论文阅读笔记AI篇 —— Transformer模型理论+实战 (四)
- 一、理论
- 1.1 理论研读
- 1.2 什么是AI Agent?
- 二、实战
- 2.1 先导知识
- 2.1.1 tensor的创建与使用
- 2.1.2 PyTorch的模块
- 2.1.2.1 torch.nn.Module类的继承与使用
- 2.1.2.2 torch.nn.Linear类
- 2.2 Transformer代码实现
一、理论
1.1 理论研读
| 参考文章或视频链接 |
|---|
| [1] 《论文阅读笔记AI篇 —— Transformer模型理论+实战 (一)》- CSDN |
| [2] 《论文阅读笔记AI篇 —— Transformer模型理论+实战 (二)》- CSDN |
| [3] 《论文阅读笔记AI篇 —— Transformer模型理论+实战 (三)》- CSDN |
1.2 什么是AI Agent?
如果说钢铁侠中的
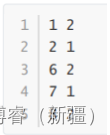
J.A.R.V.I.S.(贾维斯)是一个AGI通用人工智能的话,那么现阶段的AI Agent只是做到了感知任务、规划任务、执行任务。下面这张图的这个过程,看上去和强化学习是一模一样的。
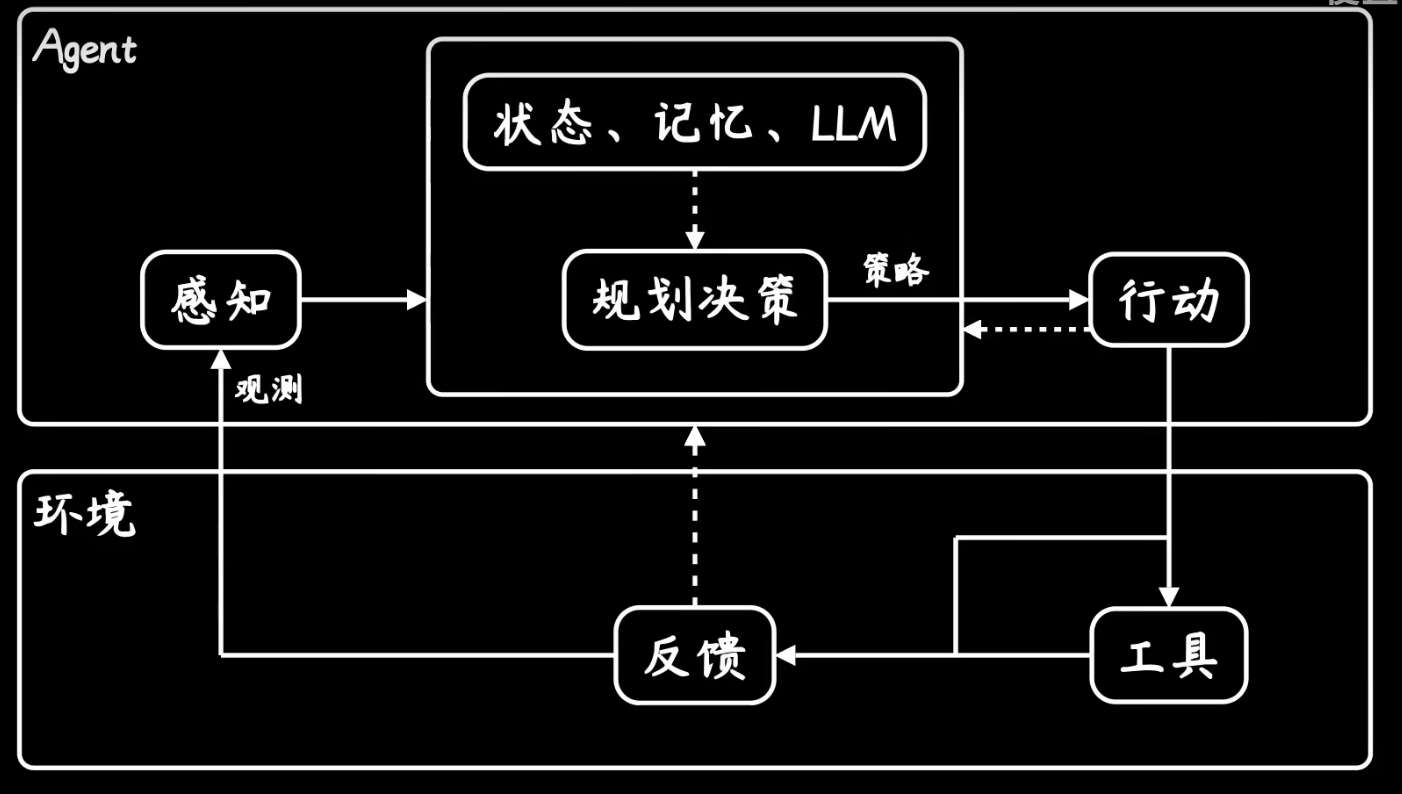
Agent结构图——参考视频[1]
| 参考文章或视频链接 |
|---|
| [1]【动画科普AI Agent:大模型之后为何要卷它?】- bilibili |
| [2]【【卢菁老师说】Agent就是一场彻头彻尾的AI泡沫】- bilibili |
| [3] 《读懂AI Agent:基于大模型的人工智能代理》 |
| [4] LLM之Agent(一):使用GPT-4开启AutoGPT Agent自动化任务完整指南 |
二、实战
2.1 先导知识
2.1.1 tensor的创建与使用
对于一维的tensor,它是没有形状而言的,你不能准确的称它为行向量row vector或列向量col vector,只有你明确的指定之后,它才有准确的形状。
但是,在数学中肯定是要有明确的意义的,要么n*1,要么1*n,总得有个说法,说法就是,认为是列向量n*1,见参考文章[2]。
import torch
import torch.nn as nn
def test1_tensor():
x = torch.tensor([1, 1, 1, 1])
print("Before reshape:", x.shape)
# x = x.reshape(4, 1)
x = x.view(4, 1) # 与reshape一样
print(x)
print("After reshape(4,1):", x.shape)
# x = x.reshape(1, 4)
x = x.view(1, 4) # 与reshape一样
print(x)
print("After reshape(1,4):", x.shape)
if __name__ == '__main__':
test1_tensor()
"""Console Output
Before reshape: torch.Size([4])
tensor([[1],
[1],
[1],
[1]])
After reshape(4,1): torch.Size([4, 1])
tensor([[1, 1, 1, 1]])
After reshape(1,4): torch.Size([1, 4])
"""
| 参考文章或视频链接 |
|---|
| [1] Introduction to PyTorch Tensors - PyTorch |
| [2] Is there any reason for using the word “column” in the context of one-dimensional tensor? |
2.1.2 PyTorch的模块
2.1.2.1 torch.nn.Module类的继承与使用
强调一点,你自己实现的所有模块,应该都是继承了nn.Module这个Class的(这也是PyTorch官方文档所强调的),不要觉得可以去掉nn.Module的继承,继承了这个类,才会有一些便捷的方法可供调用,否则你都要自己实现一遍。
class Encoder(nn.Module): # (1)Encoder继承了nn.Module
def __init__(self):
# ...
def forward(self, enc_inputs): # 你不需要显示调用该方法,因为在nn.Module.__call__里,已经默认实现了对该方法的调用
# ...
class Decoder(nn.Module): # (2)Decoder继承了nn.Module
def __init__(self):
# ...
def forward(self, dec_inputs, enc_inputs, enc_outputs): # 你不需要显示调用该方法,因为在nn.Module.__call__里,已经默认实现了对该方法的调用
# ...
| 参考文章或视频链接 |
|---|
| [1] Module — PyTorch 2.1 documentation |
| [2] Learning Day 22: What is nn.Module in Pytorch |
| [3] Why do we need to inherit from nn.Module in PyTorch? - stackoverflow |
2.1.2.2 torch.nn.Linear类
关于Linear层有一点问题,就是它的权重矩阵,nn.Linear(4,3)中的4表示输入特征的维度,3表示输出特征的维度,按理来说是一个4 * 3的矩阵才对,但是输出结果偏不,这是因为常规的线性运算是写成这样的(假设维度已知),
o
u
t
=
W
3
∗
4
i
n
4
∗
1
+
b
3
∗
1
out = W_{3*4}in_{4*1} + b_{3*1}
out=W3∗4in4∗1+b3∗1,但网络层以从左至右的视角看去,
i
n
in
in在
W
W
W矩阵的左边,写成这样的形式
o
u
t
=
(
i
n
1
∗
4
W
3
∗
4
T
)
T
+
b
3
∗
1
=
(
i
n
1
∗
4
W
4
∗
3
)
T
+
b
3
∗
1
out = (in_{1*4}W_{3*4}^T)^T + b_{3*1} = (in_{1*4}W_{4*3})^T + b_{3*1}
out=(in1∗4W3∗4T)T+b3∗1=(in1∗4W4∗3)T+b3∗1就很自然的模拟了这个视角,这样就能解释为什么输出的shape是反过来的。

请看参考文章[1]。
import torch
import torch.nn as nn
def test2_Linear_weight():
linear_layer = nn.Linear(4,3)
print(linear_layer.shape) # torch.Size([3, 4])
if __name__ == '__main__':
test2_Linear_weight()
| 参考文章或视频链接 |
|---|
| [1] Why does PyTorch’s Linear layer store the weight in shape (out, in) and transpose it in the forward pass? - stackoverflow |
2.2 Transformer代码实现
请看参考文章[1],我认为写的足够详细,也足够易懂,有些torch.transpose()的操作不太好从字面上读懂,就debug看看,无非就是高维矩阵的转置,和二维矩阵的转置也没本质区别。
| 参考文章或视频链接 |
|---|
| 本文代码来源:[1] 《Transformer 代码详解(Pytorch版)》- CSDN |
| [2] 【Transformer代码实现】- bilibili |
| 重点观看此视频:[3] [重置版]从零实现transfomer模型 || 理解ChatGPT基石 || pytorch- bilibili |