书接前文:小周带你读论文-2之"草履虫都能看懂的Transformer老活儿新整"Attention is all you need(1) (qq.com)
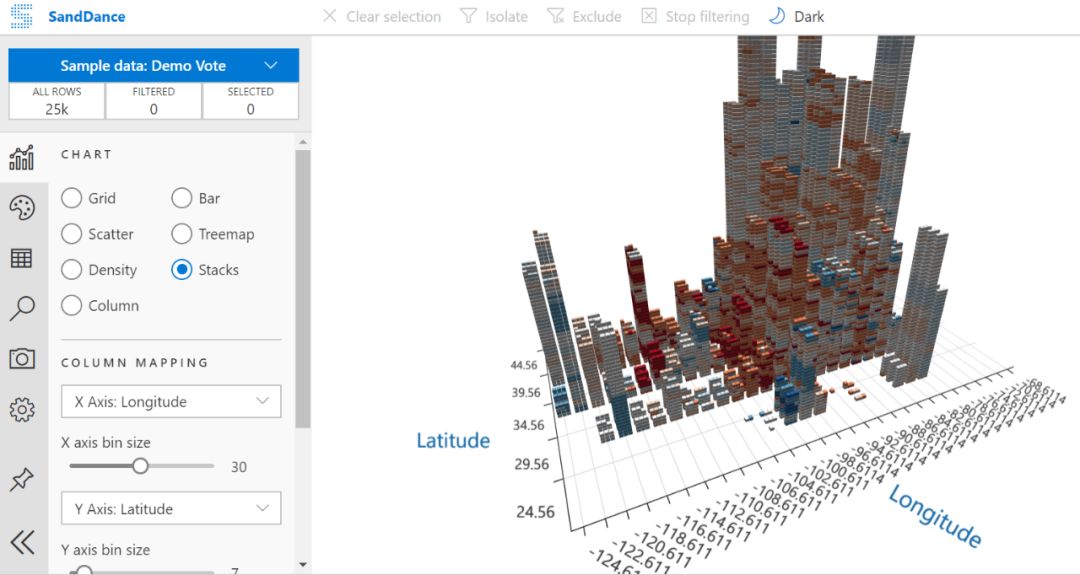
上文书说到为什么我们要用casual-decoder架构,把Transformer的左边给省略了,于是得到下图这样的架构
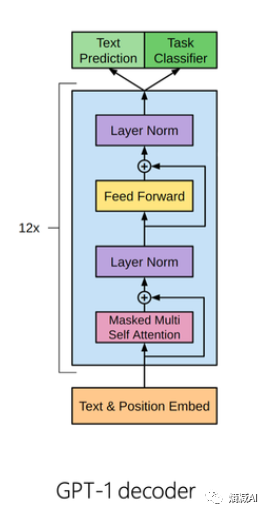
上图是GPT-1的模型结构,那么casual-decoder和原始Transformer除了没有左边的encoder还有什么区别呢?
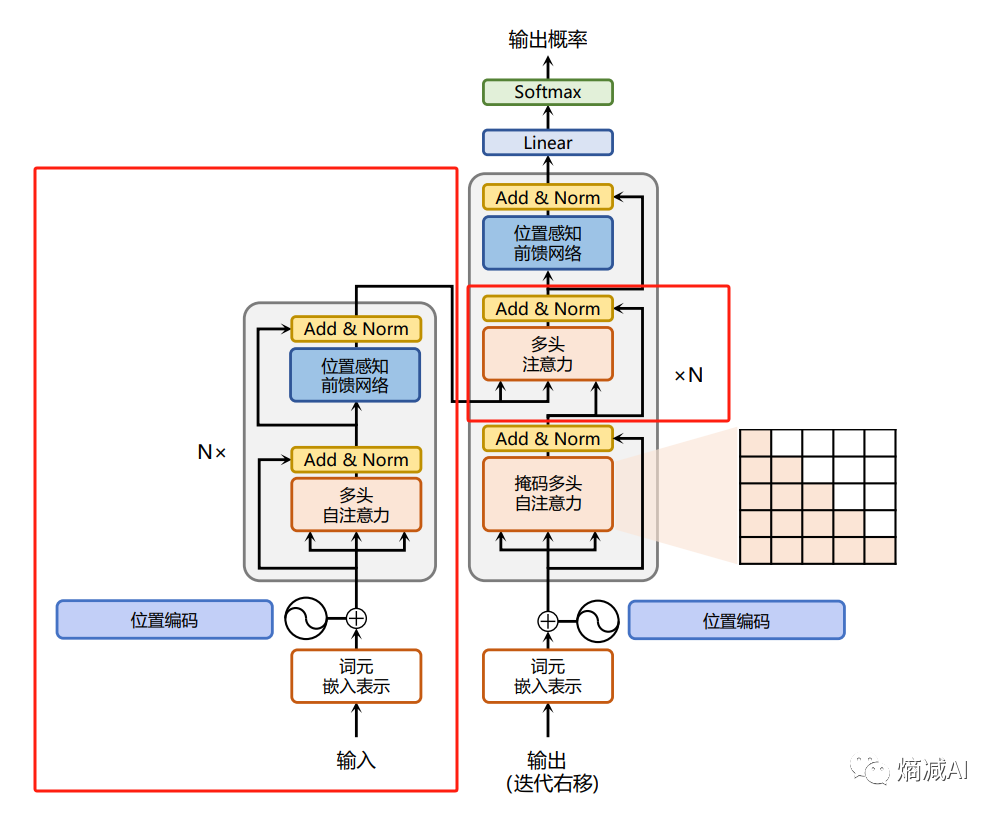
就是除了把左边红框的部分去掉了,右边中间的部分也给干掉了,精简到从多头注意力层之后过一层Layer Normal之后直接进FNN
整个网络就被精简为:
位置编码层--->N*(masked自注意力层--->第一层Layer normalization--->FFN--->第二层Layer Normalizattion)--->线性层
不同的模型可能会有区别,但是大差不差,等于你记住了我这个顺序,就记住了Casual-decoder模式的LLM的网络架构
首先一个大前提,我们应该了解Transformer模型本身肯定是看不懂你输入进去的文字的,最终是都要表示成为向量的模式,然后通过距离比较理解出你的输入大概率要对应什么输出的可能性百分率
这部分不理解的基础方面的同学,可以阅读和参考以下文章:
深度学习从入门到不想放弃-5 (qq.com)
深度学习从入门到不想放弃-6 (qq.com)
当你准备训练模型之前,首先是要定义自己的词典,也就是vocb,vocb是可以由纯粹的单字构成(汉语,估计也是唯一一门的表意文字),也可以由词组成(英语,拼音类文字,当然汉语也可以这么分),一般像Llama分词就用的BPE来分词,来支撑它的vocb,但是BPE中文用着就别扭,因为是基于字节的,也有自己写分词器的,按字来分,比如我哥们儿在做的项目就是自己做的汉字分词器,然后把5000多个汉字加入到Llama原本的vocb里面,也一样用
分完了词我们就要做我们的tokenizer,就是下面这些文件
比如打开tokenizer.json就可以看到编码
然后再通过tokenizer的model去把数字转换成向量
在NLP领域我们一般是不会采用one-hot编码的,都采用word2Vec的形式,尽量别那么稀疏,本来NLP的场景就很稀疏,所以我们要尽量省算力,省内存
比如Llama32000个词,要是one-hot编码的话,就是[0,0,0,1,0,0......(第3200个0)]这种的,显然不能让人接受,如下图我用一个4维的向量来编码一个词(所对应的数字),只要词典里这些词的四个维度的数字有一点不一样就行了,这样就省了好多的空间,实际场景中了,为了特征值比较好出结果还有其他原因,一般维度也并不太小,GPT-1刚出的时候我记得是768维,和一般的word2vec相同,到了GPT-3已经是12288维
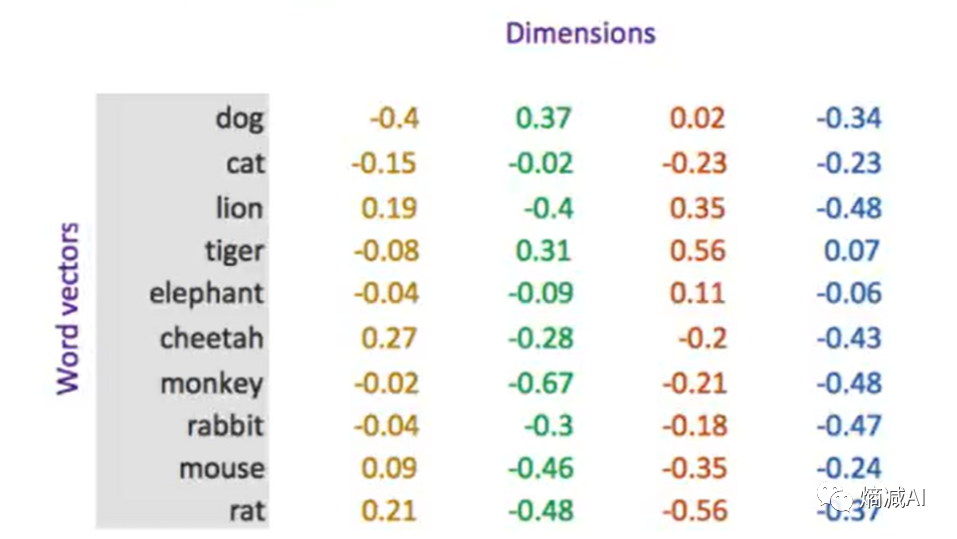
当一个句子中的所有词(或者字)被进行embedding处理之后,在进入模型训练之前,就会变成这样子,像是下图样子的Tensor
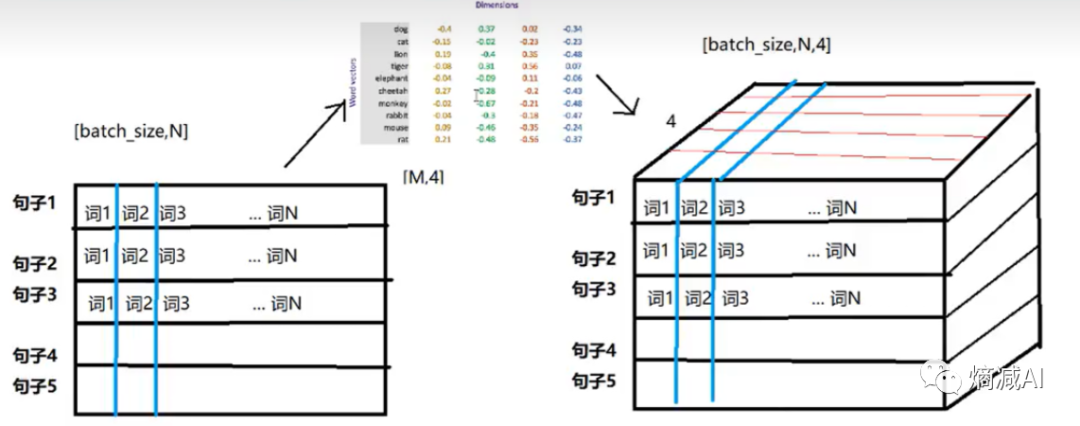
Tensor的形状就是( batchsize,seq_number,dimension_numer)
当把训练数据按照batchsize封装成这个样子,就可以送入网络里进行训练了,比如RNN就直接开始训了,但是Transformer不太行,原因是因为RNN是具有时序控制的,通过类似门电路一样的遗忘门,输入输出门,来保留原来的时序信息,但是Transfoermer是个类词袋模型,它没有这个能力,类似于fasttext,它能力就是统计词频,也没有时序关联性,比如我们要预测两句话:
"我爱你"
"你爱我"
这就是完全的两个意思,但是如果是正常做self-attention的话,其实这两句话,大概率最后输入softmax以后,值是相等的,这就属于不可用了,基于此,在做self-attention之前,我们要把embedding好的token给加点东西,来表示一个句子中不同词的顺序,在做self-attention的时候离的近的多少给点照顾,还有顺序也有前后,这样才能在训练之后的预测达到你想要的要求
那么好,首先我们就进入到今天的环节,也是Transformer的网络入口位置编码层(positional-encoding):
其实位置编码层,它严格来说,不属于Transformer网络的一部分,因为它本身这一层,不参与attention计算,但是它也是非常重要的,因为它的结果会导致attention计算的值的不同,所以很重要
为什么要有位置编码,刚才讲完了,现在我们来讲一下这东西的实现方式,目前实现位置编码主要有3种:
-
绝对位置编码
-
相对位置编码
-
旋转位置编码
我这里就讲两种绝对Sinusoidal (GPT用),旋转RoPE(Llama用),这两个要能看懂也就够用了,相对基本也用不太上(听过的模型只有T5再用)
1-绝对位置编码

简单说就是把一个句子里的词(或者字)按着奇数和偶数的顺序分别拿正弦函数(偶数)和余弦函数(奇数)给求出来一系列值,然后把这个值给挂在embedding上面加一下,一起送入Attention层
什么意思呢?
我们以一个句子"I am a Robot"来看,假设dimension为4,n为用户定义的标量,Attention is all you Need的作者定义n为12000,我为了好算定义100
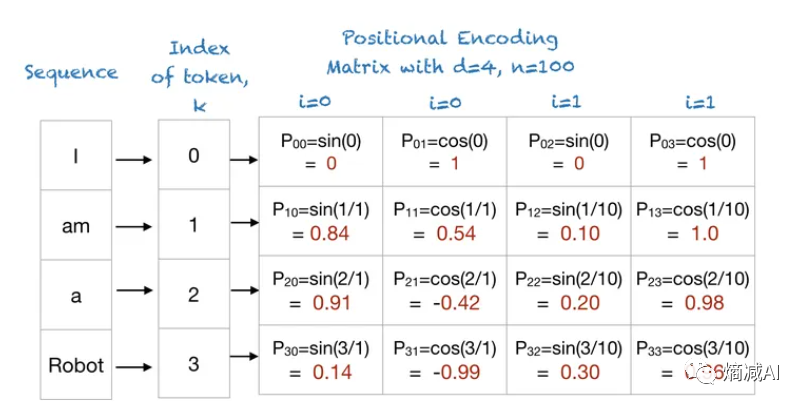
是不是就算出了关于词不同维的向量值,以及他们分别代表的正弦和余弦函数的值?
我们都知道三角函数的特性:
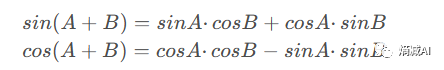
通过这种三角函数式的递进位置编码,模型能够分辨出每个token的绝对位置,也能进一步推断出token之间的相对位置
假设位置M、N两个token,其中N>M,二者相差P,则根据上述公式
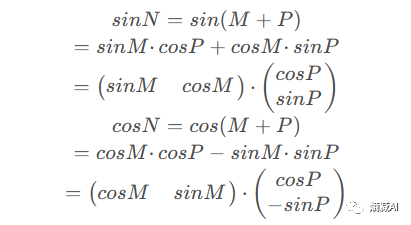
对于sin变换,能够清晰地看出位置N和query的位置M之间的关系,前者相比后者的位置多P个距离,相当于多乘出来一个(cosP sinP) (罗起来的实在打不出来。。。),cos也一样,这样就能在计算M和N之间的位置了
2-RoPE
RoPE旋转编码是苏剑林大师提出的,最早用在他自己自研的RoFormer,Llama就采用了。目前看也是为数不多的,在Transformer领域里,国人贡献的顶级技术能力和思想,下面我用几何方式来解释,还可以用复数来解释(那个我也解释不明白,大家可以自己找资料看)
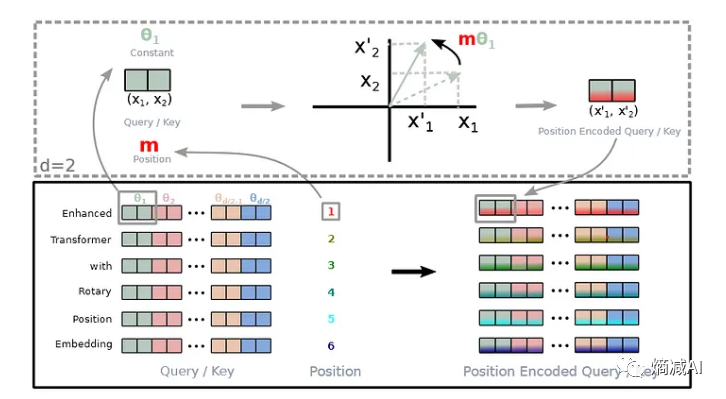
刚才我们讲的相对位置编码,主要是利用三角函数相关的算法和逻辑来判断位置,RoPE不是,它的逻辑是
对于自注意力矩阵X1位置和X2位置来求attention, RoPE先将对应token的特征向量两维度一组切分,如上图,对切分后的每个二维向量旋转,得到X'1和X'2;如上图所示,旋转角的取值与三角式位置编码相同,即采样频率θ乘上token下标,旋转完将所有切分拼接,就得到了含有位置信息的特征向量

比如要求t位置和s位置上的向量X的位置相关性如上面公式所示,RoPE通过旋转矩阵不只可以分别乘在向量qt和ks上(qk做内积求attetion,这块看不明白下节课讲),表达绝对位置,也可以乘在self-attention矩阵At,s的中间,表达相对位置,所以RoPE实现了绝对位置和相对位置的统一
RoPE的实现思路或者说本质,其实就是特征向量的旋转操作,拿一个2维的向量举例(好理解)当以下条件成立
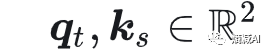
则只可能有一个θ角和它对应,然后我们把旋转矩阵给展开,就能得到qt和ks旋转后的结果,如果维度大于2,其实也是一个道理

上述式子继续推导,合并cos和sin就可以发现,qt,ks旋转后的结果,实质上,就是qt,ks乘上cos再加上qt,ks翻转维度并取反一维后再乘上sin的结果,程序里实现叫rotate_half
本节完,写了2章,1万多字,还没进到Transformer的门

,刚在门外打理完,可见我写的多细,大家别吝惜点赞,转发,收藏,一键三连啥的,谢谢