项目地址:文本情感分析 - 飞桨AI Studio星河社区 (baidu.com)
baidu/Senta: Baidu's open-source Sentiment Analysis System. (github.com)
本项目将详细全面介绍情感分析任务的两种子任务,句子级情感分析和目标级情感分析。
同时演示如何使用情感分析预训练模型SKEP完成以上两种任务,详细介绍预训练模型SKEP及其在 PaddleNLP 的使用方式。
本项目主要包括“任务介绍”、“情感分析预训练模型SKEP”、“句子级情感分析”、“目标级情感分析”等四个部分。
!pip install --upgrade paddlenlp -i https://pypi.org/simple 1、情感分析任务
众所周知,人类自然语言中包含了丰富的情感色彩:表达人的情绪(如悲伤、快乐)、表达人的心情(如倦怠、忧郁)、表达人的喜好(如喜欢、讨厌)、表达人的个性特征和表达人的立场等等。情感分析在商品喜好、消费决策、舆情分析等场景中均有应用。利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。
被人们所熟知的情感分析任务是将一段文本分类,如分为情感极性为正向、负向、其他的三分类问题:

- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
- 其他: 其他类型的情感。
实际上,以上熟悉的情感分析任务是句子级情感分析任务。
情感分析任务还可以进一步分为句子级情感分析、目标级情感分析等任务。在下面章节将会详细介绍两种任务及其应用场景。
2、情感分析预训练模型SKEP
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
情感预训练模型SKEP(Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis)。SKEP利用情感知识增强预训练模型, 在14项中英情感分析典型任务上全面超越SOTA,此工作已经被ACL 2020录用。SKEP是百度研究团队提出的基于情感知识增强的情感预训练算法,此算法采用无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义。SKEP为各类情感分析任务提供统一且强大的情感语义表示。
论文地址:[2005.05635] SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis (arxiv.org)
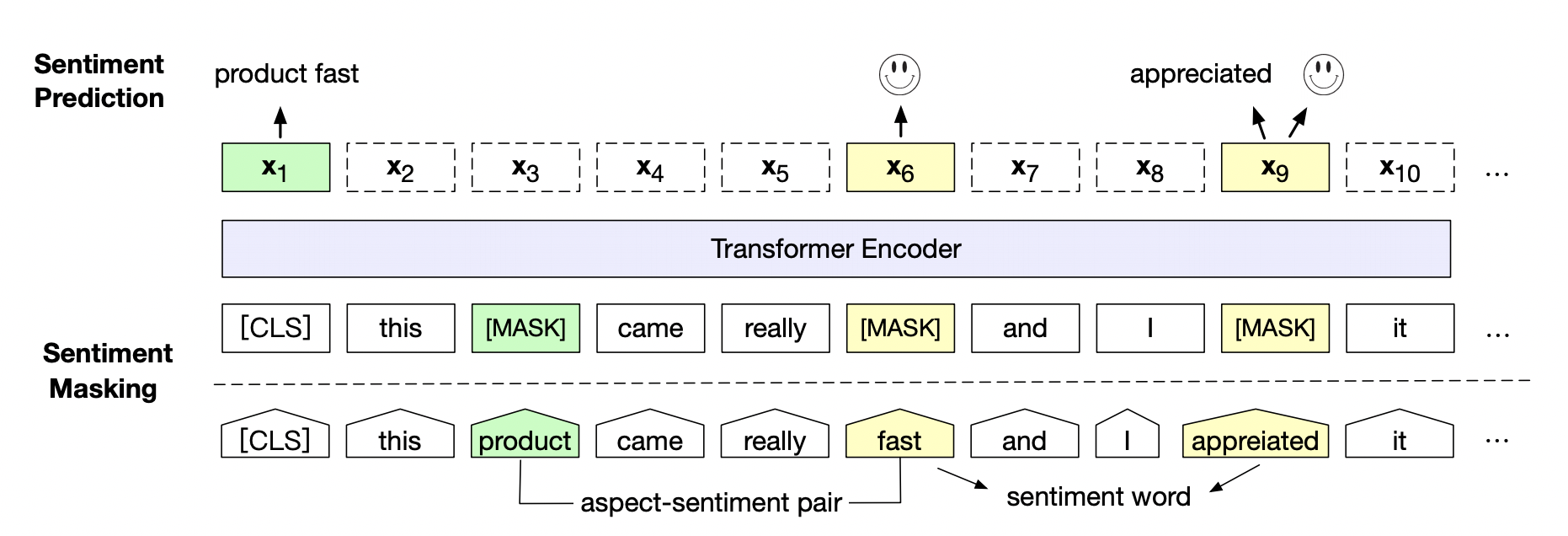
百度研究团队在三个典型情感分析任务,句子级情感分类(Sentence-level Sentiment Classification),评价目标级情感分类(Aspect-level Sentiment Classification)、观点抽取(Opinion Role Labeling),共计14个中英文数据上进一步验证了情感预训练模型SKEP的效果。
具体实验效果参考:baidu/Senta: Baidu's open-source Sentiment Analysis System. (github.com)
3、句子级情感分析 & 目标级情感分析
3.1 句子级情感分析
对给定的一段文本进行情感极性分类,常用于影评分析、网络论坛舆情分析等场景。如:
选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般 1
15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错 1
房间太小。其他的都一般... ... ... ... 0
其中1表示正向情感,0表示负向情感。

句子级情感分析任务
3.1.1 常用数据集
ChnSenticorp数据集是公开中文情感分析常用数据集, 其为2分类数据集。PaddleNLP已经内置该数据集,一键即可加载。
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
print(train_ds[0])
print(train_ds[1])
print(train_ds[2]){'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': 1, 'qid': ''}
{'text': '15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错', 'label': 1, 'qid': ''}
{'text': '房间太小。其他的都一般。。。。。。。。。', 'label': 0, 'qid': ''}
3.1.2 SKEP模型加载
PaddleNLP已经实现了SKEP预训练模型,可以通过一行代码实现SKEP加载。
句子级情感分析模型是SKEP fine-tune 文本分类常用模型SkepForSequenceClassification。其首先通过SKEP提取句子语义特征,之后将语义特征进行分类。
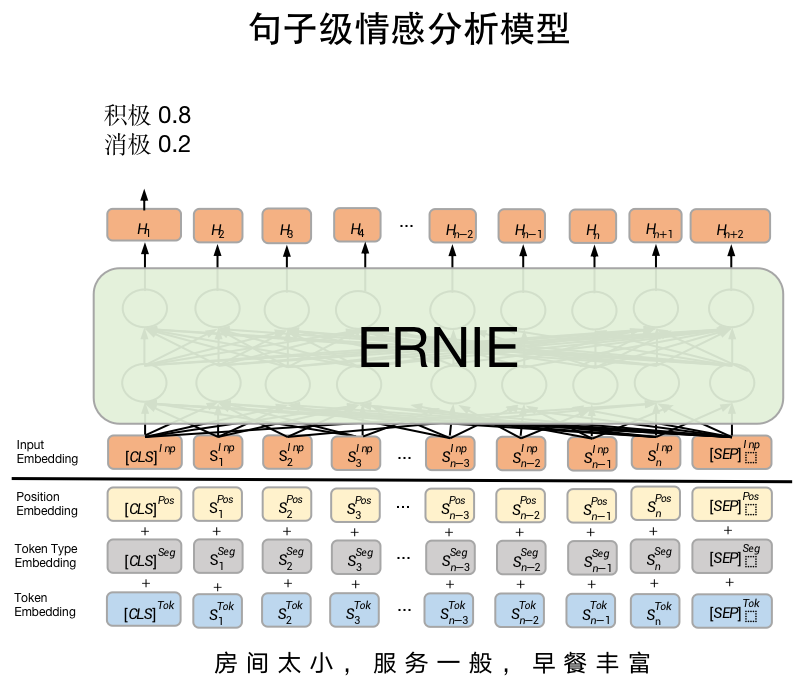
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer
# 指定模型名称,一键加载模型
model = SkepForSequenceClassification.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch", num_classes=len(train_ds.label_list))
# 同样地,通过指定模型名称一键加载对应的Tokenizer,用于处理文本数据,如切分token,转token_id等。
tokenizer = SkepTokenizer.from_pretrained(pretrained_model_name_or_path="skep_ernie_1.0_large_ch")kepForSequenceClassification可用于句子级情感分析和目标级情感分析任务。其通过预训练模型SKEP获取输入文本的表示,之后将文本表示进行分类。
-
pretrained_model_name_or_path:模型名称。支持"skep_ernie_1.0_large_ch",“skep_ernie_2.0_large_en”。- “skep_ernie_1.0_large_ch”:是SKEP模型在预训练ernie_1.0_large_ch基础之上在海量中文数据上继续预训练得到的中文预训练模型;
- “skep_ernie_2.0_large_en”:是SKEP模型在预训练ernie_2.0_large_en基础之上在海量英文数据上继续预训练得到的英文预训练模型;
-
num_classes: 数据集分类类别数。
关于SKEP模型实现详细信息参考:PaddleNLP/paddlenlp/transformers/skep at develop · PaddlePaddle/PaddleNLP (github.com)
3.1.3 数据处理
同样地,我们需要将原始ChnSentiCorp数据处理成模型可以读入的数据格式。
SKEP模型对中文文本处理按照字粒度进行处理,我们可以使用PaddleNLP内置的SkepTokenizer完成一键式处理。
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
from utils import create_dataloader
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence has the following format:
::
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
max_seq_len(obj:`int`): The maximum total input sequence length after tokenization.
Sequences longer than this will be truncated, sequences shorter will be padded.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
Returns:
input_ids(obj:`list[int]`): The list of token ids.
token_type_ids(obj: `list[int]`): List of sequence pair mask.
label(obj:`int`, optional): The input label if not is_test.
"""
# 将原数据处理成model可读入的格式,enocded_inputs是一个dict,包含input_ids、token_type_ids等字段
encoded_inputs = tokenizer(
text=example["text"], max_seq_len=max_seq_length)
# input_ids:对文本切分token后,在词汇表中对应的token id
input_ids = encoded_inputs["input_ids"]
# token_type_ids:当前token属于句子1还是句子2,即上述图中表达的segment ids
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
# label:情感极性类别
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
# qid:每条数据的编号
qid = np.array([example["qid"]], dtype="int64")
return input_ids, token_type_ids, qid# 批量数据大小
batch_size = 32
# 文本序列最大长度
max_seq_length = 128
# 将数据处理成模型可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack() # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)3.1.4 模型训练和评估
定义损失函数、优化器以及评价指标后,即可开始训练。
推荐超参设置:
max_seq_length=256batch_size=48learning_rate=2e-5epochs=10
实际运行时可以根据显存大小调整batch_size和max_seq_length大小。
utils.py文件如下(放在项目同级目录中)
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import numpy as np
import paddle
def create_dataloader(dataset,
trans_fn=None,
mode='train',
batch_size=1,
batchify_fn=None):
"""
Creats dataloader.
Args:
dataset(obj:`paddle.io.Dataset`): Dataset instance.
trans_fn(obj:`callable`, optional, defaults to `None`): function to convert a data sample to input ids, etc.
mode(obj:`str`, optional, defaults to obj:`train`): If mode is 'train', it will shuffle the dataset randomly.
batch_size(obj:`int`, optional, defaults to 1): The sample number of a mini-batch.
batchify_fn(obj:`callable`, optional, defaults to `None`): function to generate mini-batch data by merging
the sample list, None for only stack each fields of sample in axis
0(same as :attr::`np.stack(..., axis=0)`).
Returns:
dataloader(obj:`paddle.io.DataLoader`): The dataloader which generates batches.
"""
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False
if mode == "train":
sampler = paddle.io.DistributedBatchSampler(
dataset=dataset, batch_size=batch_size, shuffle=shuffle)
else:
sampler = paddle.io.BatchSampler(
dataset=dataset, batch_size=batch_size, shuffle=shuffle)
dataloader = paddle.io.DataLoader(
dataset, batch_sampler=sampler, collate_fn=batchify_fn)
return dataloader
def convert_example(example, tokenizer, is_test=False):
"""
Builds model inputs from a sequence for sequence classification tasks.
It use `jieba.cut` to tokenize text.
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj: paddlenlp.data.JiebaTokenizer): It use jieba to cut the chinese string.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
Returns:
input_ids(obj:`list[int]`): The list of token ids.
valid_length(obj:`int`): The input sequence valid length.
label(obj:`numpy.array`, data type1 of int64, optional): The input label if not is_test.
"""
input_ids = tokenizer.encode(example["text"])
input_ids = np.array(input_ids, dtype='int64')
if not is_test:
label = np.array(example["label"], dtype="int64")
return input_ids, label
else:
return input_ids
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader):
"""
Given a dataset, it evals model and computes the metric.
Args:
model(obj:`paddle.nn.Layer`): A model to classify texts.
criterion(obj:`paddle.nn.Layer`): It can compute the loss.
metric(obj:`paddle.metric.Metric`): The evaluation metric.
data_loader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches.
"""
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval loss: %.5f, accu: %.5f" % (np.mean(losses), accu))
model.train()
metric.reset()
import time
from utils import evaluate
# 训练轮次
epochs = 1
# 训练过程中保存模型参数的文件夹
ckpt_dir = "skep_ckpt"
# len(train_data_loader)一轮训练所需要的step数
num_training_steps = len(train_data_loader) * epochs
# Adam优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=2e-5,
parameters=model.parameters())
# 交叉熵损失函数
criterion = paddle.nn.loss.CrossEntropyLoss()
# accuracy评价指标
metric = paddle.metric.Accuracy()# 开启训练
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率值
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 评估当前训练的模型
evaluate(model, criterion, metric, dev_data_loader)
# 保存当前模型参数等
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)global step 10, epoch: 1, batch: 10, loss: 0.53868, accu: 0.66250, speed: 1.45 step/s
global step 20, epoch: 1, batch: 20, loss: 0.38239, accu: 0.76562, speed: 1.40 step/s
global step 30, epoch: 1, batch: 30, loss: 0.14145, accu: 0.81667, speed: 1.39 step/s
global step 40, epoch: 1, batch: 40, loss: 0.19523, accu: 0.84219, speed: 1.40 step/s
global step 50, epoch: 1, batch: 50, loss: 0.17806, accu: 0.85688, speed: 1.40 step/s
global step 60, epoch: 1, batch: 60, loss: 0.34572, accu: 0.86771, speed: 1.40 step/s
global step 70, epoch: 1, batch: 70, loss: 0.28901, accu: 0.87634, speed: 1.40 step/s
global step 80, epoch: 1, batch: 80, loss: 0.30491, accu: 0.87891, speed: 1.40 step/s
global step 90, epoch: 1, batch: 90, loss: 0.21844, accu: 0.88403, speed: 1.40 step/s
global step 100, epoch: 1, batch: 100, loss: 0.08482, accu: 0.88687, speed: 1.40 step/s
eval loss: 0.24119, accu: 0.91083
global step 110, epoch: 1, batch: 110, loss: 0.23338, accu: 0.89375, speed: 0.49 step/s
global step 120, epoch: 1, batch: 120, loss: 0.11810, accu: 0.89375, speed: 1.40 step/s
global step 130, epoch: 1, batch: 130, loss: 0.15867, accu: 0.90208, speed: 1.40 step/s
global step 140, epoch: 1, batch: 140, loss: 0.09246, accu: 0.90391, speed: 1.40 step/s
global step 150, epoch: 1, batch: 150, loss: 0.17813, accu: 0.90750, speed: 1.40 step/s
global step 160, epoch: 1, batch: 160, loss: 0.30430, accu: 0.90885, speed: 1.41 step/s
global step 170, epoch: 1, batch: 170, loss: 0.09656, accu: 0.90893, speed: 1.40 step/s
global step 180, epoch: 1, batch: 180, loss: 0.03513, accu: 0.91016, speed: 1.40 step/s
global step 190, epoch: 1, batch: 190, loss: 0.21260, accu: 0.90938, speed: 1.40 step/s
global step 200, epoch: 1, batch: 200, loss: 0.43565, accu: 0.90906, speed: 1.40 step/s
eval loss: 0.20330, accu: 0.93083
global step 210, epoch: 1, batch: 210, loss: 0.25406, accu: 0.93750, speed: 0.49 step/s
global step 220, epoch: 1, batch: 220, loss: 0.24473, accu: 0.93750, speed: 1.39 step/s
global step 230, epoch: 1, batch: 230, loss: 0.30164, accu: 0.94271, speed: 1.40 step/s
global step 240, epoch: 1, batch: 240, loss: 0.30389, accu: 0.93516, speed: 1.39 step/s
global step 250, epoch: 1, batch: 250, loss: 0.26582, accu: 0.93063, speed: 1.40 step/s
global step 260, epoch: 1, batch: 260, loss: 0.17866, accu: 0.93073, speed: 1.40 step/s
global step 270, epoch: 1, batch: 270, loss: 0.11397, accu: 0.93304, speed: 1.40 step/s
global step 280, epoch: 1, batch: 280, loss: 0.13630, accu: 0.93281, speed: 1.40 step/s
global step 290, epoch: 1, batch: 290, loss: 0.13803, accu: 0.93229, speed: 1.40 step/s
global step 300, epoch: 1, batch: 300, loss: 0.06872, accu: 0.93312, speed: 1.43 step/s
eval loss: 0.17526, accu: 0.94083
3.1.5 预测提交结果
使用训练得到的模型还可以对文本进行情感预测。
import numpy as np
import paddle
# 处理测试集数据
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack() # qid
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_ckp/model_500/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)label_map = {0: '0', 1: '1'}
results = []
# 切换model模型为评估模式,关闭dropout等随机因素
model.eval()
for batch in test_data_loader:
input_ids, token_type_ids, qids = batch
# 喂数据给模型
logits = model(input_ids, token_type_ids)
# 预测分类
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
qids = qids.numpy().tolist()
results.extend(zip(qids, labels))res_dir = "./results"
if not os.path.exists(res_dir):
os.makedirs(res_dir)
# 写入预测结果
with open(os.path.join(res_dir, "ChnSentiCorp.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for qid, label in results:
f.write(str(qid[0])+"\t"+label+"\n")3.2 目标级情感分析
在电商产品分析场景下,除了分析整体商品的情感极性外,还细化到以商品具体的“方面”为分析主体进行情感分析(aspect-level),如下、:
- 这个薯片口味有点咸,太辣了,不过口感很脆。
关于薯片的口味方面是一个负向评价(咸,太辣),然而对于口感方面却是一个正向评价(很脆)。
- 我很喜欢夏威夷,就是这边的海鲜太贵了。
关于夏威夷是一个正向评价(喜欢),然而对于夏威夷的海鲜却是一个负向评价(价格太贵)。

目标级情感分析任务
常用数据集
千言数据集已提供了许多任务常用数据集。
其中情感分析数据集下载链接:千言数据集:情感分析_千言数据集评测-飞桨AI Studio星河社区 (baidu.com)
SE-ABSA16_PHNS数据集是关于手机的目标级情感分析数据集。PaddleNLP已经内置了该数据集,加载方式,如下:
train_ds, test_ds = load_dataset("seabsa16", "phns", splits=["train", "test"])
print(train_ds[0])
print(train_ds[1])
print(train_ds[2])SKEP模型加载
目标级情感分析模型同样使用SkepForSequenceClassification模型,但目标级情感分析模型的输入不单单是一个句子,而是句对。一个句子描述“评价对象方面(aspect)”,另一个句子描述"对该方面的评论"。如下图所示。
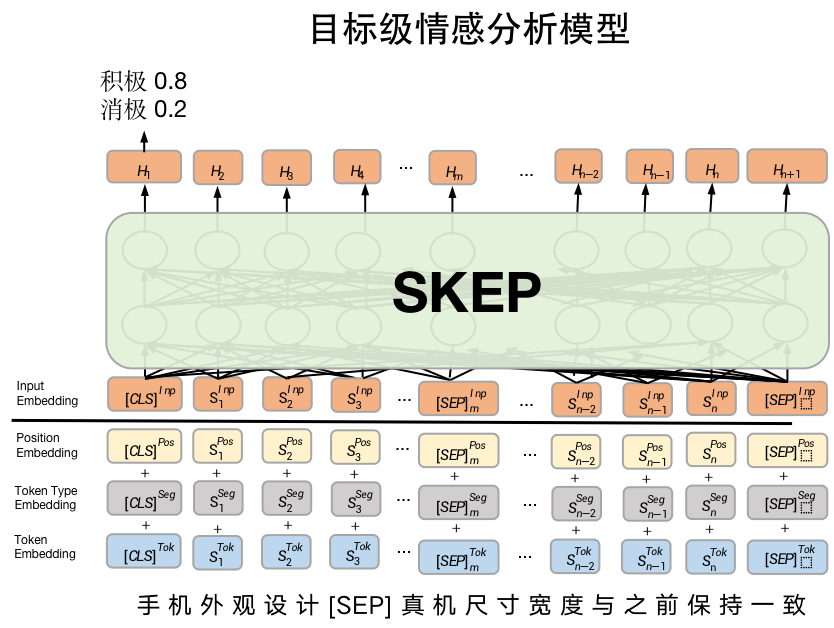
# 指定模型名称一键加载模型
model = SkepForSequenceClassification.from_pretrained(
'skep_ernie_1.0_large_ch', num_classes=len(train_ds.label_list))
# 指定模型名称一键加载tokenizer
tokenizer = SkepTokenizer.from_pretrained('skep_ernie_1.0_large_ch')数据处理
同样地,我们需要将原始SE_ABSA16_PHNS数据处理成模型可以读入的数据格式。
SKEP模型对中文文本处理按照字粒度进行处理,我们可以使用PaddleNLP内置的SkepTokenizer完成一键式处理。
from functools import partial
import os
import time
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False,
dataset_name="chnsenticorp"):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence has the following format:
::
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
note: There is no need token type ids for skep_roberta_large_ch model.
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
max_seq_len(obj:`int`): The maximum total input sequence length after tokenization.
Sequences longer than this will be truncated, sequences shorter will be padded.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
dataset_name((obj:`str`, defaults to "chnsenticorp"): The dataset name, "chnsenticorp" or "sst-2".
Returns:
input_ids(obj:`list[int]`): The list of token ids.
token_type_ids(obj: `list[int]`): List of sequence pair mask.
label(obj:`numpy.array`, data type of int64, optional): The input label if not is_test.
"""
encoded_inputs = tokenizer(
text=example["text"],
text_pair=example["text_pair"],
max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids# 处理的最大文本序列长度
max_seq_length=256
# 批量数据大小
batch_size=16
# 将数据处理成model可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)模型训练
定义损失函数、优化器以及评价指标后,即可开始训练。
# 训练轮次
epochs = 3
# 总共需要训练的step数
num_training_steps = len(train_data_loader) * epochs
# 优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=5e-5,
parameters=model.parameters())
# 交叉熵损失
criterion = paddle.nn.loss.CrossEntropyLoss()
# Accuracy评价指标
metric = paddle.metric.Accuracy()# 开启训练
ckpt_dir = "skep_aspect"
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
save_dir = os.path.join(ckpt_dir, "model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 保存模型参数
model.save_pretrained(save_dir)
# 保存tokenizer的词表等
tokenizer.save_pretrained(save_dir)global step 10, epoch: 1, batch: 10, loss: 0.65064, acc: 0.53125, speed: 1.27 step/s
global step 20, epoch: 1, batch: 20, loss: 0.52287, acc: 0.55312, speed: 1.26 step/s
global step 30, epoch: 1, batch: 30, loss: 0.71099, acc: 0.57083, speed: 1.27 step/s
global step 40, epoch: 1, batch: 40, loss: 0.70976, acc: 0.59062, speed: 1.27 step/s
global step 50, epoch: 1, batch: 50, loss: 0.62593, acc: 0.59000, speed: 1.26 step/s
global step 60, epoch: 1, batch: 60, loss: 0.70332, acc: 0.58542, speed: 1.26 step/s
global step 70, epoch: 1, batch: 70, loss: 0.52017, acc: 0.59911, speed: 1.25 step/s
global step 80, epoch: 1, batch: 80, loss: 0.64913, acc: 0.60781, speed: 1.27 step/s
global step 90, epoch: 2, batch: 6, loss: 0.56703, acc: 0.60824, speed: 1.30 step/s
global step 100, epoch: 2, batch: 16, loss: 0.59230, acc: 0.61746, speed: 1.26 step/s
global step 110, epoch: 2, batch: 26, loss: 0.74638, acc: 0.61473, speed: 0.84 step/s
global step 120, epoch: 2, batch: 36, loss: 0.67488, acc: 0.62134, speed: 1.25 step/s
global step 130, epoch: 2, batch: 46, loss: 0.60215, acc: 0.62307, speed: 1.27 step/s
global step 140, epoch: 2, batch: 56, loss: 0.47045, acc: 0.63172, speed: 1.26 step/s
global step 150, epoch: 2, batch: 66, loss: 0.53512, acc: 0.63253, speed: 1.27 step/s
global step 160, epoch: 2, batch: 76, loss: 0.59317, acc: 0.63597, speed: 1.26 step/s
global step 170, epoch: 3, batch: 2, loss: 0.50540, acc: 0.63794, speed: 1.31 step/s
global step 180, epoch: 3, batch: 12, loss: 0.69784, acc: 0.63827, speed: 1.25 step/s
global step 190, epoch: 3, batch: 22, loss: 0.57723, acc: 0.64451, speed: 1.26 step/s
global step 200, epoch: 3, batch: 32, loss: 0.53240, acc: 0.64667, speed: 1.26 step/s
global step 210, epoch: 3, batch: 42, loss: 0.87506, acc: 0.64713, speed: 0.86 step/s
global step 220, epoch: 3, batch: 52, loss: 0.60447, acc: 0.64755, speed: 1.26 step/s
global step 230, epoch: 3, batch: 62, loss: 0.51687, acc: 0.64793, speed: 1.26 step/s
global step 240, epoch: 3, batch: 72, loss: 0.57719, acc: 0.65272, speed: 1.25 step/s
global step 250, epoch: 3, batch: 82, loss: 0.43986, acc: 0.65487, speed: 1.29 step/s
预测提交结果
使用训练得到的模型还可以对评价对象进行情感预测。
@paddle.no_grad()
def predict(model, data_loader, label_map):
"""
Given a prediction dataset, it gives the prediction results.
Args:
model(obj:`paddle.nn.Layer`): A model to classify texts.
data_loader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches.
label_map(obj:`dict`): The label id (key) to label str (value) map.
"""
model.eval()
results = []
for batch in data_loader:
input_ids, token_type_ids = batch
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results# 处理测试集数据
label_map = {0: '0', 1: '1'}
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)# 根据实际运行情况,更换加载的参数路径
params_path = 'skep_ckpt/model_900/model_state.pdparams'
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
results = predict(model, test_data_loader, label_map)# 写入预测结果
with open(os.path.join("results", "SE-ABSA16_PHNS.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for idx, label in enumerate(results):
f.write(str(idx)+"\t"+label+"\n")#将预测文件结果压缩至zip文件,提交
!zip -r results.zip results
updating: results/ (stored 0%)
updating: results/ChnSentiCorp.tsv (deflated 63%)
updating: results/SE-ABSA16_PHNS.tsv (deflated 64%)