在数据分析过程中离不开表格,通常使用Excel来做数据分析,行和列用来存放不同的数据,表格能清晰直观的展示数据,而且可以将多张表组合联系起来,这种不约而同的规范也同样适用于R语言。
R语言中的数据框(DataFrame)是一种非常重要的数据结构,用于存储和处理表格数据。数据框类似于一个表格,其中包含行和列,每列可以包含不同类型的数据(如数字、字符或因子),但同一列中的所有数据必须是相同类型。
数据框的用法
df <- data.frame(Column1 = c(1, 2, 3), Column2 = c("A", "B", "C"))
以上就创建了一个基础的数据框结构,包含两列信息(使用col表示列),每列是一种指标($变量可以用来索引列元素),每行是一个观测(一条记录信息,使用row来表示行)。

访问数据框的元素
数据框是一张表格,要想获取其中指定的单元格的值,可以通过索引来提取。就像去菜鸟驿站找包裹一样,首先根据取件码确定在第几个货架,然后再看看第几层,最后看看是第几个位置。
在R语言中,每个数据框就相当于一个货架,当需要使用的时候就拎出来,通过行序号和列序号就能找到想要的数值。
-
通过列名进行提取
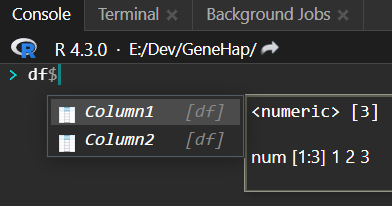
当输入数据框和$符号,系统会自动将这个数据框的每一列展示出来,通过上下键可以快速切换,从而选中想要的列。
> df$Column1 # 比如这里我想获得第一列的值
[1] 1 2 3
如果我想看看第一列的第二个数字是什么,则可以在刚刚的基础上添加[]符号,获取对应的元素。
> df$Column1[2]
[1] 2
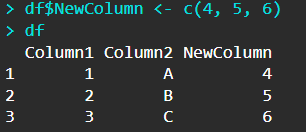
添加和修改列
df$NewColumn <- c(4, 5, 6)
如果在$后面输入一个新的列名,就可以向数据框中添加一个新列,默认是在右侧追加生成新的数据框。
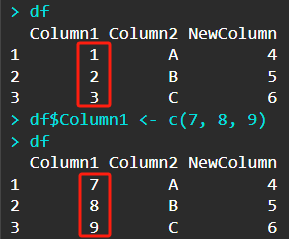
如果$后面跟的是一个已存在于数据框的列名,那么可以对数据框的值进行修改,例如以下操作能够将数据框的第一列重新赋值。
其他实用技巧
筛选和子集:
条件筛选:
subset(df, Column1 > 2)
选择特定列:
df[, c("Column1", "NewColumn")]
排序:
使用order()函数:
df[order(df$Column1),]
应用函数:
使用apply(), lapply(), sapply()等函数处理数据框中的数据,能够实现循环操作,而且速度比for循环更快。
合并数据框:
使用rbind()合并行,使用cbind()合并列,这两个功能在实际处理中用的很多,多个数据框的组合。
数据框使用注意事项
数据类型一致性:
确保每列中的数据类型是一致的,同一列的元素应该是同一种类型,尤其是数字与字符串不能混合使用。
列名:
列名应该是唯一的,且不应使用空格或特殊字符。列名不能以数字开头,尽量保持一定格式规范,这样在使用的时候才更方便。
缺失数据:
在处理数据框时要注意NA值(缺失数据),可能需要进行处理,如填充或删除,需要注意一点,缺失在R语言中使用is.na来进行判断。
大数据集处理:
对于非常大的数据集,标准的数据框可能效率不高。可以考虑使用data.table或dplyr等高效的数据处理包,速度更快。
因子类型的处理:
因子(Factor)类型在数据分析中非常常用,但在处理时需要特别注意(如转换为字符型或数值型)。
数据框是R语言中非常强大且灵活的数据结构,适用于各种数据处理和分析任务。掌握其使用方法和注意事项对于进行有效的数据分析至关重要。
本文由 mdnice 多平台发布





![[python]使用pyqt5搭建yolov8钢筋计数一次性钢材计数系统](https://img-blog.csdnimg.cn/direct/5985eb5ebb9b4e4189025acb4d4dd1e2.jpeg)