来源:投稿 作者:橡皮
编辑:学姐

论文链接:https://arxiv.org/abs/2303.09553
项目主页:https://lerf.io](https://lerf.io

图 1:语言嵌入辐射场 (LERF)。 LERF 将 CLIP 表示建立在密集、多尺度的 3D 场中。 LERF 可以在 45 分钟内从手持电话的捕获中重建,然后可以根据实时交互式文本查询呈现密集的相关性地图。 LERF 允许通过自然语言查询广泛的概念,从“电力”等抽象查询、“黄色”等视觉属性、“Waldo”等长尾对象,甚至阅读杯子上的“Boops”等文本。对于每个提示,都会渲染 RGB 图像和相关性图,重点关注具有最大相关性激活的位置。
摘要:
人类使用自然语言来描述物理世界,并根据视觉外观、语义、抽象关联或可操作性等多种属性来指代特定的三维位置。在这项工作中,我们提出了语言嵌入辐射场(LERFs),这是一种将现成模型(如 CLIP)中的语言嵌入到 NeRF 中的方法,可以在 3D 中实现这类开放式语言查询。LERF 通过沿训练射线对 CLIP 嵌入进行体积渲染,在 NeRF 中学习密集的多尺度语言场,并在训练视图中对这些嵌入进行监督,以提供多视图一致性并平滑底层语言场。经过优化后,LERF 可以为各种语言提示实时交互地提取三维相关性地图,这在机器人、理解视觉语言模型以及与三维场景交互方面具有潜在的应用案例。LERF 可对提炼出的三维 CLIP 嵌入进行像素对齐、零点查询,而无需依赖区域建议或掩码,支持在整个体素中分层进行长尾开放词汇查询。
1.引言
神经辐射场(NeRFs)已成为捕捉现实世界复杂三维场景逼真数字表现的强大技术。然而,NeRFs 的直接输出只是一个五颜六色的密度场,没有任何意义或上下文,这阻碍了与生成的三维场景交互界面的构建。
自然语言是与三维场景交互的直观界面。请看图 1 中对厨房的捕捉。想象一下,您可以通过询问 "餐具 "在哪里,或者更具体地说,询问您可以用来 "搅拌 "的工具,甚至询问您最喜欢的印有特定标志的杯子,来浏览这个厨房--所有这一切都可以通过舒适而熟悉的日常对话来实现。这不仅需要处理自然语言输入查询的能力,还需要在多个尺度上纳入语义并与长尾和抽象概念相关联的能力。
在这项工作中,我们提出了语言嵌入式辐射场(LERF),这是一种新颖的方法,通过将现成的视觉语言模型(如 CLIP)优化嵌入到 3D 场景中,从而在 NeRF 中建立语言标定。值得注意的是,LERF 直接利用 CLIP,无需通过 COCO 等数据集进行微调,也无需依赖遮罩区域锚点,这就限制了捕捉各种语义的能力。由于 LERF 保留了多尺度 CLIP 嵌入的完整性,因此它能够处理广泛的语言查询,包括视觉属性("黄")、抽象概念("电")、文本("boops")和长尾对象("waldo"),如图 1 所示。
我们通过与 NeRF 共同优化语言场来构建 LERF,该语言场将位置和物理比例作为输入,并输出单一的 CLIP 向量。在训练过程中,语言场使用多尺度特征金字塔进行监督,该金字塔包含由训练视图的图像裁剪生成的 CLIP 嵌入。这样,CLIP 编码器就能捕捉不同尺度的图像上下文,从而将相同的三维位置与不同尺度的不同语言嵌入关联起来(例如,"餐具 "与 "木勺")。在测试过程中,可以在任意尺度上查询语言场,从而获得三维相关性地图。为了规范优化后的语言场,还通过共享瓶颈纳入了自监督 DINO特征。
LERF 还有一个额外的优势:由于我们从多个视图中提取多个尺度的 CLIP 嵌入,因此通过三维 CLIP 嵌入获得的文本查询相关性图与通过二维 CLIP 嵌入获得的相关性图相比,更加本地化。根据定义,它们也是三维一致的,可以直接在三维领域中进行查询,而无需渲染到多个视图。
LERF 可以在不明显降低基本 NeRF 实现速度的情况下进行训练。完成训练过程后,LERF 就能为各种语言提示实时生成三维相关性地图。我们评估了 LERF 在一组手持捕捉的野外场景中的能力,发现它既能定位与几何体高度特定部分("手指")相关的细粒度查询,也能定位与多个对象("卡通")相关的抽象查询。LERF 可以在各种查询和场景中生成视图一致的三维相关性地图,我们网站上的视频是观看这些地图的最佳方式。我们还通过将 LSeg特征提炼成 3D,并从渲染的新颖视图中查询 OWL-ViT 来与流行的 open-vocab 检测器 LSeg和 OWL-ViT进行定量评估。我们的研究结果表明,LERF 的三维特征可以定位野外场景中的各种查询。LERF 的零样本功能为机器人、分析视觉语言模型以及与 3D 场景交互提供了潜在的用例。
2.背景
开放词汇物体检测: 有许多方法都在研究根据自然语言提示检测二维图像中的物体。这些方法的范围很广,从纯粹的零拍摄到完全在分割数据集上训练。LSeg在标注的分割数据集上训练二维图像编码器,输出与给定像素上分割标签的 CLIP 文本嵌入最匹配的像素嵌入。CRIS和 CLIPSeg基于查询的 CLIP 嵌入和预训练的 CLIP 图像编码器的中间输出,训练二维图像解码器以输出相关性图。不过,这种微调方法往往会因为在较小的数据集上进行训练而丧失大量语言能力。
针对二维图像的另一种常见方法是一个两阶段框架,其中类无关的区域或掩码建议将指导在何处查询开放词汇分类模型。OpenSeg在预测每个掩码的文本嵌入时同时学习掩码预测模型,而 ViLD则直接使用 CLIP从类别无关的掩码建议网络中对二维区域进行分类。Detic建立在现有的两阶段物体检测器方法基础上,但通过允许检测器分类器使用图像分类数据进行训练,展示了更强的泛化能力。OWL-ViT在预训练的二维图像编码器后附加了轻量级物体分类和定位头。虽然基于区域建议的方法可以利用更多的检测数据,但这些建议生成器仍倾向于在训练集分布范围内输出。因此,正如 OV-Seg的作者所指出的那样,这类网络在准确分割原始掩膜中未标记的分层组件(如物体部分)时往往会遇到困难。LERF 通过将语言嵌入到一个允许分层文本查询的密集、三维、多尺度场中,努力避免区域查询。
Grad-CAM和基于注意力的方法在视觉语言模型(如 CLIP)中提供了二维图像与文本之间的相关性映射。语义抽象等作品表明,这些框架可用于检测长尾对象,以促进场景理解。LERF 的输出结果在精神上与这些方法最为相似,都是根据查询结果输出三维相关性评分。不过,LERF 建立的三维表示法可以用不同的文本提示进行查询,而无需每次都重建底层表示法,此外,它还能将多个视角融合到一个共享场景表示法中,而不是按图像进行操作。
将二维特征提炼为 NeRF: NeRF 具有一个极具吸引力的特性,即在多个视图中平均信息。之前有几项研究利用这一特性,将二维语义、分割或特征向量提炼成三维,从而提高了它们的质量。Semantic NeRF和 Panoptic Lifting将语义分割网络中的语义信息嵌入到三维中,表明在三维中结合有噪声或稀疏的标签可以得到清晰的三维分割。这一概念已被应用于利用用户输入的极为稀疏的前景-背景遮罩涂鸦来分割物体。我们的方法通过对输入视图的多个潜在噪声语言嵌入进行平均,从这些工作中汲取了灵感。
蒸馏特征场和神经特征融合场探索了将来自 LSeg 或 DINO的像素对齐特征向量嵌入 NeRF 的方法,并证明它们可用于底层几何的三维操作。LERF 同样将特征向量嵌入 NeRF,但也展示了一种无需微调即可将非像素对齐嵌入(如来自 CLIP 的嵌入)提炼成 3D 的方法。
三维语言标定: 将语言融入三维技术的探索范围十分广泛: 三维视觉问题解答利用三维信息提取有关环境问题的答案。此外,将语言与形状信息相结合,还能通过文本提高物体识别能力。
LERF 更类似于机器人技术中的三维场景表示法,它融合了视觉语言嵌入,支持自然语言交互。VL-Maps和 OpenScene通过使用预先训练的像素对齐语言编码器,建立了一个可用于导航任务查询的三维语言特征卷。在 LERF 中,我们与三维语言编码器 LSeg 进行了比较,发现与 CLIP 相比,LSeg 的表达能力明显下降。
CLIP-Fields和 NLMaps-SayCan分别使用对比监督田地和经典点云融合技术,将农作物的 CLIP 嵌入数据融合到点云中。在 CLIP-Fields 中,作物位置由 Detic引导。另一方面,NLMaps-SayCan 依靠的是区域建议网络。这些地图比 LERF 更稀疏,因为它们主要是对检测到的对象查询 CLIP,而不是对整个场景的密集视图进行查询。同时进行的工作 ConceptFusion在 RGBD 点云中更密集地融合 CLIP 特征,使用 Mask2Former预测感兴趣的区域,这意味着它可能会丢失 Mask2Former 训练集中分布不均的物体。相比之下,LERF 不使用区域或掩码建议。
LERF 为三维文本查询提供了一个新的高密度体积界面,可与三维语言的各种下游应用集成,提高了这些方法在多视图输入时查询环境的分辨率和保真度。这得益于将多个视图中可能存在噪声的特征向量嵌入密集 LERF 结构的平滑行为。
3.语言嵌入的辐射场
给定一组经过校准的输入图像,我们就可以在 NeRF 中将 CLIP 内嵌到三维场中。然而,查询单个三维点的 CLIP 嵌入是模糊的,因为 CLIP 本身就是一种全局图像嵌入,不利于像素对齐的特征提取。考虑到这一特性,我们提出了一种新方法,即在以样本点为中心的体积上学习语言嵌入字段。具体来说,该字段的输出是包含指定体积的图像作物的所有训练视图的平均 CLIP 嵌入。通过将查询从点重构为体积,我们可以有效地从输入图像的粗作物中监督出一个密集字段,通过对给定体积比例的调节,可以以像素对齐的方式呈现这些图像。
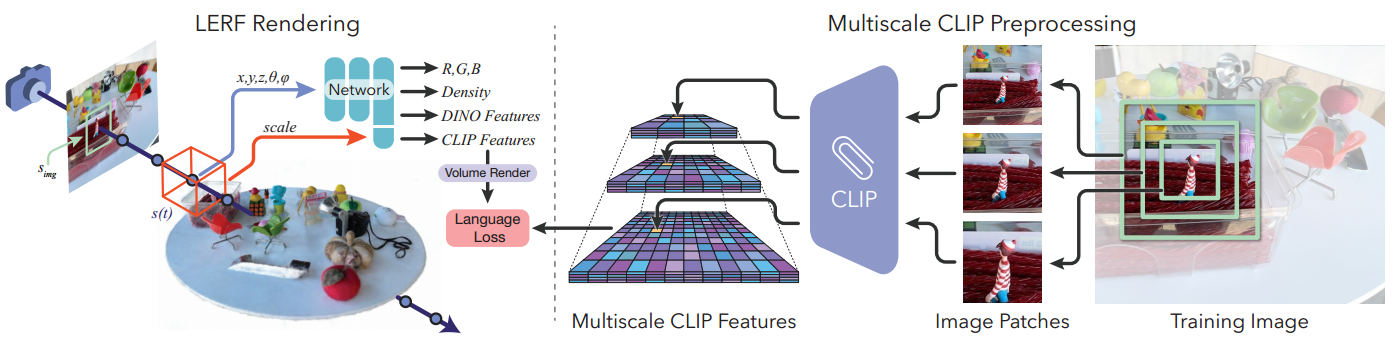
3.1 LERF 体积渲染
NeRF 接收位置 ~x 和视图方向 ~d,并输出颜色 ~c 和密度 σ。这些值的样本可以沿光线合成,从而生成像素的颜色。为了创建 LERF,我们使用语言嵌入 Flang(~x; s) 2 R d 来增强 NeRF 的输出,该语言嵌入接收输入位置 ~x 和物理尺度 s,并输出 d 维语言嵌入。我们选择这种与视角无关的输出,因为位置的语义应不受视角的影响。这样一来,多个视角就能对同一字段输入做出贡献,将它们的嵌入平均到一起。尺度 s 表示以 ~x 为中心的立方体的世界坐标边长,类似于 Mip-NeRF通过整合位置编码来整合不同尺度的方法。
通过 LERF 渲染颜色和密度的方法与 NeRF 完全相同。为了将语言嵌入呈现到图像中,我们采用了与之前的工作类似的技术,沿着一条射线 ~r(t) = ~ot + t ~d 呈现语言嵌入。不过,由于 LERF 是一个体积场,而不是点场,因此我们还必须为射线上的每个位置定义一个比例参数。为此,我们在图像平面上固定一个初始比例尺 simg,并定义 s(t)随焦距和样本与射线原点的距离成比例增加:s(t) = simg ∗ fxy=t(图 2,左)。从几何学角度看,这代表了沿着射线的挫折线。我们按照 NeRF 计算渲染权重:T(t) = R t exp (-σ(s)ds);w(t) = R t T(t)σ(t)dt,然后对 LERF 进行积分,得到原始语言输出: ^φlang = R t w(t)Flang (r(t); s(t)) dt,最后按照 CLIP 将每个嵌入归一化为单位球面:φlang = φ^ lang=jj ^φlangjj。我们发现,由于射线上的非零权重样本往往在空间上比较接近,因此射线上的样本之间没有必要进行球面插值。
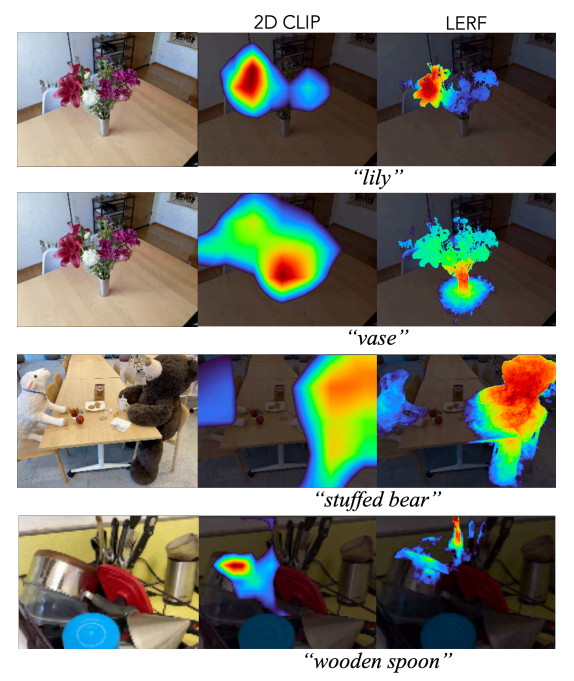
图 4:二维 CLIP 与 LERF 的对比:左图是通过片段式 CLIP 内嵌插值可视化相似性,右图是通过 LERF 渲染的相似性。由于容积语言渲染包含了多个视图的信息,因此三维相关性激活图与底层场景几何图形的吻合度更高。
3.2 多尺度监督
要对 Flang 的语言场输出进行监督,请注意我们只能查询图像斑块上的语言嵌入,而不是像素。因此,为了对多尺度 LERF 进行监督,我们会以射线起源的图像像素为中心,用大小为 simg 的图像裁剪来监督每个渲染的挫点。实际上,在 LERF 优化过程中为每条光线重新计算 CLIP 嵌入将非常昂贵,因此我们预先在多个图像裁剪尺度上计算一个图像金字塔,并存储每个裁剪的 CLIP 嵌入(图 2,右)。这个金字塔有 n 层,采样范围在 smin 和 smax 之间,每种作物排列在一个网格中,作物之间有 50% 的重叠。
在训练过程中,我们在输入视图中均匀地随机采样光线起源,并在每个视图中均匀地随机选择 simg 2 (smin; smax)。由于这些样本并不一定位于图像金字塔中的作物中心,因此我们在上下比例的 4 个最近作物的内嵌值之间进行三线插值,以生成最终的地面实况内嵌值 φ gt lang。我们尽量减小渲染嵌入和地面实况嵌入之间的损失,使两者之间的余弦相似度最大化,并按常数 λlang 缩放(第 3.3 节): Llang = -λlangφlang - φ gt lang。
3.3 DINO正则化
按上述方法直接执行 LERF 可以产生具有内聚力的结果,但在视图较少或前景-背景分离程度较低的区域,生成的相关性地图有时可能是零散的,并包含异常值(图 5)。
为了缓解这种情况,我们额外训练了一个字段 Fdino(~x),它可以在每个点输出 DINO[5] 特征。尽管 DINO 是在无标签的情况下进行训练的[1],但它已被证明具有突发性的物体分解特性,此外,它还能很好地提炼出三维字段[20],这使它成为在三维环境中对语言进行分组的理想候选者,而无需依赖标签数据或传授过于严格的先验。由于 DINO 输出的是像素对齐的特征,因此 Fdino 并不将比例作为输入,而是直接监督每条光线与其对应的 DINO 特征。我们对φdino 进行了与φlang 相同的渲染,但没有对单位球面进行归一化处理,并利用地面真实的 DINO 特征的 MSE 损失对其进行监督。由于 CLIP 和 DINO 输出头共享一个架构主干,因此 DINO 在推理过程中被明确使用,而在训练过程中仅作为一个额外的正则化器。
3.4 场结构
直观地说,优化三维语言嵌入不应影响底层场景表征中的密度分布。我们通过训练两个独立的网络来捕捉 LERF 中的这种归纳偏差:一个用于特征向量(DINO、CLIP),另一个用于标准 NeRF 输出(颜色、密度)。来自 Llang 和 Ldino 的梯度不会影响 NeRF 输出,可视为语言字段与辐射字段的联合优化。我们用多分辨率散列网格来表示这两个字段[26]。语言散列网格有两个输出 MLP,分别用于 CLIP 和 DINO。除了串联散列网格特征外,尺度 s 还作为额外输入传入 CLIP MLP。我们采用 Nerfstudio [35] 中的 Nerfacto 方法作为我们方法的基础,利用相同的建议采样、场景收缩和外观嵌入。
3.5 查询LERF
通常情况下,像 CLIP 这样的语言模型都是通过 zeroshot 分类法进行评估的,即从一个保证包含正确类别的列表中选择一个类别。然而,在实际使用 LERF 处理野外场景时,无法获得详尽的类别列表。我们将自然语言的开放性和模糊性视为一种优势,并提出了一种从 LERF(给定任意文本查询)中查询 3D 相关性地图的方法。查询 LERF 包括两个部分:1)获取渲染嵌入的相关性得分;2)根据提示自动选择比例 s。
相关性评分: 为了给每个渲染的语言嵌入 φlang 赋分,我们计算文本查询 φquer 的 CLIP 嵌入以及一组规范短语 φ i canon。我们计算渲染嵌入和规范短语嵌入之间的余弦相似度,然后计算渲染嵌入文本提示之间的成对软最大值。相关性得分就是 mini exp(φlang-φquer) exp(φlang-φi canon)+exp(φlang-φquer)) 。直观地说,这个分数表示与标准嵌入式相比,呈现的嵌入式与查询嵌入式的接近程度。所有呈现都使用相同的规范短语: "对象"、"事物"、"东西 "和 "纹理"。我们选择这些词作为用户可能进行查询的定性 "平均 "词,并发现它们对于从非常具体到视觉或抽象的查询都具有惊人的稳健性。我们承认,选择这些短语很容易受到提示工程的影响,并认为对它们进行微调可能是未来一项有趣的工作,或许可以将用户互动中对他们认为不相关的负面提示的反馈纳入其中。
规模选择:对于每个查询,我们都会计算一个尺度 s 来评估 Flang。为此,我们在 0 米到 2 米的范围内生成相关性地图,增量为 30,然后选择相关性得分最高的比例。输出相关性地图中的所有像素都将使用这一比例。我们发现这种启发式方法在各种查询中都很稳健,本文中渲染的所有图像和视频都采用了这种方法。假设场景的相关部分具有相同的比例,请参见第 5 节中的限制。
可见度过滤:缺乏足够视图的场景区域,如背景中或漂浮物附近的区域,可能会产生噪声嵌入。为了解决这个问题,在查询过程中,我们会丢弃少于五个训练视图(约占数据集中视图的 5%)观察到的样本。
3.6 实现细节
我们在 Nerfacto 方法的基础上,在 Nerfstudio中实现了 LERF。除了将 LERF 样本的数量从 48 个减少到 24 个以提高训练速度外,提案采样是相同的。我们使用在 LAION-2B 数据集上训练的 OpenClip ViTB/16 模型,图像金字塔从 smin = :05 到 smin = :5 分 7 步变化。用于表示语言特征的哈希网格要比典型的 RGB 哈希网格大得多:它有 32 层,分辨率从 16 到 512,哈希表大小为 2 21,特征维度为 8。 Flang 使用的 CLIP MLP 有 3 个宽度为 256 的隐藏层,然后才是最终的 512 维 CLIP 输出。用于 FDINO 的 DINO MLP 有 1 个宽度为 256 的隐藏层。
我们使用权重衰减为 10-9 的亚当优化器(Adam optimizer)来优化提议网络和字段,在前 5000 个训练步骤中,学习率调度器的指数从 10-2 到 10-3。所有模型的训练步数均为 30,000 步(45 分钟),但如附录所示,训练步数少至 6,000 步(8 分钟)也能取得良好效果。我们在 NVIDIA A100 上进行训练,其内存总容量约为 20GB。我们可以在 Nerfstudio 浏览器中进行实时交互式查询。加权 CLIP 损失时使用的 λ 为 0:01,这是根据经验选择的,并在第 4.4 节中进行了说明。计算相关性得分时,我们将相似性乘以 10,作为 softmax 中的温度参数。
4.实验
我们对 LERF 的功能进行了研究,发现它可以有效处理各种输入文本查询,其中包括当前开放式 Vocab 检测框架难以处理的自然语言规范的各个方面。虽然现有的三维扫描数据集已经存在,但它们往往是单个物体的数据集,或者是没有足够视角的 RGB-D 扫描数据集,无法优化高质量的 NeRF,而且这类模拟或扫描场景中包含的长尾物体很少。为了强调 LERF 处理真实世界数据的能力,我们收集了 13 个场景,其中既有野外场景(杂货店、厨房、书店),也有摆拍的长尾场景(茶馆、小雕像、手)。我们使用 iPhone 应用程序 Polycam 捕捉场景,该程序运行板载 SLAM 来查找相机姿势,使用的图像分辨率为 994×738。

图 3:5 个野外场景的 LERF 结果。每张图片都显示了 LERF 的可视化呈现(第 3 节),以及每个文本查询的相关性呈现(第 3.5 节)和激活区域的裁剪视图。在书店场景中,原始书籍封面图像以蓝色显示,并带有地球仪图标。有关相关性可视化的讨论和详情,请参阅第 4.1 节。
4.1 定性结果
我们通过将每个查询的颜色图从 50% (相关性低于规范短语)到最大相关性进行归一化,从而将相关性得分可视化。所有场景的详细可视化效果见附录,在图 3 中,我们选择了 5 个具有代表性的场景来展示 LERF 处理自然语言的能力。图 7 展示了与 LSeg 的 3D 可视化对比。
LERF 从不同的细节层面捕捉场景的语言特征,支持 "黄色 "等属性的查询,以及书名和电视节目中的特定角色("冒险时间中的杰克")等高度特定的查询。由于缺乏离散类别,对象可以与多个查询相关:在小雕像场景中,抽象文本查询可以创建有语义意义的分组。"卡通 "选择了猫、杰克、橡皮鸭、米菲、瓦尔多和玩具大象。"洗澡玩具 "选择了橡胶类物体,如橡皮鸭、杰克和玩具大象(橡胶制成)。玩具大象在三个不同的查询中都得到了突出显示,这表明 LERF 能够支持同一对象的不同语义标签。
4.2 存在确定性
我们评估了 LERF 是否能检测出一个物体是否存在于一个场景中。我们为 5 个场景标注了地面真实存在,收集了两组标签: 1) 来自 COCO 的标签,用于向 LSeg 表示内分布对象;2) 我们自己的长尾标签,由每个场景中 15-20 个对象的查询串联而成,总共 81 个查询。所有查询请参见附录。LERF 通过渲染可见几何体上的密集点云来确定场景中是否存在物体,如果任何一点的相关性得分超过阈值,则返回 "True"。
我们将 LSeg 特征与 DFF中的三维特征进行了比较,但这是在我们自己的代码库中实现的,以便进行苹果对苹果的比较。由于 LSeg 输出的是像素对齐的特征,因此我们取消了 Flang 的缩放参数。我们在图 8 中报告了相关性得分阈值的精度-召回曲线。这项实验表明,在有限的分割数据集上训练出来的 LSeg 缺乏有效表现自然语言的能力。相反,如图 7 所示,它只在训练集分布范围内的常见对象上表现良好。

图 8:三维存在性实验的精确度召回曲线,第 4.2 节。LSeg 在分布内标签上的表现与 LERF 相似,但在野外场景的长尾标签上的表现明显不如 LERF。

图 7:与 LSeg 在 3D 中的比较:由于 COCO 数据集中有杯子,因此 LSeg 在 "水杯 "上表现良好,但无法定位鸡蛋等分布外查询。
4.3 定位
为了评估 LERF 在场景中定位文本提示的能力,我们渲染了 5 个场景中 72 个对象的新视图和标签边界框。对于 3D 方法,如果相关度最高的像素位于框内,我们就认为标签成功;对于 OwL-ViT 方法,如果预测框的中心位于框内,我们就认为标签成功。结果如表 1 和图 6 所示,在定位场景的相关部分方面,嵌入 LERF 的语言嵌入明显优于三维 LSeg。我们还通过渲染全高清 NeRF 视图并选择文本查询置信度最高的边界框,与二维开放式虚拟现实检测器 OWL-ViT 进行了比较。OWL-ViT 在 3D 中的表现优于 LSeg,但在长尾查询方面则不如 LERF。

表 1: 使用 LSeg、OWL-ViT 和 LERF 的蒸馏特征字段的定位精度比较。总体性能是通过汇总场景结果计算得出的。

图 6:定位对比 利用 LSeg in 3D (DFF) 和 OWL-ViT 从新视角定位长尾物体的定性对比(表 1)
4.4 消融
无 DINO: 去除 DINO 会导致相关性地图的平滑度和边界质量下降,尤其是在周边视图较少或前景与背景之间几乎没有几何分隔的区域。我们在图 5 中展示了两个 DINO 提高相关性地图质量的示例。
单尺度训练:我们只在固定的 s0 = 15% 图像尺度上进行训练,从而将多尺度 CLIP 监督从管道中剔除。这样做极大地削弱了 LERF 处理所有尺度查询的能力,无论是在没有足够上下文的大型查询("浓缩咖啡机")上,还是在有足够上下文的查询("奶精豆荚")上,LERF 都会失败。这些结果表明,多尺度训练可以规范所有尺度的语言字段,而不仅仅是与特定查询相关的上下文字段。
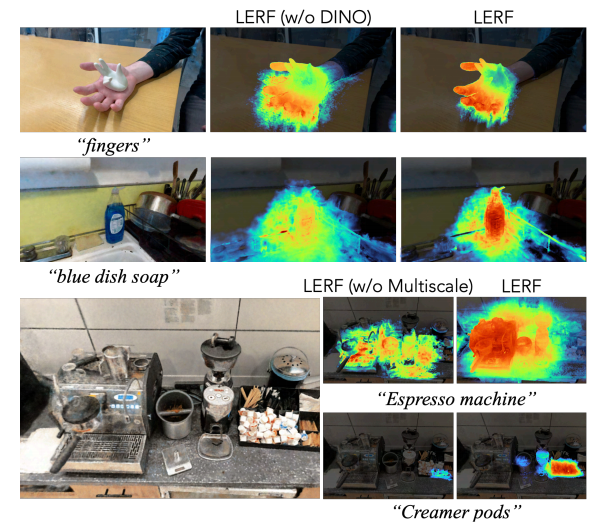
图 5:消融: 我们消减了 DINO 正则化和多尺度训练(第 4.4 节),并在此强调了相关性地图的质量下降。
5.局限性
LERF 具有与 CLIP 和 NeRF 相关的局限性;图 9 展示了其中一些局限性。与 CLIP 一样,LERF 的语言查询也经常表现出 "词袋 "行为(即 "非红色 "与 "红色 "相似),并且难以捕捉对象之间的空间关系。对于视觉或语义相似的查询,LERF 可能容易出现假阳性:"zucchinis "会激活其他形状相似的蔬菜,尽管zucchinis 比干扰项更相关(图 9)。

图 9:失败案例: LERF 在识别与查询内容在视觉上相似的对象时遇到了困难: "西葫芦 "也会在其他绿色长条蔬菜上激活,而 "叶子 "则会在绿色塑料椅子上激活。LERF 在全局/空间推理方面也很吃力,"桌子 "只在桌子的边缘被激活。")
LERF 需要已知的校准摄像机矩阵和 NeRF 质量的多视角捕捉,而这些并不总是可用或容易捕捉的。语言字段的质量受到 NeRF 重建质量的制约。此外,由于 Flang 采用的是容积式输入,靠近其他表面的物体在没有侧视图的情况下,其嵌入与周围环境的关系会变得模糊,因为没有任何视图可以看到没有物体的背景。这就导致了与单视角 CLIP 类似的模糊相关性映射(图 4)。此外,对于给定的查询,我们只从单一视角呈现语言嵌入。有些查询可能会受益于甚至需要结合多个尺度的上下文(例如 "桌子")。
6.结论
我们提出的 LERF 是一种将原始 CLIP 嵌入以密集、多尺度的方式融合到 NeRF 中的新方法,无需区域建议或微调。我们发现,这种方法可以支持各种现实世界场景中的自然语言查询,在支持自然语言查询方面远远优于像素对齐的 LSeg。LERF 是一个通用框架,支持任何对齐的多模态编码器,这意味着它可以自然地支持视觉语言模型的改进。代码和数据集将在提交过程结束后发布。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“NeRF”获取全部118篇神经辐射场论文
码字不易,欢迎大家点赞评论收藏!