KTO全称为Kahneman-Tversky Optimisation,这种对齐方法使在我们的数据上对大型语言模型(LLM)进行对齐变得前所未有地容易和便宜,而且不会损害性能。大型语言模型的成功在很大程度上得益于与人类反馈的对齐。如果ChatGPT曾经拒绝回答您的问题,很可能是因为它被训练为避免说出有争议的内容。然而,对于公司来说,对他们自己的LLM进行对齐一直是困难的。下面我们简单介绍下KTO方法,这种方法可以提高LLM的整体性能和质量,同时节省成本。
大规模对齐LLM
LLM对齐对于优化性能至关重要,但一直以来都很困难,因为:
标准的对齐方法,即带有人类反馈的强化学习(RLHF),有许多复杂的部分,很多开源项目已经努力使其工作。
对齐方法期望以偏好的形式获得反馈(例如,对于输入X,输出A比B更好)。利用人类注释工作的这种反馈很快就会变得非常昂贵,并且也可能导致数据冲突。人类自己的评分主观性强,因此需要大量努力来定义输出A如何定量优于输出B。
这两个因素意味着,对于大多数组织来说,自己的LLM大规模对齐历史上是不可能的。但这一差距正在缩小。斯坦福研究人员最近用一种称为直接偏好优化(DPO)的技术解决了第一个问题,这在数学上等同于RLHF,同时更加简单,使得对齐对于开源努力变得可行。
剩下的瓶颈是数据。只有少数几个包含文本上人类偏好的公共数据集,而且它们是通用的。例如,如果你想要人类对两种LLM输出更准确地判断意大利经济状况的反馈,你需要咨询专业人士。但获取此类数据很昂贵,无论您是直接付费还是要求员工花费宝贵的时间提供反馈。
克服数据瓶颈
在Contextual AI项目中,作者已经找到了克服这一数据瓶颈的方法。通过研究经济学家Kahneman和Tversky关于人类决策的工作,设计了一种不需要像“输入X的输出A胜过输出B”这样的偏好的对齐方法。相反,对于输入X,我们只需要知道输出Y是可取的还是不可取的。这种单一反馈是丰富的:每个公司都有可以标记为可取(例如,销售成功)或不可取(例如,没有销售)的客户互动数据。
通过在三个公共数据集(Anthropic HH、Stanford Human Preferences 和 Open Assistant)的组合上对齐从 1B 到 30B 的模型,将 KTO 与现有方法进行比较。然后,遵循现在的标准做法,使用 GPT-4 将对齐模型的各代与数据集中提供的人类首选基线进行比较。
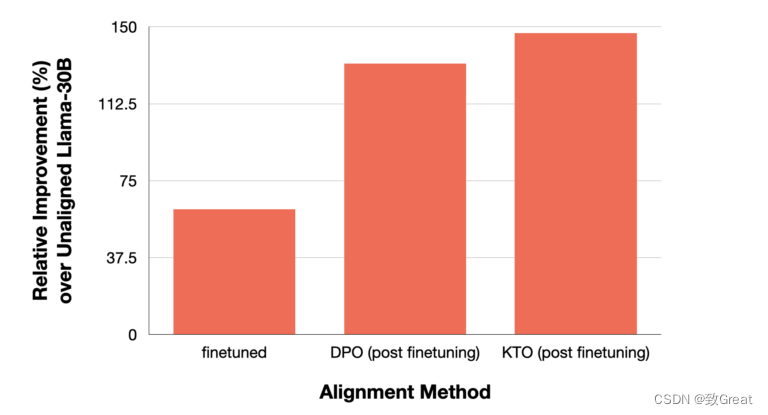
与其他对齐模型相比,Kahneman-Tversky 优化在性能上大幅提升,无论是标准微调还是 DPO
更多原理和细节请参考:
https://github.com/ContextualAI/HALOs/blob/main/assets/report.pdf
代码
https://github.com/ContextualAI/HALOs
class SimpleKTOTrainer(UnpairedPreferenceTrainer):
"""A simple version of KTO meant to introduce you to the HALOs repo."""
def loss(self,
policy_chosen_logps: torch.FloatTensor,
policy_rejected_logps: torch.FloatTensor,
reference_chosen_logps: torch.FloatTensor,
reference_rejected_logps: torch.FloatTensor) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:
"""Compute the Kahneman-Tversky loss for a batch of policy and reference model log probabilities.
For each batch of n/2 chosen examples and n/2 rejected examples (belonging to n different inputs), calculate the loss as follows.
If generation y ~ p_chosen, where x' ~ are the examples with rejected generations, we have the 'chosen' loss:
L(x, y) := 1 - sigmoid(beta * (log p_policy(y|x) - log p_reference(y|x) - KL(p_policy(y_rejected|x') || p_reference(y_rejected|x')))
If generation y ~ p_rejected, , where x' ~ are the examples with chosen generations, we have the 'rejected' loss:
L(x, y) := 1 - sigmoid(beta * KL(p_policy(y_chosen|x') || p_reference(y_chosen|x')) - [log p_policy(y|x) - log p_reference(y|x)])
"""
chosen_KL = (policy_chosen_logps - reference_chosen_logps).mean().clamp(min=0)
rejected_KL = (policy_rejected_logps - reference_rejected_logps).mean().clamp(min=0)
chosen_logratios = (policy_chosen_logps - reference_chosen_logps)
rejected_logratios = (policy_rejected_logps - reference_rejected_logps)
losses = torch.cat((1 - F.sigmoid(self.config.loss.beta * (chosen_logratios - rejected_KL)), 1 - F.sigmoid(self.config.loss.beta * (chosen_KL - rejected_logratios))), 0)
chosen_rewards = self.config.loss.beta * (policy_chosen_logps - reference_chosen_logps).detach()
rejected_rewards = self.config.loss.beta * (policy_rejected_logps - reference_rejected_logps).detach()
return losses, chosen_rewards, rejected_rewards
另外在最近有人对IPO/DPO/KTO性能做了对比:
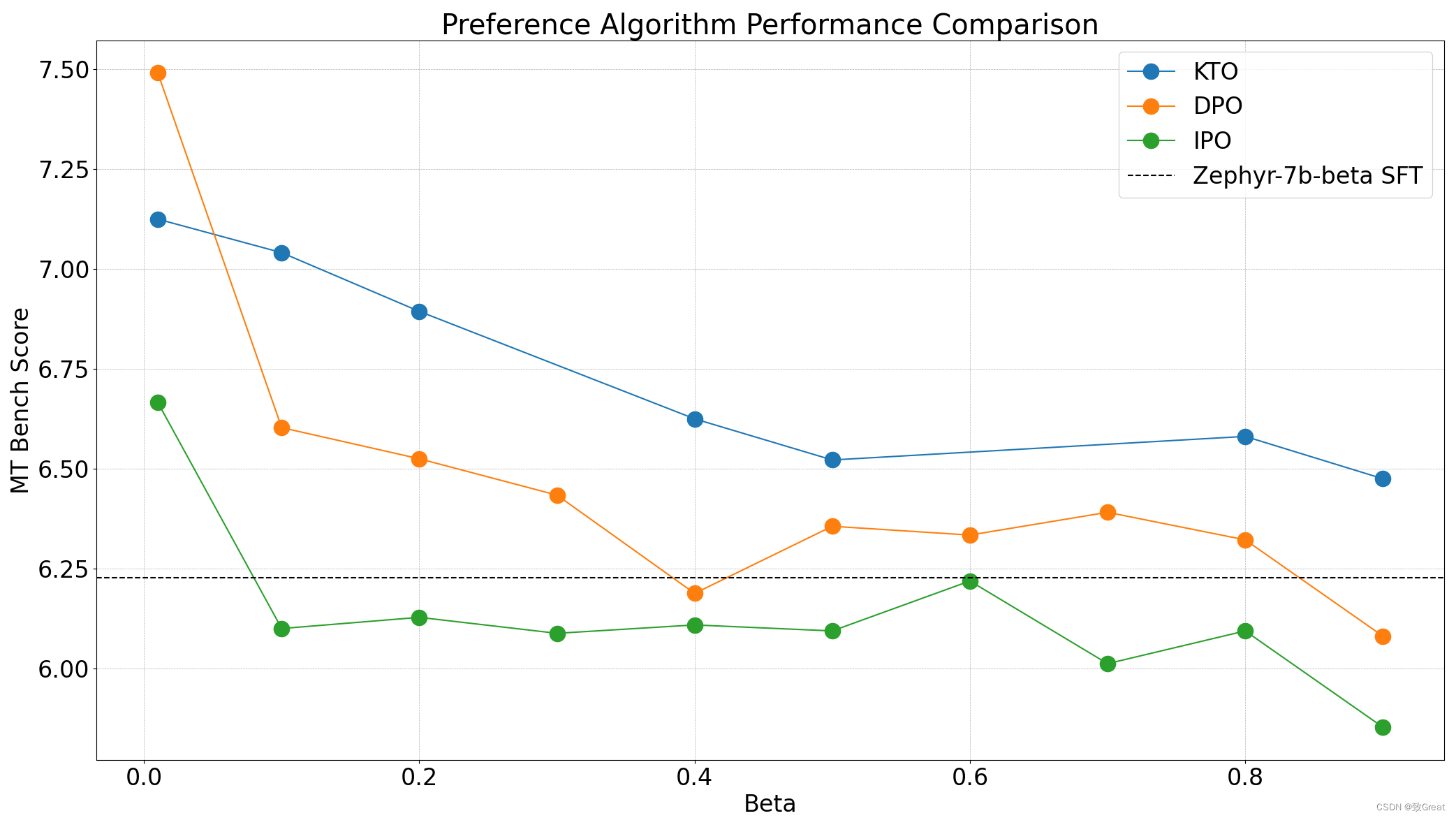
对于 Zephyr 模型,我们观察到最好的性能是以最低的成本实现的。这在所有三种测试的算法中都是一致的,社区的一个有趣的后续实验是在 0.0-0.2 范围内进行细粒度扫描。虽然 DPO 可以获得最高的 MT Bench 分数,但我们发现 KTO(配对)在除一种设置之外的所有设置中都取得了更好的结果。IPO虽然有更强的理论保证,但除了一种情况外,在所有情况下似乎都比基本模型更糟糕。
https://huggingface.co/blog/pref-tuning


![街机模拟游戏逆向工程(HACKROM)教程:[12]68K汇编-程序流控制](https://img-blog.csdnimg.cn/direct/99bcca2fb703465b9436a08511a7f7f2.png)