一、首先看网址
后面有全部代码
https://hf.fang.anjuke.com/loupan/baohequ/p3
这种形式很好分析,https://hf.fang.anjuke.com/loupan/+行政区域+页码
xinfang_area = ["feixixian", "baohequ", "shushanqu", "luyangqu", "yaohaiqu", "gaoxinqu","feidongxian", "zhengwuqu", "jingjikaifaqu"] # 行政区域
url = "https://hf.fang.anjuke.com/loupan" # 新房
new_url = f"{url}/{area}/p{n}" # 网页
我们用requests库获取页面内容,再用bs解析,获得bs对象,代码:
for area in xinfang_area:
n = 1
while True:
headers = make_headers()
if n == 1:
new_url = f"{url}/{area}"
else:
new_url = f"{url}/{area}/p{n}"
print(new_url)
res = requests.get(new_url, headers=headers).text
content = BeautifulSoup(res, "html.parser")
if content is None: # 重试
n = 1
continue二、看内容

每一块的内容都是在 <div class="item-mod">标签下面
根据刚获取的页面内容(页面包含当页所有楼盘的内容),用bs的find_all根据class:item-mod获得所有块的列表,我们看看每一块的网页是什么:
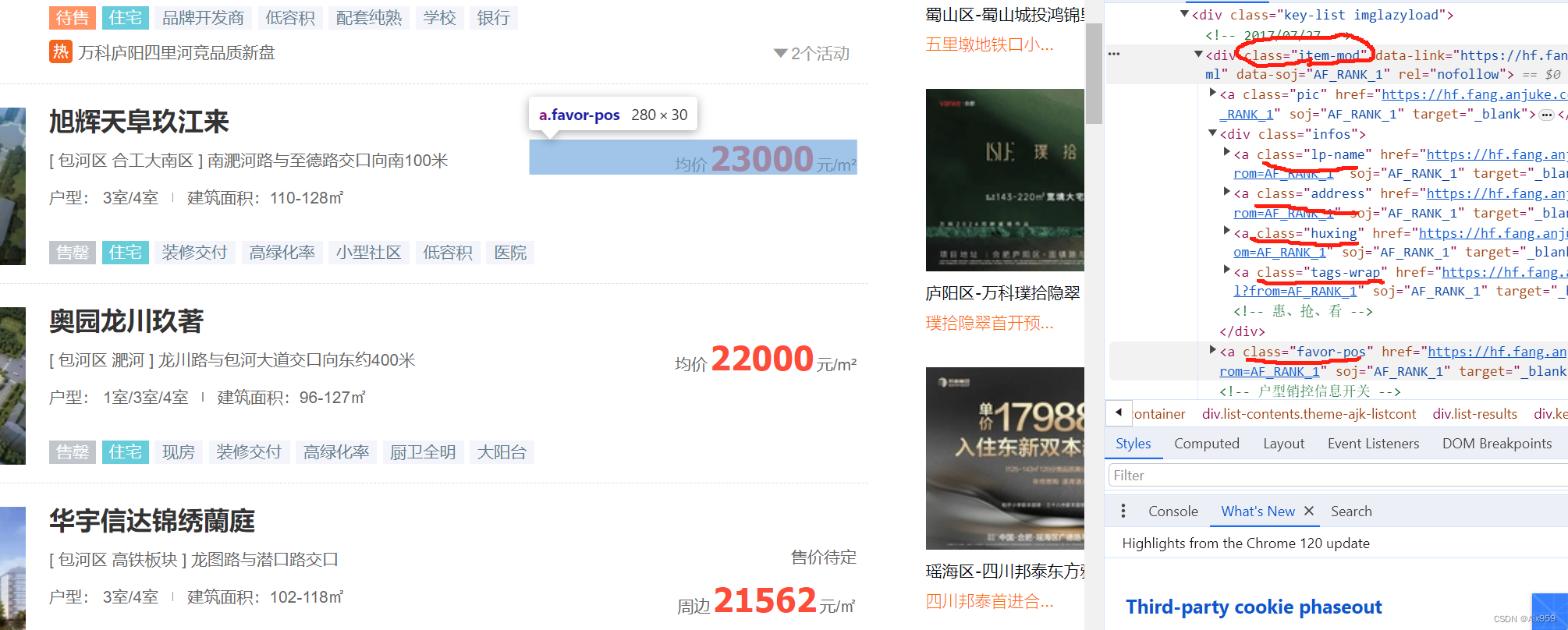
根据每一块的,内容代码基本完成了:
data = content.find_all('div', attrs={'class': 'item-mod'})
for d in data:
lp_name = d.find_next("a", attrs={"class": "lp-name"}).text
address = d.find_next("a", attrs={"class": "address"}).text
huxing = d.find_next("a", attrs={"class": "huxing"}).text
tags = d.find_next("a", attrs={"class": "tags-wrap"}).text
prices = d.find_next("a", attrs={"class": "favor-pos"}).text
price = re.findall(r'\d+', prices)[0] # 具体价格
# 写入数据
row_data = [area, lp_name, address, huxing, tags, prices, price]
with open(file_name, 'a', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(row_data)
m += 1
print(area, f"第{n}页第{m}条数据")三、换区域逻辑
不废话,直接分析
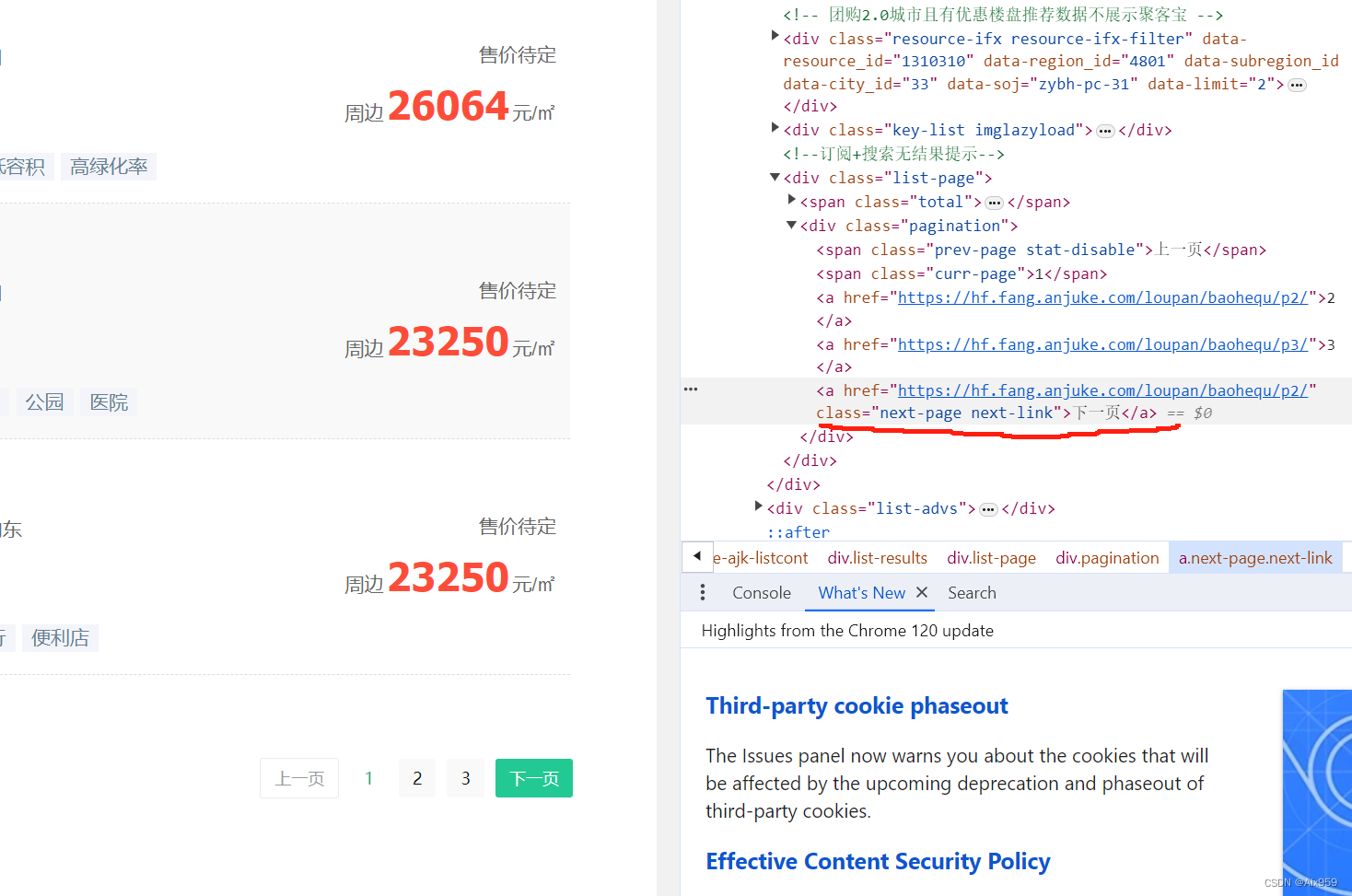
我们看到页面有下一页标签,我们对比有下一页与尾页的下一页标签的不同
这是有下一页的
这是尾页的
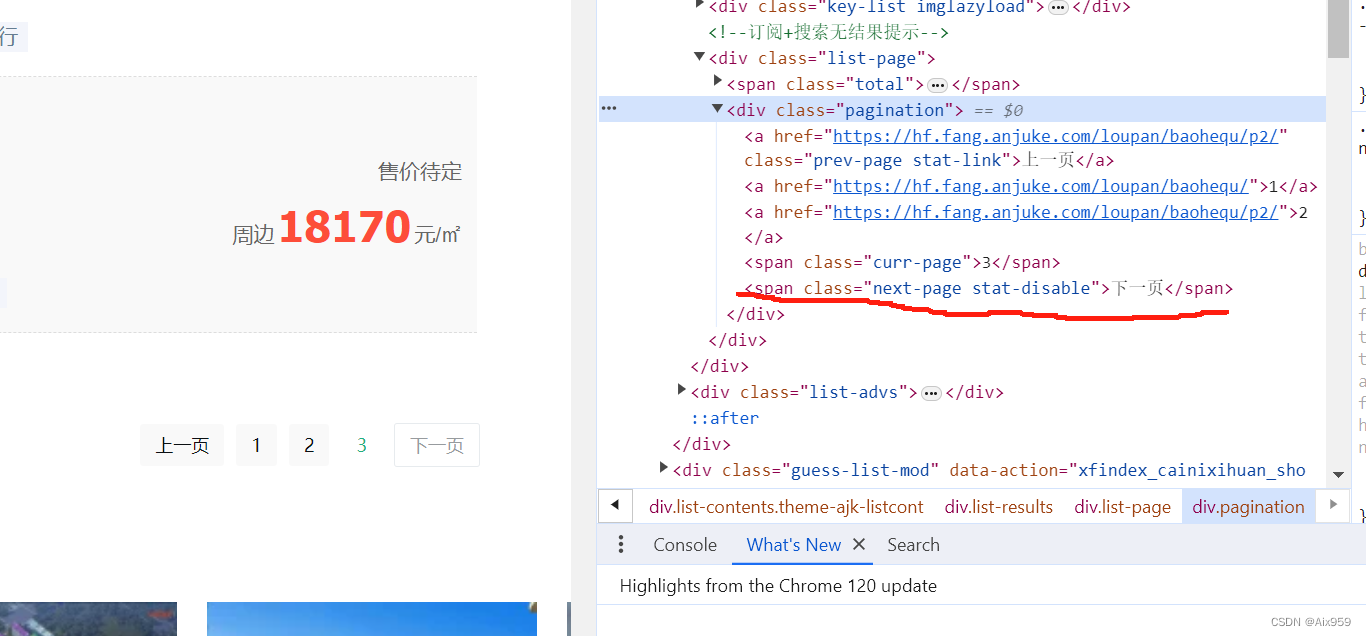
我们发现,如果尾页的下一页标签<span class="next-page stat-disable"> 说明是尾页了
此时我们的网页可以到下一个区域爬取了
next_page = content.find('span', attrs={'class': 'next-page stat-disable'})
if next_page is not None: # 没有下一页
break
四、全部代码
注意,如果没有数据可能是网页需要验证!
其他城市自己分析网页试试吧,我就不解释了
import requests
import csv
import time
import re
from bs4 import BeautifulSoup
from user_agent import make_headers
xinfang_area = ["feixixian", "baohequ", "shushanqu", "luyangqu", "yaohaiqu", "gaoxinqu",
"feidongxian", "zhengwuqu", "jingjikaifaqu"]
url = "https://hf.fang.anjuke.com/loupan" # 新房
file_name = 'anjuke/xinfang.csv'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0"}
with open(file_name, 'w', encoding='utf-8') as f:
writer = csv.writer(f)
# 2:写表头
writer.writerow(['区域', '楼盘', '地址', '户型', "其他", '价格', '单价'])
for area in xinfang_area:
n = 1
while True:
# headers = make_headers()
if n == 1:
new_url = f"{url}/{area}"
else:
new_url = f"{url}/{area}/p{n}"
print(new_url)
res = requests.get(new_url, headers=headers).text
content = BeautifulSoup(res, "html.parser")
if content is None: # 重试
n = 1
print("正在重试")
continue
# 当前页和尾页判断
next_page = content.find('span', attrs={'class': 'next-page stat-disable'})
# 解析数据
print(area, f"第{n}页数据")
m = 0
data = content.find_all('div', attrs={'class': 'item-mod'})
for d in data:
lp_name = d.find_next("a", attrs={"class": "lp-name"}).text
address = d.find_next("a", attrs={"class": "address"}).text
huxing = d.find_next("a", attrs={"class": "huxing"}).text
tags = d.find_next("a", attrs={"class": "tags-wrap"}).text
prices = d.find_next("a", attrs={"class": "favor-pos"}).text
price = re.findall(r'\d+', prices) # 具体价格
if len(price) > 0:
price = price[0]
# 写入数据
row_data = [area, lp_name, address, huxing, tags, prices, price]
with open(file_name, 'a', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(row_data)
m += 1
print(area, f"第{n}页第{m}条数据")
if next_page is not None: # 没有下一页
break
n += 1
time.sleep(2)
new_url = None