背景
Spark 3.5
最近在看Spark UI 上的一些指标看到一个很有意思的东西, 相邻的Shuffle Exechange 和 BroadcastExechange 中的 datasize 居然不一样,
前者为 765KB, 后者为 64.5MB。差别还不少,中间就增加了一个 AQEShuffleRead 计划
结论
Shuffle Exechange 中的是真实 UnsafeRow的大小
BroadcastExechange 中的是 MemoryBlock 类型数据结构所占的大小 ,而不是UnsafeRow的大小。
且BroadcastExechange中的datasize大小 和 2的整数倍接近。
现象以及分析
上图:
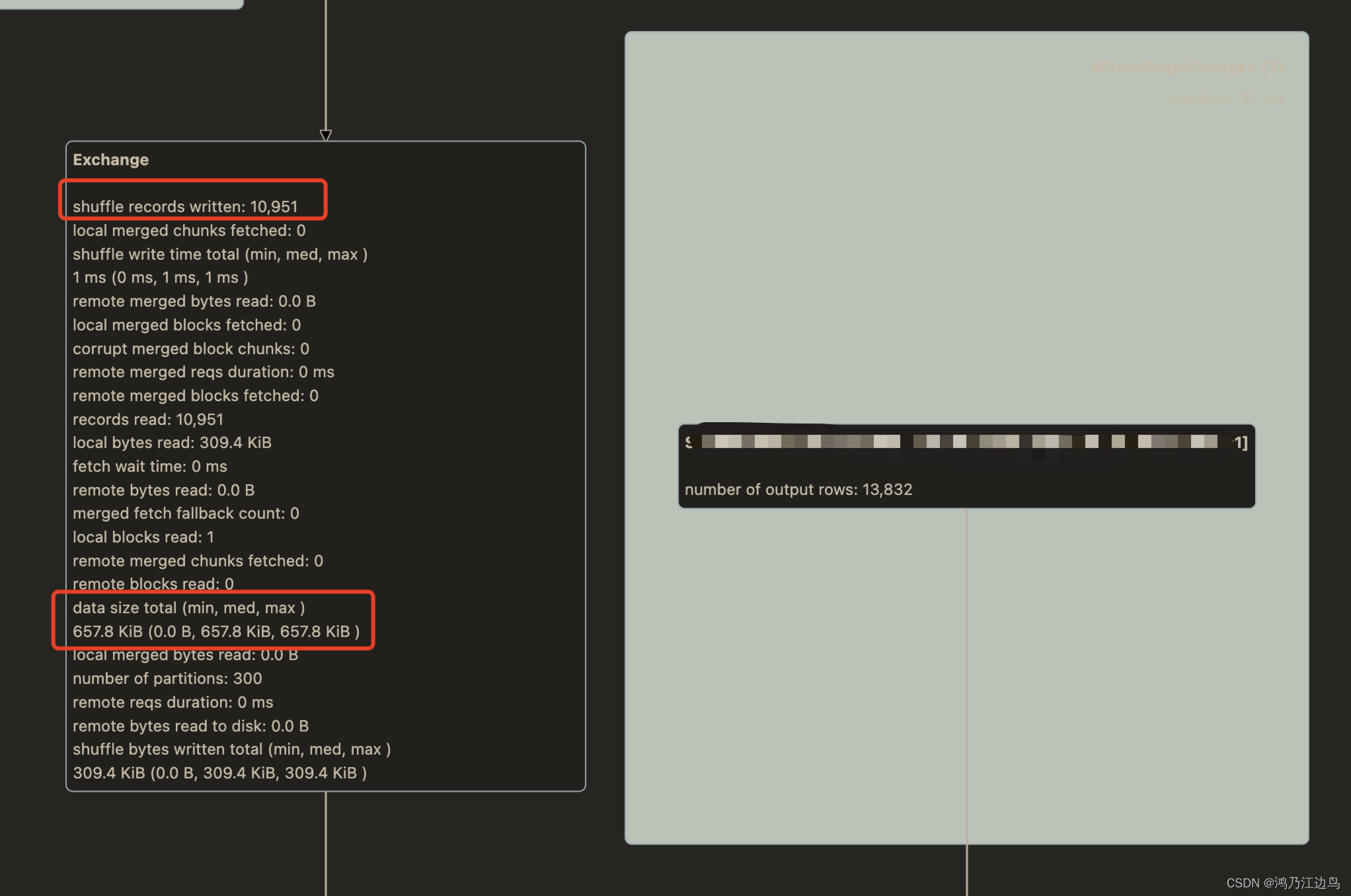
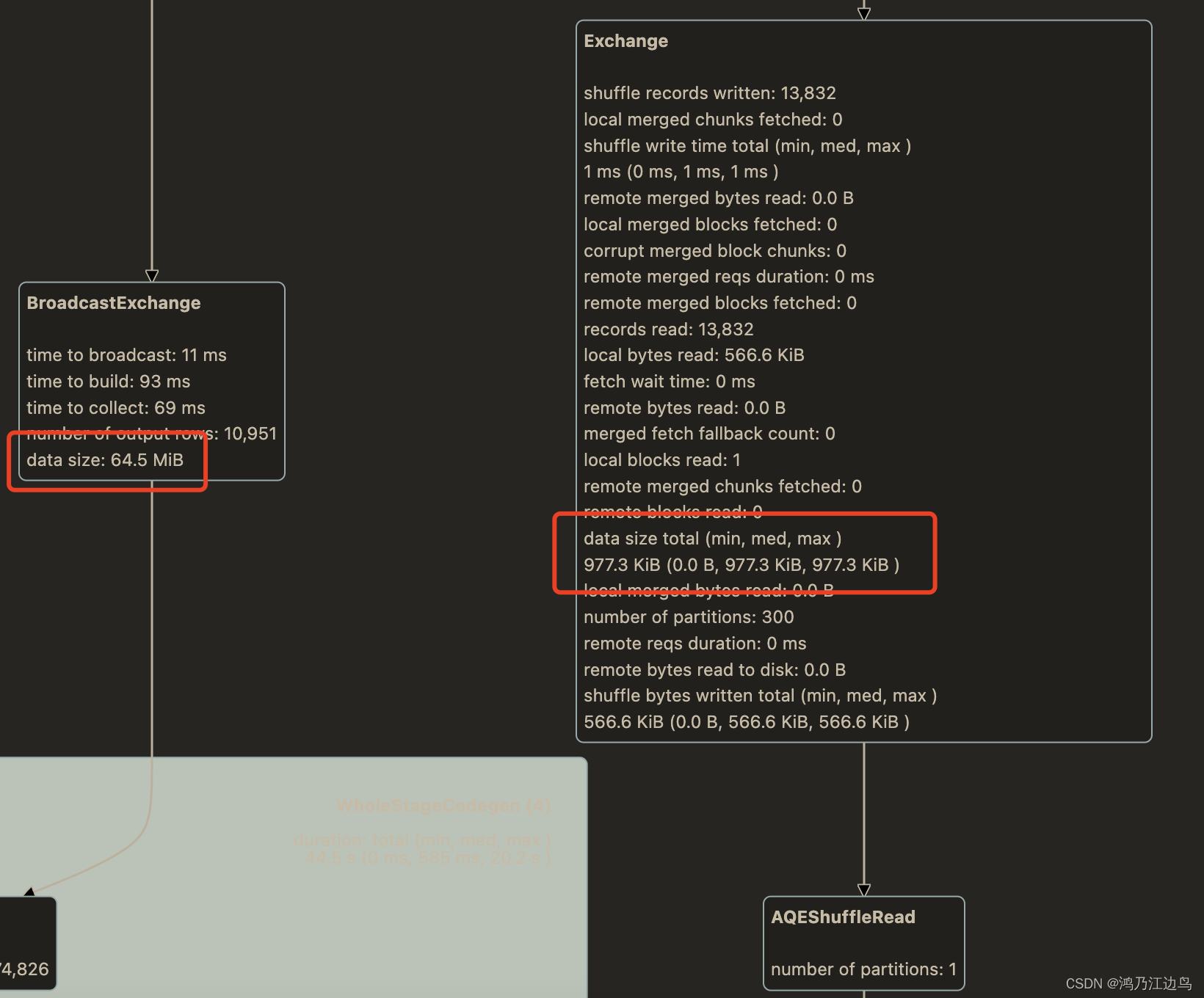

两个同样的 ShuffleExechange 记录条数和 ShuffleExechange 中 datasize 大小不一样,而在BroadcastExechange 中 dataSize 大小却是一样的(都是64.5MB)
关于 ShuffleExchange中的 dataSize的计算可以参考:Spark UI中Shuffle dataSize 和shuffle bytes written 指标区别,这里重点分析一下后者.
直接看BroadcastExechange代码:
override lazy val relationFuture: Future[broadcast.Broadcast[Any]] = {
SQLExecution.withThreadLocalCaptured[broadcast.Broadcast[Any]](
session, BroadcastExchangeExec.executionContext) {
try {
// Setup a job tag here so later it may get cancelled by tag if necessary.
sparkContext.addJobTag(jobTag)
sparkContext.setInterruptOnCancel(true)
val beforeCollect = System.nanoTime()
// Use executeCollect/executeCollectIterator to avoid conversion to Scala types
val (numRows, input) = child.executeCollectIterator()
...
val relation = mode.transform(input, Some(numRows))
val dataSize = relation match {
case map: HashedRelation =>
map.estimatedSize
case arr: Array[InternalRow] =>
arr.map(_.asInstanceOf[UnsafeRow].getSizeInBytes.toLong).sum
case _ =>
throw new SparkException("[BUG] BroadcastMode.transform returned unexpected " +
s"type: ${relation.getClass.getName}")
}
longMetric("dataSize") += dataSize
其中child.executeCollectIterator() 是在把数据从各个 Executor 收集到 Driver 端来,便于进行广播操作。
最主要的是 mode.transform(input, Some(numRows)),这里的数据流如下:
HashedRelationBroadcastMode.transform
||
\/
HashedRelation.apply(rows, key, numRows.toInt, isNullAware = isNullAware)
||
\/
UnsafeHashedRelation.apply(input, key, sizeEstimate, mm, isNullAware, allowsNullKey,
ignoresDuplicatedKey)
||
\/
new UnsafeHashedRelation(key.size, numFields, binaryMap)
最终调用的 UnsafeHashedRelation.estimatedSize的方法:
override def estimatedSize: Long = binaryMap.getTotalMemoryConsumption
而 getTotalMemoryConsumption 是dataPages所占用的大小再加上longArray的大小:
public long getTotalMemoryConsumption() {
long totalDataPagesSize = 0L;
for (MemoryBlock dataPage : dataPages) {
totalDataPagesSize += dataPage.size();
}
return totalDataPagesSize + ((longArray != null) ? longArray.memoryBlock().size() : 0L);
}
那么 BytesToBytesMap 是怎么分配的呢?如下:
val binaryMap = new BytesToBytesMap(
taskMemoryManager,
// Only 70% of the slots can be used before growing, more capacity help to reduce collision
(sizeEstimate * 1.5 + 1).toInt,
pageSizeBytes)
默认的PageSize值为:defaultPageSizeBytes:
private lazy val defaultPageSizeBytes = {
val minPageSize = 1L * 1024 * 1024 // 1MB
val maxPageSize = 64L * minPageSize // 64MB
val cores = if (numCores > 0) numCores else Runtime.getRuntime.availableProcessors()
// Because of rounding to next power of 2, we may have safetyFactor as 8 in worst case
val safetyFactor = 16
val maxTungstenMemory: Long = tungstenMemoryMode match {
case MemoryMode.ON_HEAP => onHeapExecutionMemoryPool.poolSize
case MemoryMode.OFF_HEAP => offHeapExecutionMemoryPool.poolSize
}
val size = ByteArrayMethods.nextPowerOf2(maxTungstenMemory / cores / safetyFactor)
val chosenPageSize = math.min(maxPageSize, math.max(minPageSize, size))
if (Utils.isG1GC && tungstenMemoryMode == MemoryMode.ON_HEAP) {
chosenPageSize - Platform.LONG_ARRAY_OFFSET
} else {
chosenPageSize
}
}
这个跟内存以及core有关。
当在进行val loc = binaryMap.lookup 以及loc.append操作的时候就会进行dataPage以及longArray的分配。而该size的大小并不是实际占用的大小,而是分配给该dataPage的大小。其实你会发现该datasize的大小几乎和2的倍数接近。