目录
本地数据爬取:
本地爬取练习:
网络爬取:
----- 以下为均本地数据爬取:
带条件爬取
贪婪爬取和非贪婪爬取:
例题 1:使获取 1 为不贪婪
*例题 2:使获取 0、1 都为不贪婪
之前介绍了正则表达式的语法 和 第一个作用(校验字符串)
本地数据爬取:
目的:获取满足正则表达式规则的所有字符串
先来认识几个名词:
Pattern:表示正则表达式
Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取
本地爬取代码示例:
/* 有如下文本,请按照要求爬取数据。
Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,
因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台
要求:找出里面所有的JavaXX
*/
String str="Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这" +
"两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//1.创建正则表达式的对象
Pattern p=Pattern.compile("Java\\d{0,2}");
//2.获取文本匹配器的对象
//m:文本匹配器的对象
//str:大串
//p:规则
//m要在str中找符合p规则的小串,
Matcher m = p.matcher(str);
//3.循环
//拿着文本匹配器从头开始读取,寻找是否有满足规则的子串
//如果没有,方法返回false
//如果有,返回true。在底层记录子串的起始索引和结束索引+1,
//0,4
while(m.find()){
String s=m.group();
sout(s);
}
//方法底层会根据find方法记录的索引进行字符串的截取
//substring(起始索引,结束索引);包头不包尾
//(0,4)但是不包含4索引
//会把截取的小串进行返回。本地爬取练习:
需求:把下面文本中的座机电话,邮箱,手机号,热线都爬取出来。
手机号的正则表达式:1[3-9]\d{9}
邮箱的正则表达式:\w+@[\w&&[^_]]{2,6}(\.[a-zA-Z]{2,3}){1,2}
座机电话的正则表达式:0\d{2,3}-?[1-9]\d{4,9}
热线电话的正则表达式:400-?[1-9]\\d{2}-?[1-9]\\d{3}
package pachong;
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class RegexDemo8 {
public static void main(String[] args) {
String s = "电话:18512516758,18512508907"+"或者联系邮箱:boniu@itcast.cn," +
"座机电话:01036517895,010-12345678" +"邮箱:bozai@itcast.cn," +
"热线电话:400-618-9090,400-618-4000,4006184000,4006189090";
String regex = "(1[3-9]\\d{9})|(\\w+@[\\w&&[^_]]{2,6}(\\.[a-zA-Z]{2,3}){1,2})"+"|(0\\d{2,3}-?[1-9]\\d{4,9})"+"|(400-?[1-9]\\d{2}-?[1-9]\\d{3})";
//1.获取正则表达式的对象
Pattern p = Pattern.compile(regex);
//2.获取文本匹配器的对象
//利用m去读取s,会按照p的规则找里面的小串
Matcher m = p.matcher(s);
//3.利用循环获取每一个数据
while(m.find()){
String str = m.group();
System.out.println(str);
}
}
}
网络爬取:
网络爬虫暂时混个眼熟:
需求:
把该链接
:悬赏通缉嫌疑人,30名在逃盗抢骗嫌疑人个人资料正脸照曝光(2)_社会新闻_海峡网中所有的身份证号码都爬取出来。
(学习需求)
代码示例:
public class Test02 {
public static void main(String[] args) throws IOException {
//1.创建一个URL对象
URL url = new URL("http://www.hxnews.com/news/gn/shxw/201811/01/1641427_2.shtml");
//2.连接上这个网络:保证网络是畅通的
URLConnection conn = url.openConnection();
//读取网络数据:将连接转换为输入流,并通过BufferedReader来逐行读取网络返回的数据。
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
//获取正则表达式规则:调用静态方法getRole()获取预先定义好的正则表达式字符串,这个例子中的正则表达式用于匹配中国大陆的严格格式身份证号。
String regex = getRole();
Pattern p = Pattern.compile(regex);
//数据处理和匹配:遍历BufferedReader读取的每一行数据,
// 对每行使用Pattern对象的matcher()方法生成Matcher对象,
// 然后通过Matcher对象的find()方法查找与正则表达式匹配的子串。
// 若找到匹配项,则调用group()方法打印出匹配的字符串。
while ((line = br.readLine()) != null) {
//m会在line中找符合p规则的小串
Matcher m = p.matcher(line);
while(m.find()){
System.out.println(m.group());
}
}
//关闭资源:在所有数据处理完成后,关闭BufferedReader以释放系统资源。
br.close();
}
//获取规则
public static String getRole() {
//严格的身份证;
return "[1-9]\\d{5}(18|19|20)\\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\\d|3[01])\\d{3}[\\dXx]";
}
}
----- 以下为均本地数据爬取:
带条件爬取
看下面例题:
文本:
"Windows XP:发布于2001年,Windows Vista:发布于2006年,Windows 7:发布于2009年, Windows 8:发布于2012年,Windows 10:发布于2015年,Windows 11:发布于2021年"
- 需求1:爬取版本号为Vista、7、8、10、11的Windows文本,(但是只要Windows,不显示版本号)。
- 需求2:爬取版本号为的Vista、7、8、10、11的Windows文本。正确爬取结果为:Windows Vista Windows 7 Windows 8 Windows 10 Windows 11
- 需求3:爬取除了版本号为Vista、7、8、10、11的Windows文本,
// 注意:空格
public class Test04_Required02 {
public static void main(String[] args) {
String s=" Windows XP:发布于2001年,Windows Vista:发布于2006年,Windows 7:发布于2009年," +
" Windows 8:发布于2012年,Windows 10:发布于2015年,Windows 11:发布于2021年";
//1
String regex1="Windows\\s(?=Vista|7|8|10|11)";// \\s表示空白字符
Pattern p1=Pattern.compile(regex1);
Matcher m = p1.matcher(s);
while(m.find()){
System.out.println(m.group());
}
//2
String regex2="Windows\\s(?:Vista|7|8|10|11)";//?:可省略
Pattern p2=Pattern.compile(regex2);
Matcher m2 = p2.matcher(s);
while(m2.find()){
System.out.println(m2.group());
}
//3:注意
String regex3="Windows\\s(?!Vista|7|8|10|11)\\w+";
Pattern p3=Pattern.compile(regex3);
Matcher m3 = p3.matcher(s);
while(m3.find()){
System.out.println(m3.group());
}
}
}
控制台:
Windows
Windows
Windows
Windows
Windows
Windows Vista
Windows 7
Windows 8
Windows 10
Windows 11
Windows XP
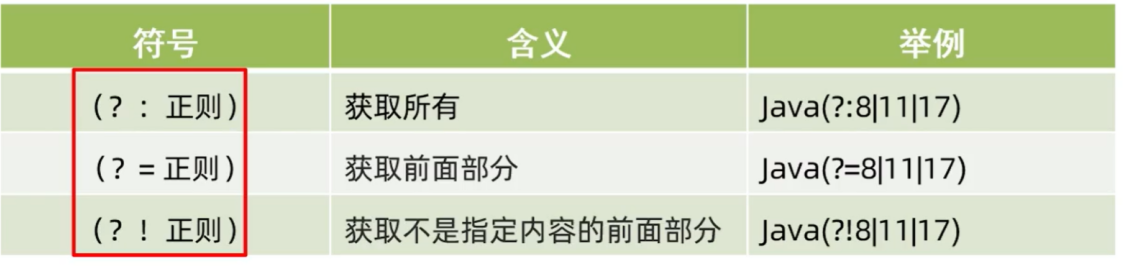
非捕获分组:正则表达式分组括号中介绍
贪婪爬取和非贪婪爬取:
注意:正则表达式规则中的量词才会有贪婪和非贪婪的区别(因为 字符类和与字符类只能匹配单个字符,也就没有贪婪和非贪婪之分)
正则表达式规则中的量词:才会有贪婪和非贪婪的区别。这些量词决定了其前面的表达式匹配字符的次数。

贪婪:它会尽可能多地匹配所涵盖的字符。(默认就是贪婪)
非贪婪:在量词后加上 ? 可以使其变为非贪婪,它会尽可能少地匹配所涵盖的字符。
例如,对于表达式"ab+":
"ab+"将会贪婪地匹配尽可能多的b,即匹配连续出现的b。
贪婪爬取获取结果:abbbbbbbbbbbb
"ab+?"将会非贪婪地匹配尽可能少的b,即只匹配一个b。
非贪婪爬取获取结果:ab
例题 1:使获取 1 为不贪婪
String s = "Java自从95年问世以来,011111" +
"经历了很多版木,目前企业中用的最多的是]ava8和]ava11,因为这两个是长期支持版木。" +
"下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
String regex="01+?";
Pattern p=Pattern.compile(regex);
Matcher m= p.matcher(s);
while(m.find()){
System.out.println(m.group());
}
控制台:
01
*例题 2:使获取 0、1 都为不贪婪
String s = "Java自从95年问世以来,0000011111" +
"经历了很多版木,目前企业中用的最多的是]ava8和]ava11,因为这两个是长期支持版木。" +
"下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
String regex="0{1}1+?";
Pattern p=Pattern.compile(regex);
Matcher m= p.matcher(s);
while(m.find()){
System.out.println(m.group());
}控制台:
01




![[Error]连接iPhone调试时提示Failed to prepare the device for development.](https://img-blog.csdnimg.cn/direct/8faa77347a35461b84c12294f506be30.png)