「前言」文章内容是排序算法之快速排序的讲解。(所有文章已经分类好,放心食用)
「归属专栏」排序算法
「主页链接」个人主页
「笔者」枫叶先生(fy)
目录
- 快速排序
- 1.1 原理
- 1.2 Hoare版本(单趟)
- 1.3 快速排序完整代码(Hoare版)(递归实现)
- 1.4 选择基准数key优化(三数取中)
- 1.5 挖坑法(单趟)
- 1.6 快速排序完整代码(挖坑法)(递归实现)
- 1.7 前后指针版(单趟)
- 1.8 快速排序完整代码(前后指针版)(递归实现)
- 1.9 快速排序小区间优化
- 1.9 快速排序非递归实现
- 1.10 特性总结
快速排序
1.1 原理
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,一种高效的排序算法
基本思想:是通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分小,然后再按照此方法对这两部分数据分别进行快速排序,以达到整个数据变成有序序列
具体步骤如下:
- 从数列中挑出一个元素作为基准元素
- 将比基准元素小的元素放在其左边,比基准元素大的元素放在其右边,基准元素所在位置即为最终位置
- 分别对左右两个子序列递归地进行快速排序
对于如何按照基准值将待排序列分为两个子序列(单趟),单趟常见的方式有:
- Hoare版本
- 挖坑法
- 前后指针法
下面先谈Hoare版本的
1.2 Hoare版本(单趟)
Hoare版本的单趟排序的动图如下:

Hoare版本的单趟排序的基本步骤如下:
- 从数组中选出一个
key,一般是最左边或是最右边的,上面动图是选左边的 - 定义一个
left: L和一个right: R。如果选的key是左边的,则需要R先走,然后L从左向右走,R从右向左走。(注意:若选择最右边的数据作为key,则需要L先走) - 选左:
- 选取最左边的基准值作为
key,L和R的任务:(1)L:找比key大的;(2)R:找比key小的 - 选取最左边的基准值作为
key: 在走的过程中,若R遇到小于key的数,则停下,L开始走,直到L遇到一个大于key的数时,将L和R的内容交换,R再次开始走,如此进行下去,直到L和R最终相遇,相遇结束。此时将相遇点的内容与key交换即可 - 选右:
- 选取最左边的基准值作为
key,L和R的任务:(1)L:找比key小的;(2)R:找比key大的 - 选取最右边的基准值作为
key: 在走的过程中,若L遇到小于key的数,则停下,R开始走,直到R遇到一个大于key的数时,将L和R的内容交换,L再次开始走,如此进行下去,直到L和R最终相遇,相遇结束。此时将相遇点的内容与key交换即可
经过一次单趟排序,最终使得key左边的数据全部都小于key,key右边的数据全部都大于key,并且key所在的位置就是最终的位置
相遇位置的值如何保证比
key小,相遇点直接和key交换会不会出错,会不会把较大的值换到了左边?
- 如果选取最左边的基准值作为
key,R先走保证相遇位置的值保证比key小 - 如果R停下来,L走,L撞到R(相遇),相遇位置的值必定比
key小 - 如果L停下来,R走,R撞到L(相遇),相遇位置的值必定比
key小 - 同理,如果选取最右边的基准值作为
key,L先走保证相遇位置的值保证比key大
1.3 快速排序完整代码(Hoare版)(递归实现)
首先经过一次单趟排序,然后将key的左序列和右序列再次进行这种单趟排序,如此反复操作下去,直到左右序列只有一个数据,或是左右序列不存在时,停止操作,此时序列(或者子序列)已经有序
排序步骤演示:
类似于二叉树的前序遍历
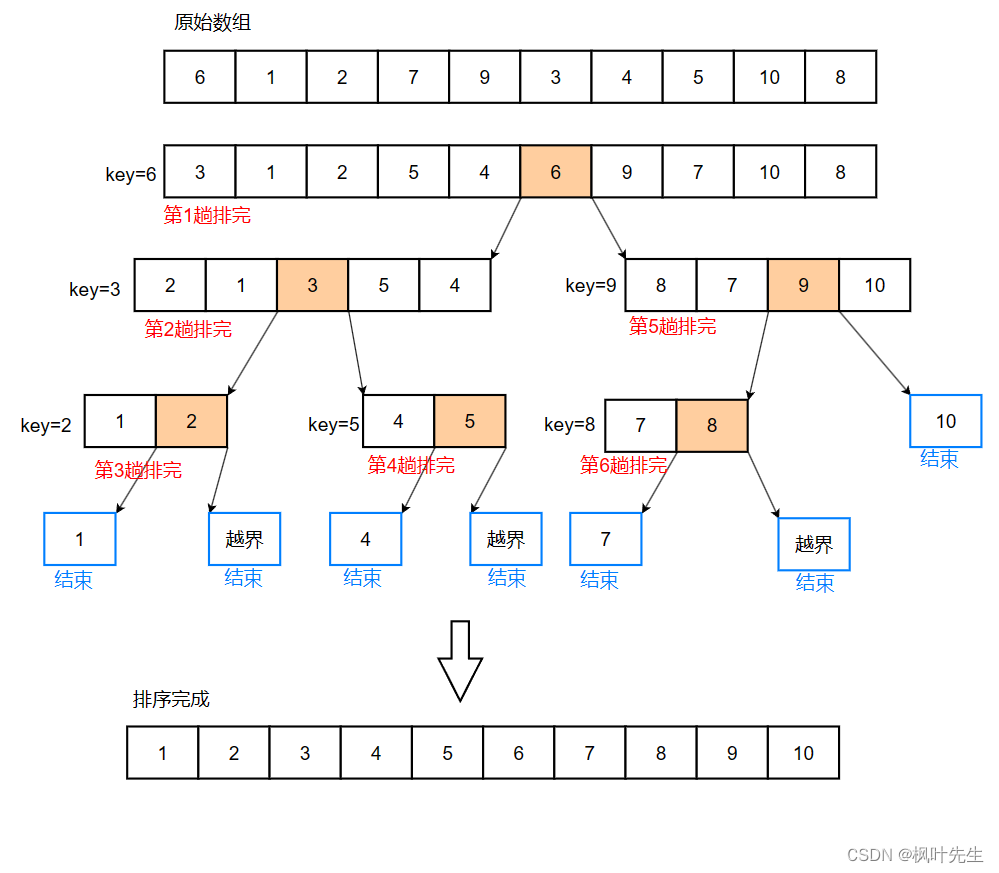
代码如下(递归,Hoare版):(升序)
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// Hoare版本(单趟)
int PartQuickSort(int* arr, int left, int right)
{
int keyi = left; // key的下标,选左边为key
while (left < right) // left == right即相遇
{
// right先走,找比key小的值
while (left < right && arr[right] >= arr[keyi])
{
--right;
}
// left后走,找比key大的值
while (left < right && arr[left] <= arr[keyi])
{
++left;
}
// 找到一组值,交换:交换arr[left] 和 arr[right]
if (left < right)
{
Swap(&arr[left], &arr[right]);
}
}
Swap(&arr[keyi], &arr[left]); // 交换 keyi 和相遇点位置的值,left==right
return left; // 返回相遇点的下标
}
// 快速排序
void QuickSort(int* arr, int left, int right)
{
// 1、区间不存在(left > right) 2、只有一个数数不需要再处理(left == right)
if (left >= right)
{
return;
}
// 单趟排序并获取基准值
int keyi = PartQuickSort(arr, left, right);
// 递归处理每一个子序列(左、右)
QuickSort(arr, left , keyi - 1); // keyi 左序列进行排序
QuickSort(arr, keyi + 1, right); // keyi 右序列进行排序
}
1.4 选择基准数key优化(三数取中)
快速排序的时间复杂度是O(NlogN),是我们在理想情况下计算的结果
在理想情况下,我们每次进行完单趟排序后,key的左序列与右序列的长度都相同
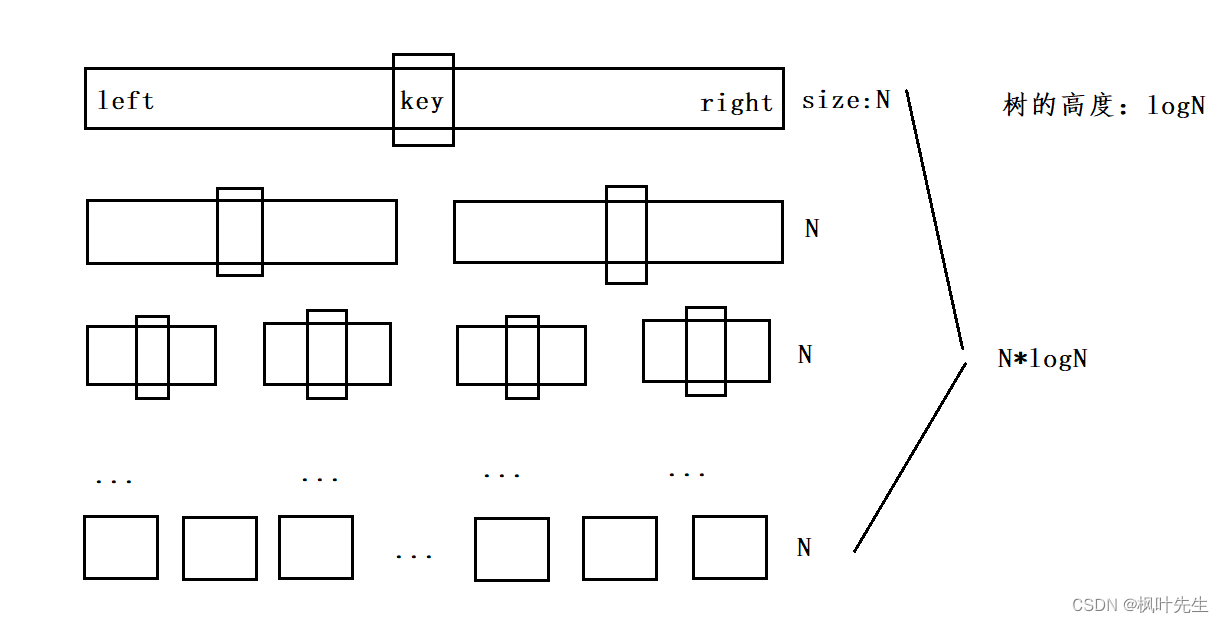
若每趟排序所选的key都正好是该序列的中间值,即单趟排序结束后key位于序列正中间,那么快速排序的时间复杂度就是O(NlogN)
可是谁能保证你每次选取的key都是正中间的那个数呢?
例如,以下数组:

如果基准值key是数组中最大或最小的数值(假设选左边),则快速排序的递归深度会非常深,排序效率会很低
若是一个有序数组使用快速排序,这种情况下,快速排序的时间复杂度退化为O(N^2)
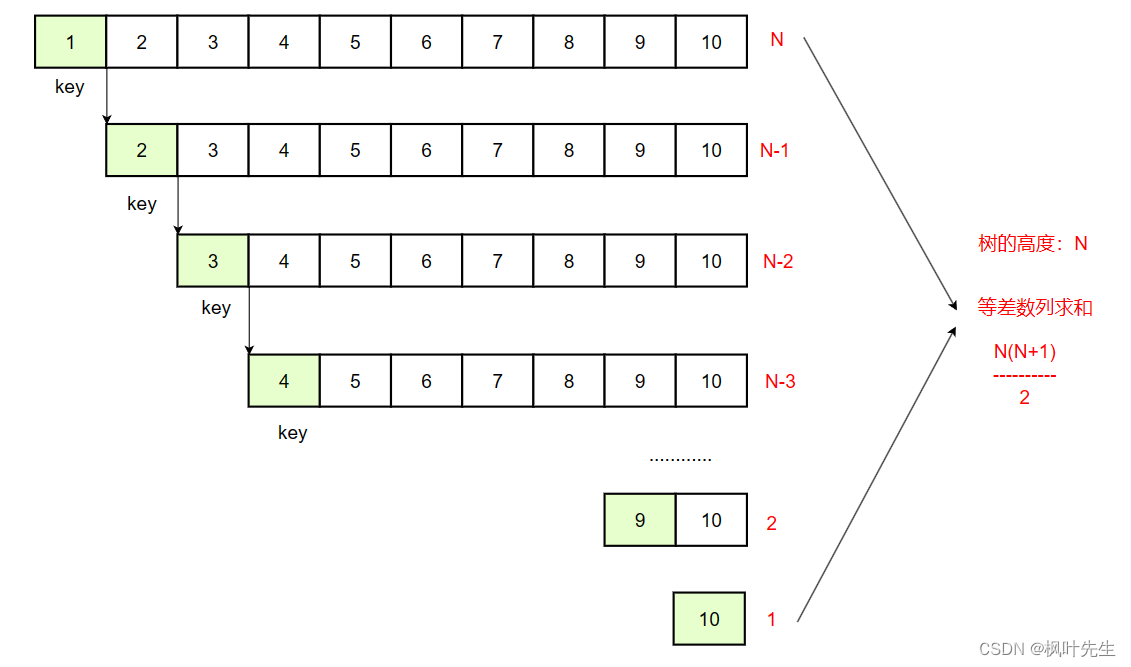
对快速排序效率影响最大的就是选取的key,若选取的key越接近中间位置,则则效率越高
为了避免这种极端情况的发生,于是出现了三数取中
三数取中
三数取中的方法是从待排序数组中选择三个元素,分别是左端、右端和中间位置的元素,然后取这三个元素的中间值作为基准元素
代码如下:
// 三数取中
int GetMidIndex(int* arr, int left, int right)
{
int mid = left + (right - left) / 2;
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{
return mid; // [mid]是中间值
}
else if (arr[left] > arr[right])
{
return left;
}
else
{
return right;
}
}
else // arr[left] >= arr[mid]
{
if (arr[mid] > arr[right])
{
return mid;
}
else if (arr[left] < arr[right])
{
return left;
}
else
{
return right;
}
}
}
需要注意,当大小居中的数不在序列的最左或是最右端时,我们不是就以居中数的位置作为key的位置,而是将key的值与最左端的值进行交换,这样key就还是位于最左端了,所写代码就无需改变,而只需在单趟排序代码开头加上以下两句代码即可:
如下:
// Hoare版本(单趟)
int PartQuickSort(int* arr, int left, int right)
{
// 三数取中
int midi = GetMidIndex(arr, left, right);
Swap(&arr[left], &arr[midi]);
int keyi = left; // key的下标,选左边为key
// ...
return left; // 返回相遇点的下标
}
1.5 挖坑法(单趟)
挖坑法是基于Hoare版本改良的(Hoare版本代码细节太多)
挖坑法的单趟排序的动图如下:

挖坑法的单趟排序的基本步骤如下:
- 选出一个数据(上图选最左为坑)存放在
key变量中,在该数据位置形成一个坑 - 定义一个
left: L和一个right: R,L从左向右走,R从右向左走(若在最左边挖坑,则需要R先走;若在最右边挖坑,则需要L先走) - 选取最左边的作为坑位为例:
- L和R的任务:(1)L:找比
key大的;(2)R:找比key小的 - R先走,在走的过程中,若R遇到小于
key的数,则将该数抛入坑位,并在此处形成一个新的坑位,这时L再向后走,若遇到大于key的数,则将其抛入坑位,又形成一个坑位,如此循环下去,直到最终L和R相遇,这时将key抛入坑位即可
经过一次单趟排序,最终也使得key左边的数据全部都小于key,key右边的数据全部都大于key,并且key所在的位置就是最终的位置
挖坑法代码如下:(升序)
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 挖坑法(单趟)
int PartQuickSort2(int* arr, int left, int right)
{
// 三数取中
int midi = GetMidIndex(arr, left, right);
Swap(&arr[left], &arr[midi]);
int key = arr[left]; // 在最左形成一个坑位
int hole = left; // 坑的下标
while (left < right)
{
// right先走,找比key小的
while (left < right && arr[right] >= key)
{
--right;
}
arr[hole] = arr[right]; // 填坑
hole = right;
// left后走,找比key大的
while (left < right && arr[left] <= key)
{
++left;
}
arr[hole] = arr[left]; // 填坑
hole = left;
}
arr[hole] = key;
return hole;
}
1.6 快速排序完整代码(挖坑法)(递归实现)
代码如下(递归,挖坑法):(升序)
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 挖坑法(单趟)
int PartQuickSort2(int* arr, int left, int right)
{
// 三数取中
int midi = GetMidIndex(arr, left, right);
Swap(&arr[left], &arr[midi]);
int key = arr[left]; // 在最左形成一个坑位
int hole = left; // 坑的下标
while (left < right)
{
// right先走,找比key小的
while (left < right && arr[right] >= key)
{
--right;
}
arr[hole] = arr[right]; // 填坑
hole = right;
// left后走,找比key大的
while (left < right && arr[left] <= key)
{
++left;
}
arr[hole] = arr[left]; // 填坑
hole = left;
}
arr[hole] = key;
return hole; // 返回key的下标
}
// 快速排序
void QuickSort(int* arr, int left, int right)
{
// 1、区间不存在(left > right) 2、只有一个数数不需要再处理(left == right)
if (left >= right)
{
return;
}
// 单趟排序并获取基准值
int keyi = PartQuickSort2(arr, left, right);
// 递归处理每一个子序列(左、右)
QuickSort(arr, left , keyi - 1); // keyi 左序列进行排序
QuickSort(arr, keyi + 1, right); // keyi 右序列进行排序
}
1.7 前后指针版(单趟)
前后指针版的单趟排序的动图如下:

前后指针法的单趟排序的基本步骤如下:
- 选出一个
key,最左边或是最右边的(上图选最左) - 开始时,
prev指向序列的左边,cur指向prev+1的位置 - 情况1:若
cur指向的内容小于key,则prev向右后移动一位,然后交换prev和cur指针指向的内容,然后cur指针++ - 情况2:若
cur指向的内容大于key,则cur指针直接++。如此进行下去,直到cur指针越界,此时将key和prev指针指向的内容交换即可
前后指针版代码如下:(升序)
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 前后指针版(单趟)
int PartQuickSort3(int* arr, int left, int right)
{
// 三数取中
int midi = GetMidIndex(arr, left, right);
Swap(&arr[left], &arr[midi]);
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (arr[cur] < arr[keyi]) // cur指向的内容小于key
{
++prev;
if(prev != cur)
Swap(&arr[prev], &arr[cur]);
}
++cur;
}
Swap(&arr[keyi], &arr[prev]);
return prev; // 返回key当前的下标
}
1.8 快速排序完整代码(前后指针版)(递归实现)
代码如下(递归,前后指针版):(升序)
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
// 前后指针版(单趟)
int PartQuickSort3(int* arr, int left, int right)
{
// 三数取中
int midi = GetMidIndex(arr, left, right);
Swap(&arr[left], &arr[midi]);
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (arr[cur] < arr[keyi]) // cur指向的内容小于key
{
++prev;
if(prev != cur)
Swap(&arr[prev], &arr[cur]);
}
++cur;
}
Swap(&arr[keyi], &arr[prev]);
return prev; // 返回key当前的下标
}
// 快速排序
void QuickSort(int* arr, int left, int right)
{
// 1、区间不存在(left > right) 2、只有一个数数不需要再处理(left == right)
if (left >= right)
{
return;
}
// 单趟排序并获取基准值
int keyi = PartQuickSort3(arr, left, right);
// 递归处理每一个子序列(左、右)
QuickSort(arr, left , keyi - 1); // keyi 左序列进行排序
QuickSort(arr, keyi + 1, right); // keyi 右序列进行排序
}
1.9 快速排序小区间优化
快速排序的递归类似于二叉树的形式,深度越深待排数组的长度越短,但是数量也越多,调用函数的次数就越多,开辟函数栈帧的消耗越大,导致效率下降(每一层的递归次数会以2倍的形式快速增长,后三层的递归次数占据了总递归次数的70%以上)
优化的方式就是设置一个排序序列的长度大小,若是数组长度大于这个指定的数,则调用快速排序,若是数组长度小于这个指定的数,不再调用快速排序,而是调用插入排序或者其他排序
这个数可自行调整,代码如下:
// 快速排序(优化)
void QuickSort2(int* arr, int left, int right)
{
// 1、区间不存在(left > right) 2、只有一个数数不需要再处理(left == right)
if (left >= right)
{
return;
}
if (right - left + 1 > 8) // 可自行调整
{
// 单趟排序并获取基准值
int keyi = PartQuickSort3(arr, left, right);
// 递归处理每一个子序列(左、右)
QuickSort(arr, left, keyi - 1); // keyi 左序列进行排序
QuickSort(arr, keyi + 1, right); // keyi 右序列进行排序
}
else // 调用其他排序
{
InsertSort(arr + left, right - left + 1);
}
}
1.9 快速排序非递归实现
将一个用递归实现的算法改为非递归时,一般需要借用一个数据结构,那就是栈
C语言的库没有封装有stack,需要自己手搓一个,C++的STL库则封装有
如果是C语言,我就不贴代码了,代码链接:stack,下面简单介绍一下手搓stack的接口
// 初始化
void StackInit(ST* ps);
// 销毁栈
void StackDestroy(ST* ps);
// 入栈
void StackPush(ST* ps, STDataType x);
// 出栈
void StackPop(ST* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool StackEmpty(ST* ps);
// 获取栈顶元素
STDataType StackTop(ST* ps);
// 获取栈中有效元素个数
int StackSize(ST* ps);
快速排序的非递归算法基本思路:
- 先将待排序列的第一个元素的下标和最后一个元素的下标入栈
- 当栈不为空时,读取栈中的信息(一次读取两个:一个是left,另一个是right),然后调用某一版本的单趟排序,排完后获得了
key的下标,然后判断key的左序列和右序列是否还需要排序,若还需要排序,就将相应序列的left和right入栈;若不需排序了(序列只有一个元素或是区间不存在),就不需要将该序列区间的信息入栈 - 重复执行步骤2,直到栈为空为止
C语言代码如下:(升序)
void QuickSort3(int* arr, int left, int right)
{
Stack st; // 创建栈
StackInit(&st); // 初始化栈
StackPush(&st, left); // 待排序列的left
StackPush(&st, right); // 待排序列的right
while (!StackEmpty(&st)) // 栈为空结束
{
int right = StackTop(&st); // 读取right
StackPop(&st); // 出栈
int left = StackTop(&st); // 读取left
StackPop(&st); // 出栈
// 判断左右区间是否合理,若不合理则跳过本次循环
if (left >= right)
{
continue;
}
int keyi = PartQuickSort2(arr, left, right); // 调用单趟的方法
StackPush(&st, left); // 左序列的left入栈
StackPush(&st, keyi - 1); // 左序列的right入栈
StackPush(&st, keyi + 1); // 右序列的left入栈
StackPush(&st, right); // 右序列的right入栈
}
}
C++代码如下:(升序)
void QuickSort4(int* arr, int left, int right)
{
stack<int> st; // 创建栈
st.push(left); // 待排序列的left
st.push(right); // 待排序列的right
while (!st.empty()) // 栈为空结束
{
int right = st.top(); // 读取right
st.pop(); // 出栈
int left = st.top(); // 读取left
st.pop(); //出栈
//判断左右区间是否合理,若不合理则跳过本次循环
if (left >= right)
{
continue;
}
int keyi = PartQuickSort2(arr, left, right); // 调用单趟的方法
st.push(left); // 左序列的left入栈
st.push(keyi - 1); // 左序列的right入栈
st.push(keyi + 1); // 右序列的left入栈
st.push(right); // 右序列的right入栈
}
}
1.10 特性总结
快速排序的特性总结如下:
- 时间复杂度:平均情况下,快速排序的时间复杂度为
O(nlogn) - 空间复杂度:
O(1) - 稳定性:不稳定
- 不适用于小规模数据,适用于大规模数据的排序
--------------------- END ----------------------
「 作者 」 枫叶先生
「 更新 」 2024.1.20
「 声明 」 余之才疏学浅,故所撰文疏漏难免,
或有谬误或不准确之处,敬请读者批评指正。