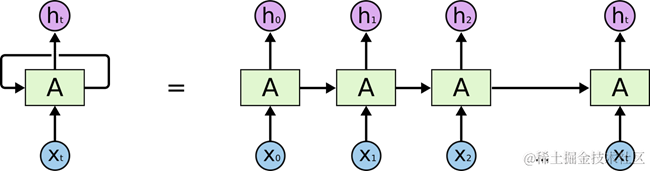
图 12 RNN-unrolled
在图 12中可以更加清楚的看到循环神经网络在每一个时刻会有一个输入Xt,然后根据循环神经网络当前的状态At,提供一个输出ht。而循环神经网络的结构特征可以很容易得出它最擅长解决的问题是与世界序列相关的。循环神经网络也是处理这类问题时最自然的神经网络结构。对于一个序列数据,可以将这个序列上不同时刻的数据依次传入循环神经网络的输入层,而输出可以是对序列中下一个时刻的预测,也可以是对当前时刻信息的处理结果(比如语音识别结果)。循环神经网络要求每一个时刻都有一个输入,但是不一定每一个时刻都需要有输出。
1.2 网络
如之前所介绍,循环神经网络可以被看作是同一神经网络结构在时间序列上被复制多次的结果,这个复制多次的结构被称为循环体。如何设计循环体的网络结构是循环神经网络解决实际问题的关键。和卷积神经网络每层神经元中参数是共享的类似,在循环神经网络中,循环体网络结构中的参数(权值和偏置)在不同时刻也是共享的。
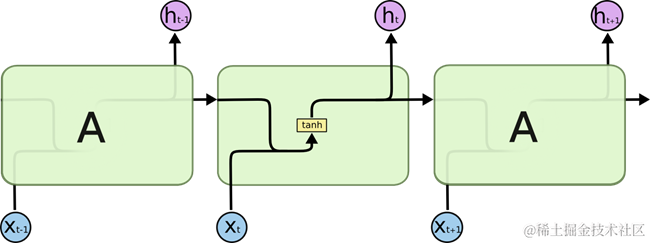
图 13 SimpleRNN
图 13展示了一个使用最简单的循环体结构的循环神经网络,在这个循环体中只使用了一个类似全连接层的神经网络结构。下面将通过图 13中所展示的神经网络来介绍循环神经网络前向传播的完整流程。循环神经网络中的状态是通过一个向量来表示的,这个向量的维度也称为神经网络隐藏层的大小,假设其为h。从图 13种可以看出,循环体中的神经网络的输入有两部分,一部分为上一时刻的状态,另一部分为当前时刻的输入样本。对于时间序列数据来说,每一时刻的输入样例可以是当前时刻的数据;对于语言模型来说,输入样例可以是当前单词对应的单词向量。
假设输入向量的维度为x,那么图 13中循环体的全连接层神经网络的输入大小为h+x。也就是将上一时刻的状态与当前时刻的输入拼接成一个大的向量作为循环体中神经网络的输入。因为该神经网络的输出为当前时刻的状态,于是输出层的节点个数也为h,循环体中的参数个数为(h+x)*h+h个(因为有h个元素的输入向量和x个元素的输入向量,及h个元素的输出向量;可用简单理解为输入层有h+x个神经元,输出层有h个神经元,从而形成一个全连接的前馈神经网络,有(h+x)*h个权值,有h个偏置)。
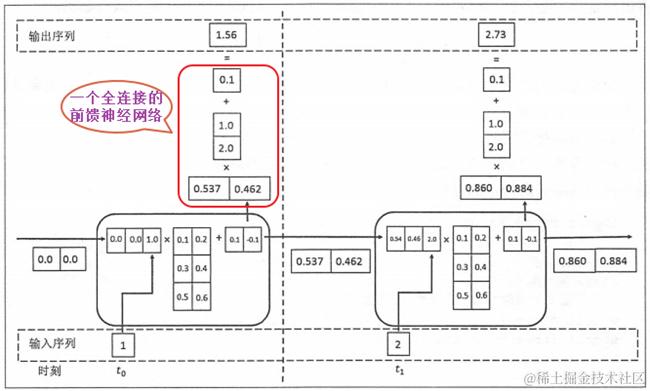
图 14 example RNN
如图 14所示具有两个时刻的RNN网络,其中t0和t1的权值和偏置是相同的,只是不同的输入而已;同时由于输入向量是1维的,而输入状态为2维的,合并起来的向量是3维的;其中在每个循环体的状态输出是2维的,然后经过一个全连接的神经网络计算后,最终输出是1维向量结构。
1.3 问题
循环神经网络工作的关键点就是使用历史的信息来帮助当前的决策。例如使用之前出现的单词来加强对当前文字的理解。循环神经网络可以更好地利用传统神经网络结构所不能建模的信息,但同时,这也带来了更大的技术挑战——长期依赖(long-term dependencies)问题。
在有些问题中,模型仅仅需要短期内的信息来执行当前的任务。比如预测短语"大海的颜色是蓝色"中最后一个单词"蓝色"时,模型并不需要记忆这个短语之前更长的上下文信息——因为这一句话已经包含了足够信息来预测最后一个词。在这样的场景中,相关的信息和待预测词的位置之间的间隔很小,循环神经网络可以比较容易地利用先前信息。
但同样也会有一些上下文场景比较复杂的情况。比如当模型试着去预测段落"某地开设了大量工厂,空气污染十分严重……这里的天空都是灰色的"的最后一个单词时,仅仅根据短期依赖就无法很好的解决这种问题。因为只根据最后一小段,最后一个词可以是"蓝色的"或者"灰色的"。但如果模型需要预测清楚具体是什么颜色,就需要考虑先前提到但离当前位置较远的上下文信息。因此,当前预测位置和相关信息之间的文本间隔就有可能变得很大。当这个间隔不断增大时,类似图 13中给出的简单循环神经网络有可能丧失学习到距离如此远的信息的能力。或者在复杂语言场景中,有用信息的间隔有大有小、长短不一,循环神经网络的性能也会受到限制。
2. LSTM长短记忆网络
2.1 概述
长短记忆网络(long short term memory, LSTM)的设计正是为了解决上述RNN的依赖问题,即为了解决RNN有时依赖的间隔短,有时依赖的间隔长的问题。其中循环神经网络被成功应用的关键就是LSTM。在很多的任务上,采用LSTM结构的循环神经网络比标准的循环神经网络的表现更好。LSTM结构是由Sepp hochreiter和Jurgen Schemidhuber于1997年提出的,它是一种特殊的循环神经网络结构。
2.2 结构
LSTM的设计就是为了精确解决RNN的长短记忆问题,其中默认情况下LSTM是记住长时间依赖的信息,而不是让LSTM努力去学习记住长时间的依赖。
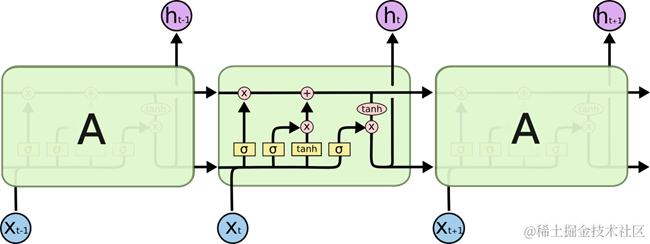
图 21 LSTM
所有循环神经网络都有一个重复结构的模型形式,在标准的RNN中,重复的结构是一个简单的循环体,如图 13 所示的A循环体。然而LSTM的循环体是一个拥有四个相互关联的全连接前馈神经网络的复制结构,如图 21所示。
目前可以先不必了解LSTM细节,只需先明白图 22所示的符号语义:

图 22 notation
- Neural NetWork Layer:该图表示一个神经网络层;
- Pointwise Operation:该图表示一种操作,如加号表示矩阵或向量的求和、乘号表示向量的乘法操作;
- Vector Tansfer:每一条线表示一个向量,从一个节点输出到另一个节点;
- Concatenate:该图表示两个向量的合并,即由两个向量合并为一个向量,如有X1和X2两向量合并后为[X1,X2]向量;
- Copy:该图表示一个向量复制了两个向量,其中两个向量值相同。
2.3 分析
2.3.1 核心设计
LSTM设计的关键是神经元的状态,如图 23所示顶部的水平线。神经元的状态类似传送带一样,按照传送方向从左端被传送到右端,在传送过程中基本不会改变,只是进行一些简单的线性运算:加或减操作。神经元的通过线性操作能够小心地管理神经元的状态信息,将这种管理方式称为门操作(gate)。
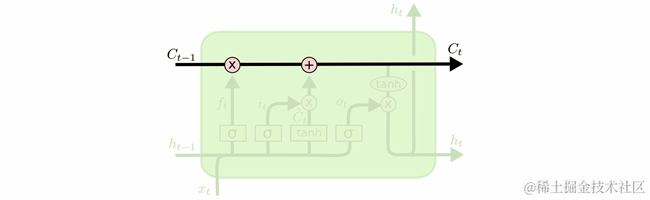
图 23 C-line
门操作能够随意的控制神经元状态信息的流动,如图 24所示,它由一个sigmoid激活函数的神经网络层和一个点乘运算组成。Sigmoid层输出要么是1要么是0,若是0则不能让任何数据通过;若是1则意味着任何数据都能通过。
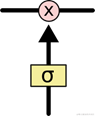
图 24 gate
LSTM有三个门来管理和控制神经元的状态信息。
2.3.2 遗忘门
LSTM的第一步是决定要从上一个时刻的状态中丢弃什么信息,其是由一个sigmoid全连接的前馈神经网络的输出阿里管理,将这种操作称为遗忘门(forget get layer)。如图 25所示。这个全连接的前馈神经网络的输入是ht-1和Xt组成的向量,输出是ft向量。ft向量是由1和0组成,1表示能够通过,0表示不能通过。
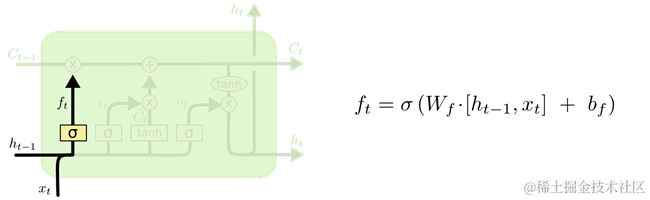
图 25 focus-f
2.3.3 输入门
第二步决定哪些输入信息要保存到神经元的状态中。这又两队前馈神经网络,如图 26所示。首先是一个sigmoid层的全连接前馈神经网络,称为输入门(input gate layer),其决定了哪些值将被更新;然后是一个tanh层的全连接前馈神经网络,其输出是一个向量Ct,Ct向量可以被添加到当前时刻的神经元状态中;最后根据两个神经网络的结果创建一个新的神经元状态。
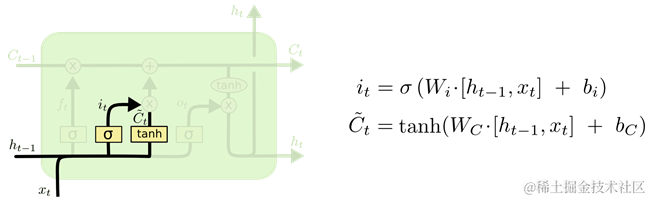
图 26 focus-i
2.3.4 状态控制
第三步就可以更新上一时刻的状态Ct-1为当前时刻的状态Ct了。上述的第一步的遗忘门计算了一个控制向量,此时可通过这个向量过滤了一部分Ct-1状态,如图 27所示的乘法操作;上述第二步的输入门根据输入向量计算了新状态,此时可以通过这个新状态和Ct-1状态根据一个新的状态Ct,如图 27所示的加法操作。
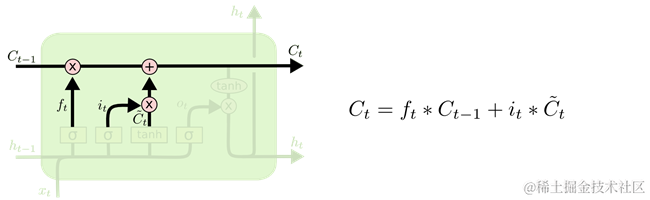
图 27 focus-C
2.3.5 输出门
最后一步就是决定神经元的输出向量ht是什么,此时的输出是根据上述第三步的Ct状态进行计算的,即根据一个sigmoid层的全连接前馈神经网络过滤到一部分Ct状态作为当前时刻神经元的输出,入土2-8所示。这个计算过程是:首先通过sigmoid层生成一个过滤向量;然后通过一个tanh函数计算当前时刻的Ct状态向量(即将向量每个值的范围变换到[-1,1]之间);接着通过sigmoid层的输出向量过滤tanh函数结果,即为当前时刻神经元的输出。
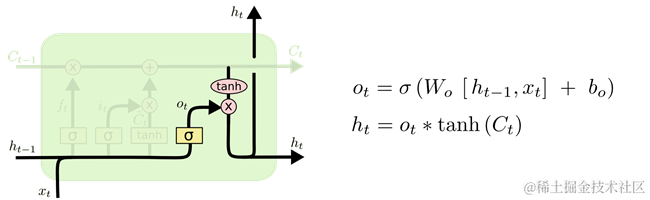
图 28 focus-o
2.4 LSTM 延伸网络
上述介绍的LSTM结构是一个正常的网络结构,然而并不是所有的LSTM网络都是这种结构,实际上,LSTM有很多种变体,即为很多种变化形态。如下介绍几种常用形态结构:
2.4.1 Peephole connections
一种流行的LSTM变体是由Gers&Schmidhuber(2000)提出的网络结构,如图 29所示。通过将上一时刻的状态Ct-1合并到各个门上,从而更详细控制各个门的管理。
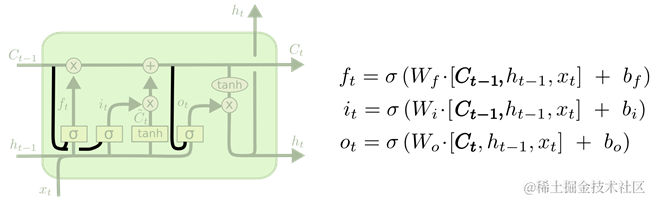
图 29 var-peepholes
2.4.2 Coupled forget and input gates
另一种变体是使用耦合的遗忘门和输入门,如图 210所示。
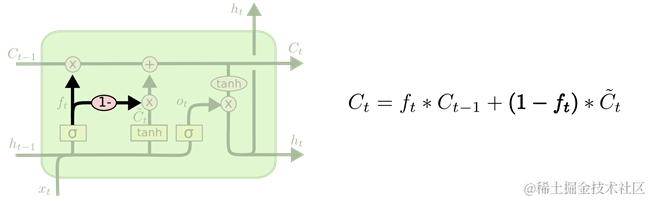
图 210 var-tired
2.4.3 Gated Recurrent Unit
另一种变体是Gated Recurrrent Unit,如图 211所示。
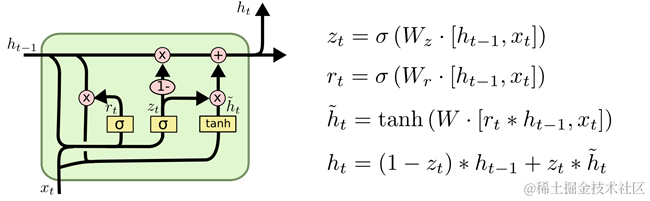
图 211 var-GRU
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习

人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。









![[前 10 名] 最佳 Android 数据恢复软件免费下载](https://img-blog.csdnimg.cn/img_convert/7c62d4914ef8a266a01275c829b4e36d.jpeg)