一、大模型系统中检索增强生成(RAG)的意义
当前大模型在处理特定领域或者高度专业化的查询时表现出知识缺失,当所需信息超出模型训练数据范围或需要最新数据时,大模型可能无法提供准确答案。基于行业SOP、行业标准、互联网实时信息等领域外部知识构建私域知识向量模型,设计RAG系统用于多文档、多源数据、多维数据的检索器,设计优化双编码、联合编码等方法的信息生成器,使得生成组件能够更深入地理解问题背后的上下文,并产生更加信息丰富的回答。
二、LLM-RAG的框架设计
整体框架包括 大部分:私域知识的嵌入;文档知识的分割;私域知识的向量化;大模型的装载;问答链的组装;

1、私域知识的嵌入
借助langchain及llama-index开发框架可满足目前大部分知识形式的嵌入,包括数据库、PDF、word、excel、csv、txt、markdown、知识图谱(neo4j)、图片等。
Llama-index提供的知识嵌入工具
Langchain 知识嵌入工具
2、文档知识的分割
我们知道目前的大模型对处理信息的多少有限制,输入到大模型系统内的信息量及其组合将直接影响大模型给出答案的相关性、准确性和及时性。因此对文档知识的合理分割是提升大模型检索增强及生成问答的关键。
文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下:
句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
3、私域知识的向量化
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
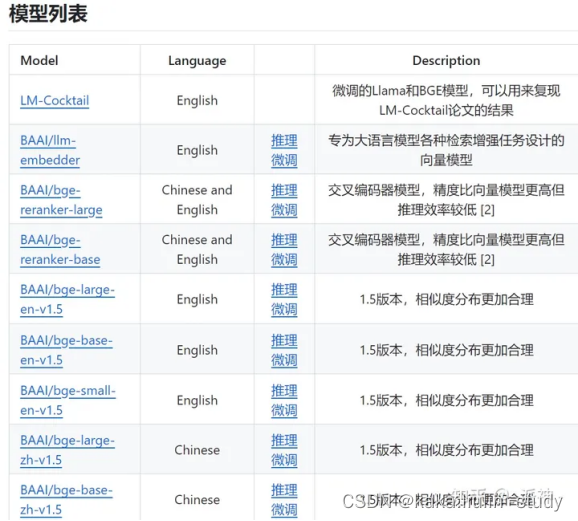
知识向量化的几种方式:
#modelscope下载:国内推荐
from langchain.embeddings import ModelScopeEmbeddings
model_id = "damo/nlp_corom_sentence-embedding_chinese-base"
#damo/nlp_corom_sentence-embedding_chinese-base
#damo/nlp_corom_sentence-embedding_english-base
embeddings = ModelScopeEmbeddings(model_id=model_id)
#hunggingface下载:国外推荐
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2")
#from langchain.embeddings import SentenceTransformerEmbeddings
#embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# 构建向量数据库
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
)
4、大模型的装载
目前基于大模型的应用开发有多种框架,如何根据硬件、场景需求等高效、便捷装载大模型是开发LLM-RAG系统的关键。以下汇总了多种装载方式:
1)基于llama.cpp的cpu低成本装载:主要模型文件来自于hunggingface;
2)基于chatglm.cpp的CPU低成本装载:包括langchian[api]、openai[api]等形式。
3)基于langchain及Hugging Face Local Pipelines装载:支持的模型参考langchian文档中心。
5、问答链的组装
同样的,langchain为我们准备了一些构造好的问答链(langchain chains),包括sql数据库查询链、CSV查询链、html查询链、问答链等。
三、LLM-RAG的实践
1、多种方式低成本装载LLM
① langchain local_model形式
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM,pipeline
import torch
from langchain.llms.huggingface_pipeline import HuggingFacePipeline
model_path = "Qwen/Qwen-1_8B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda(0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=200000)
llm = HuggingFacePipeline(pipeline=pipe)
② langchain chatglm.cpp形式
参考chatglm.cpp GitHub网站:https://github.com/li-plus/chatglm.cpp
#安装chatglm.cpp库
!pip install --upgrade pip
!pip install chatglm.cpp[api]
#下载chatglm3-6b cpu量化文件
!git clone https://www.modelscope.cn/tiansz/chatglm3-6b-ggml.git
#启动 chatglm3-6b langchain-api服务
MODEL=./chatglm3-6b-ggml/chatglm3-ggml.bin uvicorn chatglm_cpp.langchain_api:app --host 127.0.0.1 --port 8000
获得chatglm3-6b langchain-api服务地址:http://127.0.0.1:8000
将chatglm3-6b接入langchain框架
endpoint_url = "http://127.0.0.1:8000"
llm = ChatGLM(
endpoint_url=endpoint_url,
max_token=1024,
history=[
["我是数据分析师,可以向我查询任何关于数据分析的问题。"]
],
top_p=0.9,
model_kwargs={"sample_model_args": False},
)
③ langchian llama.cpp形式
llama.cpp是使用原始C ++的项目来重写LLaMa(长格式语言模型)等开源大模型推理代码。这使得可以在各种硬件上本地运行大模型。
#安装llama-cpp
!pip install llama-cpp-python
#从modelscope或者hunggingface下载量化模型:gguf
from modelscope.hub.file_download import model_file_download
model_dir = model_file_download(model_id='mikeee/TheBloke-openbuddy-zephyr-7B-v14.1-GGUF',file_path='openbuddy-zephyr-7b-v14.1.Q4_K_S.gguf',cache_dir='./Qwen')
#载入大模型
from langchain.llms import LlamaCpp
from langchain.prompts import PromptTemplate
from langchain.callbacks.manager import CallbackManager
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
n_gpu_layers =0 # Change this value based on your model and your GPU VRAM pool.
n_batch = 5120 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# Make sure the model path is correct for your system!
llm = LlamaCpp(
model_path="./Qwen/mikeee/TheBloke-openbuddy-zephyr-7B-v14.1-GGUF/openbuddy-zephyr-7b-v14.1.Q4_K_S.gguf",
n_gpu_layers=n_gpu_layers,
n_batch=n_batch,
max_tokens=200000,
n_ctx=8912,
callback_manager=callback_manager,
verbose=True, # Verbose is required to pass to the callback manager
)
2、私有知识的装载及向量化
① 多文档处理
#装载文件
def get_doc(dir_path):
file_lst = os.listdir(dir_path)
docs = []
i = 1
for file in file_lst:
file_type = file.split('.')[-1]
#print(file_type)
if file_type == 'docx':
loader = UnstructuredWordDocumentLoader(dir_path+'/'+file)
elif file_type == 'csv':
loader = UnstructuredCSVLoader(dir_path+'/'+file)
elif file_type == 'pdf':
loader = UnstructuredPDFLoader(dir_path+'/'+file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
print(str(i)+'-----'+file+'------完成装载')
i = +1
return docs
文档分割及向量化
#载入开源向量化模型
from langchain.embeddings import ModelScopeEmbeddings
model_id = "damo/nlp_corom_sentence-embedding_chinese-base"
#damo/nlp_corom_sentence-embedding_chinese-base
#damo/nlp_corom_sentence-embedding_english-base
embeddings = ModelScopeEmbeddings(model_id=model_id)
#文档分割
docs = get_doc('./Qwen')
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
#文档向量化
split_docs = text_splitter.split_documents(docs)
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings
)
② 单文档处理
#pdf
loader = UnstructuredPDFLoader('./Qwen/2304.08485.pdf')
docs=loader.load()
#docx
loader = UnstructuredWordDocumentLoader('./Qwen/《主数据质量检查报告》LL.docx')
docs=loader.load()
#csv
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="./Qwen/正则式.csv")
docs = loader.load()
#web文件
from langchain.document_loaders import AsyncHtmlLoader
urls = ["https://price.21food.cn/yurou/", "https://price.21food.cn/fushipin/"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
3、文档:RAG Q&A
使用 RetrievalQA 作为问答链
from langchain.prompts import PromptTemplate
# 我们所构造的 Prompt 模板
template = """你是一个数据治理工程师同时也是一个知识搜索查询工程师,请根据可参考的上下文回答用户的问题,如果用户的问题不清晰且不是给定的上下文覆盖的,请不要乱回答,请回答 抱歉!我尚未学习该知识。
问题: {question}
可参考的上下文:
···
{context}
···
基于用户给定的信息,重新汇总上下文生成精准的回答。
如果给定的上下文无法让你做出回答,请回答你不知道。
有用的回答:"""
# 调用 LangChain 的方法来实例化一个 Template 对象,该对象包含了 context 和 question 两个变量,在实际调用时,这两个变量会被检索到的文档片段和用户提问填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
#Q&A
question = "千信金属产业园主要业务数据以及业务术语有哪些?"
result = qa_chain({"query": question})
print("检索问答链回答 question 的结果:")
print(result["result"])
使用 ConversationalRetrievalChain 问答链检索增强生成
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
bot = ConversationalRetrievalChain.from_llm(llm, retriever=vectordb.as_retriever(),memory=memory,verbose=True,return_source_documents=False)
query = "根基提供的上下文,千信产业园主要业务术语及主数据,并给出数据治理的建议"
result = bot.invoke({"question": query})
result["answer"]
4、问答结果探讨
将某企业的数据治理方向的一些文档做成私有知识库,基于私有知识库回答数据治理方面的问题。
私有知识库文档
问题一:
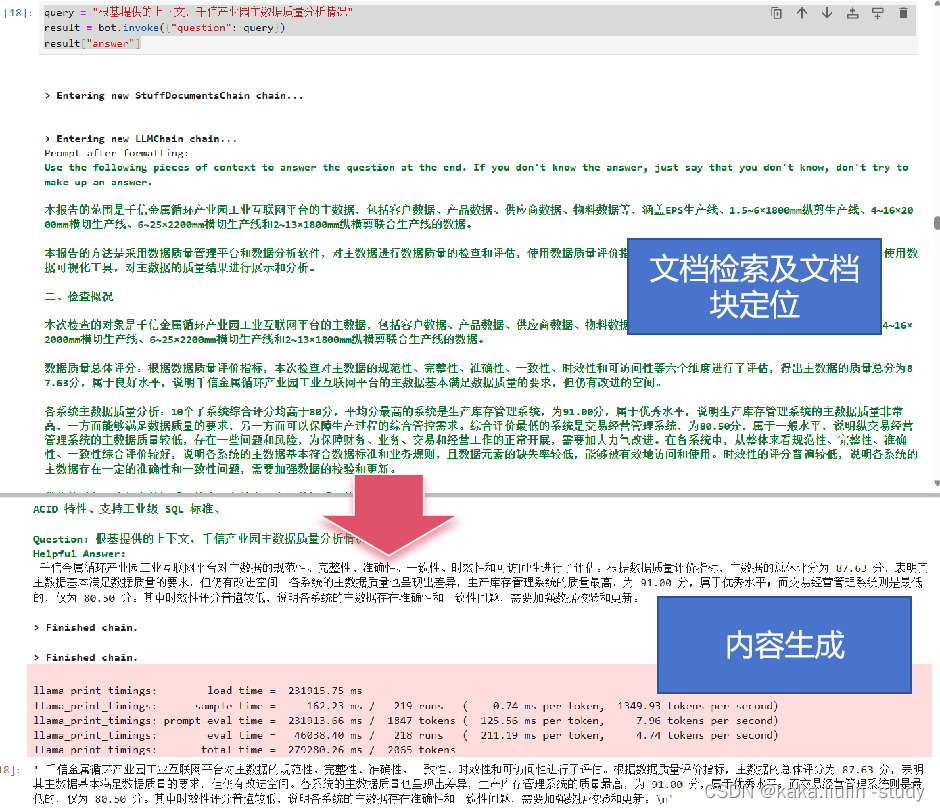
query = "根基提供的上下文,千信产业园主数据质量分析情况"
result = bot.invoke({"question": query})
result["answer"]
结果分析:对于私有知识库内确定的知识,整个RAG系统能比较精准的定位检索到用户问题所需的文档及文档块,并给出精准的答案。
问题二:
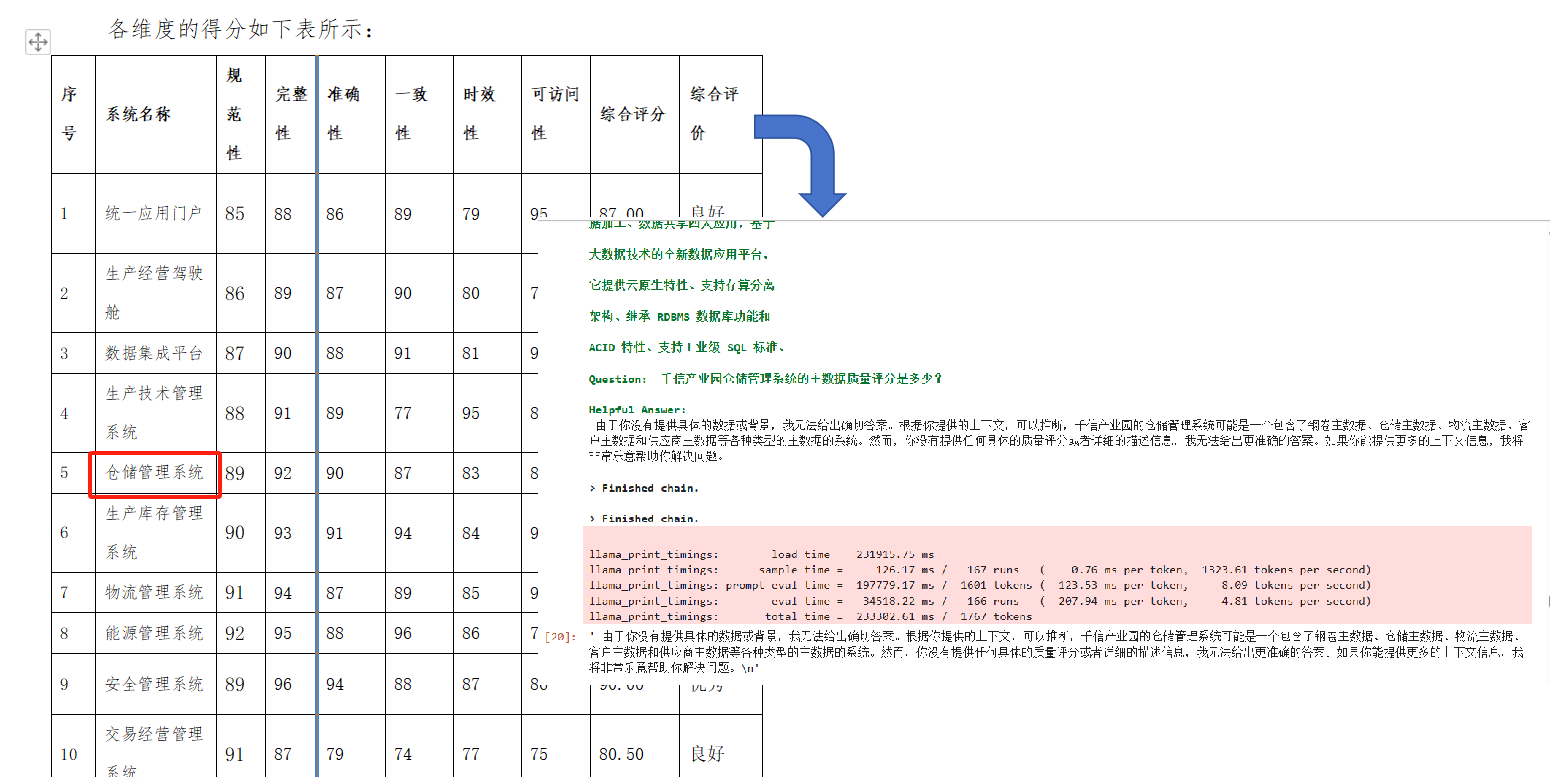
query = "根基提供的上下文,千信产业园仓储管理系统主数据质量评分都是多少"
result = bot.invoke({"question": query})
result["answer"]
结果分析:对于文档内存在的表格,目前简单的检索链和问答链无法给出精准的回答,分析原因应该是表格数据的检索还是需要使用CSV文件的嵌入以及CSV-chain才能获取精准的答案。


![[娱乐]索尼电视安装Kodi](https://img-blog.csdnimg.cn/direct/1e61f069e7794ed6b98f0204eba4a4ee.png)