深度多模态学习:对近期进展和趋势的综述
深度学习的成功已经成为解决越来越复杂的机器学习问题的催化剂,这些问题通常涉及多个数据模态。我们回顾了深度多模态学习的最新进展,并突出了该活跃研究领域的现状,以及存在的差距和挑战。我们首先对深度多模态学习架构进行分类,然后讨论在深度学习架构中融合学到的多模态表示的方法。我们强调两个研究领域——正则化策略和学习或优化多模态融合结构的方法——作为未来工作的激动人心的领域。
引言
神经网络近年来取得了令人瞩目的复兴,长期以来对于训练深度模型的能力的担忧成功地被一群先驱研究人员通过算法、数据和计算力的进步所缓解[1]。这一积极的研究领域不仅引起了学术界的关注,也吸引了工业界的兴趣,并在许多实际问题中,特别是涉及高维非结构化数据的领域,如计算机视觉、语音和自然语言处理等领域,取得了最先进的性能。
随着深度学习在视觉领域的不可否认的成功,深度学习研究的自然发展方向指向涉及更大规模和更复杂多模态数据的问题。这种多模态数据集包含来自观察共同现象的不同传感器的数据,其目标是以互补的方式使用数据来学习复杂的任务。深度学习的主要优势之一是可以自动学习每种模态的分层表示,而不是手动设计或手工制作模态特定的特征,然后将其馈送到机器学习算法中。
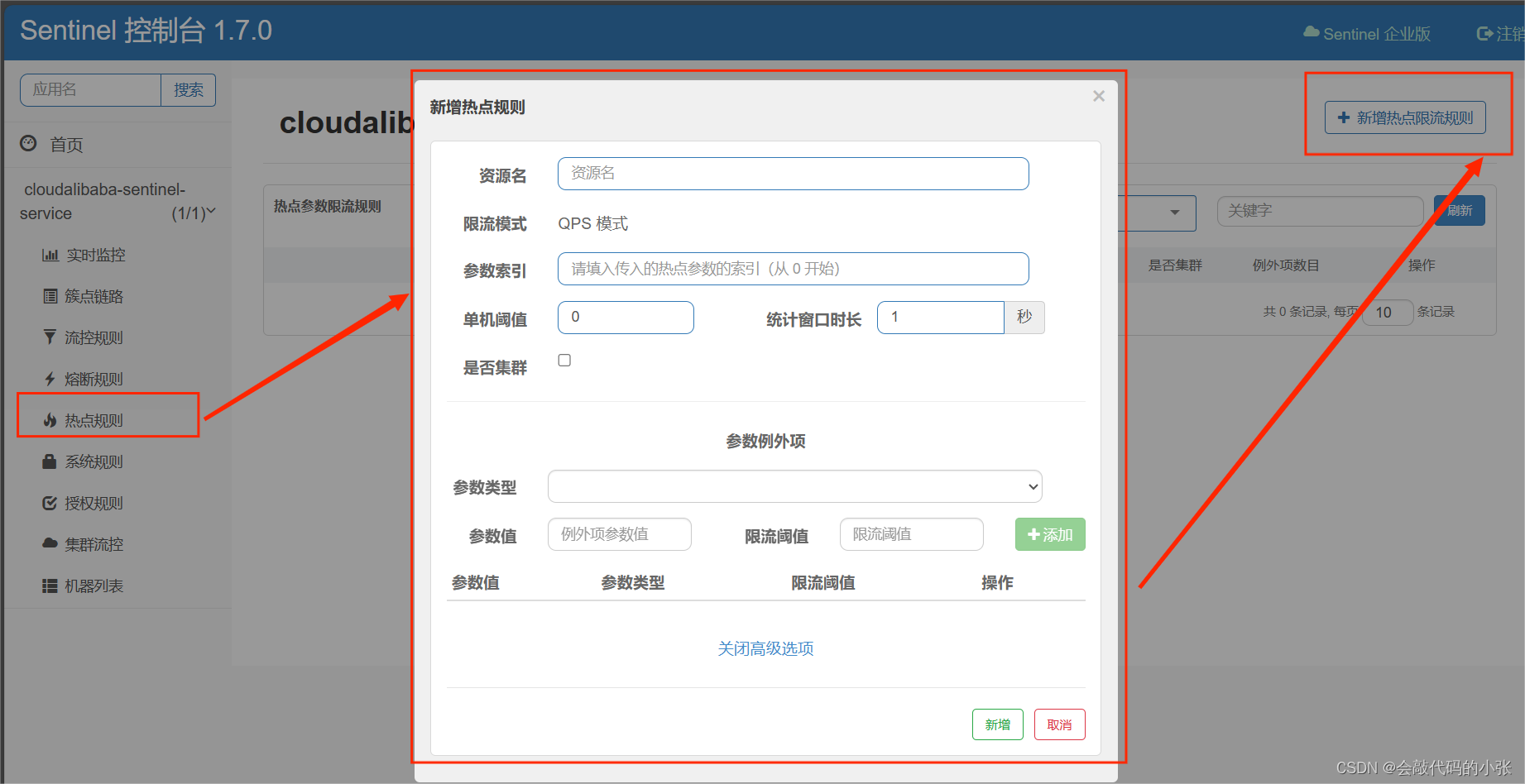
本文的目标是通过突出深度多模态学习领域的进展、差距和挑战,提供对深度多模态学习现状的全面调查,并提出未来研究方向。考虑到在领先的会议和期刊中发表的应用于多模态数据的深度学习技术不断增加,我们认为这一综述具有时效性,如图1所示。
本文的核心集中在深度多模态学习研究的两个重要关注领域:1) 使用正则化技术改进跨模态学习的方法(见“多模态正则化”部分);以及2) 通过搜索、优化或某些学习过程尝试找到最优深度多模态体系结构的方法(见“融合结构学习与优化”部分)。
背景
在我们的综述中,我们采用Lahat等人提供的定义[2],其中我们考虑使用多个传感器观察到的现象或系统,每个传感器输出可以称为与单个数据集相关联的模态。使用多模态数据的基本动机是,对于给定的学习任务,可以从考虑的每个模态中提取互补信息,产生更丰富的表示,相较于仅使用单一模态,可以实现更好的性能。有许多从使用多模态数据中受益的实际任务。例如,在医学图像分析中,使用多种成像模态,如计算机断层扫描(CT)、磁共振成像(MRD)和超声成像,提供了医学专家在诊断和治疗中常规使用的互补信息。涉及人机交互的应用广泛使用深度和视觉线索,如沉浸式游戏和自动驾驶。类似的性能改进也可以在生物特征应用中看到。在遥感应用中,来自不同传感器的数据(强度图像、合成孔径雷达和光探测与测距(LIDAR))经常被融合。
长期以来,研究界一直在探讨涵盖不同应用领域的多模态数据融合技术[3],[4]。传统上,从数据融合的角度研究如何组合多个传感器的信号。这被称为早期融合或数据级融合,侧重于如何最好地组合来自多个源的数据,无论是通过消除模态之间的相关性还是将融合的数据表示在更低维度的共同子空间中。实现这些目标的技术包括主成分分析(PCA)、独立成分分析和典型相关分析。然后,将融合的数据呈现给机器学习算法。当集成分类器在2000年代初变得流行时[5],研究人员开始应用属于被称为后期融合或决策级融合的范畴的多模态融合技术。总体而言,这些后期融合策略比早期融合策略更容易实现,尤其是当不同模态在数据维度和采样率方面差异显著时,往往导致性能的提高。
如在“中间融合”部分所示,流行的深度神经网络(DNN)架构允许第三种形式的多模态融合,即学到的表示的中间融合,为众多实际问题提供了一种真正灵活的多模态融合方法。由于深度学习架构在其隐藏层中学习底层数据的分层表示,不同模态之间的学到的表示可以在各个抽象层次上进行融合。
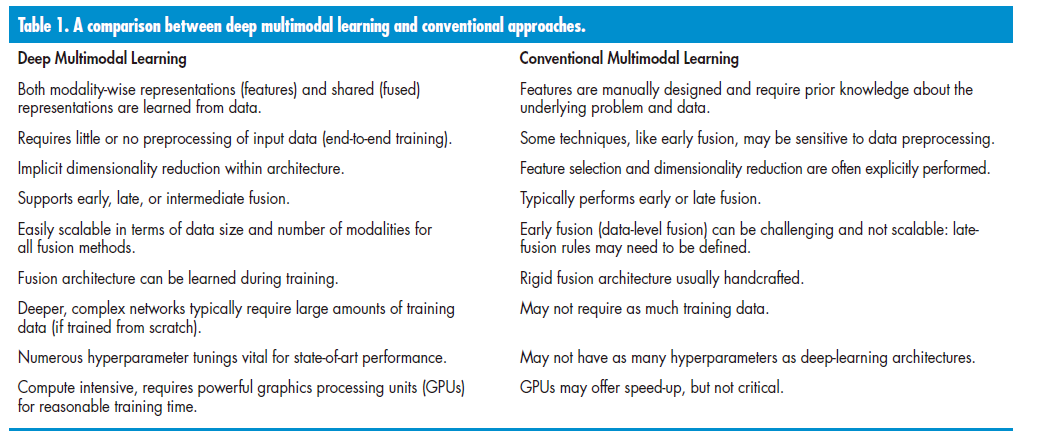
基于深度学习的多模态学习相对于传统的机器学习方法具有几个优势,这些优势在表1中进行了突出显示。对于许多实际问题,深度学习模型通常在涉及多模态数据的问题上提供了更好的性能。然而,这涉及到一些我们接下来将讨论的架构设计选择。
其中一个设计选择涉及何时融合不同的模态。从传统的数据融合角度来看,从业者可以在数据级别融合各种输入模态,然后继续训练单个机器学习模型,但正如我们在“早期融合”部分中所讨论的,这个选择可能相当具有挑战性。或者,也可以考虑后期融合选项,并在“后期融合”部分中审查该类别中的几项工作。深度学习的一个重要特征是其能够从原始数据中学习分层表示。这一特征可以在多模态学习中加以利用,以对学到的表示如何融合进行精细的控制。因此,在多模态深度学习中的一个常见做法是构建一个共享表示或融合层,该层可以合并模态的传入表示,从而迫使网络学习其输入的联合表示。最简单的融合层是一个包含隐藏单元的层,每个单元从所有模态接收输入。在不同抽象层次上学习跨模态共享表示的灵活性可以被利用来实现更好的多模态融合结果;然而,问题仍然存在:在表示的哪个深度融合会达到最优?
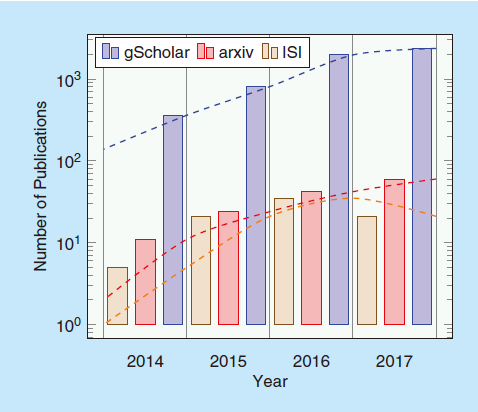
图1:深度多模态学习日益增长的研究兴趣。数据是通过分析技术出版物的主要搜索引擎(Google Scholar、arXiv和Thomson-Reuters’ ISI)的搜索结果生成的。我们使用了搜索词多模态、融合和深度学习,并应用搜索过滤器以包括工程、计算机科学和数学领域的参考文献,排除了与社会科学、神经生物学和商业相关的结果。请注意,由于返回结果方面的差异,我们使用了半对数刻度。
深度多模态学习的第二个架构设计选择涉及要融合哪些模态。在多模态融合中的基本假设是,不同的模态对解决手头任务提供了互补的信息。然而,可能情况是,包含所有可用的模态最终对机器学习算法的性能产生不利影响,因此可能需要某种形式的特征选择。在“融合结构学习与优化”部分,我们讨论了在训练过程中可以自动学习最优融合顺序和深度的一些技术。
第三个设计选择涉及处理缺失数据或模态。在推断过程中,深度多模态学习模型应该足够强大,以弥补缺失的数据或模态。在这种情况下,通常使用生成模型。
大多数深度多模态学习方法还涉及从原始数据中进行表示学习。通常情况下,深度多模态架构利用了几个针对特定类型数据进行优化的标准模块或“构建块”。选择哪个深度学习模块最适合提取给定模态的相关信息也是一个重要的架构设计选择。例如,当考虑二维像素数据时,通常会优先选择卷积架构。三维卷积网络可以用于体积数据,如CT、MRI或甚至视频。当使用时间数据时,可以整合循环神经网络(RNN)的变体,如长短时记忆(LSTM)或门控循环单元。
选择模态-wise 深度学习架构主要取决于输入的维度,或者是否需要学习时间趋势。在这些常见的架构选择之外,根据可能涉及数据集属性甚至用于训练或部署的硬件的特定应用需求,由读者决定。
应用领域
本节旨在概述深度多模态学习引起浓厚兴趣的各种应用领域。尽管多模态学习和融合是一个广泛研究的主题,但深度多模态学习直到Ngiam等人[6]和Srivastava和Salakhutdinov [7]的研究之后才开始引起注意。这些早期的深度多模态融合作品仅涉及两种模态:图像和文本。Ngiam等人[6]研究了包括简单连接输入和共享表示学习在内的多种多模态融合方法,以及跨模态学习(在训练期间所有模态的数据都存在,但在测试期间只有单一模态可用)。与此同时,Srivastava和Salakhutdinov [7]也在深度学习框架中展示了融合涉及图像和文本的不同模态的高级表示的效用。一个显著的发现是,通过简单连接传入连接构建多模态融合层导致相对较差的结果,揭示了隐藏单元与来自单个模态的变量之间存在强连接,但很少有单元跨模态连接。他们还发现,为了成功地捕捉跨模态相关性,至少需要一个非线性阶段,因为单个模态的高级表示将相对“模态无关”,因此更容易融合。这些早期的探索成为深度多模态学习中一系列后续工作的基础,这些工作研究了各种正则化策略(见“多模态正则化”部分),以强制学习模态间关系的约束。
人类活动识别
一个重要的研究领域,大量利用多模态数据的是人类活动识别。在这个庞大的研究大伞下,有许多子领域与人类理解的某些方面相关。鉴于人类在社交环境中表现出高度复杂的行为,因此对于机器学习算法来说,需要多模态数据来对其人类行为进行分类或“理解”是很自然的。不足为奇的是,我们发现近年来许多深度多模态融合的研究作品侧重于典型涉及音频、视频、深度和骨骼运动信息等模态的多媒体数据。多模态深度学习方法已被应用于涉及人类活动的各种问题,如动作识别(一个活动可能由两个或更多短动作序列组成)、手势识别[8]、凝视方向估计[9]、人脸识别[10]和情感识别[11]。智能手机的普及,其配备了不少于十个传感器,催生了涉及多模态数据的新型应用,如连续生物特征认证[12]和活动识别[13]。相关的研究子领域包括人体姿态估计[14]和语义场景理解[15]。
我们预计在可预见的未来,深度学习研究社区将继续关注这些问题。这不仅体现在发表的多模态深度学习论文数量上,还体现在在线提供的数据集和公共挑战的不断增加(见表2)
医学应用领域
深度学习在医学应用中已成为一个引起极大关注的重要应用领域。以医学影像为例,它包括多种多样的多模态数据,以不同的医学成像模态形式存在,如磁共振成像(MRI)、计算机断层扫描(CT)、正电子发射断层扫描(PET)、功能性磁共振成像(fMRI)、X射线和超声。尽管新的医学影像技术取得了显著的进展,但对这些模态进行诊断仍然需要经过高度训练的人类专家。传统的计算机视觉方法需要手动设计形态特征表示。然而,将人类专家的默契知识转化为计算形式并非易事。在医学影像领域,手动设计适用的图像特征非常具有挑战性,因为它不仅涉及对微小的视觉标记和异常的解释,通常需要多年的医学培训,还涉及融合来自多个成像模态的互补和可能冲突的信息。因此,通过示例学习这些多模态特征的能力,正如深度学习在计算机视觉中的成功所示,促使研究人员调查其在医学领域的适用性。因此,不足为奇的是,近年来医学图像分析研究的数量越来越多[16],既包括单模态也包括多模态,涉及基于深度学习的方法。
多模态深度学习已在涉及组织和器官分割[17]、多模态医学图像检索[18]、多模态医学图像配准[19]和计算机辅助诊断[20]的问题中得到应用。Mamoshina等人最近的一篇综述文章[21]展示了深度神经网络(DNNs)的日益流行,包括在涉及基因组、蛋白质组和药物数据的生物医学应用中实现多模态融合的模型。
应用于医学应用的基于深度学习的方法面临两个主要挑战:1)获取足够标记数据的难题和2)类别不平衡问题(负例远远超过正例的情况)。为了克服第一个挑战,早期的方法采用了基于块的训练[22]。最近,利用迁移学习的技术取得了惊人的成功[23]。这涉及在一个独立的大型数据集上重用由非常深的网络学习到的与数据无关的表示,例如ImageNet,然后只对网络的上层进行微调或重新训练,使用一个规模小得多的医学数据集。另一种常见的技术是进行训练数据增强,例如应用不同的仿射变换或随机扰动图像的亮度和对比度,以增加可用的训练数据量。为了解决数据不平衡问题,通常会在损失函数中应用某种形式的加权,使在多数类上犯的错误比在少数类上犯的错误受到更少的惩罚。这些挑战,尽管在医学领域的问题中非常常见,也可能发生在其他领域,因此解决方案同样适用。然而,尽管深度学习在医学应用中取得了成功,医学界对在现实世界中部署它们仍然持谨慎态度,因为深度学习通常被视为不透明。鉴于设计可解释的深度神经网络的不断努力[24],[25],这种观点可能会逐渐改变。
自主系统
在深度学习取得成功后,自主导航(也称为自动驾驶)应用的兴趣激增,这些应用通常涉及从安装在车辆上的传感器获取的多模态数据。例如,一辆自动驾驶汽车可能包括多个外部和内部传感器,包括雷达、立体视觉可见光摄像机、激光雷达、红外(IR)摄像机、全球定位系统(GPS)和音频。为了进行自主导航,从传感器收集的异构数据被用于学习一些相互关联但复杂的任务,如定位和地图绘制、场景理解、运动规划和司机状态识别。
自主导航的最大挑战之一是操作环境的动态性——系统必须适应和对天气变化、光照变化、行人和其他交通、道路状况以及交通标志等作出反应。然而,深度学习和强化学习技术[26]在推动这个应用领域的发展方面发挥了重要作用,Uber、Nvidia、Baidu和Tesla等行业参与者积极参与商业自动驾驶汽车的开发。
在自动驾驶中的一个重要任务是实时场景理解。它要求学习系统识别场景中的对象,如车道、交通标志、行人和其他交通。因此,对于多模态视频流的每一帧,首先必须执行语义分割。然后必须定位场景中识别的每个语义概念。对于这样的任务,通常使用执行每一帧像素级标注的深度全卷积架构[27]。对于多模态输入,一个常见的策略是在输入到全卷积神经网络(CNN)之前,沿通道维度连接同步帧(这在某种程度上是早期融合),或者在深层次的多模态网络中训练单独的模态网络,然后进行融合。我们在“融合结构”部分进一步讨论了这样的融合策略。通过使用全卷积神经网络的三维变体,语义分割可以扩展到视频。自动驾驶车辆技术中使用的基本技术可以扩展到其他机器人应用,如移动机器人或无人机导航、抓取配置学习[28]和机器人操纵[29]。
总结
我们突出了深度多模态学习方法已经站稳脚跟并持续迅速发展的三个主要领域。除了已经在每个关键领域中强调的工作之外,我们在表3中列出了涉及深度多模态学习的其他代表性工作。在我们讨论特定深度学习模型的地方,我们还强调了涉及文本、图像和视频的几个其他应用领域,例如视觉问题回答(VQA)和图像以及视频注释。
模型
将多模态深度学习应用于新问题涉及选择体系结构和学习算法两者。总体而言,我们将这些选择称为模型。已经提出了各种不同的深度学习模型用于多模态数据。虽然有多种对它们进行审查的方法,但我们选择根据它们的学习范式将显著的例子分组和组织起来,具体来说是它们是生成的、判别的还是混合的模型。我们选择这种分类的原因是这种选择会影响可以选择的体系结构和学习算法。
生成模型隐式或显式地表示数据分布,通常允许通过一个过程对新数据进行抽样或“生成”,因此得名。另一方面,判别模型则不那么雄心勃勃。与其对分布进行建模,它们试图对类别边界进行建模。在监督学习的设置中,我们有数据X和标签Y,生成模型学习联合概率P(X,Y)。相反,判别模型主要用于预测任务,这些模型学习条件概率P(Y | X)。然而,生成模型仍然可以具有判别特性。生成模型的一个优势是它们更加灵活。例如,在推断过程中可以对P(X,Y)进行抽样,以解决缺失模态的情况。

判别模型
判别性深度体系结构直接对输入到输出的映射进行建模,模型参数通过最小化一些正则化损失函数来学习。这样的模型构成了提出的多模态学习模型的主体,任务包括各种问题领域的分类或识别
除了上述的积极研究问题外,图像字幕和VQA[36]这两者都将自然语言处理和机器学习算法的高级场景解释结合起来,引起了积极的研究兴趣。在深度图像字幕中,模型需要生成图像内容的文本描述,这可以通过使用判别技术[37]、[38]和生成方法[39]来实现。另一方面,VQA通常要求模型基于图像内容回答复杂问题,这是一个生成任务。这个问题也可以转化为一个判别性的设置(例如,多项选择问题)[40]。最近,Kim等人[41]扩展了非常成功的深度残差网络模型,用于多模态VQA问题。由于多种模态可能存在相关性,作者精心设计了跨模态的联合残差映射,并在VQA方面取得了最先进的结果。
判别性深度多模态学习模型也已被提出用于人类活动识别。随着RGB-深度(RGB-D)摄像机的廉价可用性和带有众多传感器的智能手机的普及,涉及四到五种模态的深度多模态学习体系结构已经被报道。这些问题涉及时间数据(视频、关节运动、音频),有效地学习时空依赖关系是必不可少的。为了捕捉时空结构和关系,深度多模态学习方法通常使用时空组件,如LSTM或隐马尔可夫模型,结合视觉表示学习层,如CNN或3D-CNNs[42],[43]。这些模型从CNN和循环层的组合中受益,这两者可以共同捕捉时空关系
还有一些工作的例子,其中生成模型已经被调整用于执行判别任务。例如,Larochelle和Bengio[44]提出了RBM的判别变体(深度信念网络(DBNs)和深度玻尔兹曼机的构建模块)。在讨论“人类活动识别”、“医疗应用”和“自主系统”等部分时,已经提到了其他判别模型。此外,表3还列举了其他多模态问题的判别模型的例子。尽管判别模型擅长分类或回归任务,但在存在缺失数据或模态时无法应对。判别模型还需要大量标记数据,在某些应用中可能昂贵。接下来,我们将审查深度生成多模态模型,考虑判别模型的缺点,深度生成多模态模型提供了一些优势。
生成模型
深度生成模型通常用于表征可见数据的高阶相关性质,以进行模式分析或合成。它们还可以用于表征可见数据及其相关类别的联合统计分布。生成模型如DBNs也可以通过利用它们从未标记数据中学习(无监督学习)的能力,并使用反向传播算法进行判别性微调,或者与其他分类器(如支持向量机)一起使用所学表示进行分类和回归任务。
对于多模态学习问题,生成模型在测试时可能存在缺失模态或缺乏标记数据的情况下是有用的。Ngiam等人的早期工作[6]和Srivastava和Salakhutdinov[30]证明了生成模型确实能够处理这样的学习问题。此后,文献中报道了许多专门处理存在缺失数据情况下使用生成深度多模态网络的作品[31],[45]。
虽然基于堆叠受限玻尔兹曼机(RBM)的能量模型在深度生成式多模态学习中受到了广泛关注,但生成模型的格局正在发生变化。最近,生成对抗网络[46],使用变分推断训练的深度有向模型[47]在多模态和单模态环境中变得越来越受欢迎[48]–[50]。
混合模型
尽管判别模型的训练目标是最大化类别之间的区分度,生成模型擅长建模数据分布。混合模型在一个统一的框架中结合了判别和生成组件。邓[51]将混合深度体系结构定义为目标是判别的体系结构,但是通过生成体系结构的结果进行了辅助(通常是以显著的方式)。例如,在混合模型中,生成组件可以学习输入模态的深层表示,并使用判别组件进行分类或回归任务。混合模型可根据[52]分为三组:
- 联合方法,通过优化单一目标函数来学习使用生成和判别组件的联合表示
- 迭代方法,使用迭代方法(例如使用期望最大化)学习共享表示,使用从生成和判别组件更新的表示
- 分阶段方法,生成和判别组件在不同阶段分别进行训练。通过无监督方式生成模型学到的表示可以通过监督训练用作判别组件的特征。
[53]报告了一个联合模型的例子,其中通过组合前者的条件RBM时间生成模型和后者的由条件随机场组成的判别组件,对音频-视频模态的短期时间特征和长期时间依赖性进行建模。该模型还能够处理由于生成组件而导致的模态缺失。其他相关的混合体系结构包括Sachan等人的[54]和Liu等人的[55]。
总结
在本节中,我们根据它们的主要学习范式突出了多模态体系结构。在某种意义上,深度学习模型可以被看作是允许我们“混搭”不同模型以创建复杂深度多模态体系结构的构建模块。虽然这可以被视为深度学习的优势,但一个常见问题是体系结构设计更像是一门艺术而不是科学。尽管如此,与每个模型相关的许多超参数必须仔细微调,而在处理混合体系结构时,这个过程可能甚至更加复杂。另一个需要关注的方面是模态和它们表示之间融合结构的选择。接下来,我们将讨论多模态融合结构的几种选择,并将讨论引向优化和学习这种融合体系结构以获得更好性能的吸引人的概念。
融合结构
深度体系结构提供了实施多模态融合的灵活性,可以是早期、中期或晚期融合。在深度学习出现之前,多模态融合方法通常将早期融合称为特征级融合,将晚期融合称为决策级融合。然而,使用深度学习方法,特征级融合的概念可以进一步扩展到中期融合的概念。
早期融合
早期融合涉及将多个来源的数据,有时是非常不同的数据,集成到单个特征向量中,然后作为输入传递给机器学习算法,如图2(a)所示。要融合的数据是传感器的原始或预处理数据;因此,通常使用数据融合或多传感器融合这些术语。
如果在不进行特征提取的情况下执行数据融合,这可能会非常具有挑战性。例如,不同传感器之间的采样率可能不同,或者来自多个数据源的同步数据可能在一个源产生离散数据的情况下不可用,而另一个源则提供连续数据流。
为了缓解与融合原始数据相关的一些问题,可以首先从每个模态中提取更高级别的表示,这可能是手工制作的特征或学习表示,正如在深度学习中常见的那样,然后在特征级别进行融合。当使用非分层特征时,如手工制作特征中经常发生的情况,从多个模态提取的特征可以仅在一个级别融合,然后输入到机器学习算法中。由于深度学习基本上涉及从原始数据中学习分层表示,这导致了中期融合的产生。
大多数早期融合模型都采用了一个简化的假设,即各种信息源的状态之间存在条件独立性。在实践中这可能不成立,因为多个模态往往高度相关(例如,视频和深度线索)。Sebe [56]认为,不同的流包含的信息在高层次上只与另一个流相关。这个假设允许每个模态的输出独立于其他模态进行处理。
在其最简单的形式中,早期融合涉及多模态特征的串联,就像Poria等人[34]所实施的那样。多模态数据的早期融合可能无法充分利用所涉及模态的互补性,可能导致包含冗余的非常大的输入向量。通常,会应用维度缩减技术(如PCA)来消除输入空间中的这些冗余。自编码器是PCA的非线性推广[58],在深度学习中被广泛用于从原始数据中提取分布式表示。这个想法已经被扩展,以学习一个旨在在共同特征空间内表示多模态数据的多模态嵌入空间[59],[60]。
在早期融合多模态数据时面临的问题之一是确定不同数据源之间的时间同步性。通常,这些信号以共同的采样率重新采样。为了减轻这个问题,Martínez和Yannakakis[61]提出了几种方法(卷积、训练和池化融合),以集成离散事件序列和连续信号。
晚期融合
晚期融合或决策级融合是指从多个分类器中聚合决策,每个分类器都在单独的模态上进行训练[见图2(b)]。这种融合架构通常受欢迎,因为来自多个分类器的错误往往不相关,而且该方法与特征无关。存在各种规则来确定如何组合来自不同分类器的决策。这些融合规则可以是最大融合、平均融合、基于贝叶斯规则的融合,甚至可以使用元分类器进行学习。在机器学习社区广泛关注集成分类器的早期到中期2000年代,决策级融合曾经非常流行。有一些研究采用了深度多模态学习的晚期或决策级融合[33],[43],[62],除了表3中列出的一些研究。根据我们审查的论文,我们没有找到确凿的证据表明晚期融合优于早期融合——性能在很大程度上取决于具体问题。毫无疑问,当输入模态显着不相关,具有非常不同的维度和采样率时,更容易为多模态学习问题实现晚期融合方法。另一种选择,即中期融合,提供了从多模态数据中学到的表示何时以及如何进行融合的更大灵活性。
中期融合
神经网络通过将输入映射到一系列层的流水线中,将原始输入转换为更高级别的表示。每个层通常交替执行线性和非线性操作,这些操作对其输入进行缩放、平移和扭曲,从而生成原始数据的新表示。在多模态环境中,当所有模态都被转换为表示时,就可以将不同的表示融合到单个隐藏层中,然后学习一个共同的多模态表示。深度多模态融合中的大多数工作都采用这种中期融合方法,其中通过将来自多模态专用路径的连接输入到这一层的单元进行构建共享表示层,如图2©所示。表示(特征)是使用不同类型的层学习的(例如,2-D卷积、3-D卷积或完全连接的层),并且使用融合层(也称为共享表示层)融合这些表示。
这个共享表示层可以是一个单独的共享层,在某个深度上融合多个通道,也可以逐渐融合,一次融合一个或多个模态。在共享表示层或融合层通过对来自不同模态的权重进行简单串联后,天真地对特征或权重进行串联可能导致过拟合或网络无法学习由于不同的底层分布而导致的模态之间的关联。提高多模态融合性能的一种简单方法是在通过对来自不同模态的权重进行简单串联构建共享表示层(或融合层)之后应用一些形式的降维,如PCA [63] 或堆叠的自编码器 [10]。在不同深度融合各种表示的选择可能是深度多模态融合的最强大和灵活的方面,与其他融合技术相比。灵活融合方案的优势可以在Karpathy等人的工作中看到[64],他们展示了使用“慢融合”模型在训练过程中逐渐融合视频流的学习表示,相对于早期融合和晚期融合模型,对于大规模视频分类问题始终产生更好的结果。同样,Neverova等人[8]在实证中显示,通过首先在渐进的方式中将高度相关的模态融合到不太相关的模态中(例如,首先是视觉模态,然后是动作捕捉,然后是音频),可以为交际手势识别产生最先进的结果。
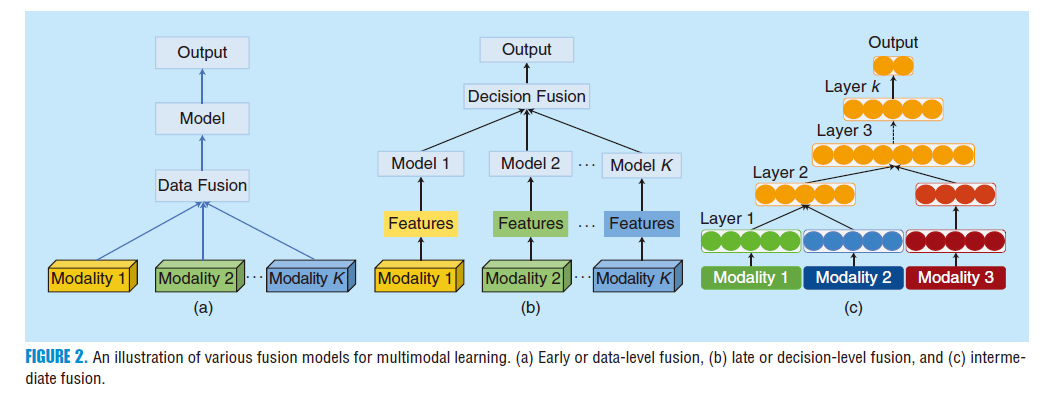
尽管使用共享表示层学习多模态表示确实具有灵活性,但许多当前的体系结构在何时、何地以及哪些模态可以融合方面需要仔细设计。在“多模态融合结构学习与优化”部分,我们进一步讨论了尝试优化多模态学习所需的繁琐体系结构设计过程的努力。
多模态正则化
深度学习技术通过最小化损失函数来迭代优化一组模型参数(通常是每一层之间的权重和偏置),以提高泛化性能,通常作为添加到损失函数的附加项。从计算的角度来看,正则化为优化问题提供了稳定性,导致算法加速,从统计的角度来看,正则化减少了过拟合[65]。
在深度多模态学习背景下,一个重要的设计考虑是制定强制执行模态间和模态内关系的代价函数和正则化器,例如信息论正则化器和结构正则化,我们现在简要回顾一下。
信息论正则化器是使用诸如互信息和信息变差的度量制定的。例如,Sohn等人[66]提出了一个成本函数,通过最小化模态之间的信息变差来学习模态之间的关系。这个公式背后的直觉是,学习如何最大化一个数据模态关于其他数据模态的信息量将允许生成模型根据部分观察推理出缺失的数据模态。或者,也可以在训练期间最大化互信息项[67]。基于Kulback-Leibler(KL)散度的另一种基于信息论的损失公式由Zhu等人[68]提出,用于多标签图像注释问题。在预训练阶段,他们首先使用未标记的数据通过反向传播最小化预测和地面实况分布之间的KL散度,从而从每个模态学习中间表示。最后,为了学习多模态权重的最佳组合,他们采用了指数化的在线学习算法,以顺序找到最佳的组合权重集。
受多任务学习中结构化特征选择的启发[69],Wu等人[70]设计了一种模型,使用迹范数正则化项,鼓励类似的模态在视频分类问题中共享相似的表示,使用视频和音频模态。还通过Wang等人[71]探讨了强制执行模态间和模态内相关性的代价函数。他们的公式包括一个判别项和一个基于典型相关分析的相关项。在后续工作中[72],他们提出了一个多模态融合层,使用矩阵变换明确强制实现一个由不同模态特征共享的公共部分,同时保留模态特定的学习。
Lenz等人[28]在成本函数中制定了一个结构正则化项,该项允许模型学习多个输入模态之间的相关特征,但规范化每个特征使用的模态数量,从而阻止模型学习模态之间的弱相关性。结构正则化基本上为每组模态特定权重分别应用某种形式的正则化。他们考虑了多种结构正则化的变体,用于多模态机器人抓取任务。在他们的情况中,其中一种表现良好的方法包括在最大范数惩罚之上应用L0范数。
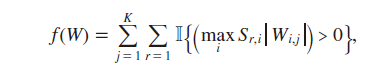
其中,Sr,i等于1,如果特征i属于组r,否则为零。S是一个大小为R×N的二进制模态矩阵,其中每个元素Sr,i表示一个可见单元xi在特定模态r中的成员资格。I是一个指示函数,如果其参数为真,则值为一,否则为零。
在某些问题中,时间上下文可能起到重要作用,例如司机活动预测。与人类活动识别不同,司机活动预测中,机器学习系统必须仅在事件发生之前的短时间内使用部分上下文进行预测。为解决这个问题,Jain等人[35]在其具有LSTM单元的多模态RNN的成本函数中引入了一个随时间呈指数增长的时间项。这鼓励模型尽早纠正错误。
多模态感知正则化器在模型性能上带来了边际到显著的改进。尽管包括这些多模态正则化策略,但本节讨论的深度学习体系结构仍将输入模态合并到单个融合层中。可能的扩展是研究一个渐进融合模型,以利用这些正则化策略。
融合结构学习和优化
迄今为止,大多数提出的多模态深度学习体系结构都是精心设计的。虽然许多模型采用单一融合层(共享表示层),但一些杰出的工作[8] [64]实施了逐渐融合的策略。选择融合哪种模态以及在哪个深度表示通常基于直觉(例如,尽早融合相似的模态,然后在更深的层次融合不同的模态)。当涉及到两个以上的模态时,还取决于在问题中使用的模态的性质,选择最佳融合架构可能更具挑战性。一个自然的进展是将寻找最佳多模态融合架构视为一个模型搜索或结构学习问题。
神经网络结构的优化在单模态问题上一直是机器学习研究人员长期探讨的问题。这主要涉及确定网络中神经元的最佳数量和层数。存在着网络的良好泛化能力、参数数量和训练数据可用性之间的权衡。如果使用足够大的训练数据训练,太大的网络可能表现良好或过拟合,而太小的网络可能欠拟合,并可能导致泛化性能不佳。
一种常见的方法是采用自下而上的构造方法。Elman[73]提出的基本思想是从一个相对较小的网络开始,逐步增加隐藏单元或层,直到找到性能最佳的架构。更近期,在大规模设置中,Chen等人[74]通过在一个神经网络到另一个神经网络之间进行知识转移,逐渐向inception风格[75]网络添加深度和宽度。
剪枝算法[76]采用自上而下的方法解决了相同的问题。近期的深度神经网络(DNN)方法包括Feng和Darrel提出的[77],他们提出了一种进化的生长和剪枝算法,优化了印度自助餐过程-CNN模型的结构;以及Yang等人[78],他们基于稀疏表示引入了大型多样化数据集的网络剪枝。
基于遗传算法(GA)的神经网络结构优化是最早用于神经网络结构搜索和优化的元启发式搜索算法之一[79]。在2000年代初,一种名为“Neuro Evolution of Augmenting Topologies”(NEAT)的算法[80]也使用GA来演化越来越复杂的神经网络架构,引起了广泛关注。更近期,Shinozaki和Watanabe[81]应用了GA和协方差矩阵演化策略来优化DNN的结构,将DNN的结构参数化为基于有向无环图表示的简单二进制向量。由于GA搜索空间可能非常庞大,并且在搜索空间中每个模型评估都很昂贵,因此使用大型GPU集群进行并行搜索以加速该过程。
这些神经网络结构搜索和优化技术可以轻松扩展到多模态环境中,如果设计了网络架构的合适表示,并且在搜索过程中训练和测试多个架构的成本不是禁止性昂贵的。随着数据集大小接近千兆字节,甚至是太字节级别,以及包含数百万参数和多个模态的深度网络架构,多模态融合结构的搜索和优化可能变得非常昂贵,除非实施一些并行搜索过程或使用高效的优化算法。虽然贝叶斯优化(BO)[82]一直是超参数优化的热门选择,但最近已经用于多模态融合结构的优化[83]。通过使用基于高斯过程的BO,将架构优化作为离散优化问题,搜索所有可能的多模态融合架构的空间。提出了一种新颖的图诱导核来量化搜索空间中不同架构之间的距离。
强化学习[84]也被用于深度神经结构搜索[85]。该工作提出了一种新颖的方法,使用RNN生成可变长度的神经网络模型描述。RNN通过强化学习进行训练,以最大化生成的架构在验证集上的预期准确性。
近期的一些研究将结构学习视为网络中的正则化手段或容量控制。通过以随机方式剪枝网络,可以将随机正则化方法视为通过模型平均来改善泛化的一种集成方法。Kulkarni等人[86]通过确定性正则化实现了学习DNN结构的方法。他们在每一对全连接层之间插入一个稀疏对角矩阵,其条目受到l1惩罚。这隐式地定义了每层有效权重矩阵的大小。该方法具有与Dropout [87]类似的效果。Blockout [88]通过一种巧妙的技术实现了对隐藏单元的随机分配到“簇”中,形成块状结构的权重矩阵,从而同时进行正则化和模型选择。此外,通过对多个随机推断通道的输出进行平均(可以视为集成分类器的一种情况),取得了比ResNets更好的结果。这种架构有效地实现了多个架构的后期融合,以取得更好的结果。
Stochastic regularization已经被扩展到多模态环境中,由Neverova等人[8]和最近由Li等人[89]提出。在后者的研究中,作者表明,当模态间相关性较高时,通过网络学习的融合结构的早期融合方法产生了更好的结果,而在输入模态相关性较低时,后期融合方法效果更好。这与前者的经验选择一致。
在本节中,我们介绍了一些最近的研究,它们使用随机正则化或优化,从而实现了与精心设计的架构相媲美甚至更好的深度多模态融合架构。虽然深度表示学习已经在很大程度上解决了特征工程的问题,但下一个合乎逻辑的步骤将是摆脱对深度架构的繁琐工程,追求能够自动实现这一目标的技术。
数据集
为了促进多模态学习领域的研究,已经向公众发布了许多数据集。我们注意到,其中大多数数据集通常涉及以人为中心的视觉理解,变体包括情感识别、群体行为分析等。表2列出了一些此类数据集,涉及的模态以及问题领域。虽然这个列表并不是详尽无遗的,我们涵盖了更近期(许多是在过去三年内发布的)供多模态研究使用的数据集。虽然大多数数据集至少包含两种模态(例如图像和文本),或多达四种(RGB-D、音频和骨架姿势),但一些数据集,例如H-MOG [12],包括多达九种不同的模态。对于感兴趣的读者,Firman [90] 提供了对102个RGB-D数据集的广泛调查。自主驾驶和驾驶员辅助系统(使用驾驶员行为预测)是深度学习中的一个热门研究课题。这些数据集不仅高度多模态[91],而且非常庞大——包含来自多达六个个体传感器的数据,而且数据量非常大——长达一年的驾驶数据在各种天气条件下都有。例如,牛津RobotCar [92]数据集包含超过23TB的全年驾驶数据,记录了各种天气条件下的行车情况。
我们注意到,相对较少的是多模态医学数据集,可能是由于成本以及伦理和隐私问题。大多数医学数据集也往往较小,涉及10到50名受试者,并且还存在高度的类别不平衡(例如,与异常病例相比,正常病例更为常见)。医学信息学和影像学研究对多模态信息的依赖较大,这可以用来改进计算机辅助诊断。鼓励努力收集并公开提供此类数据集。
结论与未来方向
在本文中,我们回顾了深度多模态学习领域的最新进展。不可否认的是,将多模态纳入学习问题几乎总是能够在广泛的问题领域中获得更好的性能。从融合的角度来看,我们看到深度多模态学习中的技术可以分为早期融合和晚期融合方法,深度学习方法提供了一种灵活的中间融合方法,不仅使模态表示的融合更加简单,学习联合表示,还允许在架构的各个深度处进行多模态融合。尽管深度学习在许多情况下减少了对特征工程的需求,但深度学习架构仍然涉及大量手工设计,实验者可能没有探索可能的融合架构的完整空间。研究人员自然应该将学习的概念扩展到架构中,以实现真正通用的学习方法,可以在最小或没有人类干预的情况下,针对特定任务进行调整。
我们回顾了学习最佳架构的几种选择。这包括随机正则化、将架构优化视为超参数优化问题,例如使用BO,以及增量在线强化学习。这在我们看来是深度多模态学习中最令人兴奋的研究领域。架构学习可能非常计算密集,因此研究人员应该充分利用硬件加速和分布式深度学习的进展。
我们还确定了在深度多模态学习中引起最大关注的几个应用领域。这包括RGB-D和来自移动手机上众多传感器的数据,已被用于涉及多模态数据的一系列问题,如人类活动识别及其变体。我们预见到在未来几年中,这一领域将在新的应用方面获得更多关注,这将深刻影响我们的日常生活。另一个重要的领域是医学研究,涉及多种数据模态,其中一些模态在没有人类专家介入的情况下很难解释。随着医学界对人工智能辅助诊断的崛起,我们将看到在这一领域取得更重要的进展。最后,还有两个引起深度学习研究人员关注的应用领域,涉及自主车辆或机器人以及多媒体应用,例如视频转录、图像字幕等。像利用多模态数据的在线聊天机器人(例如图像和文本)或推荐系统等新颖应用可能在不久的将来变得普遍。
最后,我们要承认这是一个快速发展的领域,随着大量新研究的发表速度,深度多模态学习架构的许多新创新都有望呈现。我们尽力避免提供特定的架构设计建议,因为我们发现许多问题需要考虑特定的应用场景。尽管如此,我们认为这是一个及时的出版物,我们强调的未来研究方向有望成为推动研究领域更有组织努力的指南。
作者
Dhanesh Ramachandram(dramacha@uoguelph.ca)于1997年获得工业技术学士学位,2003年从马来西亚理科大学获得计算机视觉和机器人学博士学位。曾担任该大学的副教授。他目前是加拿大安大略省圭尔夫大学的研究员,也是IEEE的高级会员。他对计算机视觉、医学成像和多模态问题的深度学习感兴趣。
Graham W. Taylor(gwtaylor@uoguelph.ca)于2003年和2004年分别获得加拿大滑铁卢大学的应用科学学士和硕士学位。他于2009年从加拿大多伦多大学获得计算机科学博士学位,导师是Geoffrey Hinton和Sam Roweis。他是加拿大安大略省圭尔夫大学的副教授,是人工智能研究所的成员,也是加拿大高级研究院Azrieli全球学者。他对统计机器学习和生物启发式计算机视觉感兴趣,重点是无监督学习和时间序列分析。
参考文献
[1] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015.
[2] D. Lahat, T. Adali, and C. Jutten, “Multimodal data fusion: An overview of methods, challenges, and prospects,” Proc. IEEE, vol. 103, no. 9, pp. 1449–1477, 2015.
[3] P. K. Atrey, M. A. Hossain, A. El Saddik, and M. S. Kankanhalli, “Multimodal fusion for multimedia analysis: A survey,” Multimedia Systems, vol. 16, no. 6, pp. 345–379, 2010.
[4] B. Khaleghi, A. Khamis, F. O. Karray, and S. N. Razavi, “Multisensor data fusion: A review of the state-of-the-art,” Inform. Fusion, vol. 14, no. 1, pp. 28–44, 2013.
[5] L. I. Kuncheva, Combining Pattern Classifiers: Methods and Algorithms. Hoboken, NJ: Wiley, 2004.
[6] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal deep learning,” in Proc. 28th Int. Conf. Machine Learning (ICML-11), 2011, pp. 689–696.
[7] N. Srivastava and R. R. Salakhutdinov, “Multimodal learning with deep Boltzmann machines,” in Proc. Advances in Neural Inform. Processing Syst., 2012, pp. 2222–2230.
[8] N. Neverova, C. Wolf, G. Taylor, and F. Nebout, “ModDrop: Adaptive multi-modal gesture recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 8, pp. 1692–1706, 2016.
[9] S. S. Mukherjee and N. M. Robertson, “Deep head pose: Gaze-direction estimation in multimodal video,” IEEE Trans. Multimedia, vol. 17, no. 11, pp. 2094–2107, 2015.
[10] C. Ding and D. Tao, “Robust face recognition via multimodal deep face representation,” IEEE Trans. Multimedia, vol. 17, no. 11, pp. 2049–2058, 2015.
[11] S. E. Kahou, X. Bouthillier, P. Lamblin, C. Gulcehre, V. Michalski, K. Konda, S. Jean, P. Froumenty, et al., “EmoNets: Multimodal deep learning approaches for emotion recognition in video,” J. Multimedia User Interfaces, vol. 10, no. 2, pp. 99–111, 2015.
[12] Z. Sitová, J. Šedeˇnka, Q. Yang, G. Peng, G. Zhou, P. Gasti, and K. S. Balagani, “HMOG: New behavioral biometric features for continuous authentication of smartphone users,” IEEE Trans. Inf. Forensics Security, vol. 11, no. 5, pp. 877–892, 2016.
[13] V. Radu, N. D. Lane, S. Bhattacharya, C. Mascolo, M. K. Marina, and F. Kawsar, “Toward multimodal deep learning for activity recognition on mobile devices,” in Proc. ACM Int. Joint Conf. Pervasive and Ubiquitous Computing: Adjunct, 2016, pp. 185–188.
[14] A. Jain, J. Tompson, Y. LeCun, and C. Bregler, “Modeep: A deep learning framework using motion features for human pose estimation,” in Proc. Asian Conf. Computer Vision, 2014, pp. 302–315.
[15] A. Valada, G. L. Oliveira, T. Brox, and W. Burgard, “Deep multispectral semantic scene understanding of forested environments using multimodal fusion,” in Proc. Int. Symp. Experimental Robotics (ISER 2016), 2016, pp. 465–477.
[16] D. Shen, G. Wu, and H.-I. Suk, “Deep learning in medical image analysis,” Annu. Review Biomedical Eng., vol. 19, pp. 221–248, 2017.
[17] R. Kiros, K. Popuri, D. Cobzas, and M. Jagersand, “Stacked multiscale feature learning for domain independent medical image segmentation,” in Proc. Int. Workshop on Mach. Learning in Medical Imaging, 2014, pp. 25–32.
[18] P. Wu, S. C. Hoi, H. Xia, P. Zhao, D. Wang, and C. Miao, “Online multimodal deep similarity learning with application to image retrieval,” in Proc. 21st ACM Int. Conf. Multimedia. 2013, pp. 153–162.
[19] M. Simonovsky, B. Gutiérrez-Becker, D. Mateus, N. Navab, and N. Komodakis, “A deep metric for multimodal registration,” in Proc. Int. Conf. Medical Image Computer and Computer-Assisted Intervention, 2016, pp. 10–18.
[20] S. Liu, S. Liu, W. Cai, H. Che, S. Pujol, R. Kikinis, D. Feng, M. J. Fulham, et al., “Multimodal neuroimaging neature learning for multiclass diagnosis of Alzheimer’s disease,” IEEE Trans. Biomed. Eng., vol. 62, no. 4, pp. 1132–1140, 2015.
[21] P. Mamoshina, A. Vieira, E. Putin, and A. Zhavoronkov, “Applications of deep learning in biomedicine,” Molecular Pharmaceutics, vol. 13, no. 5, pp. 1445–1454, 2016.
[22] Y. Guo, G. Wu, L. A. Commander, S. Szary, V. Jewells, W. Lin, and D. Shen, “Segmenting hippocampus from infant brains by sparse patch matching with deep-learned features,” in Proc. Int. Conf. Medical Image Computer and Computer-Assisted Intervention, 2014, p. 308.
[23] N. Tajbakhsh, J. Y. Shin, S. R. Gurudu, R. T. Hurst, C. B. Kendall, M. B. Gotway, and J. Liang, “Convolutional neural networks for medical image analysis: Full training or fine-tuning?” IEEE Trans. Med. Imag., vol. 35, no. 5, pp. 1299–1312, 2016.
[24] I. Sturm, S. Lapuschkin, W. Samek, and K.-R. Müller, “Interpretable deep neural networks for single-trial EEG classification,” J. Neuroscience Methods, vol. 274, pp. 141–145, Dec. 2016.
[25] S. G. Kim, N. Theera-Ampornpunt, C.-H. Fang, M. Harwani, A. Grama, and S. Chaterji, “Opening up the black box: an interpretable deep neural network-based classifier for cell-type specific enhancer predictions,” BMC Syst. Biology, vol. 10, no. 2, p. 54, 2016.
[26] C. Chen, A. Seff, A. Kornhauser, and J. Xiao, “Deepdriving: Learning affordance for direct perception in autonomous driving,” in Proc. IEEE Int. Conf. Computer Vision, 2015, pp. 2722–2730.
[27] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2015, pp. 3431–3440.
[28] I. Lenz, H. Lee, and A. Saxena, “Deep learning for detecting robotic grasps,” Int. J. Robotics Res., vol. 34, no. 4-5, pp. 705–724, 2015.
[29] S. Gu, E. Holly, T. Lillicrap, and S. Levine. (2016). Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. arXiv. [Online]. Available: https://arxiv.org/abs/1610.00633
[30] N. Srivastava and R. Salakhutdinov, “Learning representations for multimodal data with deep belief nets,” presented at Proc. 29th Int. Conf. Machine Learning (Workshop), 2012.
[30] N. Srivastava and R. Salakhutdinov, “Learning representations for multimodal data with deep belief nets,” presented at Proc. 29th Int. Conf. Machine Learning (Workshop), 2012.
[31] Y. Cao, S. Steffey, J. He, D. Xiao, C. Tao, P. Chen, and H. Müller, “Medical image retrieval: A multimodal approach,” Cancer Informatics, vol. 13, no. Suppl 3, p. 125, 2014.
[32] M. Liang, Z. Li, T. Chen, and J. Zeng, “Integrative data analysis of multi-platform cancer data with a multimodal deep learning approach,” IEEE/ACM Trans. Comput. Biol. Bioinf., vol. 12, no. 4, pp. 928–937, 2015.
[33] K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” in Proc. Advances in Neural Information Processing Systems, 2014, pp. 568–576.
[34] S. Poria, E. Cambria, and A. Gelbukh, “Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis,” in Proc. Conf. Empirical Methods on Natural Language Processing, 2015, pp. 2539–2544.
[35] A. Jain, A. Singh, H. S. Koppula, S. Soh, and A. Saxena, “Recurrent neural networks for driver activity anticipation via sensory-fusion architecture,” in Proc. 2016 IEEE Int. Conf. Robotics and Automation (ICRA), 2016, pp. 3118–3125.
[36] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, “VQA: Visual question answering,” in Proc. Int. Conf. Computer Vision (ICCV), 2015, pp. 2425–2433.
[37] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell, “Long-term recurrent convolutional networks for visual recognition and description,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2015, pp. 2625–2634.
[38] A. Karpathy, A. Joulin, and F. F. F. Li, “Deep fragment embeddings for bidirectional image sentence mapping,” in Proc. Advances in Neural Information Processing Systems, 2014, pp. 1889–189
[39] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2015, pp. 3156–3164.
[40] M. Ren, R. Kiros, and R. Zemel, “Exploring models and data for image question answering,” in Proc. Advances in Neural Information Processing Systems, 2015, pp. 2953–2961.
[41] J.-H. Kim, S.-W. Lee, D.-H. Kwak, M.-O. Heo, J. Kim, J.-W. Ha, and B.-T. Zhang. (2016). Multimodal residual learning for visual QA. arXiv. [Online]. Available: https://arxiv.org/abs/1606.01455
[42] F. J. Ordóñez and D. Roggen, “Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition,” Sensors, vol. 16, no. 1, p. 115, 2016.
[43] D. Wu, L. Pigou, P.-J. Kindermans, N. D.-H. Le, L. Shao, J. Dambre, and J.-M. Odobez, “Deep dynamic neural networks for multimodal gesture segmentation and recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 8, pp. 1583–1597, 2016.
[44] H. Larochelle and Y. Bengio, “Classification using discriminative restricted Boltzmann machines,” in Proc. 25th Int. Conf. Machine Learning, 2008, pp. 536–543.
[45] Y. Huang, W. Wang, and L. Wang, “Unconstrained multimodal multi-label learning,” IEEE Trans. Multimedia, vol. 17, no. 11, pp. 1923–1935, 2015.
[46] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Proc. Advances in Neural Information Processing Systems, 2014, pp. 2672–2680.
[47] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in Proc. Int. Conf. Learning Representations (ICLR), 2014.
[48] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee, “Generative adversarial text to image synthesis,” in Proc. 33rd Int. Conf. Machine Learning (ICML), 2016, pp. 1060–1069.
[49] M. Suzuki, K. Nakayama, and Y. Matsuo. (2016). Joint multimodal learning with deep generative models. arXiv. [Online]. Available: https://arxiv.org/abs/1611.01891
[50] G. Pandey and A. Dukkipati. (2016). Variational methods for conditional multimodal deep learning. arXiv. [Online]. Available: https://arxiv.org/abs/1603.01801al multimodal deep learning. arXiv. [Online]. Available: https://arxiv.org/abs/1603.01801
[51] L. Deng, “A tutorial survey of architectures, algorithms, and applications for deep learning,” APSIPA Trans. Signal and Inform. Processing, vol. 3, pp. 1–29, 2014.
[52] M. R. Amer, T. Shields, B. Siddiquie, A. Tamrakar, A. Divakaran, and S. Chai, “Deep multimodal fusion: A hybrid approach,” Int. J. Comput. Vision, pp. 1–17, 2017. DOI: 10.1007/s11263-017-0997-7.
[53] M. R. Amer, B. Siddiquie, S. Khan, A. Divakaran, and H. Sawhney, “Multimodal fusion using dynamic hybrid models,” in Proc. IEEE 2014 Applications of Computer Vision Winter Conf., 2014, pp. 556–563.
[54] D. S. Sachan, U. Tekwani, and A. Sethi, “Sports video classification from multimodal information using deep neural networks,” in Proc. 2013 Association for the Advancement of Artificial Intelligence Fall Symp., 2013, pp. 102–107.
[55] Y. Liu, X. Feng, and Z. Zhou, “Multimodal video classification with stacked contractive autoencoders,” Signal Processing, vol. 120, pp. 761–766, Mar. 2016.
[56] N. Sebe, Machine Learning in Computer Vision, vol. 29. Dordrecht, The Netherlands: Springer, 2005.
[57] A. Owens, J. Wu, J. H. McDermott, W. T. Freeman, and A. Torralba, Ambient Sound Provides Supervision for Visual Learning. Cham, Switzerland: Springer International Publishing, 2016, pp. 801–816.
[58] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, 2006.
[59] D. Wang, P. Cui, M. Ou, and W. Zhu, “Learning compact hash codes for multimodal representations using orthogonal deep structure,” IEEE Trans. Multimedia, vol. 17, no. 9, pp. 1404–1416, 2015.
[60] J. Masci, M. M. Bronstein, A. M. Bronstein, and J. Schmidhuber, “Multimodal similarity-preserving hashing,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 4, pp. 824–830, 2014.
[61] H. P. Martínez and G. N. Yannakakis, “Deep multimodal fusion,” in Proc. 16th Int. Conf. Multimodal Interaction, 2014, pp. 34–41.
[62] S. E. Kahou, C. Pal, X. Bouthillier, P. Froumenty, Ç. Gülçehre, R. Memisevic, P. Vincent, A. Courville, et al., “Combining modality specific deep neural networks for emotion recognition in video,” in Proc. 15th ACM Int. Conf. Multimodal Interaction, 2013, pp. 543–550.
[63] D. Yi, Z. Lei, and S. Z. Li, “Shared representation learning for heterogenous face recognition,” in Proc. Automatic Face and Gesture Recognition 11th IEEE Int. Conf. Workshops, 2015, pp. 1–7.
[64] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei, “Large-scale video classification with convolutional neural networks,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2014, pp. 1725–1732.
[65] M. J. Wainwright, “Structured regularizers for high-dimensional problems: Statistical and computational issues,” Annu. Rev. Statistics Application, vol. 1, pp. 233–253, Apr. 2014.
[66] K. Sohn, W. Shang, and H. Lee, “Improved multimodal deep learning with variation of information,” in Proc. Advances in Neural Information Processing Systems., 2014, pp. 2141–2149.
[67] J. J.-Y. Wang, Y. Wang, S. Zhao, and X. Gao, “Maximum mutual information regularized classification,” Eng. Applicat. Artificial Intell., vol. 37, pp. 1–8, Jan. 2015.
[68] S. Zhu, X. Li, and S. Shen, “Multimodal deep network learning-based image annotation,” IET Electron. Lett., vol. 51, no. 12, pp. 905–906, 2015.
[69] H. Fei and J. Huan, “Structured feature selection and task relationship inference for multi-task learning,” Knowledge and Inform. Syst., vol. 35, no. 2, pp. 345–364, 2013.
[70] Z. Wu, Y.-G. Jiang, J. Wang, J. Pu, and X. Xue, “Exploring inter-feature and interclass relationships with deep neural networks for video classification,” in Proc. ACM Int. Conf. Multimedia, 2014, pp. 167–176.
[71] A. Wang, J. Lu, J. Cai, T. J. Cham, and G. Wang, “Large-margin multi-modal deep learning for RGB-D object recognition,” IEEE Trans. Multimedia, vol. 17, no. 11, pp. 1887–1898, Nov. 2015.
[72] A. Wang, J. Cai, J. Lu, and T.-J. Cham, “MMSS: Multi-modal sharable and specific feature learning for RGB-D object recognition,” in Proc. IEEE Int. Conf. Computer
Vision, 2015, pp. 1125–1133.
[73] J. Elman, “Learning and development in neural networks: The importance of starting small,” Cognition, vol. 48, no. 1, pp. 71–99, 1993.
[74] T. Chen, I. Goodfellow, and J. Shlens. (2015). Net2Net: Accelerating learning via knowledge transfer. arXiv. [Online]. Available: https://arxiv.org/abs/1511.05641
[75] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proc. IEEE Conf. Computer Vision and Pattern Recognition, 2015, pp. 1–9.
[76] R. Reed, “Pruning algorithms—A survey,” IEEE Trans. Neural Netw., vol. 4, no. 5, pp. 740–747, 1993.
[77] J. Feng and T. Darrel, “Learning the structure of deep convolutional networks,” in Proc. Int. Conf. Computer Vision, 2015, pp. 2749–2757.
[78] J. Yang, J. Ma, M. Berryman, and P. Perez, “A structure optimization algorithm of neural networks for large-scale data sets,” in Proc. 2014 IEEE Int. Conf. Fuzzy Syst. (FUZZ-IEEE), 2014, pp. 956–961.
[79] D. Whitley, T. Starkweather, and C. Bogart, “Genetic algorithms and neural networks: Optimizing connections and connectivity,” Parallel Comput., vol. 14, no. 3, pp. 347–361, 1990.
[80] K. O. Stanley and R. Miikkulainen, “Efficient evolution of neural network topologies,” in Proc. Congr. Evolutionary Computation (CEC02), 2002, pp. 1757–1762.
[81] T. Shinozaki and S. Watanabe, “Structure discovery of deep neural network based on evolutionary algorithms,” in Proc. 2015 IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 4979–4983.
[82] B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. de Freitas, “Taking the human out of the loop: A review of Bayesian optimization,” Proc. IEEE, vol. 104, no. 1, pp. 148–175, 2016.
[83] D. Ramachandram, M. Lisicki, T. Shields, M. Amer, and G. Taylor, “Structure optimization for deep multimodal fusion networks using graph-induced kernels,” in Proc. 25th European Symp. Artificial Neural Networks, Computational Intelligence, and Machine Learning (ESANN), Bruges, Belgium, 2017, pp. 11–16.
[84] R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, vol. 1. Cambridge, MA: MIT Press, 1998.
[85] B. Zoph and Q. V. Le. (2016). Neural architecture search with reinforcement learning. arXiv. [Online]. Available: https://arxiv.org/abs/1611.01578
[86] P. Kulkarni, J. Zepeda, F. Jurie, P. Pérez, and L. Chevallier, “Learning the structure of deep architectures using L1 regularization,” in Proc. British Machine Vision Conf., 2015, pp. 23.1–23.11.
[87] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,” J. Mach. Learning Res., vol. 15, no. 1, pp. 1929–1958, 1 Jan. 2014.
[88] C. Murdock, Z. Li, H. Zhou, and T. Duerig, “Blockout: Dynamic model selection for hierarchical deep networks,” in Proc. Int. Conf. Computer Vision and Pattern Recognition, 2016, pp. 2583–2591.
[89] F. Li, N. Neverova, C. Wolf, and G. Taylor, “Modout: Learning multi-modal architectures by stochastic regularization,” in Proc. 2017 IEEE Conf. Automatic Face and Gesture Recognition, 2017, pp. 422–429.
[90] M. Firman, “RGBD data sets: Past, present and future,” in Proc. CVPR Workshop on Large Scale 3D Data: Acquisition, Modelling, and Analysis, 2016.
[91] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI data set,” Int. J. Robotics Res., vol. 32, no. 11, pp. 1231–1237, 2013.
[92] W. Maddern, G. Pascoe, C. Linegar, and P. Newman, “1 Year, 1000km: The Oxford RobotCar data set,” Int. J. Robotics Res., vol. 36, no. 1, pp. 3–15, 2017.
[93] C. Chen, R. Jafari, and N. Kehtarnavaz, “UTD-MHAD: A multimodal data set for human action recognition utilizing a depth camera and a wearable inertial sensor,” in Proc. 2015 IEEE Int. Conf Image Processing (ICIP), 2015, pp. 168–172.
[94] S. Escalera, X. Baró, J. Gonzalez, M. A. Bautista, M. Madadi, M. Reyes, V. Ponce-López, H. J. Escalante, et al., “Chalearn looking at people challenge 2014: Dataset and results,” in Proc. Workshop at the European Conf. Computer Vision, 2014, pp. 459–473.
[95] F. Ofli, R. Chaudhry, G. Kurillo, R. Vidal, and R. Bajcsy, “Berkeley MHAD: A comprehensive multimodal human action database,” in Proc. 2013 IEEE Workshop on Applications of Computer Vision, 2013, pp. 53–60.
[96] A. Pablo, Y. Mollard, F. Golemo, A. C. Murillo, M. Lopes, and J. Civera, “A multimodal human-robot interaction data set,” in Proc. Neural Information Processing Systems, 2016, pp. 1–5.
[97] F. Ringeval, A. Sonderegger, J. Sauer, and D. Lalanne, “Introducing the Reco multimodal corpus of remote collaborative and affective interactions,” in Proc. Automatic Face and Gesture Recognition 10th IEEE Int. Conf. Workshops, 2013, pp. 1–8.
[98] O. Banos, C. Villalonga, R. Garcia, A. Saez, M. Damas, J. A. Holgado-Terriza, S. Lee, H. Pomares, and I. Rojas, “Design, implementation and validation of a novel open framework for agile development of mobile health applications,” Biomedical Eng. Online, vol. 14, no. 2, p. S6, 2015. [Online]. Available: https://doi.org/10.1186/1475-925X-14-S2-S6
[99] J. Mao, J. Xu, K. Jing, and A. L. Yuille, “Training and evaluating multimodal word embeddings with large-scale web annotated images,” in Proc. Advances in Neural Information Processing Systems, 2016, pp. 442–450.
[100] J. Arevalo, T. Solorio, M. Montes-y Gómez, and F. A. González. (2017). Gated multimodal units for information fusion. arXiv. [Online]. Available: https://arxiv.org/abs/1702.01992
[101] Y.-G. Jiang, Z. Wu, J. Wang, X. Xue, and S.-F. Chang, “Exploiting feature and class relationships in video categorization with regularized deep neural networks,” IEEE Trans. Pattern Anal. Mach. Intell., 2017. doi: https://doi.org/10.1109/ TPAMI.2017.2670560
[102] R. Min, N. Kose, and J.-L. Dugelay, “KinectFaceDB: A Kinect database for face recognition,” IEEE Trans. Syst., Man, Cybern., Syst., vol. 44, no. 11, pp. 1534–1548, Nov. 2014.
[103] B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, Y. Burren, N. Porz, et al., “The multimodal brain tumor image segmentation benchmark (BRATS),” IEEE Trans. Med. Imag., vol. 34, no. 10, pp. 1993–2024, 2015.


![[Python] scikit-learn之mean_squared_error函数(Mean Squared Error(MSE))介绍和使用案例](https://img-blog.csdnimg.cn/direct/bb55cb99b2fd43d792b622c812b8e692.png)