「发表于知乎专栏《移动端算法优化》」
本文主要介绍OpenCL的 Kernel,包括代码的实例以及使用注意的详解。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能(HPC)开发基础教程
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
一、概述
二、OpenCL kernel 样例
2.1 kernel 代码样例
2.2 kernel 代码存储
三、 OpenCL C 语言介绍
3.1 数据类型
3.2 矢量加载和存储
3.3 修饰符
3.4 运算符
3.5 build-in 函数
3.6 shuffle 和 select 函数
3.7 native 函数
四、OpenCL 高斯滤波 kernel 实例
五、工程代码
六、参考资料
一、概述
OpenCL程序由host端运行时API调用和OpenCL kernel 两部分组成,在“GPU 优化技术-OpenCL 运行时 API 介绍”中我们已经对host端运行时API做了系统而详细的介绍,接下来我们开始OpenCL kernel 部分的介绍。
OpenCL kernel 是运行在设备端的,采用OpenCL C 语言进行开发,本文接下来首先给出一个简单的OpenCL kernel 样例,然后对OpenCL C 语言的各个部分做详细的说明,最后会给出一个完整的OpenCL程序实例,相信通过本文的学习之后大家应该可以在实际工作中使用OpenCL来优化程序的性能。
二、OpenCL kernel 样例
OpenCL kernel函数的整体结构和C函数像似,由函数名、形参列表以及大括号包含的执行语句构成,但是和C函数还有几点不同。
- 每个内核函数的声明都以__kernel或者kernel开头;
- 内核函数的返回类型必须是void类型;
- 如果内核函数不带参数,可能在某些厂商平台会编译报错;
通过下面样例代码展示一部分OpenCL C语言内容,后面会针对这些语言组成进行详细说明。
2.1 kernel 代码样例
下面kernel样例是一维矩阵向量相加操作,每个工作项计算一个矩阵中的8个元素,实现并行计算。
__kernel void add(__global uchar *a,
__global uchar *b,
__global ushort *dst,
__private const int length)
{
// 获取工作项索引
int idx = get_global_id(0) << 3;
// 边界判断
if (idx >= length)
{
return;
}
// 每个工作项处理8个元素
// vload8实现一次加载8个元素
ushort8 a_ln = convert_ushort8(vload8(0, a + idx));
ushort8 b_ln = convert_ushort8(vload8(0, b + idx));
// 向量相加
ushort8 c_ln = a_ln + b_ln;
// 存储结算结果
vstore8(c_ln, 0, dst + idx);
}- 函数名
__kernel是必须要有,函数声明为可由OpenCL设备上的应用程序执行的内核,告诉编译器这是一个OpenCL 内核函数。
- 函数形参
内核函数也可以通过值传递和引用传递两种方式传递参数,如果内核参数是结构体,内核函数性能会下降,一般不与推荐使用。
__global uchar *a、__global uchar *b等使用了全局内存区域(__global),对应下图中的Global Memory,这块内存区域空间最大,latency最高是GPU最基础的内存。
__private const int length、int idx等内部寄存器变量使用私有内存区域(__private),对应下图存Private Memory,这块内存区域是每个工作组独有的,工作组和工作组之间不可相互访问,同一个工作组中的工作项共享一块内存区域。

OpenCL 内存模型
- 函数返回值
内核函数规定不能有返回值,返回类型只能是void类型。
2.2 kernel 代码存储
从CL的API函数clCreateProgramWithSource可知,编译cl_program需要我们输入kernel字符串。
- 文本文件保存
内核代码可以保存为后缀名为".cl"的文本文件,如add_kernel.cl。其读取处理方式和一般文件处理方式相同。同时add_kernel.cl的内容格式与C语言风格相似,很多代码编辑器(例如vscode)能自动识别.cl文件从而可以显示相应的语法高亮。

.cl文件
.cl文件转换为字符串
通过读取文件方式,我们需要把.cl文件内容转换为C字符串,然后对字符串的代码进行源码编译。
std::string ClReadString(const std::string &filename)
{
std::ifstream fs(filename);
if(!fs.is_open())
{
std::cout << "open " << filename << " fail!" << std::endl;
}
return std::string((std::istreambuf_iterator<char>(fs)), std::istreambuf_iterator<char>());
}
std::string source_name = "gaussian.cl";
std::string program_source = ClReadString(source_name);
char *cl_str = (char *)program_source.c_str();
program = clCreateProgramWithSource(context, 1, (const char **)&cl_str, NULL, NULL);- 字符串保存
#define CL_KERNEL(...) #__VA_ARGS__
static const MI_CHAR *add_cl_kernel_str = CL_KERNEL(
__kernel void add(__global uchar *a,
__global uchar *b,
__global uchar *dst,
__private const int length)
{
int idx = get_global_id(0);
if (idx >= length)
{
return;
}
dst[idx] = a[idx] + b[idx];
}
);
program = clCreateProgramWithSource(context, 1, (const char **)& add_cl_kernel_str , NULL, NULL);三、 OpenCL C 语言介绍
OpenCL C严格遵循C99标准,不支持标准C99头文件、函数指针、递归、变长数组和位域等,但是增加了一些超集包括工作项和工作组、矢量数据类型、同步和地址空间限定符以及一些内置函数包括image、sampler图像处理函数、工作项函数和native函数,实现高效的性能。
3.1 数据类型
数据类型主要有三部分,最基础的标量数据类型和C99标准保持一致,额外新增了矢量数据类型和其他内置image和sampler等类型。
3.1.1 标量数据类型
OpenCL支持的标量数据类型比较简单,功能和C/C++中的数据类型一样。需要强调注意的点在于半精度和双精度浮点数是可选项。
| 类型 | API类型 | 描述 |
|---|---|---|
| char/uchar | cl_char/cl_uchar | 有/无符号8位整数 |
| short/ushort | cl_short/cl_ushort | 有/无符号16位整数 |
| int/uint | cl_int/cl_uint | 有/无符号32位整数 |
| long/ulong | cl_long/cl_ulong | 有/无符号64位整数 |
| float/double | cl_float/cl_double | 32位浮点数/64位浮点数,符合IEEE754存储格式 |
| half | cl_half | 16位浮点数。half数据类型必须符合IEEE754-2008半精度存储格式 |
| size_t | n/a | 无符号整数类型,sizeof结果类型,匹配设备地址空间(32、64) |
| void | void | 无类型数据 |
3.1.1.1 半精度浮点数

半精度浮点
- 高通Adreno GPU具有专门的硬件ALU来加速半精度计算,半精度ALU的GFLOPs几乎是单精度的两倍。但是16bit半精度支持有限,表示的精度范围有限,在整数值上只能表示[0,2048]范围,因此在和浮点混合使用会出现精度误差问题。
- 针对半精度类型,需要查询设备是否支持半精度浮点数,如果device_flag结果为0,则说明设备不支持双精度。
int device_flag = 1;
err = clGetDeviceInfo(device,CL_DEVICE_HALF_FP_CONFIG, sizeof(cl_device_fp_config),
&device_flag, NULL);- 对于支持半精度浮点运算的设备,为了在内核函数中启用此功能,需要添加如下预处理器指令,另外内核程序编译选项添加"-D FP16",使能内核程序代码FP_16宏定义。
#ifdef FP16
#pragma OpenCL EXTENSION cl_khr_fp16 : enable
#endif3.1.1.2 双精度浮点数
针对可选项类型,高通Adreno GPU不支持双精度浮点数,因此需要查询设备是否支持双精度浮点数,如果device_flag结果为0,则说明设备不支持双精度。
int device_flag = 1;
err = clGetDeviceInfo(device,CL_DEVICE_DOUBLE_FP_CONFIG, sizeof(cl_device_fp_config),
&device_flag, NULL);
对于支持双精度浮点运算的设备,为了在内核函数中启用此功能,需要添加如下预处理器指令,另外内核程序编译选项添加"-D FP64",使能内核程序代码FP_64宏定义。
#ifdef FP64
#pragma OpenCL EXTENSION cl_khr_fp64 : enable
#endif对于OpenCL设备而言,双精度计算速度比单精度慢2~3倍,因此为了提升整体程序的性能,尽量使用单精度浮点类型。
3.1.2 矢量数据类型
变量后面是一个n来定义矢量中的元素个数,对所有矢量数据类型,支持的n值包括2、3、4、8和16。double类型是可选项,需要设备支持双精度时才可用。
高通Adreno设备上使用矢量数据编写kernel,性能会有2倍左右的提升。然后在Mali设备上矢量类型kernel和标量类型kernel性能没有差异。
3.1.2.1 矢量数据类型分类
| 类型 | API类型 | 描述 |
|---|---|---|
| charn/ucharn | cl_charn/cl_ucharn | n个8位有/无符号整数值的矢量 |
| shortn/ushortn | cl_shortn/cl_ushortn | n个16位有/无符号整数值的矢量 |
| intn/uintn | cl_intn/cl_uintn | n个32位有/无符号整数值的矢量 |
| longn/ulongn | cl_longn/cl_ulongn | n个64位有/无符号整数值的矢量 |
| floatn | cl_floatn | n个32位浮点数值的矢量 |
| doublen | cl_doublen | n个64位浮点数值的矢量 |
矢量初始化
可以由一组标量、矢量或标量和矢量的组合来初始化一个矢量的值。
矢量初始化写法:
float4 v0 = (float4)(1.0f, 2.0f, 3.0f, 4.0f);
//如果标量值都相等
float4 v1 = (float4)(1.0f); // 代表四个值都为1.0f
//小宽度矢量初始化大宽度矢量
float2 v2 = (float2)(1.0f, 2.0f);
float2 v3 = (float2)(3.0f, 4.0f);
float4 v4 = (float4)(v2, v3);
//矢量标量结合初始化矢量
float3 vrgb = (float3)(0.25, 0.5, 0.75);
float4 rgba = (float4)(vrgb, 1.0f);矢量分量:OpenCL提供三种方式来访问矢量分量:数值索引、字母索引和hi/lo/even/odd方式。它们都是通过点(.)方式来访问分量。数值索引和字母索引对比使用如下所示:

实例代码
//实例代码
int8 data = (int8)(1, 2, 3, 4, 5, 6, 7, 8);
int4 a = data.s1234; // a = (2, 3, 4, 5)
int4 b = data.s3456; // b = (4, 5, 6, 7)需要注意对于数值索引和字母索引,两个不能混用。例如:
float4 f;
float4 A = f.xy34;
float4 B = f.s01yw;
//上述两种用法都是错误的,两种不同的索引不能混用hi/lo/even/odd:主要用来访问一半矢量分量,具体访问的分量如下:
| 矢量分量 | v.lo | v.hi | v.odd | v.even |
|---|---|---|---|---|
| float2 v | v.x,v.s0 | v.y,v.s1 | v.y,v.s1 | v.x,v.s0 |
| float3 v | v.s01,v.xy | v.s23,v.zw | v.s13,v.yw | v.s02,v.xz |
| float4 v | v.s01,v.xy | v.s23,v.zw | v.s13,v.yw | v.s02,v.xz |
| float8 v | v.s0123 | v.s4567 | v.s1357 | v.s0246 |
| float16 v | v.s01234567 | v.s89abcdef | v.s13579bdf | v.s02468ace |
实例代码
//实例代码
int8 data = (int8)(1, 2, 3, 4, 5, 6, 7, 8);
int4 a = data.hi; // a = (5, 6, 7, 8)
int4 b = data.lo; // b = (1, 2, 3, 4)
int4 c = data.even; // c = (2, 4, 6, 8)
int4 d = data.odd; // d = (1, 3, 5, 7)3.1.3 其他内置类型
例如一些图像处理相关的内置类型image1d_t、image2d_t、image3d_t以及sampler_t等其他内置类型,这些会在后面文章详细讲解。
3.2 矢量加载和存储
在数据类型这节详细说明了目前支持的标量数据类型和矢量数据类型,那么矢量数据的加载和存储也会有对应的矢量化函数,支持的类型分别有char/uchar、short/ushort、int/uint、long/ulong和float,fp16和double是可选项。
| 矢量加载/存储 | |
|---|---|
| Tn vloadn(size_t offset, const [constant] T *p) | 从地址p+(offset * n)读一个T类型矢量数据 |
| floatn vload_halfn(size_t offset, const [constant] half *p) | 从地址p+(offset * n)读一个half矢量数据 |
| void vstoren(Tn data, size_t offset, T *p) | 写T类型矢量数据到地址p+(offset * n) |
| void store_halfn(floatn data, size_t offset, half *p) | 写half矢量数据到地址p+(offset * n) |
- 矢量加载

矢量加载示意图
- 合并访问
合并访问是OpenCL和GPU并行计算的重要概念,基本就是底层硬件操作可以把多个工作项的数据load和store请求合并为一个请求,从而提升数据存储效率,如果不支持合并访问,GPU硬件必须为每个单独的请求执行数据load和store操作,从而导致性能下降。

合并访问示意图
上图所示,针对8个工作项如果kernel代码中使用vload4,从内存中加载8个数据合并访问为2次load操作。但是,如果是标量加载则需要加载8次load请求操作。因此,矢量加载相对于标量加载可以减少4倍load内存请求,提高kernel的内存带宽利用率。
具体示例代码如下:
//标量load/store 代码
__kernel void MatrixCopy(__global uchar *src,
__global uchar *dst,
int width, int height)
{
int g_idx = get_global_id(0);
int g_idy = get_global_id(1);
if ((g_idx >= width) || (g_idy >= height))
return;
dst[g_idy * height + g_idx] = src[g_idy * width + g_idx];
}
// 向量load/store代码:
__kernel void MatrixCopyVector(__global uchar *src,
__global uchar *dst,
int width, int height)
{
int g_idx = get_global_id(0) << 2;
int g_idy = get_global_id(1);
if ((g_idx >= width) || (g_idy >= height))
return;
int offset = mad24(g_idy, width, g_idx);
uchar4 v_ln0 = vload4(0, src + offset);
vstore4(v_ln0, 0, dst + offset);
}- 实测性能差异:在高通8450 Adreno GPUs上kernel的start->end执行时间如下图所示,向量化代码时间为1.17ms,标量代码时间为2.17ms,可以看出性能有接近1倍的提升。

合并访问性能对比图
3.3 修饰符
3.3.1 地址空间修饰符
OpenCL的存储器模型分别为:全局存储器、局部存储器、常量存储器和私有存储器,对应的地址空间修饰符为:__global(或global)、__local(或local)、__constant(或constant)和__private(或private)。
__global参数的数据将被放置在全局内存中。
__constant参数的数据将存储在全局只读内存中(有效)。
__local参数的数据将存储在本地内存中。
__private参数的数据将存储在私有内存中(默认)。
地址空间修饰符
OpenCL的存储器模型分别为:全局存储器、局部存储器、常量存储器和私有存储器,对应的地址空间修饰符为:__global(或global)、__local(或local)、__constant(或constant)和__private(或private)。
__global参数的数据将被放置在全局内存中。
__constant参数的数据将存储在全局只读内存中(有效)。
__local参数的数据将存储在本地内存中。
__private参数的数据将存储在私有内存中(默认)。3.3.2 函数修饰符
- kernel修饰符
__kernel(kernel)修饰符声明一个函数为内核函数,在OpenCL设备上执行。
//kernel修饰符
__kernel void MatrixMatrixAdd(__global float *mtx_a,
__global float *mtx_b,
__global float *mtx_c,
const int rows,
const int cols)
{
}
//或者
kernel void MatrixMatrixAdd(global float *mtx_a,
global float *mtx_b,
global float *mtx_c,
const int rows,
const int cols)
{
}- 内核可选属性修饰符
kernel修饰符可以和属性修饰符__attribute__结合使用,主要有三种组合方式。
//提示编译器内核正在处理数据类型的大小
__kernel __attribute__((vec_type_hint(typen)))
//提示编译器当前使用工作组的大小是多少
__kernel __attribute__((work_group_size_hint(16, 16, 1)))
// 指定必须使用的工作组大小,local_work_size的大小
__kernel __attribute__((reqd_work_group_size(16, 16, 1)))3.3.3 对象访问修饰符
访问修饰符用于指定图像类型的参数, 内核参数中的图像对象可以声明为只读、只写或者读写。
__read_only(或read_only)和__write_only(或write_only)来修饰图像对象参数。__read_write(或read_write)只能在内核中对又读又写的图像对象参数进行修饰。默认修饰符为read_only。
__kernel void add(__read_only image2d_t img_a,
__write_only image2d_t img_d)
{
......
}3.3.4 属性限定符
- 指定 enum、struct 和 union 类型的特殊属性
__attribute__((aligned(n))) __attribute__((endian(host)))
__attribute__((aligned)) __attribute__((endian(device)))
__attribute__((packed)) __attribute__((endian))- 指定变量或结构体的特殊属性
__attribute__((aligned(alignment)))
__attribute__((nosvm))- 指定可以展开循环(for、while 和 do )
__attribute__((OpenCL_unroll_hint(n)))
__attribute__((OpenCL_unroll_hint))3.4 运算符
OpenCL C运算符接受多个参数操作符中,对象可以标量和矢量数据类型,其中很多操作符还可以处理标量和矢量之间的混合运算。
OpenCL的运算符分类
| 运算符类型 | 运算符符号及描述 |
|---|---|
| 算术运算符 | 加(+)、减(-)、乘(*)、除(/)、取余(%) |
| 关系运算符 | 大于(>)、小于(<)、大于等于(>=)、小于等于(<=)、等于(==)、不等于(!=) |
| 位运算符 | 位与(&)、位或(|)、异或(^)、非(~)、右移(>>)、左移(<<) |
| 逻辑运算符 | 与(&&)、或(||) |
| 条件选择运算符 | 三目选择运算符(?:) |
| 一元运算符 | 正负(+\-)、自加(++)、自减(--)、类型长度(sizeof)、非(!)、逗号(,)、(&,*) |
| 赋值运算符 | =、*=、/=、+=、-=、<<=、>>=、&=、^=、|= |
算术运算符主要用于内置函数、浮点标量和矢量数据类型。对于算术运算符,如果操作数具有相同的类型,则结果将具有与操作数相同的类型。 如果运算涉及包含整数的向量和包含浮点值的向量,则生成的向量为浮点。 同样不能对浮点值或包含浮点值的向量使用位运算符。
//操作数为浮点数和整数类型,返回值为浮点类型
float a = 3.1415;
int b = 2;
float c = a * b;
// 操作数一个为矢量数据,另一个为标量数据,标量数据会被转换为矢量
int4 v_d = (int4)(1, 2, 3, 4);
int s_d = 3;
int4 v_sum = v_d * d;// (1, 2, 3, 4) * (3, 3,3,3) = (3, 6, 9, 12)运算符的多种使用方式
__kernel void op_sample(__global int4 *output)
{
// 向量元素加4
int4 vec = (int4)(1, 2, 3, 4);
vec += 4;
// 向量第三个元素和7比较
if(vec.s2 == 7)
vec &= (int4)(-1, -1, 0, -1);
//对向量vec中的第一个和第二个元素赋值
vec.s01 = vec.s23 < 7;
// vec的第三个元素移位处理
while(vec.s3 > 7 && (vec.s0 < 16 || (vec.s1 < 16))
vec.s3 >>= 1;
*output = vec;
}3.5 build-in 函数
build-in:内建函数通俗的理解就是OpenCL c标准中自带的内部函数,有点类似与C语言的math.h文件中的函数。
内置函数支持标量和向量类型参数,同时返回类型和实际类型保持一致。同时内置函数也会扩展 cl_khr_fp64和cl_khr_fp16 的支持,只需要使用时指定double和half类型就可以。
3.5.1 工作项函数
工作项作为内核执行的最小单元工需要遍历整个数据,主要是根据执行内核的所有其他工作项中的 ID。
维度和工作项
对于工作项的数目、ID及维度OpenCL内核提供了一下几个内置查询函数。如下表所示。
| uint get_work_dim() | 返回内核中使用的维度数 |
|---|---|
| size_t get_global_size(uint dimindx) | 返回dim指定维度上全局工作项数目 |
| size_t get_global_id(uint dimindx) | 返回dim指定维度上全局工作项id |
| size_t get_global_offset() | 返回dim指定维度上全局工作项id初始偏移量 |
为了能够明白上述函数的使用方法,我们以遍历一张56x56的灰度图像为例子展开说明:
//开发者使用外部API设置全局工作项和偏移量
const size_t global_size[2] = {56, 56};
const size_t offset[2] = {0, 10};
err = clEnqueueNDRangeKernel(cmdqueue, kernel, 2, offset,
global_size, NULL, 0, NULL, NULL);
// kernel 代码
__kernel void image_process(__global uchar *src,
__global uchar *dst,
int rows,
int cols)
{
int idx_x = get_global_id(0); // 获取值 0 ~ 56
int idx_y = get_global_id(1); // 获取值 10 ~ 66
int size_x = get_global_size(0); // 获取值 56
int size_y = get_global_size(1); // 获取值 56
int ofst_x = get_global_offset(0); // 值为 0
int ofst_y = get_global_offset(1); // 值为 10
int dim_size = get_work_dim; //当前设置工作组为2维, 值为 2
}工作组
当工作项需要同步它们的执行时,工作组变得很重要。工作组内的工作项可以共享局部存储器。
对于工作组的信息,OpenCL内核提供了一下几个内置查询函数。如下表所示:
| size_t get_num_groups(uint dim) | 返回dim指定维度上工作组数目 |
|---|---|
| size_t get_group_id(uint dim) | 返回dim指定维度上工作组id |
| size_t get_local_id(uint dim) | 返回工作组内dim指定维度上的工作项id |
| size_t get_local_size(uint dim) | 返回工作组内dim指定维度上的工作项数目 |
为了能够明白上述函数的使用方法,我们以遍历一张56x56的灰度图像为例子展开说明:
const int global_offset[2] = {3, 5};
const int global_size[2] = {6, 4};
const int local_size[2] = {3, 2};
err = clEnqueueNDRangeKernel(cmdqueue, kernel, 2, offset,
global_size, local_size, 0, NULL, NULL);
//kernel 代码
__kernel void group_sample(__global float *dst)
{
int gid_x = get_global_id(0);
int gid_y = get_global_id(1);
int gsize_x = get_global_size(0);
int ofst_x = get_global_offset(0);
int ofst_y = get_global_offset(1);
int lid_x = get_local_id(0);
int lid_y = get_local_id(1);
int idx_x = gid_x - ofst_x;
int idx_y = gid_y - ofst_y;
int index = idx_y * gsize_x + idx_x;
float f = gid_x * 10.0f + gid_y * 1.0f;
f += lid_x * 0.1f + lid_y * 0.01f;
dst[index] = f;
}
//输出结果
35.00 45.10 55.20 65.00 75.10 85.20
36.01 46.11 56.21 66.01 76.11 86.21
37.00 47.10 57.20 67.00 77.10 87.20
38.01 48.11 58.21 68.01 78.11 88.21上述样例详细说明了 clEnqueueNDRangeKernel 如何为工作项配置本地和全局 ID等信息,相信大家能有一个直观的认识。
3.5.2 浮点数学函数
OpenCL 的浮点函数分为五类:算术和舍入、比较、指数和对数、三角函数和杂项。
算术和舍入函数

针对舍入函数:rint 舍入到最接近的偶数, round 返回最接近的整数,如果两个最接近的整数同样接近,则返回距离 0 更远的整数。 针对算术函数的乘加函数:“mad 优势是速度优于准确性,fma 优势是精度更高。 样例示意:
__kernel void mod_round(__global float *mod_input,
__global float *mod_output,
__global float4 *round_input,
__global float4 *round_output)
{
mod_output[0] = fmod(mod_input[0], mod_input[1]);
mod_output[1] = remainder(mod_input[0], mod_input[1]);
round_output[0] = rint(*round_input);
round_output[1] = round(*round_input);
round_output[2] = ceil(*round_input);
round_output[3] = floor(*round_input);
round_output[4] = trunc(*round_input);
}
//输出结果
fmod(317.0, 23.0) = 18.0
remainder(317.0, 23.0) = -5.0
Rounding input: -6.5 -3.5 3.5 6.5
rint: -6.0, -4.0, 4.0, 6.0
round: -7.0, -4.0, 4.0, 7.0
ceil: -6.0, -3.0, 4.0, 7.0
floor: -7.0, -4.0, 3.0, 6.0
trunc: -6.0, -3.0, 3.0, 6.0比较函数

比较函数主要是一些简单向量比较过程,注意点一般在clamp和smoothstep函数的区别。
三角函数

OpenCL提供了更多的三角函数,可以帮助我们更好的实现某些算法优化。 样例示意:
__kernel void sin_cal(__global float4 *angle,
__global float4 *dst)
{
*dst = sin(*angle);
}
//结果
//输入
(30, 60, 90, 120)
//输出
(0.5, 0.866025, 1, 0.866025)类型转换
类型转换主要分为标量类型转换和向量类型转换及饱和四舍五入操作。
- 标量类型转换:主要是标量到标量的转换和标量到向量的转换操作
// 标量到标量转换
T a = (T)b;
// 标量到向量转换
Tn a = (Tn)(b);- 向量类型转换:主要是标量到标量的转换和标量到向量的转换操作
函数原型
destType convert_destType(srcType)
destType convert_destType<_sat><_rounding>(srcType)
destTypeN convert_destTypeN<_sat><_rounding>(srcTypeN)饱和处理:_sat是饱和溢出处理,例如int转uchar, 限幅在0-255之间;
四舍五入:浮点数转整数
_rte:向最近邻偶数舍入
_rtz:向最近邻零舍入
_rtp:向正无穷方向舍入
_rtn:向负无穷方向舍入
默认:convert默认舍入为rtz
float4 vin = (float4)(1.3, 2.6, 3.4, 5.6);
uchar4 vot = convert_uchar4_sat_rte(vin);
// 输出
1 2 3 63.5.3 整数数学函数
OpenCL 提供了广泛的整数运算,本节将它们分为三类:加减法、乘法和杂项。 在每种情况下,整数数据类型指的是所有有符号和无符号整数:uchar/char, ushort/short, uint/int, ulong/long。
加减法

加法计算中经常会出现两个整数相加时发生溢出,或者在减法中因为操作数的不同导致相减发生溢出。样例示意:
__kernel void inter_arithmetic(__global int *x,
__global int *y,
__global int *dst)
{
int add0 = add_sat(x, y);
int sub0 = sub_sat(x, y);
int add_sum = *x + *y;
int sub_sum = *x - *y;
*dst = add0 - sub0;
}
//输入
x = 1,968,526,677 y = 1,914,839,586
//输出
add_sum = –411,601,033 (0xE7777777)
add0 = 2,147,483,647 (0x7FFFFFFF) //饱和
sub_sum = –393,705,336 (0xE8888888)
sub0 = 2,147,483,647 (0x7FFFFFFF) //饱和乘法

示例代码
__kernel void inter_mul(__global uint *dst)
{
int x = 0x71111111, y = 0x72222222;
uint a = 0x123456;
uint b = 0x112233;
uint c = 0x111111;
dst[0] = mul_hi(x, y);
dst[1] = mad24(a, b, c);
dst[2] = mad_hi(a, b, c);
}
//输出
dst[0] = 0x3268ACF1;
dst[1] = ;
dst[2] = ;其它整数函数
整数类型的一个最值、绝对值、限幅等函数的说明和使用。

示例代码
__kernel void inter_opera(__global uint *dst)
{
uchar a = 252;
uchar b = 0x95;
uchar c = 0x31;
dst[0] = rotate(a, 3);
dst[1] = upsample(b, c);
}
//输出
dst[0] = 224;
dst[1] = 0x9531;3.6 shuffle 和 select 函数
shuffle 函数:
在OpenCL中,经常会碰到会对向量的多个分量进行交叉运算的情况,针对运算对象并不是相邻,存在交叉的情况,效率可能并不会很好,使用shuffle性能可能会提升10%以上。
OpenCL 的 shuffle 函数接受一个或两个输入向量并创建一个包含输入分量的输出向量。
- 示例函数:
allm shuffle(alln x, uintegerm mask); - 作用:按照 mask 规定的顺序创建一个包含 x 的分量的向量
- 伪代码
for( i = 0; i < n; i += 1)
{
dst[i] = src[mask[i]];
}- 示例结果

shuffle 示意图
- 相关函数:
allm shuffle2(alln x, alln y, uintegerm mask);

shuffle2 示意图
- 示例代码
const int mask = (uint4)(1, 2, 0, 1);
float4 d4;
float4 res = shuffle(d4, mask);select 函数:
为了保证kernel代码的流水线顺序,避免分支跳转,需要把if、条件运算符可能引起分支跳转的语句使用select内置函数优化掉,进而提升内核运行效率。
OpenCL 的 select 函数从两个输入的内容创建一个输出向量。
- 示例函数:
alln select(alln a, alln b, u/integern mask) - 作用:根据mask中的最高有效位从 a 和 b 中选择分量输出。
- 伪代码
//三目条件判断
for( i = 0; i < n; i += 1)
{
dst[i] = mask[i] ? src0[i] : src1[i];
}
//使用select
for( i = 0; i < n; i += 8)
{
int8 vmask = vload8(0, mask[i]);
int8 v0 = vload8(0, src0[i]);
int8 v1 = vload8(0, src1[i]);
int8 vres = select(v0, v1, vmask);
vstore8(vres, 0, dst[i]);
}- 示例结果

select 示意图
- 相关函数:
alln bitselect(alln a, alln b, u/integern mask)

bitselect 示意图
更多的内置函数本文目前不讲解说明了,后面会有专门的文章进行说明。
3.7 native 函数
GPU设备会有内置硬件模块基本单元(EFU),专门用来加速一些基础的数学函数,这些函数可能有EFU独立支持,也可能由EFU和ALU结合产生,以达到高性能计算函数。
- 带有native_前缀
- 相比常规函数性能更好,精度更低
native函数
native_cos, native_divide, native_exp, native_exp2, native_exp10, native_log,
native_log2, native_log10, native_powr, native_recip, native_rsqrt, native_sin,
native_sqrt, native_tannative和build-in函数比较
| 数学函数 | 定义 | 如何使用 | 精度 | 性能 |
|---|---|---|---|---|
| fast | 低精度函数 | -cl-fast-relaxed-math 编译选项 | 中 | 中 |
| native | 硬件直接计算 | native_function | 低 | 高 |
四、OpenCL 高斯滤波 kernel 实例
4.1 代码展示
以 8 位灰度图像高斯滤波为例编写 CPU C 代码和 OpenCL 的kernel内核代码。CPU的C代码采用行列分离的方式进行计算,边界方式使用反射101的方式。具体代码如下所示。
int Gaussian3x3Sigma0U8C1(uint8_t *src, int width, int height, int istride,
uint8_t *dst, int ostride)
{
if ((NULL == src) || (NULL == dst))
{
printf("input param invalid!\n");
return -1;
}
for (int row = 0; row < height; row++)
{
// 上边界和下边界索引更新
int last = (row == 0) ? 1 : -1;
int next = (row == height - 1) ? -1 : 1;
// 三行数据指针索引
uint8_t *src0 = src + (row + last) * istride;
uint8_t *src1 = src + row * istride;
uint8_t *src2 = src + (row + next) * istride;
uint8_t *p_dst = dst + row * ostride;
for (int col = 0; col < width; col++)
{
// 左右边界的下标索引更新
int left = (col == 0) ? 1 : ((col == width - 1)? width - 2 : col - 1);
int right = (col == 0) ? 1 : ((col == width - 1)? width - 2 : col + 1);
uint16_t acc = 0;
// 利用行列分离和kernel对称性思想,先计算水平和 然后求垂直和
acc += src0[left] + src0[right] + src0[col] * 2;
acc += (src1[left] + src1[right]) * 2 + src1[col] * 4;
acc += src2[left] + src2[right] + src2[col] * 2;
// 归一化饱和操作
p_dst[col] = ((acc + (1 << 3)) >> 4) & 0xFF;
}
}
return 0;
}OpenCL kernel内核代码采用buffer的方式进行读写操作,每个工作项处理4个元素,利用向量化方式处理可以多个工作项并行运算。如果读采用image2d_t的方式,性能会更好,以后会介绍。
__kernel void Gauss3x3u8c1Buffer(__global uchar *src, int row, int col,
int src_pitch, int dst_pitch,
__global uchar *dst)
{
// 工作组下标索引,<< 2 代表矢量化操作,一次输出4个元素值
int x = get_global_id(0) << 2;
int y = get_global_id(1);
// 越界检测,防止多读和多写
if ( x >= col || y >= row)
{
return;
}
// kernel 行地址下标索引 r1为中间行
int r1_index = mad24(y, src_pitch, x);
// r0 表示上一行地址下标索引
int r0_index = select(mad24(y - 1, src_pitch, x), mad24(y + 1, src_pitch, x), ((y - 1) < 0));
// r2 表示下一行地址下标索引
int r2_index = select(r1_index - src_pitch, r1_index + src_pitch, ((y + 1) < row));
// 矢量化加载,每次load行方向的8个元素
int8 r0 = convert_int8(vload8(0, src + r0_index));
int8 r1 = convert_int8(vload8(0, src + r1_index));
int8 r2 = convert_int8(vload8(0, src + r2_index));
// 垂直方向求和
int8 vert_sum = (r0 + r2) + (r1 << (int8)(1));
// 构造水平方向矢量
int4 v_hori_s0 = vert_sum.lo;
int4 v_hori_s1 = (int4)(vert_sum.s1234);
int4 v_hori_s2 = (int4)(vert_sum.s2345);
// 水平方向求和 然后归一化操作
int4 v_res = (v_hori_s0 + v_hori_s2 + (v_hori_s1 << (int4)(1)) + (int4)(1 << 3)) >> (int4)(4);
// int 转换为 uchar 类型,并做饱和操作
uchar4 v_dst = convert_uchar4_sat(v_res);
// 计算目的地址的行地址下标索引
int dst_index = mad24(y, dst_pitch, x + 1);
// 写入到目的地址中
vstore4(v_dst, 0, dst + dst_index);
}4.2 结果展示
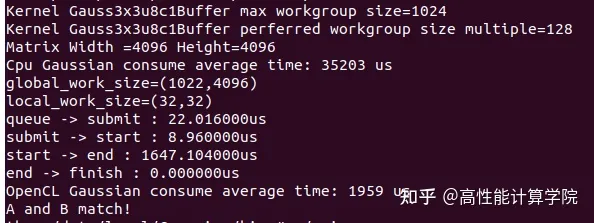
完整的实现代码可以下载我们的github仓库运行。 下图是我们在高通骁龙8450平台上的运行结果,可以看到使用OpenCL优化之后运行时间从35.203ms(图像尺寸4096x4096)下降到了1.96ms,性能有了17倍多的提升, 感兴趣的读者可以自己运行下结果。
Gaussian 性能对比
五、工程代码
https://github.com/mobile-algorithm-optimization/guidegithub.com/mobile-algorithm-optimization/guide/tree/main/OpenCLGaussian
六、参考资料
[1]《OpenCL IN ACTION》
[2]《OpenCL 2.0 Reference Card》
[3]《OpenCL 异构并行计算》
[4] https://www.khronos.org/OpenCL/
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!