目录
跳表介绍
跳表的特点:
跳表的应用场景:
C++ 代码示例:
跳表的特性
跳表示例
总结
跳表(Skip List)是一种支持快速搜索、插入和删除的数据结构,具有相对简单的实现和较高的查询性能。下面是跳表的详细介绍和一个简单的 C++ 代码示例:
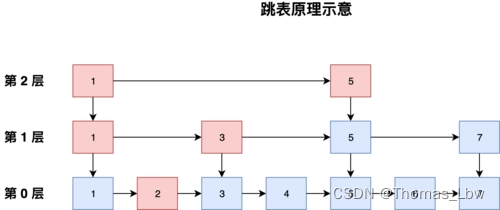
跳表介绍
跳表的特点:
- 有序结构: 跳表中的每个节点都包含一个元素,并且节点按照元素的大小有序排列。
- 多层索引: 跳表通过维护多层索引来实现快速搜索。每一层都是一个有序链表,最底层包含所有元素,而每上一层的节点是下一层节点的一部分。
- 跳跃式访问: 通过索引层,跳表允许在较高层直接跳过一些节点,从而提高搜索效率。
跳表的应用场景:
- 有序集合的实现: 用于需要频繁的插入、删除和搜索操作的有序数据集合,如 Redis 中的有序集合(Sorted Set)。
- 替代平衡树: 在某些场景下,跳表可以作为对平衡树的一种替代,具有更简单的实现和较好的性能。
C++ 代码示例:
#include <iostream>
#include <vector>
#include <cstdlib>
const int MAX_LEVEL = 16; // 最大层数
// 跳表节点定义
struct Node {
int value;
std::vector<Node*> forward; // 每层的指针数组
Node(int val, int level) : value(val), forward(level, nullptr) {}
};
// 跳表定义
class SkipList {
private:
Node* header; // 头节点
int level; // 当前跳表的最大层数
public:
SkipList() : level(1) {
header = new Node(0, MAX_LEVEL);
}
// 随机生成一个层数
int randomLevel() {
int lvl = 1;
while ((rand() % 2) && (lvl < MAX_LEVEL))
lvl++;
return lvl;
}
// 插入一个元素
void insert(int val) {
std::vector<Node*> update(MAX_LEVEL, nullptr);
Node* current = header;
// 从最高层到底层,找到每一层的插入位置
for (int i = level - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->value < val) {
current = current->forward[i];
}
update[i] = current;
}
// 随机生成一个层数
int newLevel = randomLevel();
// 如果新的层数比当前层数高,则更新 update
if (newLevel > level) {
for (int i = level; i < newLevel; i++) {
update[i] = header;
}
level = newLevel;
}
// 创建新节点
Node* newNode = new Node(val, newLevel);
// 更新每一层的指针
for (int i = 0; i < newLevel; i++) {
newNode->forward[i] = update[i]->forward[i];
update[i]->forward[i] = newNode;
}
}
// 搜索一个元素,返回是否存在
bool search(int val) {
Node* current = header;
// 从最高层到底层,搜索每一层的节点
for (int i = level - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->value < val) {
current = current->forward[i];
}
}
// 到达底层,判断是否找到目标元素
if (current->forward[0] != nullptr && current->forward[0]->value == val) {
return true;
} else {
return false;
}
}
// 删除一个元素
void remove(int val) {
std::vector<Node*> update(MAX_LEVEL, nullptr);
Node* current = header;
// 从最高层到底层,找到每一层的删除位置
for (int i = level - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->value < val) {
current = current->forward[i];
}
update[i] = current;
}
// 到达底层,判断是否找到目标元素
if (current->forward[0] != nullptr && current->forward[0]->value == val) {
// 更新每一层的指针,删除目标节点
for (int i = 0; i < level; i++) {
if (update[i]->forward[i] != current->forward[i]) {
break;
}
update[i]->forward[i] = current->forward[i]->forward[i];
}
// 如果删除的是最高层的节点,更新层数
while (level > 1 && header->forward[level - 1] == nullptr) {
level--;
}
// 释放节点内存
delete current;
}
}
// 打印跳表
void printSkipList() {
for (int i = level - 1; i >= 0; i--) {
Node* current = header->forward[i];
std::cout << "Level " << i << ": ";
while (current != nullptr) {
std::cout << current->value << " ";
current = current->forward[i];
}
std::cout << std::endl;
}
std::cout << "-----------------------" << std::endl;
}
};
int main() {
// 创建跳表
SkipList skipList;
// 插入一些元素
skipList.insert(3);
skipList.insert(6);
skipList.insert(7);
skipList.insert(9);
skipList.insert(12);
// 打印跳表
skipList.printSkipList();
// 搜索元素
int searchValue = 7;
if (skipList.search(searchValue)) {
std::cout << "Element " << searchValue << " found in the skip list." << std::endl;
} else {
std::cout << "Element " << searchValue << " not found in the skip list." << std::endl;
}
// 删除元素
int removeValue = 6;
skipList.remove(removeValue);
// 打印删除后的跳表
skipList.printSkipList();
return 0;
}
这是一个简单的跳表实现,包括插入、搜索和删除操作。在实际应用中,跳表的层数、随机层数的方式以及其他细节可以根据具体需求进行调整。
跳表的特性
-
有序性: 跳表中的每个节点按照元素的大小有序排列。这使得在跳表中可以快速定位和搜索元素。
-
多层索引: 跳表通过维护多层索引来实现快速搜索。每一层都是一个有序链表,最底层包含所有元素,而每一层的节点是下一层节点的子集。这样的多层索引结构可以提高搜索效率。
-
跳跃式访问: 通过多层索引,跳表允许在较高层直接跳过一些节点,从而实现跳跃式的访问。这种设计类似于在二分查找中直接跳过一半的元素,从而提高了搜索的效率。
-
平衡性: 跳表的设计通过随机层数和灵活的插入策略,保持了跳表的平衡性。这有助于避免类似于二叉搜索树中的不平衡情况,使得操作的时间复杂度更加可控。
-
简单实现: 跳表相对于其他高效的数据结构,如平衡树,实现相对简单。它不需要像平衡树那样复杂的平衡维护,使得代码的实现和维护相对容易。
-
支持动态操作: 跳表天生适合动态操作,包括插入和删除。由于插入和删除操作只需要调整相邻节点的指针,而不需要进行全局的平衡调整,因此操作的效率较高。
-
适应范围广: 跳表可以应用于各种有序数据集合的场景,特别是在需要频繁插入、删除和搜索操作的场景中,其性能表现优异。
跳表的这些特性使得它在一些应用场景中具有明显的优势,尤其在无法提前知道数据分布情况的情形下,跳表能够以较简单的方式维护有序性和高效操作。
跳表示例
下面是一个使用 C++ 实现的跳表例子,包含插入、搜索、删除和打印操作。在这个例子中,我使用了模板类以支持不同类型的元素。
#include <iostream>
#include <vector>
#include <cstdlib>
// 跳表节点定义
template <typename T>
struct Node {
T value;
std::vector<Node*> forward;
Node(T val, int level) : value(val), forward(level, nullptr) {}
};
// 跳表定义
template <typename T>
class SkipList {
private:
Node<T>* header;
int level;
public:
SkipList() : level(1) {
header = new Node<T>(T(), MAX_LEVEL); // 初始值为 T() 的头节点
}
// 随机生成一个层数
int randomLevel() {
int lvl = 1;
while ((rand() % 2) && (lvl < MAX_LEVEL))
lvl++;
return lvl;
}
// 插入一个元素
void insert(const T& val) {
std::vector<Node<T>*> update(MAX_LEVEL, nullptr);
Node<T>* current = header;
// 从最高层到底层,找到每一层的插入位置
for (int i = level - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->value < val) {
current = current->forward[i];
}
update[i] = current;
}
// 随机生成一个层数
int newLevel = randomLevel();
// 如果新的层数比当前层数高,则更新 update
if (newLevel > level) {
for (int i = level; i < newLevel; i++) {
update[i] = header;
}
level = newLevel;
}
// 创建新节点
Node<T>* newNode = new Node<T>(val, newLevel);
// 更新每一层的指针
for (int i = 0; i < newLevel; i++) {
newNode->forward[i] = update[i]->forward[i];
update[i]->forward[i] = newNode;
}
}
// 搜索一个元素,返回是否存在
bool search(const T& val) const {
Node<T>* current = header;
// 从最高层到底层,搜索每一层的节点
for (int i = level - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->value < val) {
current = current->forward[i];
}
}
// 到达底层,判断是否找到目标元素
return (current->forward[0] != nullptr && current->forward[0]->value == val);
}
// 删除一个元素
void remove(const T& val) {
std::vector<Node<T>*> update(MAX_LEVEL, nullptr);
Node<T>* current = header;
// 从最高层到底层,找到每一层的删除位置
for (int i = level - 1; i >= 0; i--) {
while (current->forward[i] != nullptr && current->forward[i]->value < val) {
current = current->forward[i];
}
update[i] = current;
}
// 到达底层,判断是否找到目标元素
if (current->forward[0] != nullptr && current->forward[0]->value == val) {
// 更新每一层的指针,删除目标节点
for (int i = 0; i < level; i++) {
if (update[i]->forward[i] != current->forward[i]) {
break;
}
update[i]->forward[i] = current->forward[i]->forward[i];
}
// 如果删除的是最高层的节点,更新层数
while (level > 1 && header->forward[level - 1] == nullptr) {
level--;
}
// 释放节点内存
delete current;
}
}
// 打印跳表
void printSkipList() const {
for (int i = level - 1; i >= 0; i--) {
Node<T>* current = header->forward[i];
std::cout << "Level " << i << ": ";
while (current != nullptr) {
std::cout << current->value << " ";
current = current->forward[i];
}
std::cout << std::endl;
}
std::cout << "-----------------------" << std::endl;
}
};
int main() {
// 创建跳表
SkipList<int> skipList;
// 插入一些元素
skipList.insert(3);
skipList.insert(6);
skipList.insert(7);
skipList.insert(9);
skipList.insert(12);
// 打印跳表
skipList.printSkipList();
// 搜索元素
int searchValue = 7;
if (skipList.search(searchValue)) {
std::cout << "Element " << searchValue << " found in the skip list." << std::endl;
} else {
std::cout << "Element " << searchValue << " not found in the skip list." << std::endl;
}
// 删除元素
int removeValue = 6;
skipList.remove(removeValue);
// 打印删除后的跳表
skipList.printSkipList();
return 0;
}
在这个例子中,使用跳表有几个考虑因素:
-
高效的搜索操作: 跳表的搜索操作时间复杂度为 O(log n),其中 n 是跳表中的元素个数。相较于普通链表的线性搜索,跳表提供了更快的搜索速度。
-
支持动态操作: 跳表天生适合动态操作,包括插入和删除。由于插入和删除操作只需要调整相邻节点的指针,而不需要进行全局的平衡调整,因此在元素的动态更新场景下,跳表相对于其他数据结构更具有优势。
-
简单实现: 跳表的实现相对简单,不需要像平衡树那样复杂的平衡维护。这使得它在实际应用中更容易实现和维护。
-
对比其他数据结构: 在这个示例中,使用跳表的主要目的是演示跳表的基本原理和操作,并不代表它是绝对优于其他数据结构的选择。具体选择数据结构的决策取决于实际应用场景、数据分布情况以及对不同操作的需求。
总结
特性:
- 有序性: 跳表中的每个节点按照元素的大小有序排列,使得在跳表中可以快速定位和搜索元素。
- 多层索引: 跳表通过维护多层索引来实现快速搜索,每一层都是一个有序链表,最底层包含所有元素。
- 跳跃式访问: 通过多层索引,跳表允许在较高层直接跳过一些节点,实现跳跃式的访问,提高搜索效率。
- 平衡性: 通过随机层数和灵活的插入策略,保持了跳表的平衡性,避免了类似于二叉搜索树中的不平衡情况。
- 支持动态操作: 跳表天生适合动态操作,包括插入和删除,操作的时间复杂度较低。
应用场景:
- 有序集合的实现: 适用于需要频繁插入、删除和搜索操作的有序数据集合,例如在 Redis 中的有序集合(Sorted Set)实现中使用了跳表。
- 替代平衡树: 在某些场景下,跳表可以作为对平衡树的一种替代,相对简单的实现和较好的性能表现使得它成为一种备选选择。
- 动态数据库索引: 在数据库中,跳表可以用作动态索引结构,适用于动态更新和频繁搜索的情况。
- 高效的动态排序: 在需要频繁的动态排序操作的场景下,跳表的性能可能优于传统的排序算法。
总体评价:
- 优势: 跳表提供了一种在有序数据集合中实现高效的动态操作的方式,相较于平衡树结构实现较为简单,适用于需要频繁更新和搜索的场景。
- 劣势: 跳表相对于其他数据结构可能占用更多内存,对于某些内存敏感的场景,可能不是最优选择。在一些特定的搜索密集型场景中,红黑树等平衡树结构也具有竞争力。
总体而言,跳表在一些动态、搜索密集的应用场景中表现出色,但在具体选择时,需要综合考虑数据分布、内存使用、实现难度等因素。