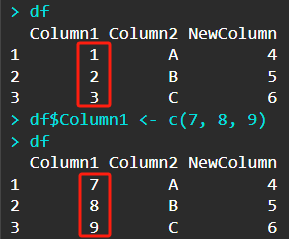
一些细节:
在训练前 有一个tudui.train()的作用:
如果网络里有dropout/batchnorm等层,就需要用到tudui.train(),也就是没有这些层的话,tudui.train()没用调用不调用都行
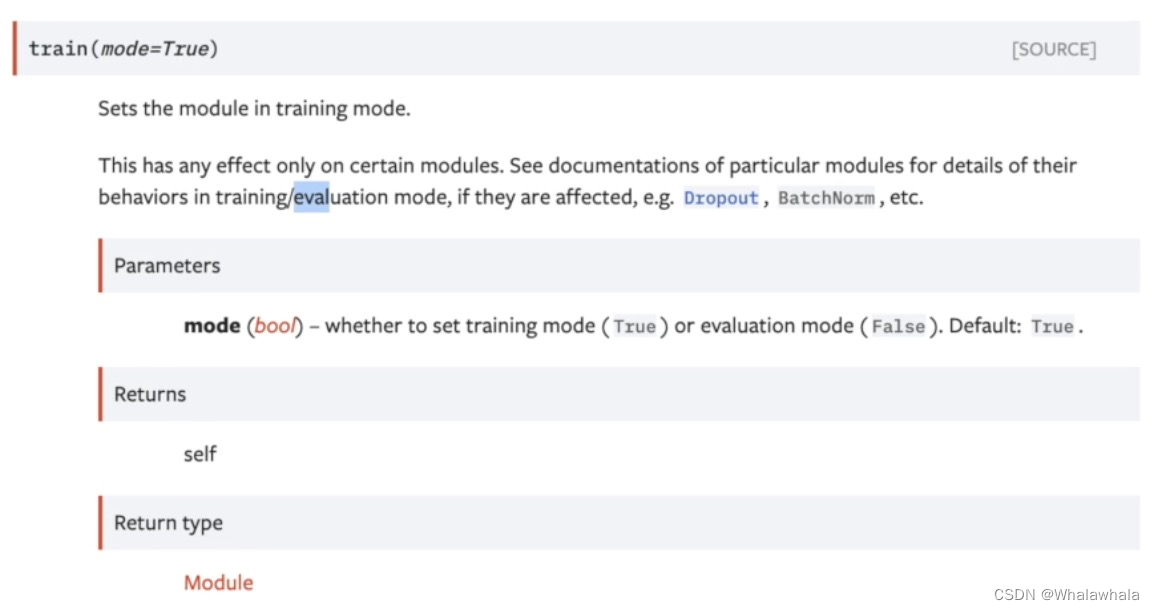 在测试前 有一个
在测试前 有一个tudui.eval()的作用:
同上
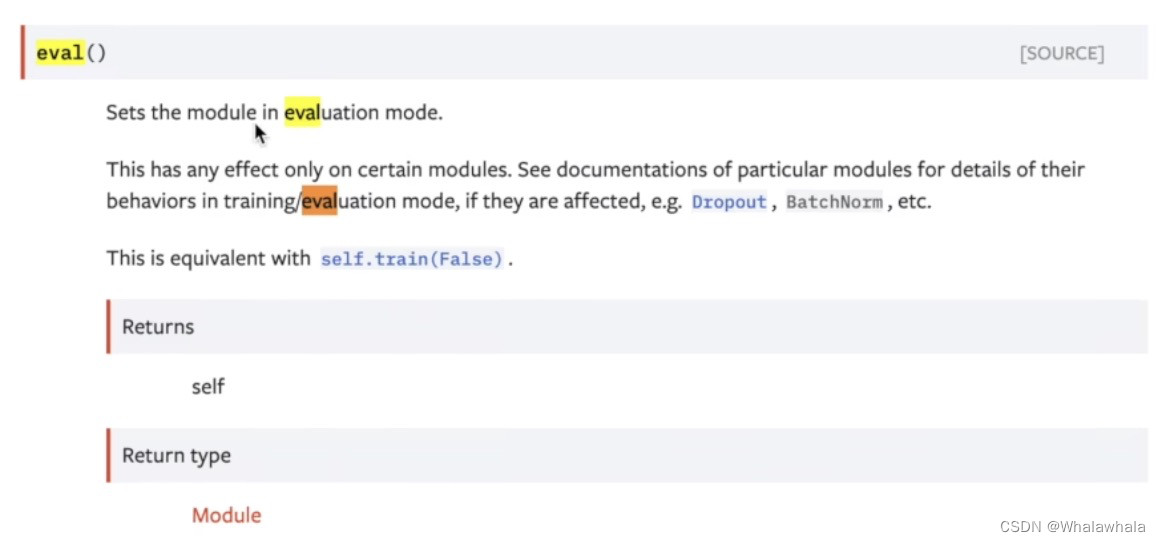
整个训练逻辑:
- 准备数据
- dataloader加载数据集
- 创建网络模型(看注释a)
- 定义损失函数、优化器
- 设置训练网络的一些参数,如训练的次数、测试的次数、训练的轮数等
- (可选)添加tensorboard
- 开始第一轮训练,每轮训练包括 { 从dataloader取数据
for data in train_dataloader,优化器优化模型,输出提示信息等 } - 测试,最好要有
with torch.no_grad():{ 可以自己定义一些指标,还有损失 } - 展示网络在数据集上的效果,保存模型为.pth或者.pt等 { 官方推荐的保存方法为,
torch.save(tudui.state_dict(), "tudui_{}.pth".format(i)),这样可以以字典形式保存模型的参数,不保存别的,少占内存 }
注释a: 创建网络模型为tudui = Tudui(),至于class Tudui,可以在另一个.py文件中,之后使用from在头文件那里引进来