原文链接:https://arxiv.org/abs/2312.17118
1. 引言
现有的3D占用预测方法建立密集的3D特征,没有考虑场景的稀疏性,因此难以满足实时要求。此外,这些方法仅关注语义占用,无法区分实例。
本文认为场景的稀疏性包含两个方面:几何稀疏性(绝大多数的体素为空)和实例稀疏性(实例数量远小于非空体素数量)。
本文提出SparseOcc,一个基于多视图图像的、完全稀疏的全景占用网络。首先使用稀疏体素解码器重建场景的稀疏几何,仅对非空区域建模从而极大减小计算资源。再使用掩膜Transformer,通过稀疏实例查询在稀疏空间预测各物体的掩膜和标签。进一步提出掩膜指导的稀疏采样以避免掩膜Transformer中密集的交叉注意力。这样,可以将语义占用与实例占用统一为全景占用。
3. SparseOcc
SparseOcc包含3部分:图像编码器(主干+FPN)、稀疏体素解码器(预测稀疏3D几何占用和嵌入)、掩膜Transformer解码器(在稀疏空间预测语义和实例)。

3.1 稀疏体素解码器
由于场景中的绝大多数(超过90%)体素均为空,可以建立稀疏的3D场景表达。
总体结构:采用由粗到细的结构,每一层以体素token的稀疏集合为输入。在每层的最后会估计每个体素的占用分数,并根据占用分数得到稀疏性。有两种稀疏化方法:基于阈值的方法和top-
k
k
k方法。其中后者可保证等长样本,能提高训练效率。
k
k
k可通过统计不同分辨率下非空体素的最大数量得到。稀疏化的体素token会作为下一层的输入。
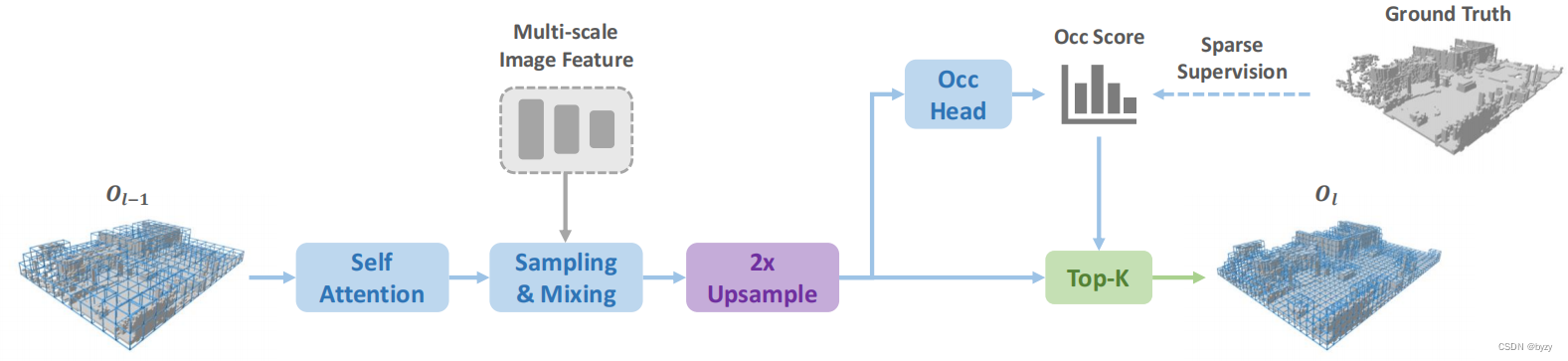
设计细节:每层使用类似Transformer的结构来处理体素级查询,类似SparseBEV。设
l
l
l层的输入包含
K
l
−
1
K_{l-1}
Kl−1个体素查询,每个查询包括3D位置和
C
C
C维内容向量。首先通过自注意力聚合全局与局部特征,然后使用线性层从内容向量生成3D偏移量,并根据体素的位置和大小得到全局坐标系下的采样点。最后使用相机参数将采样点投影到各视图上,通过双线性插值采样多尺度特征,并使用自适应混合增强。
时间建模:本文将采样点变换到过去的时间戳上,并采样图像特征,来自各帧的采样特征会堆叠并进行自适应混合。
监督:每一层均有监督。使用二元交叉熵(BCE)损失监督几何占用头,其中仅监督预测占用的稀疏集合。
由于样本的不平衡性,本文为不同类别的体素分配不同的权重。对类别
c
c
c,其权重为
w
c
=
∑
i
=
1
C
M
i
M
c
w_c=\frac{\sum_{i=1}^C M_i}{M_c}
wc=Mc∑i=1CMi
其中 M i M_i Mi为第 i i i类体素的数量。
3.2 掩膜Transformer
基于Mask2Former,使用 N N N个稀疏实例查询(可分解为二值掩膜查询 Q m ∈ [ 0 , 1 ] N × K Q_m\in[0,1]^{N\times K} Qm∈[0,1]N×K和内容查询 Q c ∈ R N × C Q_c\in\mathbb{R}^{N\times C} Qc∈RN×C)。掩膜Transformer分为3步:多头自注意力(MHSA)、掩膜指导的稀疏采样、自适应混合。MHSA进行查询间的交互,而后两者进行查询与图像特征之间的交互。
掩膜指导的稀疏采样:使用Mask2Former中的掩膜交叉注意力需要所有位置的键,会带来计算负担。本文进行了修改:给定Transformer解码器第 ( l − 1 ) (l-1) (l−1)层的掩膜预测,通过随机选择掩膜内的体素,生成3D采样点集合,并投影到图像上采样特征(即仅需要掩膜内体素投影位置的键)。稀疏采样机制也能使得时间建模更加容易,只需要变换采样点即可(和3,2节中一致)。
掩膜交叉注意力:若预测掩膜 Q m ( n , k ) Q_m(n,k) Qm(n,k)小于阈值,则在常规交叉注意力计算softmax前,将对应位置替换为负无穷,也就是忽略 Q c ( n ) Q_c(n) Qc(n)与 V ( k ) V(k) V(k)的关系。
预测:使用带Sigmoid激活函数的线性分类器,基于内容嵌入 Q c Q_c Qc进行分类。使用MLP将查询嵌入 Q c Q_c Qc转化为相同大小的掩膜嵌入 M M M,与稀疏体素嵌入 V ∈ R K × C V\in\mathbb{R}^{K\times C} V∈RK×C进行点乘,得到掩膜预测。这样,预测空间就是稀疏体素解码器定义的稀疏化3D空间。掩膜预测会作为下一层的掩膜查询 Q m Q_m Qm。
根据矩阵的形状判断,这里的点乘应该是指矩阵乘法。
监督:由于稀疏体素解码器的重建不够精确,可能会导致漏检或误检。对于漏检(真实实例不在预测中),本文丢弃这些实例。对于误检,将其分类为额外的“无物体”类别。
损失函数:使用匈牙利匹配方法匹配预测与真值。focal损失用于分类,DICE损失和BCE掩膜损失用于掩膜预测。
4. 全景占用基准
使用3D边界框生成全景真值。通过已有的语义占用基准,组合边界框内所有的该类体素,作为实例分割结果。
使用边界框的原始大小会导致丢失边界体素,而扩大边界框又会导致重叠。本文使用两阶段分组方式,在第二阶段将未分组体素分配给最近的边界框。
评估指标使用全景质量(PQ)指标,即语义质量(SQ)与识别质量(RQ)的乘积:
S
Q
=
∑
(
p
,
g
)
∈
T
P
I
o
U
(
p
,
g
)
∣
T
P
∣
R
Q
=
∣
T
P
∣
∣
T
P
∣
+
1
2
∣
F
P
∣
+
1
2
∣
F
N
∣
SQ=\frac{\sum_{(p,g)\in TP}IoU(p,g)}{|TP|}\\RQ=\frac{|TP|}{|TP|+\frac{1}{2}|FP|+\frac{1}{2}|FN|}
SQ=∣TP∣∑(p,g)∈TPIoU(p,g)RQ=∣TP∣+21∣FP∣+21∣FN∣∣TP∣
其中TP的IoU阈值为0.5。
5. 实验
5.1 实施细节
掩膜Transformer各层的权重共享。
5.2 主要结果
与过去的方法相比,SparseOcc可以使用更小的图像主干和输入分辨率达到相同或更高的性能。
5.3 消融
稀疏体素解码器v.s.密集体素解码器:与密集体素输出的方法相比,本文的方法在几何占用预测上有更高的速度和性能。对于语义占用预测,本文的方法也有相当的性能;对于全景质量指标,本文的方法性能略低,这可能是由于掩膜解码器训练不充分。
掩膜指导的稀疏采样v.s.密集交叉注意力:与密集交叉注意力相比,本文的方法速度上快了1倍,且性能有所提升。与均匀采样方法相比,本文的方法通过关注前景区域,有更高的性能。
**稀疏体素解码器预测的有限的体素集合是否足够覆盖场景?**与仅使用BCE损失的方法相比,引入权重平衡正负样本能提高性能;使用所有类别的样本平衡能大幅提高IoU与各类平均召回率。
时间建模:使用更多的过去帧,以及在稀疏体素编码器和掩膜Transformer中均使引入时间融合,均能提高性能。
掩膜解码器中的查询数量:当查询数少于场景中的实例数时,训练会崩溃。当查询数超过最优值后,不会带来性能提升。
6. 局限性
真值不可靠:来自激光雷达点云积累方式的占用标签可能会导致未被扫描的区域被视为空区域。
积累误差:稀疏体素解码器中,早期丢弃的体素不能被恢复;掩膜解码器也只能从稀疏体素解码器输出的区域进行预测。







![[ELK] ELK企业级日志分析系统](https://img-blog.csdnimg.cn/direct/12b58952fae64eeb836b0cef10f81f9d.png)