文章目录
- Amazon FSx – 概述
- Amazon FSx for Lustre
- FSx Lustre - 文件系统部署选项
- Amazon FSx for NetApp ONTAP
- Amazon FSx for OpenZFS
- Hybrid Cloud 存储
- AWS 存储云原生选项
- AWS 存储网关
- Amazon S3 File Gateway
- Amazon FSx File Gateway
- Volume Gateway
- Tape Gateway
- Storage Gateway – 硬件设备
- AWS Storage Gateway
- AWS Transfer Family
- AWS DataSync
- AWS 存储服务之间的传输
- 存储比较
- AWS 集成和消息传递
- 章节介绍
- Amazon SQS - 什么是队列?
- Amazon SQS – 标准队列
- SQS 一 生成消息
- SQS 一 消费消息
- SQS – 多个 EC2 实例使用者
- SQS with Auto Scaling Group (ASG)
- SQS 可以在应用程序层之间解耦
- Amazon SQS - 安全
- SQS – Message Visibility Timeout
- Amazon SQS - Long Polling
- Amazon SQS – FIFO Queue
- SQS with Auto Scaling Group (ASG)
- Amazon SNS
- SNS 与 许多 AWS 服务集成
- Amazon SNS – 如何发布
- Amazon SNS – 安全
- SNS + SQS:Fan Out (扇出)
- 应用:S3 事件到多个队列
- 应用程序:通过 Kinesis Data Firehose SNS 到 Amazon S3
- Amazon SNS – FIFO topic
- SNS FIFO + SQS FIFO:扇出
- SNS – 消息过滤
- Kinesis 概述
- Kinesis Data Streams
- Kinesis Data Streams – Capacity Modes
- Kinesis Data Streams 安全
- Kinesis Firehose
- Kinesis Data Streams vs Firehose
- Kinesis Data Streams
- Kinesis Data Firehose
- 将数据排序到 Kinesis 中
- 将数据排序到 SQS 中
- Kinesis 与 SQS 排序
- SQS vs SNS vs Kinesis
- SQS
- SNS
- Kinesis
- Amazon MQ
- Amazon MQ – 高可用性
Amazon FSx – 概述
在 AWS 上启动的第三方高性能文件系统,以下是一些 AWS 完全托管的服务:

适用于 Windows 的 Amazon FSx(文件服务器)
- FSx for Windows 是完全托管的 Windows 文件系统共享驱动器
- 支持 SMB 协议和 Windows NTFS
- Microsoft Active Directory 集成、ACL、用户配额
- 可以安装在 Linux EC2 实例上
- 支持 Microsoft 的分布式文件系统 (DFS) 命名空间(跨多个 FS 的组文件)
- 扩展到 10 GB/s、数百万 IOPS、100 PB 数据
- 存储选项:
- SSD:延迟敏感的工作负载(数据库、媒体处理、数据分析……)
- HDD:广泛的工作负载(主目录、CMS,…)
- 可以从您的本地基础设施(VPN 或 Direct Connect)进行访问
- 可配置为多可用区(高可用性)
- 数据每天备份到S3
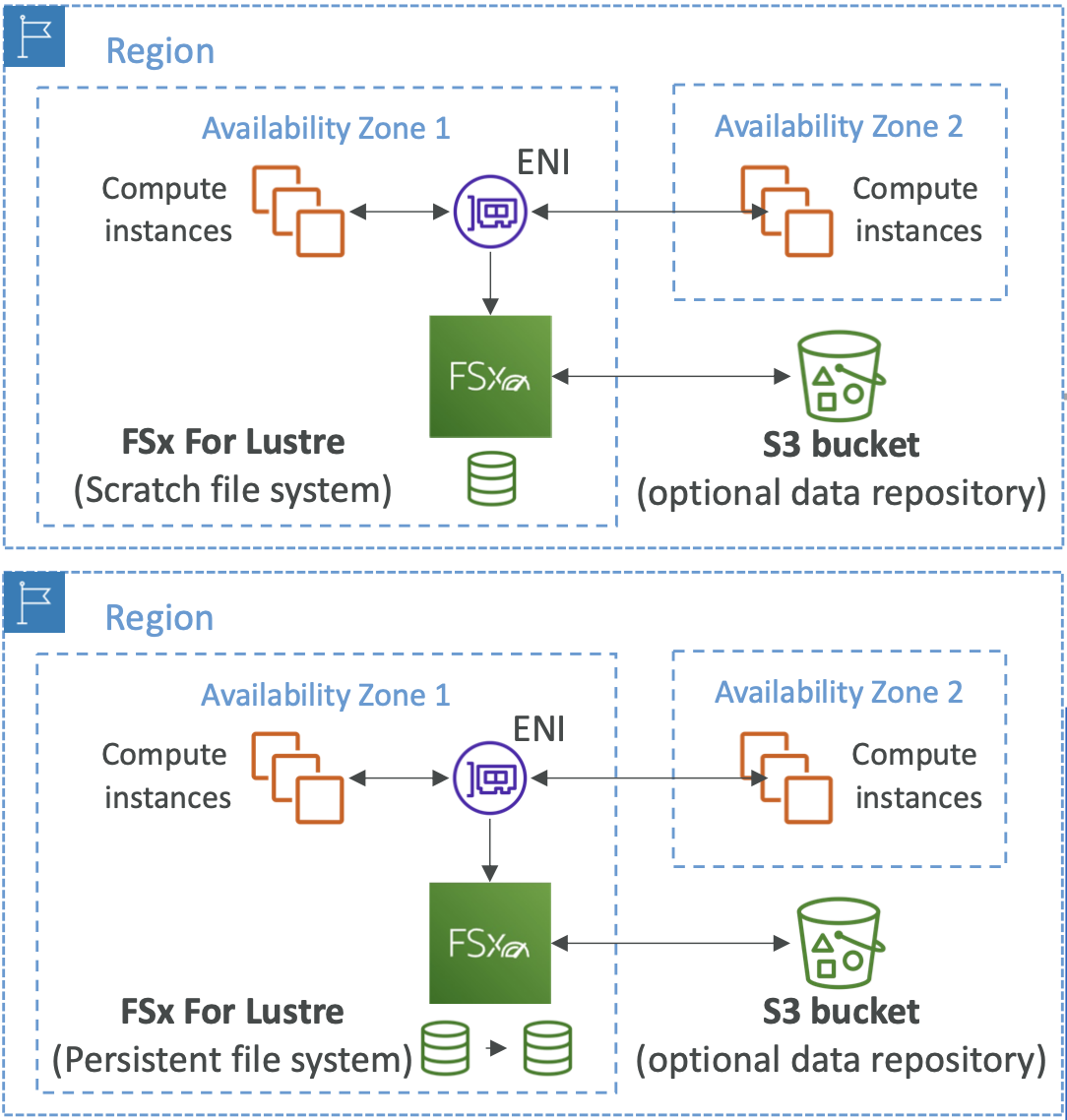
Amazon FSx for Lustre
- Lustre 是一种并行分布式文件系统,用于大规模计算
- Lustre 这个名字源自“Linux”和“cluster”
- 机器学习、高性能计算(HPC)
- 视频处理、财务建模、电子设计自动化
- 可扩展至 100 GB/s、数百万 IOPS、亚毫秒级延迟
- 存储选项:
- SSD:低延迟、IOPS 密集型工作负载、小文件和随机文件操作
- HDD:吞吐量密集型工作负载、大型连续文件操作
- 与S3无缝集成
- 可以“读取 S3”作为文件系统(通过 FSx)
- 可以将计算的输出写回到S3(通过FSx)
- 可以从本地服务器(VPN 或 Direct Connect)使用
FSx Lustre - 文件系统部署选项
- 暂存文件系统
- 临时存储
- 数据不会被复制(如果文件服务器出现故障,数据不会保留)
- 高突发(速度提高 6 倍,每 TiB 200MBps)
- 用途:短期加工,优化成本
- 持久文件系统
- 长期储存
- 数据在同一可用区内复制
- 在几分钟内替换失败的文件
- 用途:长期处理、敏感数据
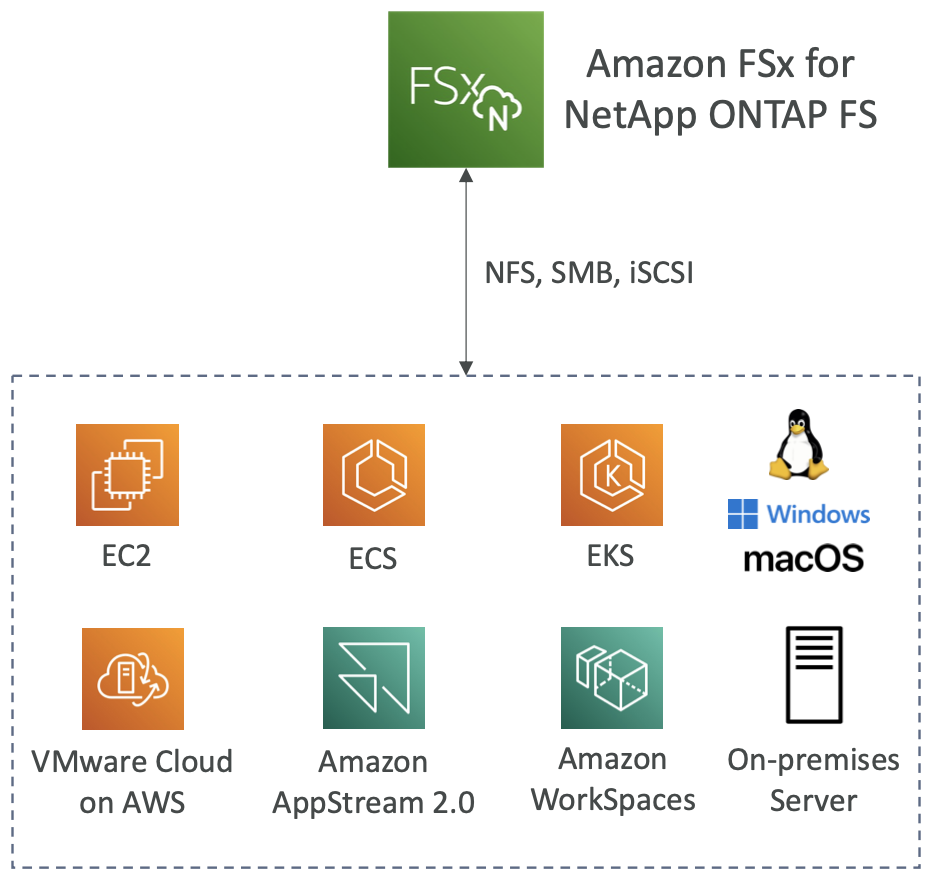
Amazon FSx for NetApp ONTAP
- AWS 上的托管 NetApp ONTAP
- 文件系统兼容NFS、SMB、iSCSI协议
- 将 ONTAP 或 NAS 上运行的工作负载移至 AWS
- 适用于:
- Linux
- 窗户
- 苹果系统
- AWS 上的 VMware 云
- Amazon Workspaces 和 AppStream 2.0
- Amazon EC2、ECS 和 EKS
- 存储自动缩小或增长
- 快照、复制、低成本、压缩和数据
- 时间点瞬时克隆(有助于测试新工作负载)
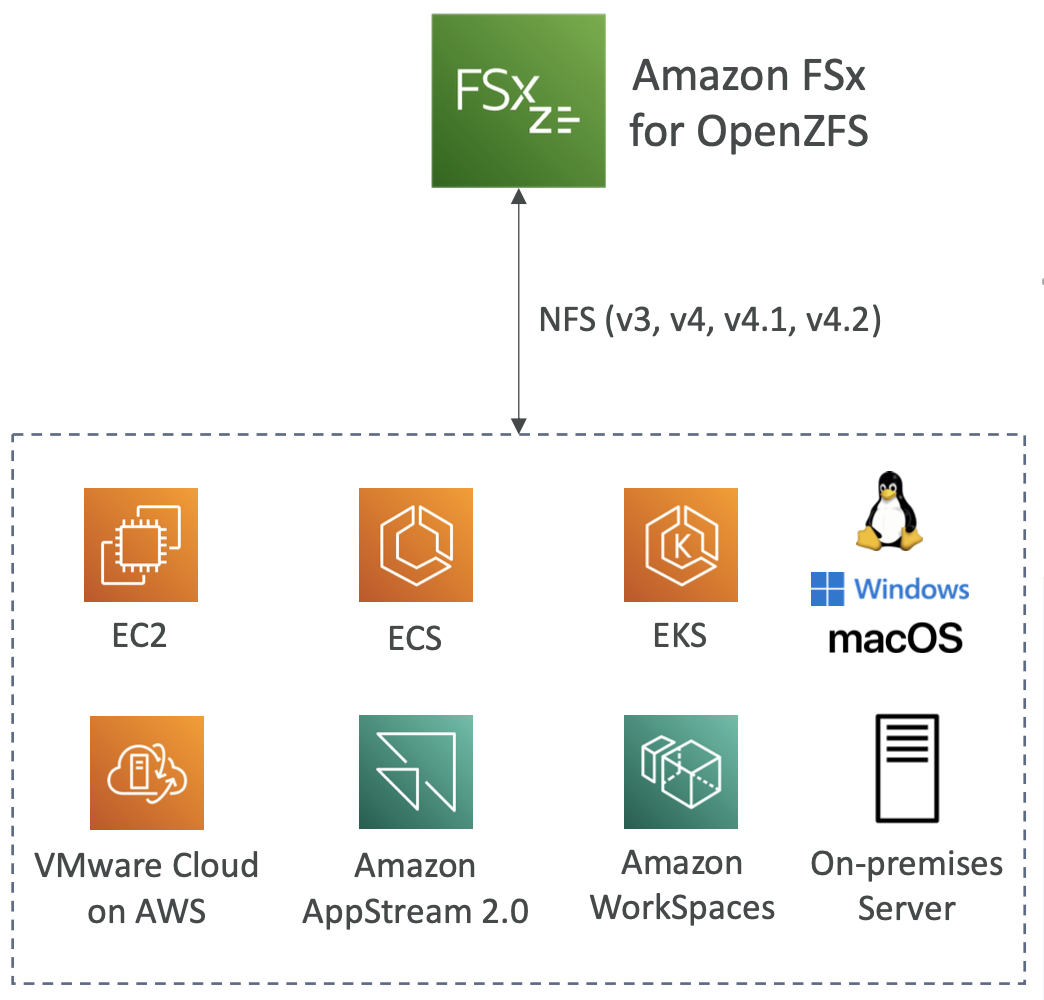
Amazon FSx for OpenZFS
- AWS 上的托管 OpenZFS 文件系统
- 与 NFS 兼容的文件系统(v3、v4、v4.1、v4.2)
- 将 ZFS 上运行的工作负载迁移到 AWS
- 适用于:
- Linux
- Window
- 苹果系统
- VMware Cloud on AWS
- Amazon Workspaces 和 AppStream 2.0
- Amazon EC2、ECS 和 EKS
- 高达 1,000,000 IOPS,延迟 < 0.5 毫秒
- 快照、压缩和低成本
- 时间点瞬时克隆(有助于测试新工作负载)
Hybrid Cloud 存储
- AWS 正在推动“混合云”
- 您的部分基础设施位于云端
- 您的部分基础设施位于本地
- 这可能是由于
- 长时间的云迁移
- 安全要求
- 合规要求
- 信息技术战略
- S3 是一种专有存储技术(与 EFS / NFS 不同),那么如何在本地公开 S3 数据?
- AWS 存储网关!
AWS 存储云原生选项
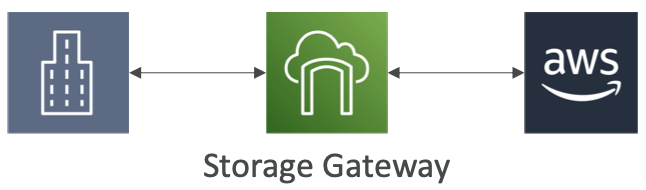
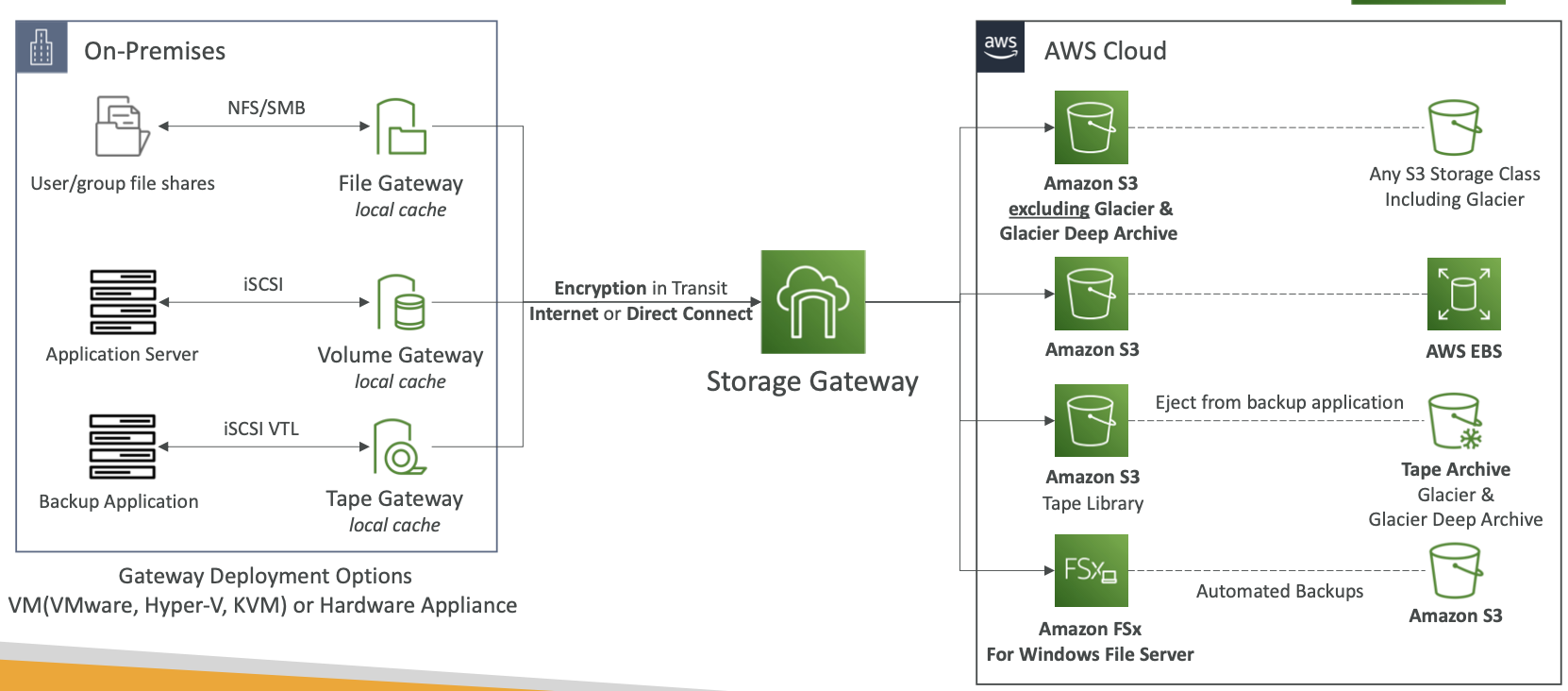
AWS 存储网关
- 本地数据和云数据之间的桥梁
- 用例:
- 灾难恢复
- 备份和恢复
- 分层存储
- 本地缓存和低延迟文件访问
- 存储网关的类型:
- S3 文件网关
- FSx 文件网关
- 卷网关
- 磁带网关
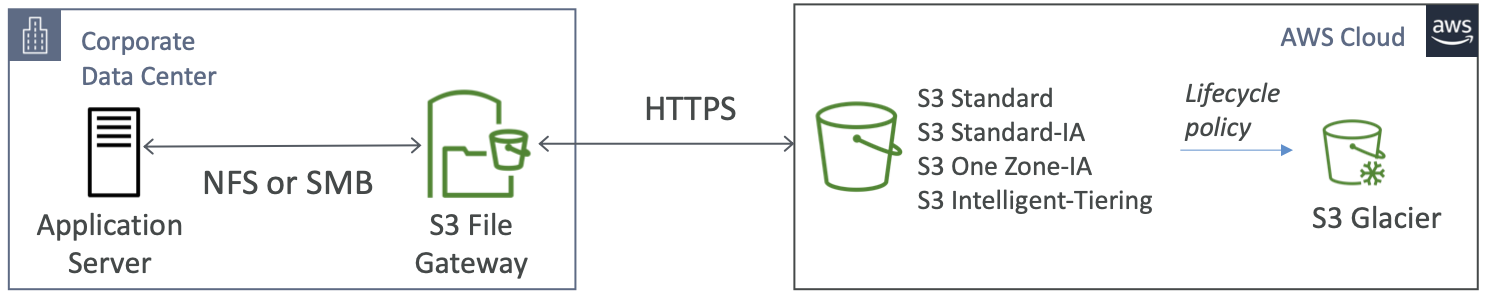
Amazon S3 File Gateway
- 可使用 NFS 和 SMB 协议访问配置的 S3 存储桶
- 最近使用的数据缓存在文件网关中
- 支持S3Standard、S3StandardIA、S3OneZoneA、S3Intelligent Tiering
- 使用生命周期策略过渡到 S3 Glacier
- 使用每个文件网关的 IAM 角色进行存储桶访问
- SMB 协议与 Active Directory (AD) 集成以进行用户身份验证
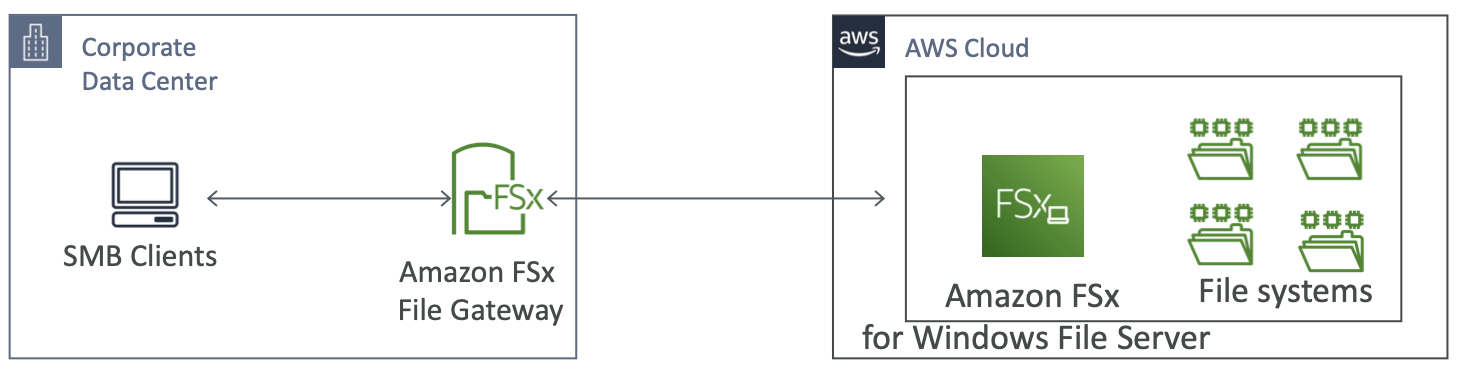
Amazon FSx File Gateway
- 对 Amazon FSx for Windows File Server 的本机访问
- 经常访问的数据的本地缓存
- Windows 本机兼容性(SMB、NTFS、Active Directory…)
- 对于组文件共享和主目录有用
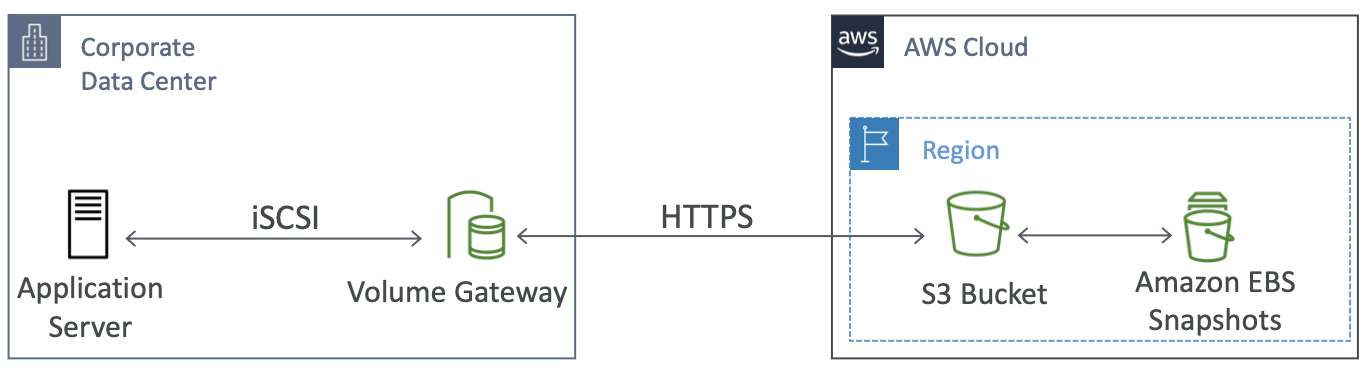
Volume Gateway
- 使用 S3 支持的 iSCSI 协议的块存储
- 由 EBS 快照支持,可以帮助恢复本地卷!
- 缓存卷:低延迟访问最新数据
- 存储卷:整个数据集都在本地,计划备份到 S3
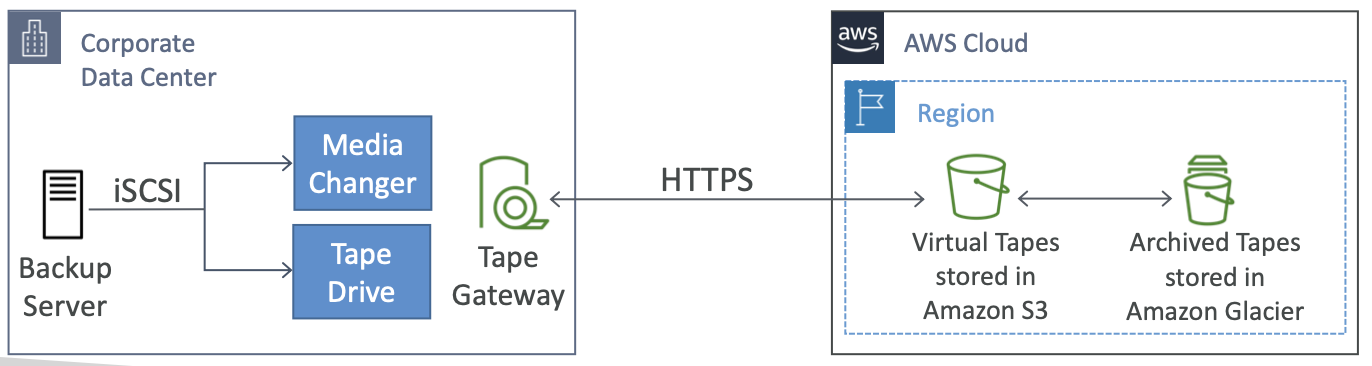
Tape Gateway
- 一些公司使用物理磁带进行备份过程(!)
- 通过磁带网关,公司可以使用相同的流程,但是在云中
- 由 Amazon S3 和 Glacier 支持的虚拟磁带库 (VTL)
- 使用现有的基于磁带的流程(和 iSCSI 接口)备份数据
- 与领先的备份软件供应商合作
Storage Gateway – 硬件设备
- 使用 Storage Gateway 意味着您需要本地虚拟化
- 否则,您可以使用 Storage Gateway 硬件设备
- 您可以在 amazon.com 上购买
- 可与文件网关、卷网关、磁带网关配合使用
- 拥有所需的CPU、内存、网络、SSD缓存资源
- 有助于小型数据中心的日常 NFS 备份
AWS Storage Gateway
AWS Transfer Family
- 使用 FTP 协议将文件传入和传出 Amazon S3 或 Amazon EFS 的完全托管服务
- 支持的协议
- AWS Transfer for FTP(文件传输协议 (FTP))
- AWS Transfer for FTPS(基于 SSL 的文件传输协议 (FTPS))
- AWS Transfer for SFTP(安全文件传输协议 (SFTP))
- 托管基础设施、可扩展、可靠、高可用性(多可用区)
- 按每小时每个配置端点付费 + 以 GB 为单位的数据传输
- 在服务中存储和管理用户的凭据
- 与现有身份验证系统集成(Microsoft Active Directory、LDAP、Okta、Amazon Cognito、自定义)
- 用途:共享文件、公共数据集、CRM、ERP…
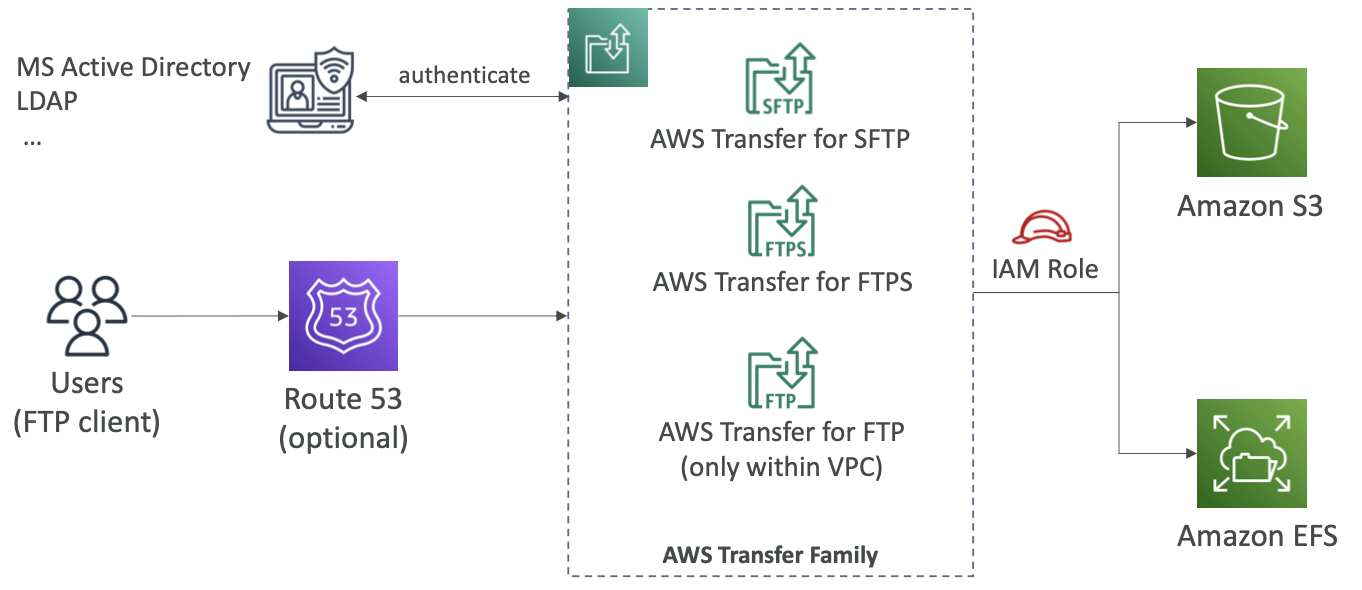
AWS DataSync
- 移入和移出大量数据
- 本地/其他云到 AWS(NFS、SMB、HDFS、S3 API…) – 需要代理
- AWS 到 AWS(不同的存储服务) – 无需代理
- 可以同步到:
- Amazon S3(任何存储类别 - 包括 Glacier)
- Amazon EFS
- Amazon FSx(Windows、Lustre、NetApp、OpenZFS…)
- 复制任务可以安排为每小时、每天、每周
- 保留文件权限和元数据(NFS POSIX、SMB…)
- 一个代理任务可以使用10 Gbps,可以设置带宽限制
NFS / SMB 到 AWS(S3、EFS、FSx…)
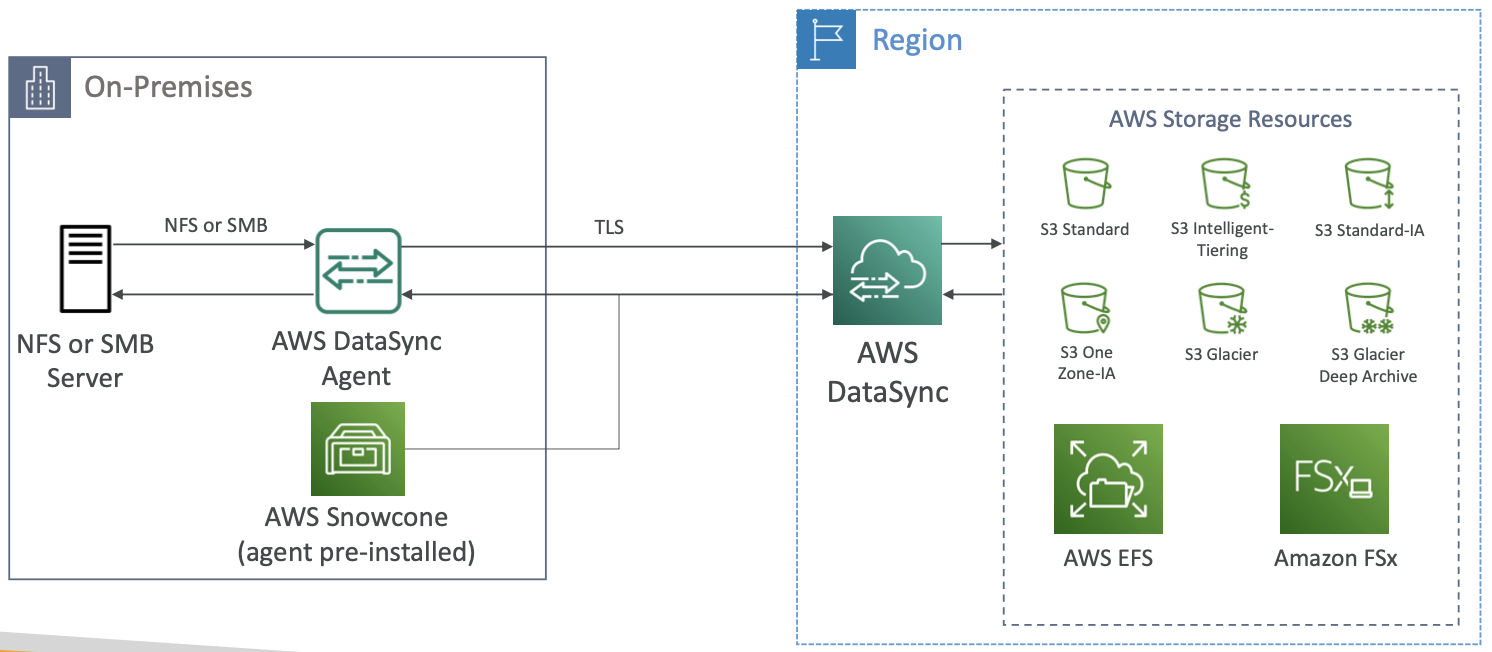
AWS 存储服务之间的传输
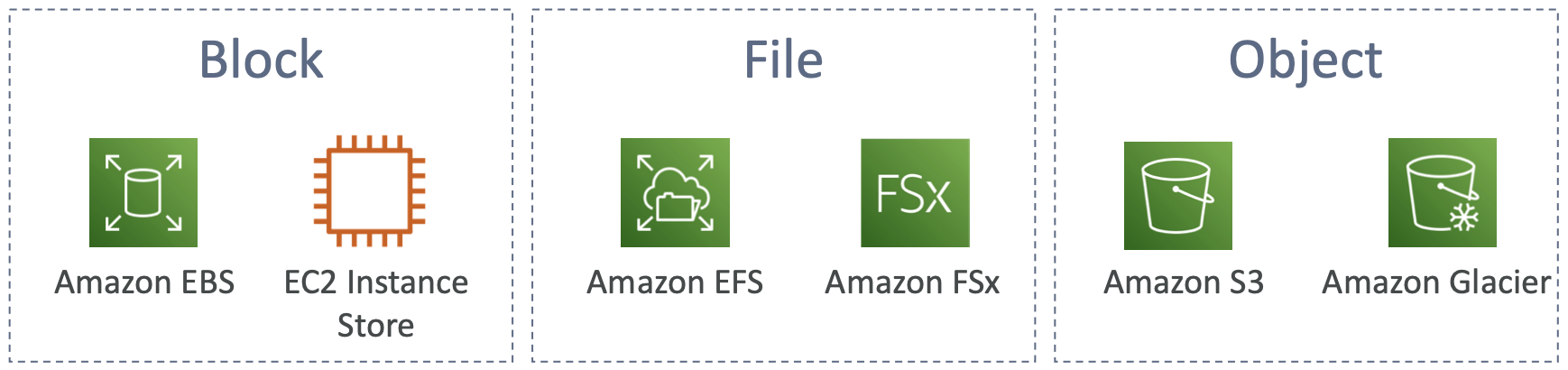
存储比较
- S3:对象存储
- S3 Glacier:对象档案
- EBS 卷:一次用于一个 EC2 实例的网络存储
- 实例存储:EC2 实例的物理存储(高 IOPS)
- EFS:Linux 实例的网络文件系统、POSIX 文件系统
- FSx for Windows:适用于 Windows 服务器的网络文件系统
- FSx for Lustre:高性能计算 Linux 文件系统
- 适用于 NetApp ONTAP 的 FSx:高操作系统兼容性
- FSx for OpenZFS:托管 ZFS 文件系统
- 存储网关:S3 和 FSx 文件网关、卷网关(缓存和存储)、磁带网关
- 传输系列:Amazon S3 或 Amazon EFS 之上的 FTP、FTPS、SFTP 接口
- 数据同步:安排从本地到 AWS 或 AWS 到 AWS 的数据同步
- Snowcone / Snowball / Snowmobile:以物理方式将大量数据移动到云端
- 数据库:针对特定工作负载,通常带有索引和查询
AWS 集成和消息传递
章节介绍
- 当我们开始部署多个应用程序时,它们将不可避免地需要相互通信
- 应用程序通信有两种模式:
- 同步通信(应用程序到应用程序)
- 异步/基于事件(应用程序到队列到应用程序)
- 如果流量突然激增,应用程序之间的同步可能会出现问题
- 如果您突然需要编码 1000 个视频但通常是 10 个怎么办?
- 在这种情况下,最好解耦你的应用程序,
- 使用SQS:队列模型
- 使用SNS:发布/订阅模型
- 使用Kinesis:实时流模型
- 这些服务可以独立于我们的应用程序进行扩展!

Amazon SQS - 什么是队列?
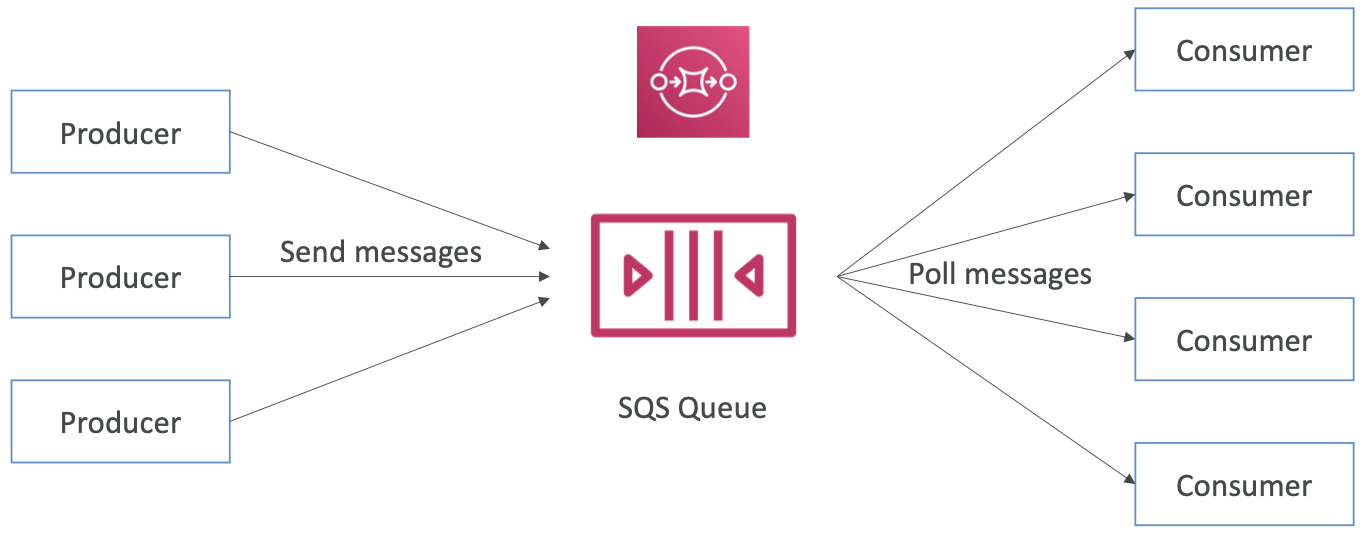
Amazon SQS – 标准队列
- 最旧的产品(超过 10 年)
- 完全托管的服务,用于解耦应用程序
- 属性:
- 无限吞吐量,无限队列中的消息数量
- 消息默认保留:4 天,最多 14 天
- 低延迟(发布和接收<10毫秒)
- 每条发送的消息限制为 256KB
- 可能有重复的消息(至少一次传递,偶尔)
- 消息可能无序(尽力而为)
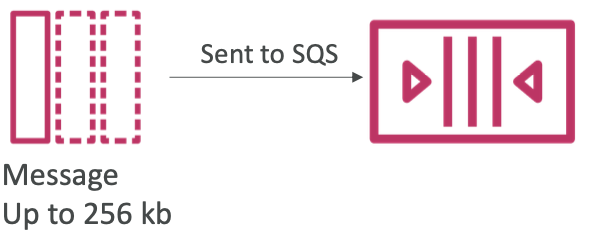
SQS 一 生成消息
- 使用 SDK(SendMessage API)生成到 SQS
- 消息保留在SQS中,直到消费者将其删除
- 消息保留:默认4天,最长14天
- 示例:发送要处理的订单
- 订单编号
- 客户ID
- 任何你想要的属性
- SQS标准:无限吞吐量
SQS 一 消费消息
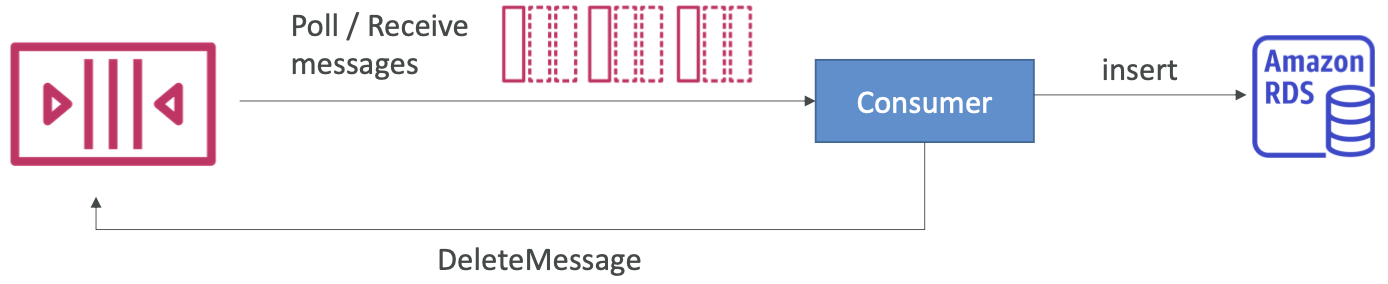
- 消费者(在 EC2 实例、服务器或 AWS Lambda 上运行)…
- 轮询 SQS 消息(一次最多接收 10 条消息)
- 处理消息(示例:将消息插入 RDS 数据库)
- 使用DeleteMessage API删除消息
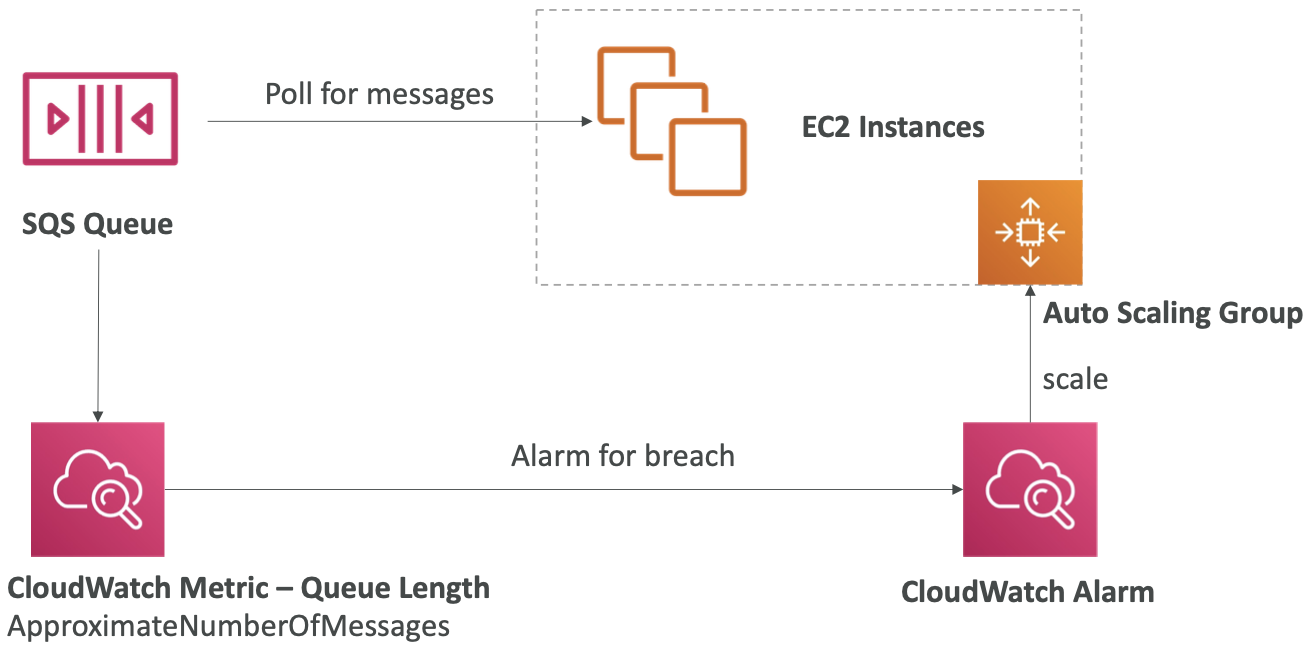
SQS – 多个 EC2 实例使用者
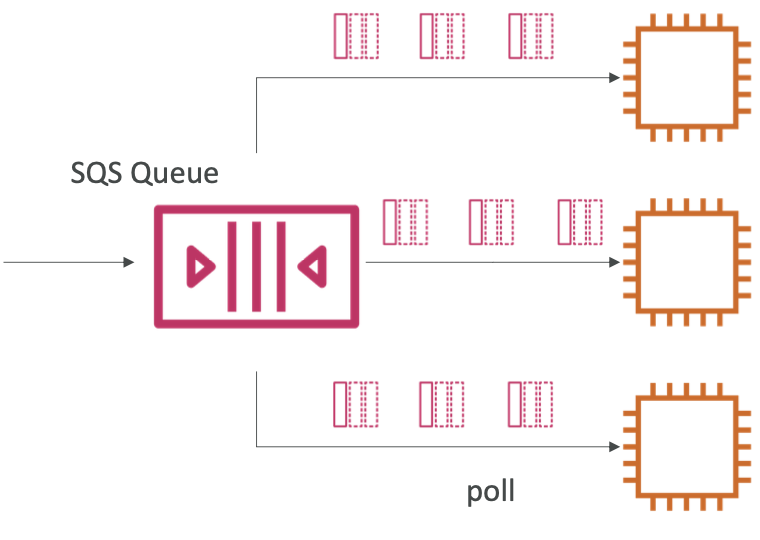
- 消费者并行接收和处理消息
- 至少一次交货
- 尽力而为的消息排序
- 消费者处理消息后删除消息
- 我们可以水平扩展消费者以提高处理吞吐量
SQS with Auto Scaling Group (ASG)
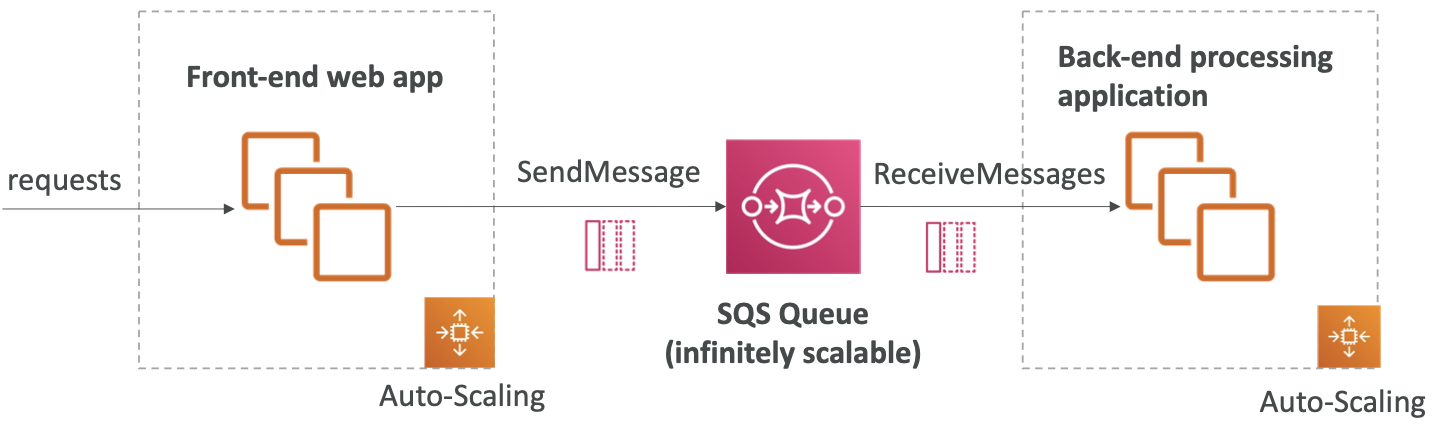
SQS 可以在应用程序层之间解耦
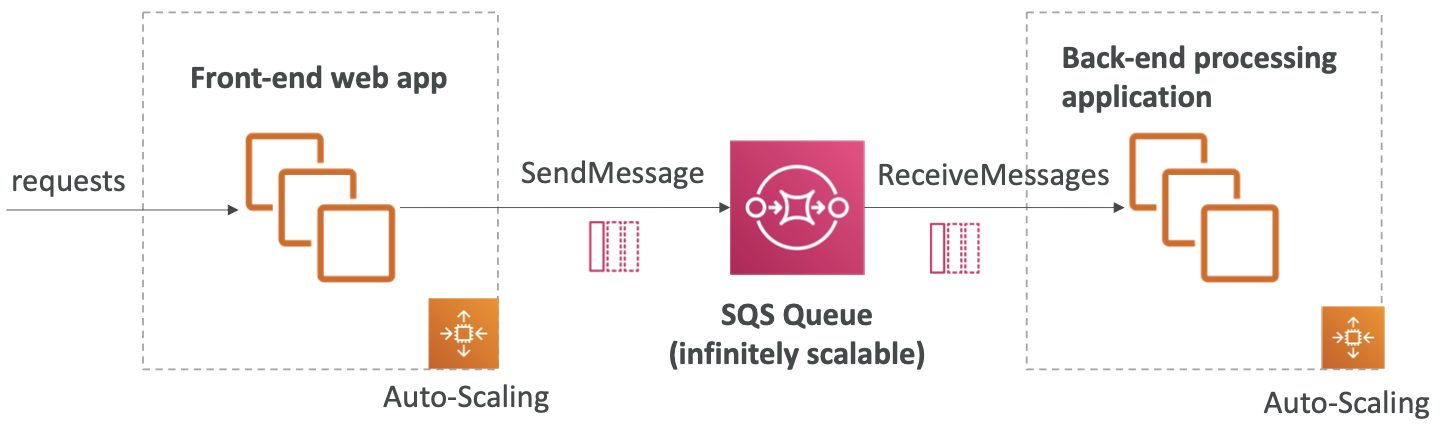
Amazon SQS - 安全
- 加密:
- 使用 HTTPS API 进行飞行加密
- 使用 KMS 密钥进行静态加密
- 客户端加密(如果客户端想要自己执行加密/解密)
- 访问控制:用于管理对 SQS API 访问的 IAM 策略
- SQS访问策略(类似于S3存储桶策略)
- 对于跨账户访问 SQS 队列很有用
- 用于允许其他服务(SNS、S3…)写入 SQS 队列
SQS – Message Visibility Timeout
- 消息被消费者轮询后,其他消费者将看不到该消息
- 默认情况下,“消息可见超时”为 30 秒
- 这意味着消息有 30 秒的时间来处理
- 消息可见性超时结束后,消息在 SQS 中“可见”
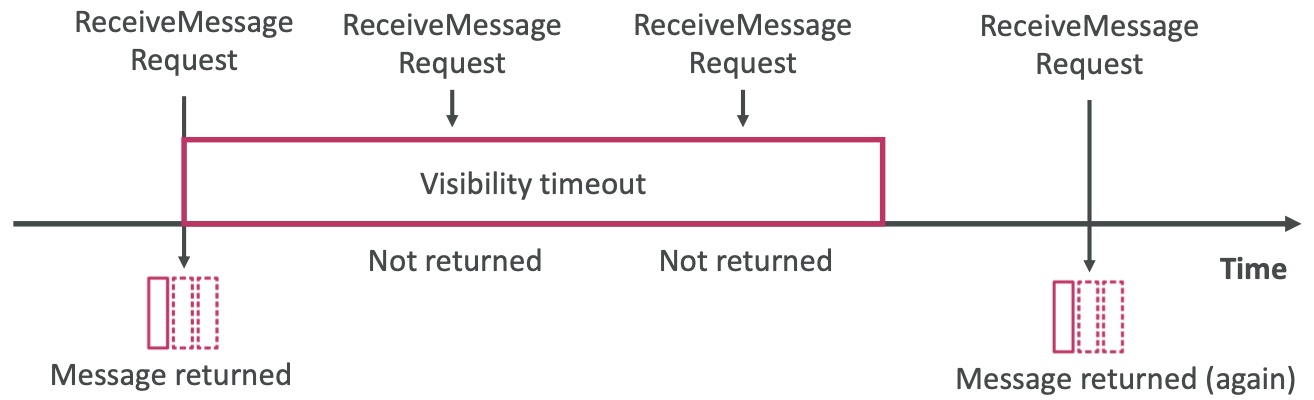
- 如果消息在可见性超时内没有被处理,它将被处理两次
- 消费者可以调用 ChangeMessageVisibility API 来获得更多时间
- 如果可见性超时很高(小时)并且消费者崩溃,重新处理将需要时间
- 如果可见性超时太低(秒),我们可能会得到重复项
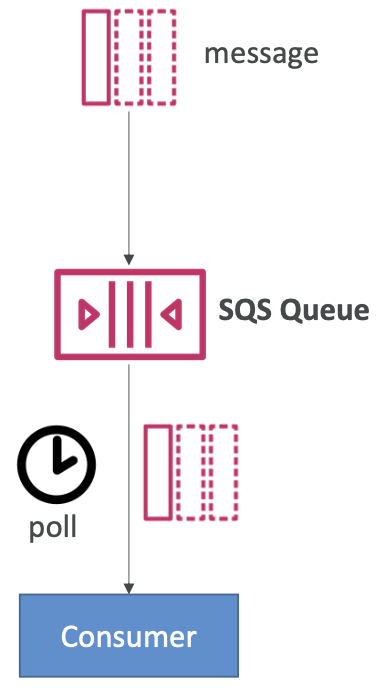
Amazon SQS - Long Polling
- 当消费者从队列中请求消息时,如果队列中没有消息,它可以选择“等待”消息到达
- 这称为长轮询
- LongPolling 减少了对 SQS 的 API 调用数量,同时提高了应用程序的效率并减少了延迟
- 等待时间可以在 1 秒到 20 秒之间(最好是 20 秒)
- 长轮询优于短轮询
- 可以使用 WaitTimeSeconds 在队列级别或 API 级别启用长轮询
Amazon SQS – FIFO Queue
- FIFO = 先进先出(队列中消息的排序)

- 吞吐量有限:不进行批处理时为 300 条消息/秒,使用批处理时为 3000 条消息/秒
- 一次性发送能力(通过删除重复项)
- 消息由消费者按顺序处理
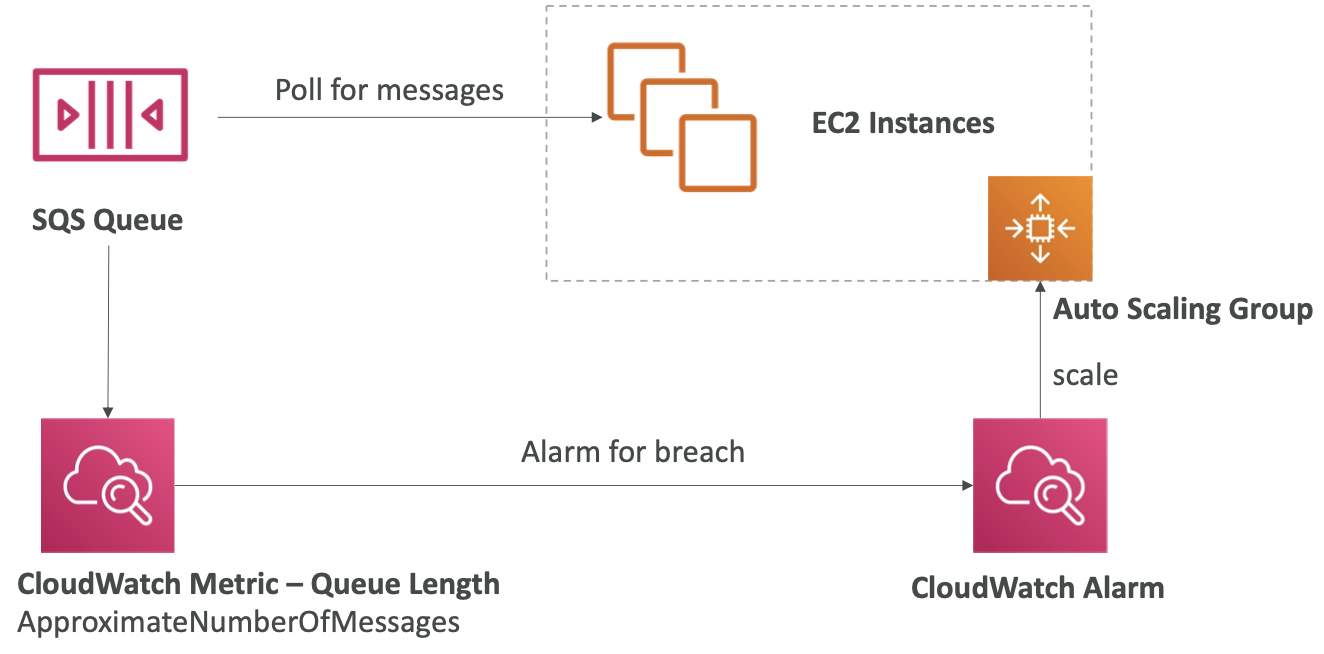
SQS with Auto Scaling Group (ASG)
如果负载过大,部分交易可能会丢失
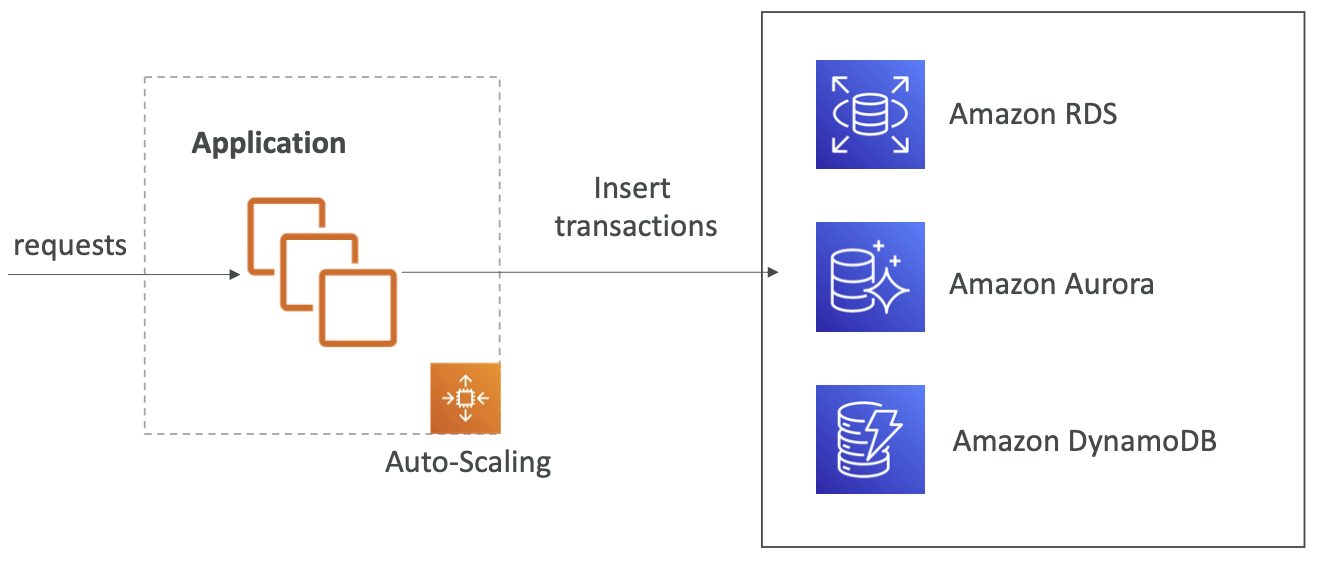
SQS 作为数据库写入的缓冲区
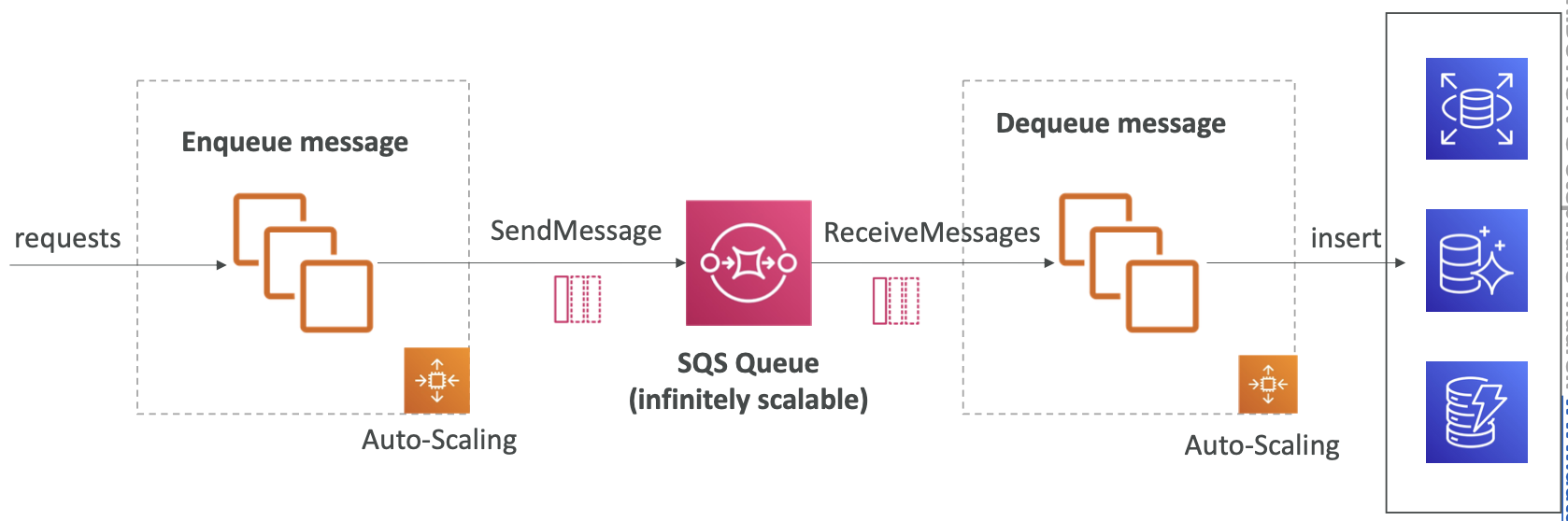
SQS 在应用程序层之间解耦
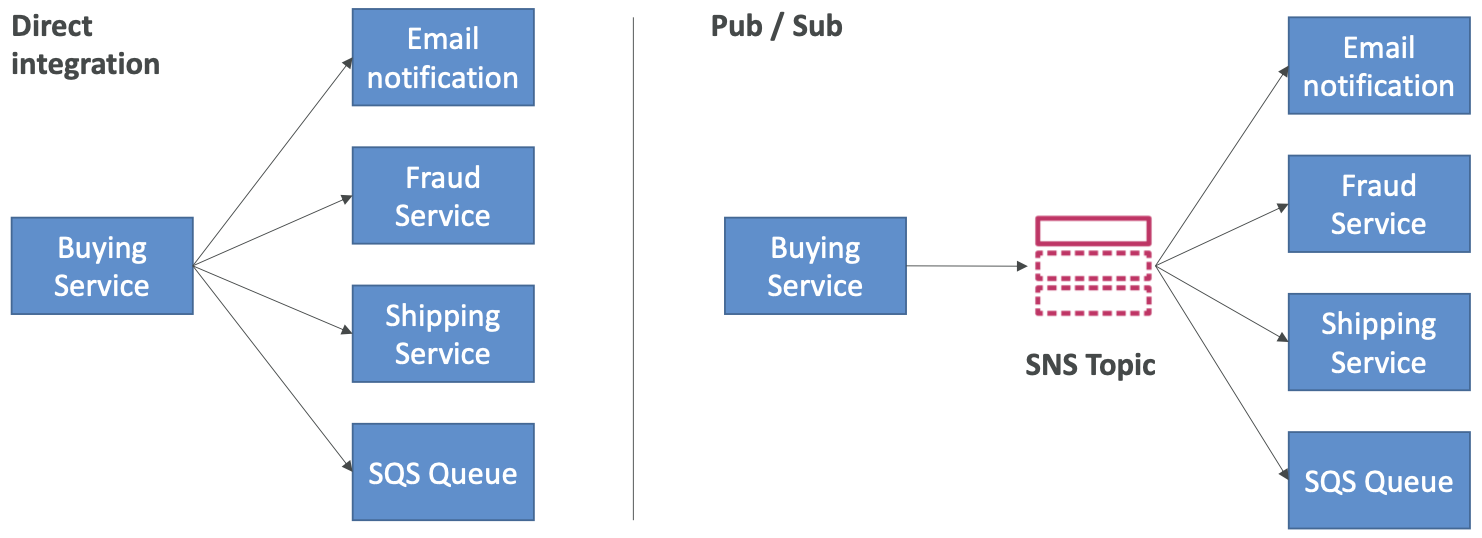
Amazon SNS
- 如果您想将一条消息发送给多个接收者怎么办?
- “事件生产者”仅向一个 SNS 主题发送消息
- 我们想要收听 SNS 主题通知就有多少个“事件接收者”(订阅)
- 每个主题订阅者都会收到所有消息(注意:过滤消息的新功能)
- 每个主题最多 12,500,000 个订阅
- 100,000 个主题限制
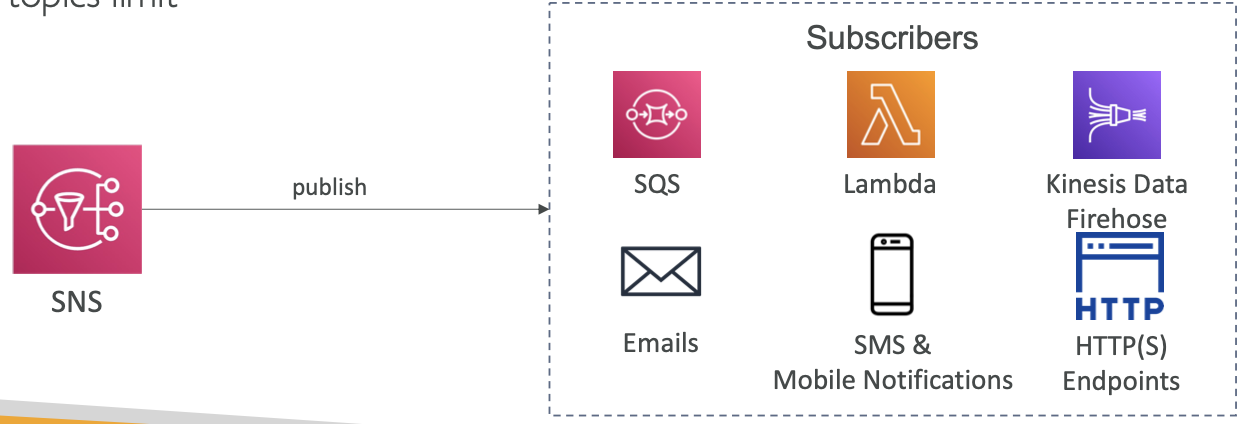
SNS 与 许多 AWS 服务集成
- 许多AWS服务可以直接将数据发送到SNS以进行通知
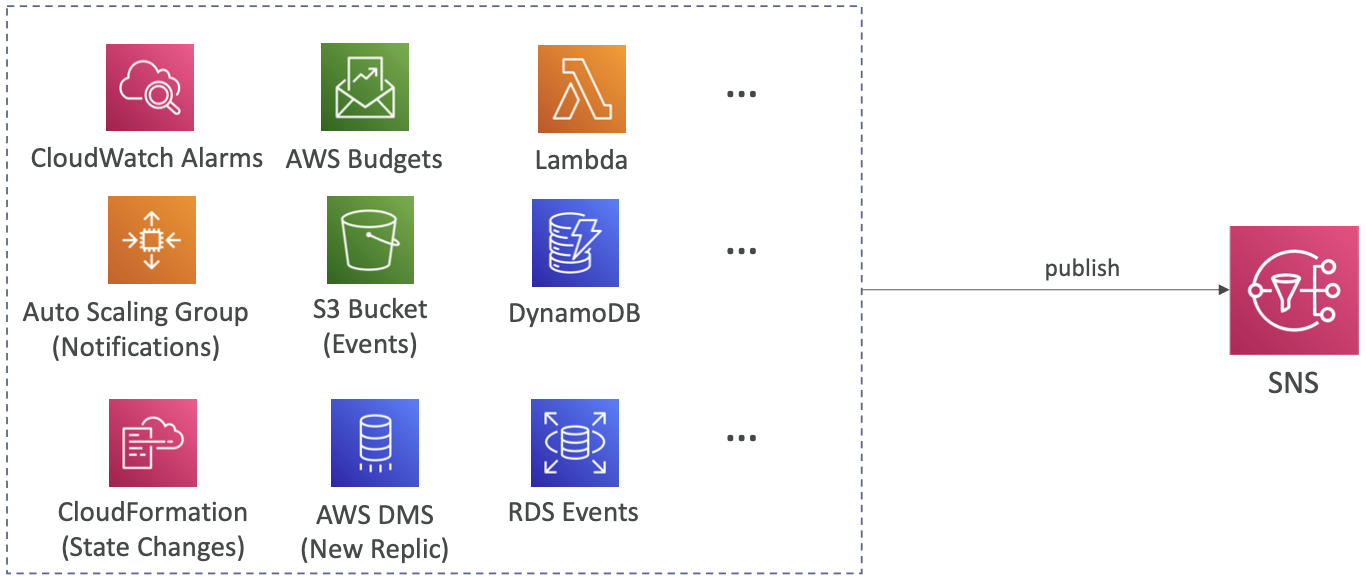
Amazon SNS – 如何发布
- 主题发布(使用SDK)
- 创建主题
- 创建订阅(或多个)
- 发布到主题
- 直接发布(用于移动应用程序SDK)
- 创建平台应用程序
- 创建平台端点
- 发布到平台端点
- 可与 Google GCM、Apple APNS、Amazon ADM 配合使用…
Amazon SNS – 安全
- 加密:
- 使用 HTTPS API 进行飞行加密
- 使用 KMS 密钥进行静态加密
- 客户端加密(如果客户端想要自己执行加密/解密)
- 访问控制:用于规范对 SNS API 访问的 IAM 策略
- SNS 访问策略(类似于 S3 存储桶策略)
- 对于跨帐户访问 SNS 主题很有用
- 用于允许其他服务(S3…)写入 SNS 主题
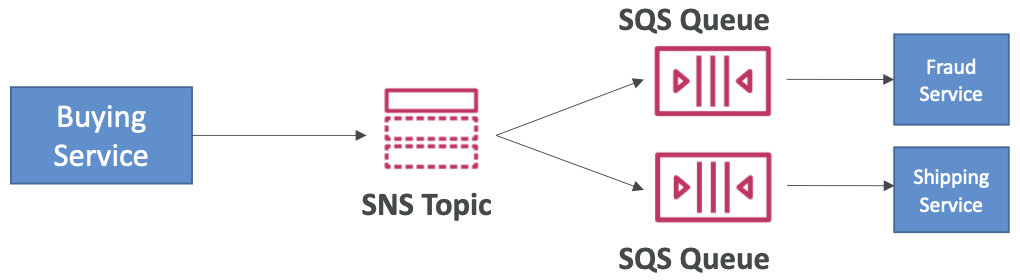
SNS + SQS:Fan Out (扇出)
- 在SNS中推送一次,在所有订阅者的SQS队列中接收
- 完全解耦,无数据丢失
- SQS 允许:数据持久性、延迟处理和工作重试
- 能够随着时间的推移添加更多 SQS 订阅者
- 确保您的 SQS 队列访问策略允许 SNS 写入
- 跨区域交付:与其他区域的 SQS 队列配合使用
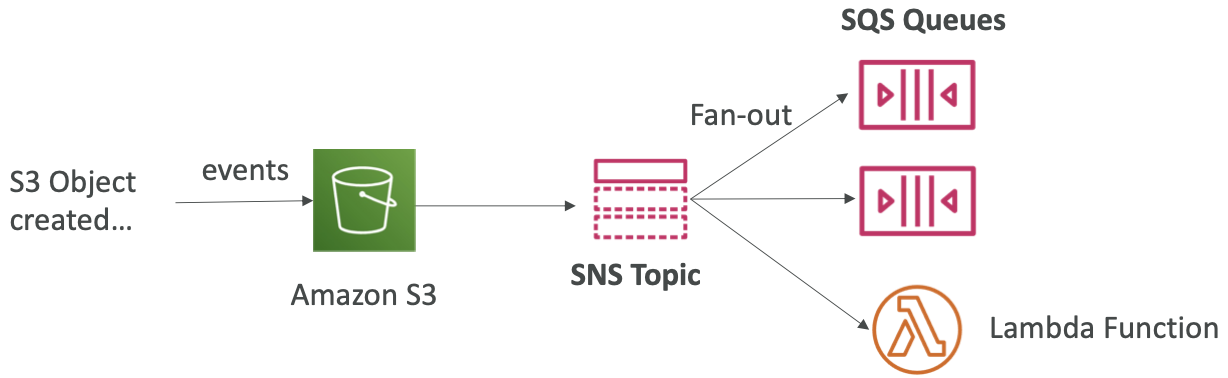
应用:S3 事件到多个队列
- 对于相同的组合:事件类型(例如对象创建)和前缀
(例如 images/)您只能有一个 S3 事件规则 - 如果您想将相同的S3事件发送到多个SQS队列,请使用扇出
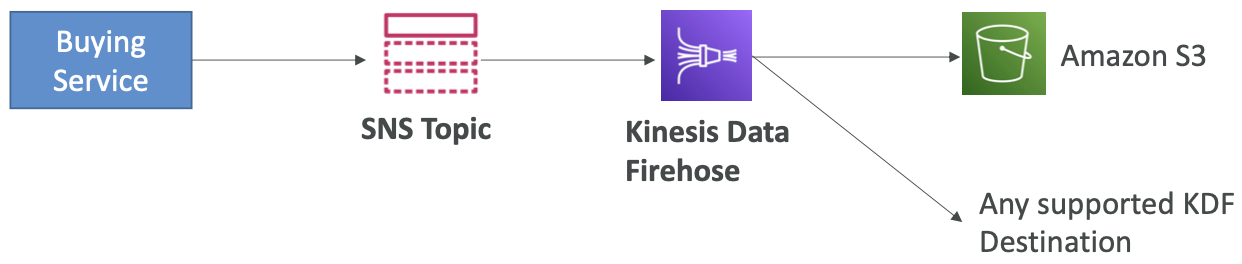
应用程序:通过 Kinesis Data Firehose SNS 到 Amazon S3
- SNS 可以发送到 Kinesis,因此我们可以拥有以下解决方案架构:
Amazon SNS – FIFO topic
- FIFO = 先进先出(topic 中的消息排序)

- 与 SQS FIFO 类似的功能:
- 按消息组 ID 排序(同一组中的所有消息均排序)
- 使用重复数据删除 ID 或基于内容的重复数据删除
- 只能将 SQS FIFO 队列作为订阅者
- 吞吐量有限(与 SQS FIFO 相同的吞吐量)
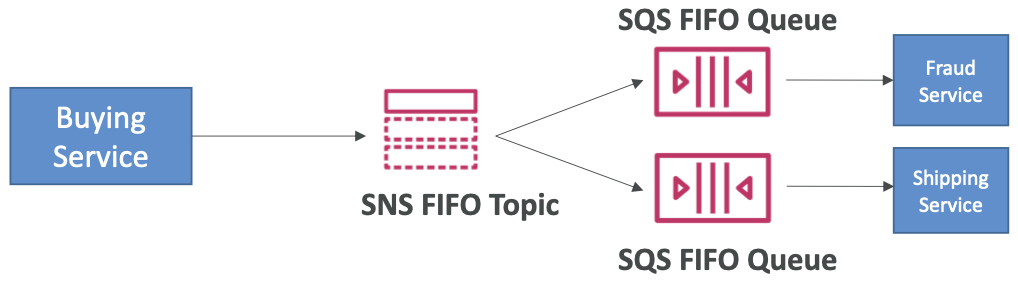
SNS FIFO + SQS FIFO:扇出
- 如果您需要扇出+排序+重复数据删除
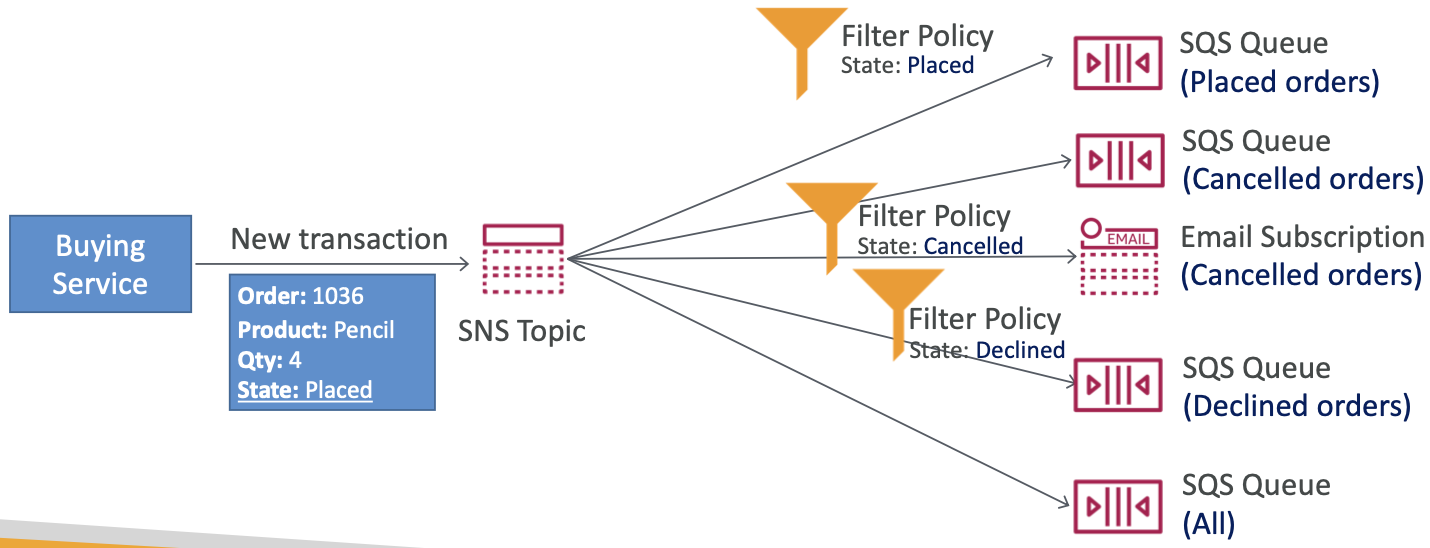
SNS – 消息过滤
- JSON 策略用于过滤发送到 SNS topic 订阅的消息
- 如果订阅没有过滤策略,它会收到每条消息
Kinesis 概述
- 轻松实时收集、处理和分析流数据
- 摄取实时数据,例如:应用程序日志、指标、网站点击流、物联网遥测数据…
- Kinesis Data Streams:捕获、处理和存储数据流
- Kinesis Data Firehose:将数据流加载到 AWS 数据存储中
- Kinesis Data Analytics:使用 SQL 或 Apache Flink 分析数据流
- Kinesis Video Streams:捕获、处理和存储视频流
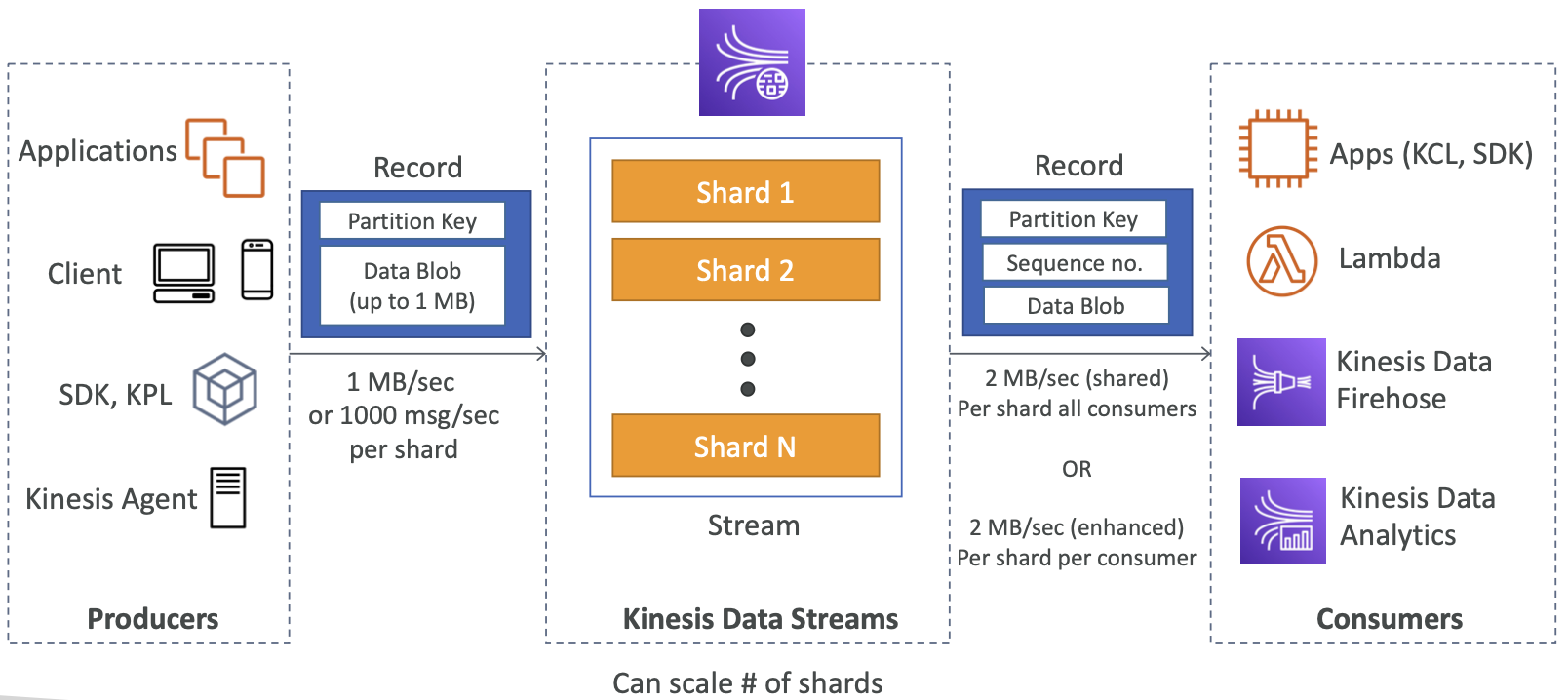
Kinesis Data Streams
- 保留 1 天至 365 天
- 能够重新处理(重放)数据
- 数据一旦插入 Kinesis,就无法删除(不变性)
- 共享同一分区的数据进入同一分片(排序)
- 生产者:AWS SDK、Kinesis Producer Library (KPL)、Kinesis Agent
- 消费者:
- 编写您自己的:Kinesis 客户端库 (KCL)、AWS SDK
- 托管:AWS Lambda、Kinesis Data Firehose、Kinesis Data Analytics、
Kinesis Data Streams – Capacity Modes
- Provisioned(配置)模式:
- 您可以选择配置的分片数量、手动扩展或使用 API
- 每个分片的速度为 1MB/s(或每秒 1000 条记录)
- 每个分片的输出速度为 2MB/s(经典或增强型扇出消费者)
- 您按每小时配置的分片付费
- On-demand(点播)模式:
- 无需配置或管理容量
- 配置默认容量(4 MB/秒或每秒 4000 条记录)
- 根据过去 30 天内观察到的吞吐量峰值自动扩展
- 按每小时流和按 GB 数据输入/输出付费
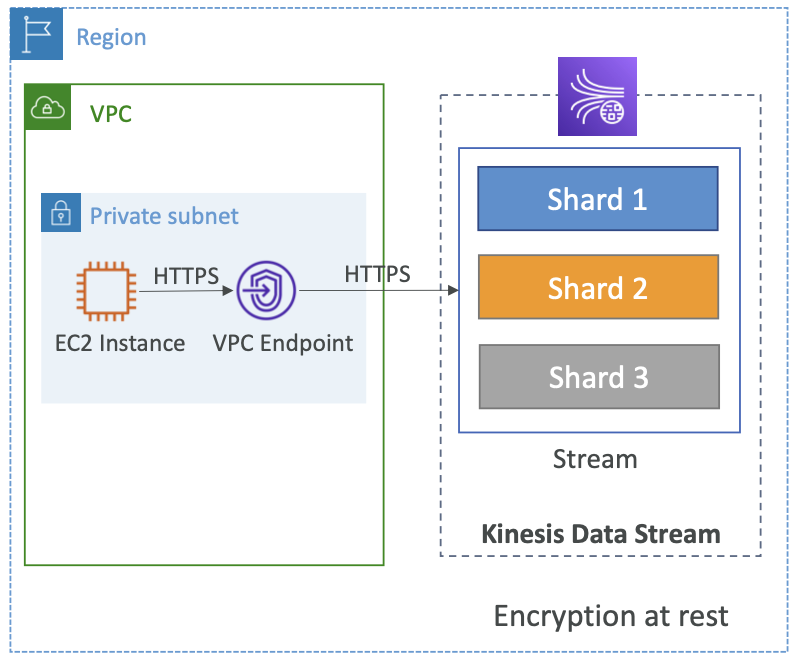
Kinesis Data Streams 安全
- 使用 IAM 策略控制访问/授权
- 使用 HTTPS 端点进行动态加密
- 使用 KMS 静态加密
- 您可以在客户端实现数据的加密/解密(较难)
- VPC 端点可供 Kinesis 在 VPC 内访问
- 使用 CloudTrail 监控 API 调用
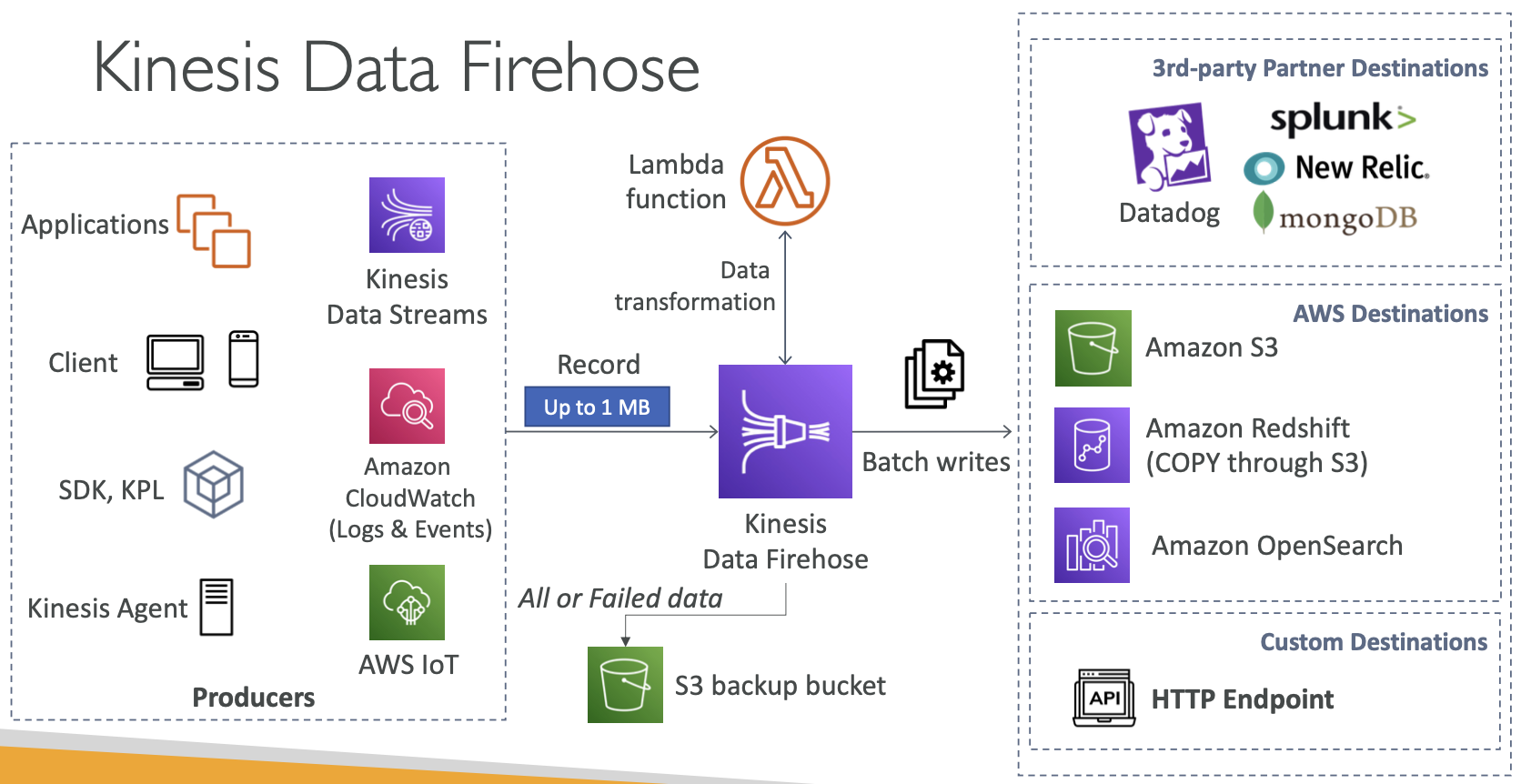
Kinesis Firehose
- 完全托管服务,无需管理,自动扩展,无服务器
- AWS:Redshift / Amazon S3 / OpenSearch
- 第 3 方合作伙伴:Splunk / MongoDB / DataDog / NewRelic / …
- 自定义:发送到任何 HTTP 端点
- 为通过 Firehose 的数据付费
- 近乎实时
- 非完整批次的最低延迟为 60 秒
- 每次至少 1MB 数据
- 支持多种数据格式、转换、转换、压缩
- 支持使用 AWS Lambda 进行自定义数据转换
- 可以将失败或所有数据发送到备份 S3 存储桶
Kinesis Data Streams vs Firehose
Kinesis Data Streams
- 用于大规模摄取的流媒体服务
- 编写自定义代码(生产者/消费者)
- 实时(~200 毫秒)
- 管理扩展(分片拆分/合并)
- 数据存储1至365天
- 支持重播功能
Kinesis Data Firehose
- 将流数据加载到 S3 / Redshift / OpenSearch / 3rd party / 自定义 HTTP
- 完全托管
- 近乎实时(缓冲时间最少 60 秒)
- 自动缩放
- 无数据存储
- 不支持重播功能
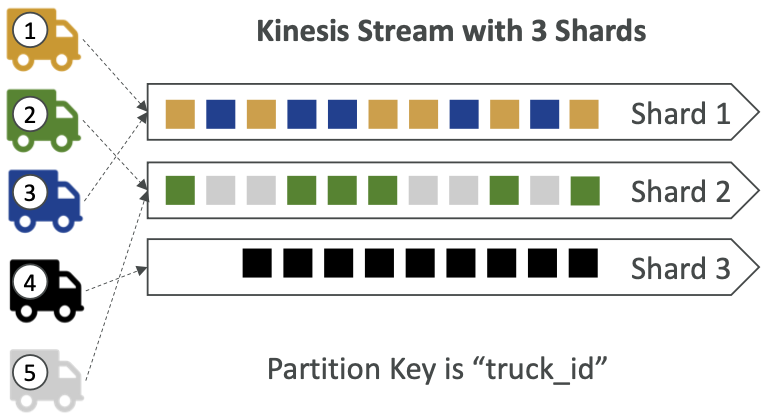
将数据排序到 Kinesis 中
- 假设您有 100 辆卡车(truck_1、truck_2、…truck_100)在路上定期将其 GPS 位置发送到 AWS。
- 您想要按顺序使用每辆卡车的数据,以便您可以准确跟踪它们的移动。
- 您应该如何将该数据发送到 Kinesis?
- 答案:使用“truck_id”的“分区键”值发送
- 相同的密钥将始终进入相同的分片
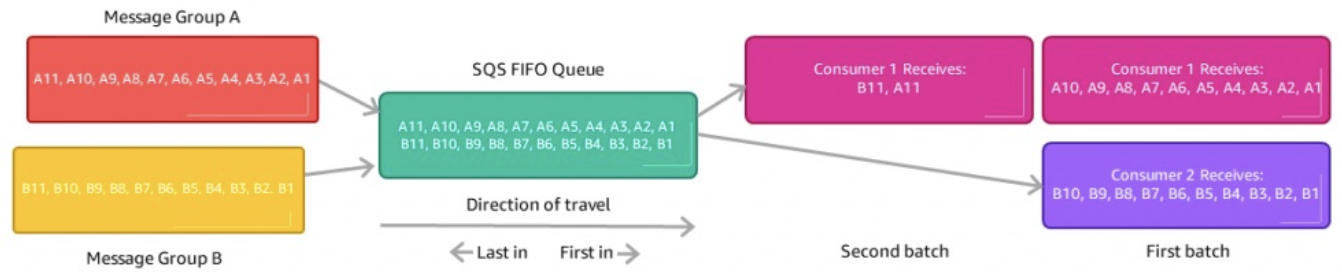
将数据排序到 SQS 中
- 对于 SQS 标准,数据是无序的
- 对于 SQS FIFO,如果不使用 Group ID,消息将按照发送的顺序被消费,只有一个消费者

- 您想要扩大消费者的数量,但希望消息在彼此相关时能够“分组”
- 然后使用组 ID(类似于 Kinesis 中的分区键)
Kinesis 与 SQS 排序
- 假设有 100 辆卡车、5 个 kinesis 分片、1 个 SQS FIFO
- Kinesis 数据流:
- 平均每个分片有 20 辆卡车
- 卡车的数据将在每个分片中排序
- 我们可以拥有的最大并行消费者数量是 5
- 可以接收高达 5 MB/s 的数据
- SQS 先进先出
- 你只有一个SQS FIFO队列
- 您将拥有 100 个群组 ID
- 您最多可以有 100 个消费者(由于有 100 个组 ID)
- 每秒最多有 300 条消息(如果使用批处理则为 3000 条)
SQS vs SNS vs Kinesis
SQS
- 消费者“拉数据”
- 数据被消耗后被删除
- 可以拥有任意数量的工人(消费者)
- 无需配置吞吐量
- 仅在 FIFO 队列上保证排序
- 单独的消息延迟能力
SNS
- 将数据推送给许多订阅者
- 多达 12,500,000 名订户
- 数据不持久(如果未交付就会丢失)
- 酒吧/订阅者
- 多达 100,000 个主题
- 无需配置吞吐量
- 与 SQS 集成以实现扇出架构模式
- SQS FIFO 的 FIFO 功能
Kinesis
- 标准:拉取数据 - 每个分片 2 MB
- 增强扇出:推送数据 - 每个消费者每个分片 2 MB
- 可以重播数据
- 适用于实时大数据、分析和 ETL
- 在分片级别排序
- 数据在 X 天后过期
- 预配置模式或按需容量模式
Amazon MQ
- SQS、SNS 是“云原生”服务:来自 AWS 的专有协议
- 从本地运行的传统应用程序可能使用开放协议,例如:MQTT、AMQP、STOMP、Openwire、WSS
- 迁移到云时,我们可以使用 Amazon MQ,而不是重新设计应用程序以使用 SQS 和 SNS
- Amazon MQ 是 RabbitMQ 或 ActiveMQ 的托管消息代理服务
- Amazon MQ 的“扩展性”不如 SQS / SNS
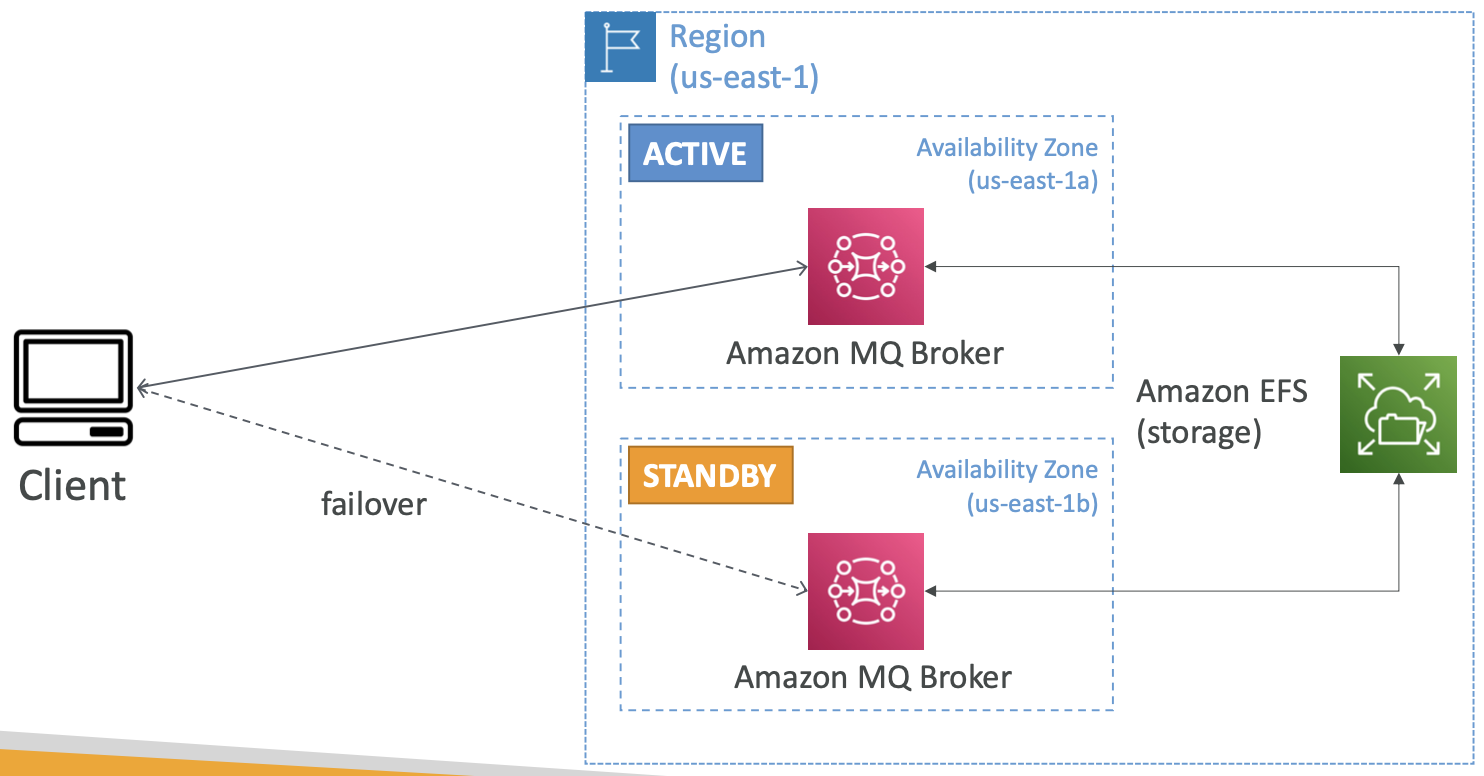
- Amazon MQ 在服务器上运行,可以在多可用区中运行并进行故障转移
- Amazon MQ 具有队列功能 (~SQS) 和主题功能 (~SNS)
Amazon MQ – 高可用性