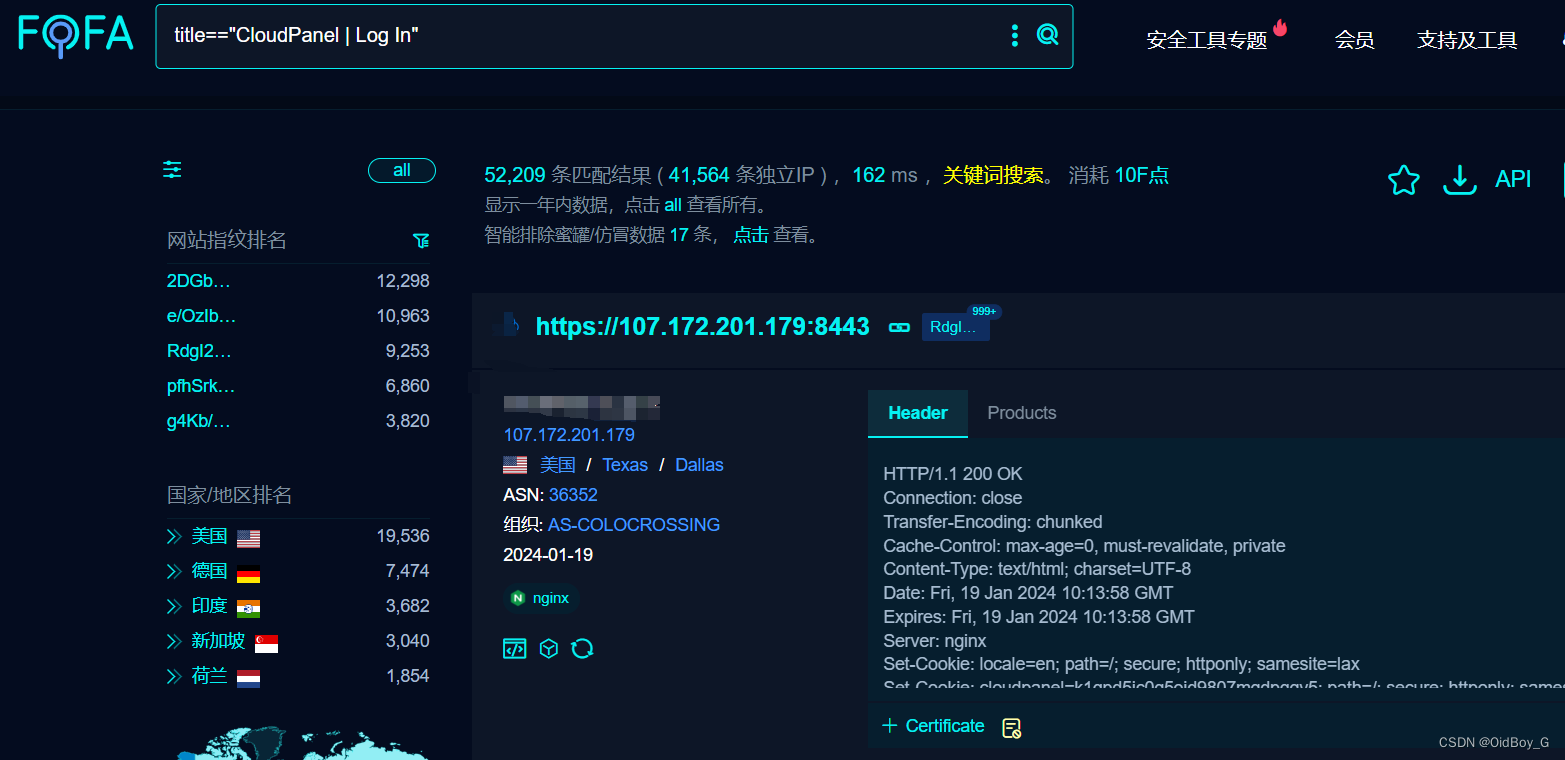
在Elasticsearch中,有多种数据类型可用于定义字段。
在开始了解数据类型之前,首先要知道,在Elasticsearch中,分词处理主要针对文本字段,而对于其他类型字段(如数值、日期、布尔等),通常不会进行分词处理。这是因为文本字段需要支持全文搜索、模糊匹配和文本分析,而其他类型字段通常用于精确匹配和聚合计算,不需要进行分词。
一、了解字符串类型(string)
在ES早期版本有一个string数据类型,使用string类型时,有两种用法(通过index来区分):
| 全文检索 | 分词 | index=analysis | 按单个字符匹配 | 被称作analyzed字符串 |
| 关键词搜索 | 不分词 | index=not_analysis | 按照整个文本进行匹配 | 被称为not-analyzed字符串 |
Elasticsearch在5.0版本中引入了text和keyword数据类型用于替代string类型。
下面我们通过一个示例来对比,ES分别如何使用string和text/keyward来创建索引:
例:假设我现在要创建名为my_index的索引,包含一个tag的字段(分词),以及一个foo的字段(不分词):
1)在Elasticsearch2.0版本的DSL语句:
PUT /my_index
{
"mappings": {
"_doc":{
"properties": {
"tag": {
"type": "string",
"index": "analyzed"
},
"foo": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}
2)在Elasticsearch5.0版本的DSL语句:
PUT /my_index
{
"mappings": {
"_doc":{
"properties": {
"tag": {
"type": "text",
"analyzer": "standard"
},
"foo": {
"type": "keyword"
}
}
}
}
}
总结:简而言之,无非就是5.0版本为string找了一个替代方案,text(分词)用于全文检索,keyword(不分词)用于聚合和排序。
扩展:在Elasticsearch中,
"analyzer"是用于指定文本字段如何被分析的部分。它定义了在建立索引时和搜索时如何处理文本数据的过程。在提供的示例中,"analyzer"属性指定了"standard"分析器,这意味着文本字段将使用标准分析器进行处理。标准分析器将文本分成单词,并且会根据一些规则进行标准化,例如将单词转为小写。
注意:在Elasticsearch中,在创建索引定义mapping映射时,如果您只有一个字段,可以省略"properties",直接将字段定义放在"_doc" 下。这种情况下,您可以简化索引的创建过程。
注意:从Elasticsearch 7.0版本开始,一个索引只能包含一个类型,因此在创建索引时可以省略type。在示例中,我已经省略了type,因为在较新的Elasticsearch版本中,这是一个可选的设置。
二、简单的数据类型
1、文本类型(text):当一个字段是要被全文检索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。文本类型通常用于存储文本数据,支持全文搜索和分析。
2、关键字类型(keyword):这种类型适用于结构化的字段,例如:标签、email地址、手机号等,这种类型的字段可以用作过滤、排序、聚合等。用于存储关键字数据,不会被分词,通常用于精确匹配和聚合操作。
3、Numeric类型:用于存储数值类型的数据,包括整数类型(integer、long、short、byte)和浮点数类型(float、double),Numeric类型支持范围查询、排序和聚合操作,在满足需求的情况下,优先使用范围小的字段。字段长度越短,索引和搜索的效率越高。
-
Integer类型(integer):用于存储整数数据,支持有符号的32位整数,范围为
-2^31到2^31-1; -
Long类型(long):用于存储长整数数据,支持有符号的64位整数,范围为
-2^63到2^63-1; -
Short类型(short):占用2个字节,范围为-32,768至32,767;
-
Byte类型(byte):占用1个字节,范围为-128至127;
-
Float类型(float):用于存储单精度浮点数数据,占4个字节;
-
Double类型:用于存储双精度浮点数数据,占8个字节;
下面是一个创建数值类型字段的示例,其它字段同理:
PUT /my_index
{
"mappings": {
"_doc": {
"amount": {
"type": "integer"
}
}
}
}
4、日期类型(date):用于存储日期和时间数据,由于JSON中没有日期类型,所以es中的日期类型形式比较多样。
- 包含格式化日期的字符串, “2024-01-016"或"2024/01/16 12:10:30”;
- 代表时间毫秒数的长整型数字;
- 代表时间秒数的整数。
如果在Elasticsearch中未指定日期类型的格式,则默认格式是 “strict_date_optional_time||epoch_millis”。strict_date_optional_time 表示日期时间格式,epoch_millis 表示以毫秒为单位的时间戳。这意味着Elasticsearch会尝试解析日期字符串,如果失败,它将尝试解析为时间戳。
1)使用日期格式示例:
## 创建索引,添加映射
PUT my_index
{
"mappings": {
"_doc": {
"pub_date": {"type": "date"}
}
}
}
## 添加数据
PUT my_index/_doc/11
{ "pub_date": "2018-10-10" }
## Solr中默认使用的日期格式
PUT my_index/_doc/11
{ "pub_date": "2018-10-10T12:00:00Z" }
## 时间的毫秒值
PUT my_index/_doc/11
{ "pub_date": "1589584930103" }
2)多种日期格式:多个格式使用双竖线||分隔, 每个格式都会被依次尝试, 直到找到匹配的。
## 添加映射
PUT my_index
{
"mappings": {
"_doc": {
"pub_date": {
"type": "date", ## 可以接受如下类型的格式
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
5、布尔类型(boolean):用于存储布尔值,可以接受表示真、假的字符串或数字。
- 真值: true、“true”、“on”、“yes”、“1”…
- 假值: false、“false”、“off”、“no”、“0”、“”(空字符串)、0.0、0
6、 二进制型(binary):二进制类型是Base64编码字符串的二进制值,不以默认的方式存储,且不能被搜索。用于存储二进制数据,如图片、音频或视频文件。
## 添加映射
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"title": {"type" : "text"}
"blob": {"type": "binary"}
}
}
}
}
## 添加数据
PUT my_index/_doc/1
{
"title": "Some binary blog",
"blob": "hED903KSrA084fRiD5JLgY=="
}
注意:在Elasticsearch中,Base64编码的二进制值应该是连续的,不应该包含换行符
\n。
7、范围类型(range):range类型支持以下几种:

(1) 添加映射:
PUT /company
{
"mappings": {
"properties": {
"expected_number": {
"type": "integer_range"
},
"time_frame": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"ip_whitelist": {
"type": "ip_range"
}
}
}
}
(2) 添加数据:
POST /company/_doc
{
"expected_number": {
"gte": 100,
"lte": 500
},
"time_frame": {
"gte": "2022-01-01",
"lte": "2023-01-01"
},
"ip_whitelist": "192.168.1.0/24"
}
(3) 查询数据:
GET /company/_search
{
"query": {
"range": {
"expected_number": {
"gte": 200
}
}
}
}
查询结果:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "company",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"expected_number": {
"gte": 100,
"lte": 500
},
"time_frame": {
"gte": "2022-01-01",
"lte": "2023-01-01"
},
"ip_whitelist": "192.168.1.0/24"
}
}
]
}
}
三、复杂的数据类型
暂时整理到这里,下面类型详细内容,后续抽空补充
1、Array类型:用于存储数组数据。Array类型可以包含多个相同或不同类型的元素,并支持按数组中的某个元素进行查询。
2、Object类型:用于存储复杂的结构化数据。Object类型类似于关系型数据库中的行,可以包含多个属性字段。
3、嵌套类型(nested):嵌套类型是对象数据类型的一个特例, 可以让array类型的对象被独立索引和搜索。
3、Geo类型(geo_point):用于存储地理位置数据。Geo类型支持点、线、多边形等地理形状的索引和查询。