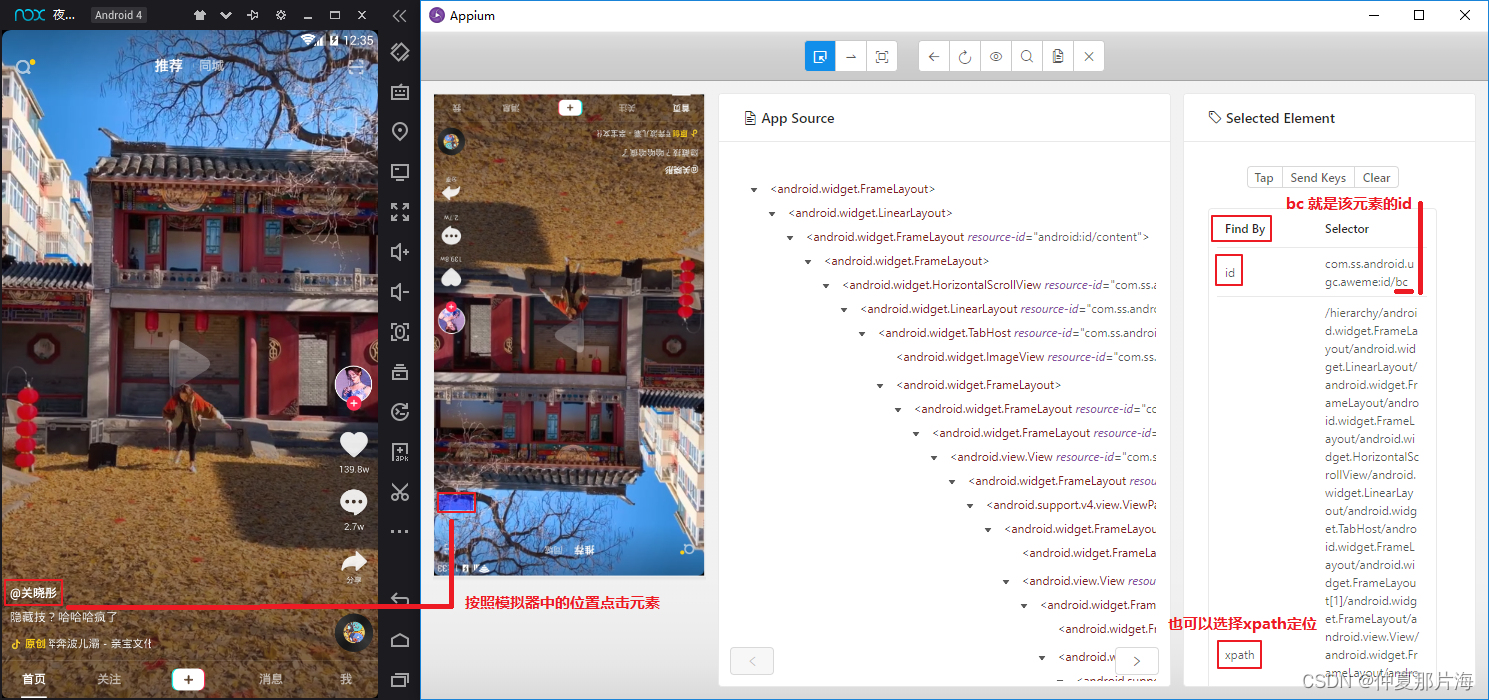
一、【写在前面】
PY是一个调包侠语言,多学一个库可以提高计算速度。Collections提供了各种数据类型和集合工具,可以很方便的处理各种数据结构。如果您有刷力扣的习惯,可以经常看到Collections和itertools的身影,经常用这两个可以做到一行解题,之前笔者介绍过了Itertools,这篇文章介绍一下Collection。
官网:collections — Container datatypes — Python 3.12.1 documentation
itertools博客:python强大的排列组合库-itertools-CSDN博客
二、【正式介绍】
这个Collections库官网文档就9个方法,一篇博客就能介绍完。
1. namedtuple:
namedtuple 用于创建带有字段名称的元组,使得元组的每个字段都有一个易于理解的名称。它通常用于表示记录型的数据。以下是示例:
from collections import namedtuple
# 创建一个名为 'Person' 的命名元组,包含 'name' 和 'age' 两个字段
Person = namedtuple('Person', ['name', 'age'])
# 创建一个 Person 对象
person = Person(name='Alice', age=30)
# 访问字段 print(person.name) # 输出 'Alice'
print(person.age) # 输出 302. deque:
deque 是双端队列,支持高效地在两端进行添加和删除操作。它适用于需要快速操作队列和栈的场景。以下是示例:
from collections import deque
# 创建一个空的双端队列
dq = deque()
# 在队列的右端添加元素
dq.append(1) dq.append(2)
# 在队列的左端添加元素
dq.appendleft(0)
# 弹出右端的元素
print(dq.pop())
# 输出 2
# 弹出左端的元素
print(dq.popleft())
# 输出 03. Counter:
Counter 用于统计可迭代对象中元素的出现次数。它返回一个字典,其中键是元素,值是元素出现的次数。以下是示例:
from collections import Counter
# 统计字符串中字符的出现次数
text = "hello world"
char_count = Counter(text)
# 获取字符 'l' 的出现次数
print(char_count['l']) # 输出 34. OrderedDict:
OrderedDict 是有序字典,记住了元素的插入顺序。与普通字典不同,OrderedDict 在迭代时会按照元素的插入顺序返回。以下是示例:
from collections import OrderedDict
# 创建一个有序字典
ordered_dict = OrderedDict()
# 添加键值对
ordered_dict['a'] = 1 ordered_dict['b'] = 2
# 迭代时按照插入顺序返回键值对
for key, value in ordered_dict.items():
print(key, value)
# 输出: # a 1 # b 25. defaultdict:
defaultdict 是字典的子类,允许为字典中的每个键设置默认值。这样,在访问不存在的键时,不会引发 KeyError。以下是示例:
from collections import defaultdict
# 创建一个默认值为 0 的
defaultdict num_dict = defaultdict(int)
# 添加键值对
num_dict['a'] = 1
# 访问不存在的键,默认值为 0
print(num_dict['b'])
# 输出 06. ChainMap:
ChainMap 允许将多个字典链接在一起,形成一个逻辑上的单一字典。这对于组合多个配置或选项字典非常有用。以下是示例:
from collections import ChainMap
# 创建两个字典
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}
# 创建 ChainMap 将两个字典链接在一起
combined_dict = ChainMap(dict1, dict2)
# 访问键 'b',将返回第一个字典中的值
print(combined_dict['b'])
# 输出 27. UserDict:
7、8、9这三个方法都带一个User,本质是一个可以自己定义方法的Class,对self.data直接操作即可。
UserDict 是用于自定义字典行为的包装器类。它继承自内置的 dict 类,并允许您重写字典的方法以实现自定义行为。通常,UserDict 用于创建自定义的字典类型,以添加特定的方法或修改字典的行为。
示例用法:
from collections import UserDict
class MyDict(UserDict):
def get_keys(self):
return list(self.data.keys())
my_dict = MyDict({'a': 1, 'b': 2})
keys = my_dict.get_keys()
print(keys) # 输出 ['a', 'b']8. UserList:
UserList 用于自定义列表行为的包装器类。它继承自内置的 list 类,并允许您重写列表的方法以实现自定义行为。通常,UserList 用于创建自定义的列表类型,以添加特定的方法或修改列表的行为。
示例用法:
from collections import UserList
class MyList(UserList):
def append_twice(self, value):
self.data.append(value)
self.data.append(value)
my_list = MyList([1, 2, 3])
my_list.append_twice(4)
print(my_list) # 输出 [1, 2, 3, 4, 4]9. UserString:
UserString 用于自定义字符串行为的包装器类。它继承自内置的 str 类,并允许您重写字符串的方法以实现自定义行为。通常,UserString 用于创建自定义的字符串类型,以添加特定的方法或修改字符串的行为。
示例用法:
from collections import UserString
class MyString(UserString):
def reverse(self):
return self.data[::-1]
my_string = MyString("hello")
reversed_str = my_string.reverse()
print(reversed_str) # 输出 'olleh'



![[足式机器人]Part2 Dr. CAN学习笔记- 最优控制Optimal Control Ch07-1最优控制问题与性能指标](https://img-blog.csdnimg.cn/direct/795a53af3e9143c7b8b4dc4861f83c39.png#pic_center)