🎈行百里者半九十🎈
🎈目录🎈
- 概念
- 多表查询
- 自连接
- 子查询
- 单行子查询
- 多行子查询
- in关键字
- all关键字
- any关键字
- 多列子查询
- 在from中使用子查询
- 合并查询
- union
- union all
- 总结
概念
之前我们很多的查询都只是对于单表进行查询,而在实际开发中往往数据来自不同的表,所以需要多表查询。多表查询也称复合查询,MySQL复合查询是指在一个查询语句中结合使用多个子查询或联结(JOIN)操作,以完成更复杂的数据检索或分析任务。这种查询可以包括多个 SELECT 语句、联结、子查询等,从而允许你在一个查询中获取来自不同表的数据或根据不同条件组合结果。复合查询的主要目的是实现对数据库中数据的灵活检索,以便满足复杂的业务需求。
多表查询
基本的多表查询通常涉及使用 JOIN 操作,以联结两个或多个表的数据。以下是一个简单的多表查询的例子,有如下两张stu和cla表。
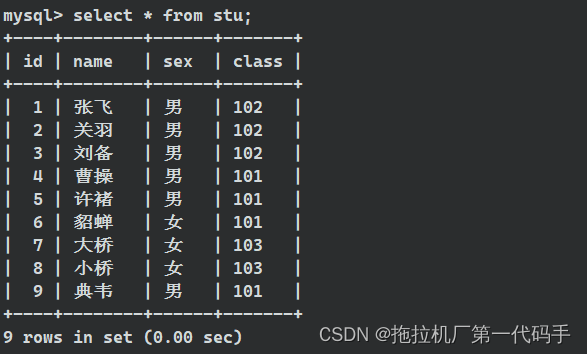

当我们不设任何条件单纯进行复合查询,执行语句会出现如下结果:
select * from stu, cla; ---select * from stu join cla;
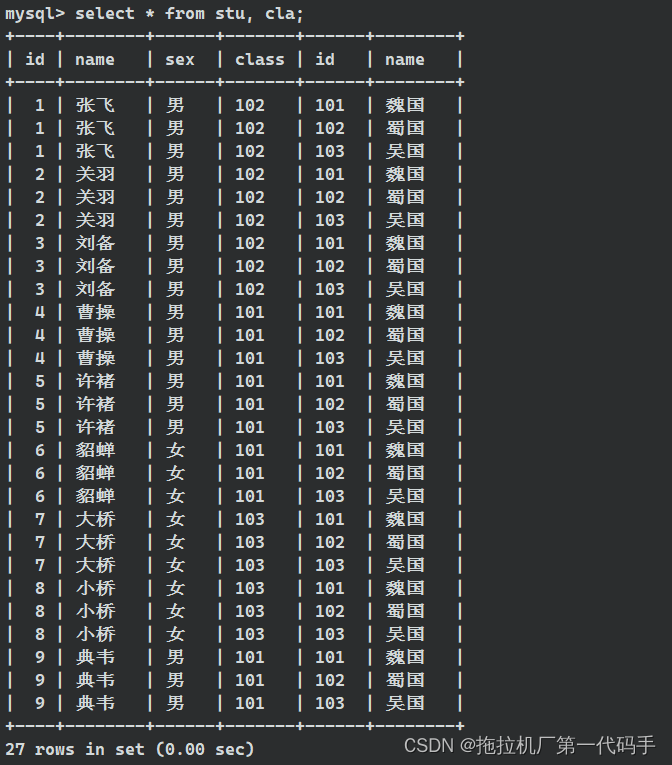
可以看到在结果中,每个表的每一行都与另一个表的每一行组合,形成了笛卡尔积。在实际应用中,应当避免无条件的笛卡尔积,因为它可能导致结果集非常庞大,对性能产生负面影响。通常,应该通过使用合适的连接条件来执行表的连接,以获得更有意义的结果。
例如,获取每个人的姓名、性别和国家。
select stu.name '姓名', sex '性别', cla.name '国家'
from stu, cla
where stu.class=cla.id;
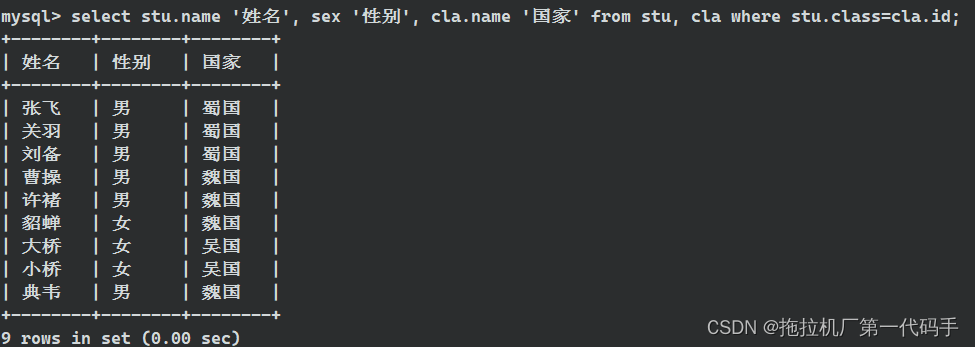
类似这样的多表查询可帮助你从关联的表中检索出合并的信息,使得查询结果更具有实际业务意义。
自连接
自连接是指在同一张表内进行连接操作,即连接表中的不同行与自身的其他行。这种连接通常涉及使用表的别名(alias)来区分表的不同实例。
如下示例,假设有一个表 employees 包含员工的信息,其中包括员工的ID和其直接上级的ID:
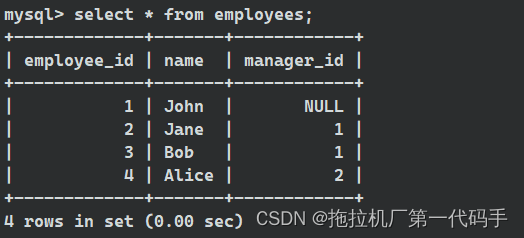
在这个表中,manager_id 列表示员工的直接上级的ID。要查询每个员工及其对应的直接上级,可以执行自连接,使用表的别名来引用相同的表:
select e1.name name, e2.name manager
from employees e1, employees e2
where e1.manager_id=e2.employee_id;
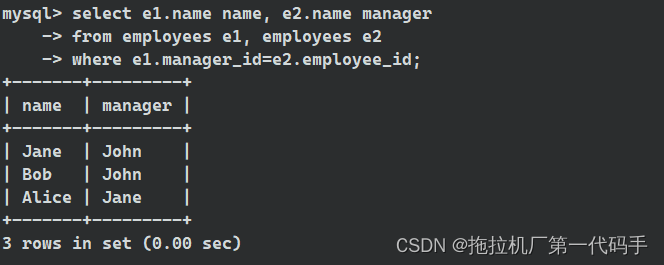
在这个例子中,employees 表通过自连接找到每个员工及其对应的直接上级。通过使用表别名,我们可以清晰地区分表的两个实例,并指定连接条件。自连接通常用于处理层次结构数据,其中一个记录与同一表中的另一个记录有关联。
子查询
子查询是嵌套在主查询中的查询,可以作为主查询的一部分来获取需要的数据。子查询可以出现在不同的位置,例如在 SELECT、FROM、WHERE 子句中,根据需求选择合适的位置。
单行子查询
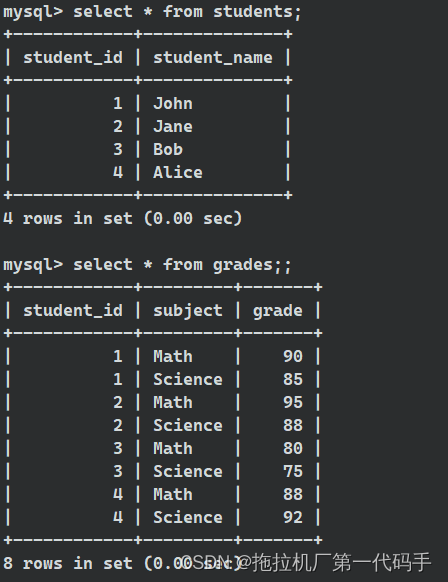
单行子查询是指返回单一值而不是结果集的子查询。这种类型的子查询通常用于在主查询中计算或比较单一值。例如假设有两个表 students 和 grades,其中 students 表包含学生信息,grades 表包含学生成绩信息。
表 students:
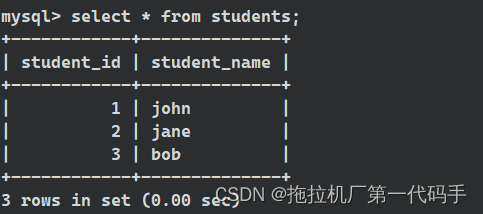
表 grades:

现在,假设我们想找到成绩最高的学生。我们可以使用单行子查询来获取最高分数:
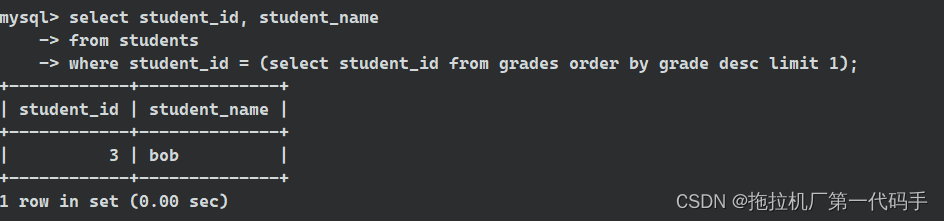
select student_id, student_name
from students
where student_id = (select student_id from grades order by grade desc limit 1);
在这个查询中,子查询 (select student_id from grades order by grade desc limit 1) 返回最高分数对应的学生ID,然后主查询使用这个学生ID来获取相关的学生信息。结果如下:
多行子查询
多行子查询是指返回多个结果的子查询,通常用于与主查询中的某个条件进行比较或筛选。假设有两个表 employees 和 salaries,其中 employees 表包含员工信息,salaries 表包含员工薪资信息。
表 employees:
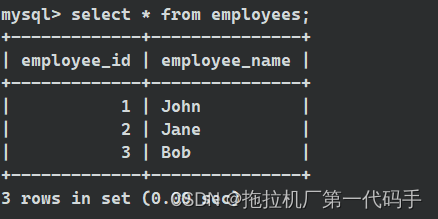
表 salaries:
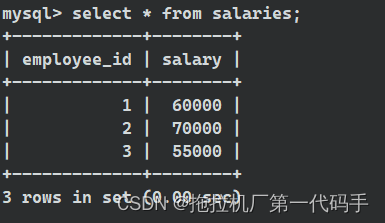
现在,假设我们想找到薪资高于公司平均薪资的员工。我们可以使用多行子查询计算平均薪资并与每个员工的薪资进行比较:
select e.employee_id, employee_name, salary
from employees e, salaries s
where e.employee_id=s.employee_id and salary > (select avg(salary) from salaries);
在这个查询中,子查询 (select avg(salary) from salaries) 返回每个员工的平均薪资,然后主查询使用这些值来筛选薪资高于平均薪资的员工。结果如下:

in关键字
当使用 IN 关键字时,你可以通过指定一个值列表来检查某个列是否包含在这个值列表中。可以使用 IN 关键字检查 employee_id 是否在满足条件(薪资高于公司平均薪资)的员工列表中。
select e.employee_id, employee_name, salary
from employees e, salaries s
where e.employee_id = s.employee_id and e.employee_id in (
select employee_id from salaries where salary > (
select avg(salary) from salaries));
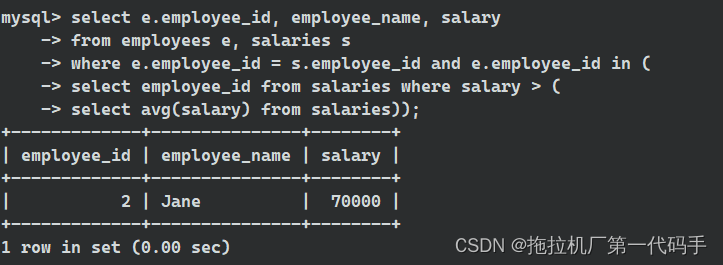
在这个查询中,IN 子句检查 employee_id 是否在子查询中返回的员工列表中。这个子查询会选择那些薪资高于公司平均薪资的员工的 employee_id。这样,你就可以得到所有薪资高于公司平均薪资的员工的记录。
all关键字
在 SQL 中,ALL 关键字用于与比较运算符一起使用,用于比较某个值与子查询中所有值的关系。通常,ALL 与比较运算符一起使用,例如 > ALL 或 < ALL。假设有两个表,分别为学生信息和多个成绩的表格。
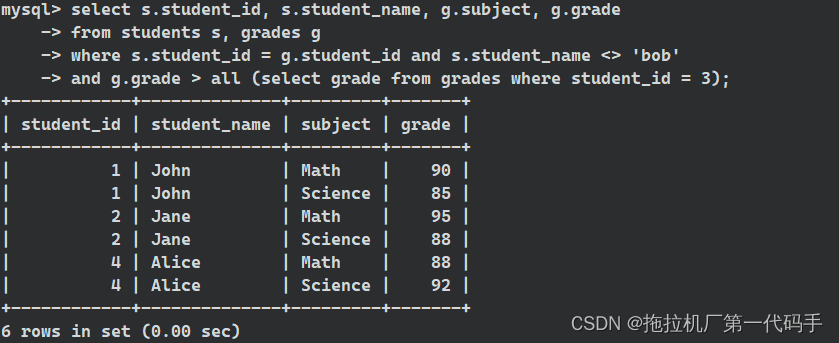
现在,我们想查询所有成绩都高于Bob的成绩的记录:
select s.student_id, s.student_name, g.subject, g.grade
from students s, grades g
where s.student_id = g.student_id and s.student_name <> 'bob'
and g.grade > all (select grade from grades where student_id = 3);
请注意,使用
ALL关键字时,要确保子查询返回的结果不包含NULL值,否则可能导致不确定的结果。
any关键字
在 SQL 中,ANY 关键字用于与比较运算符一起使用,用于比较某个值与子查询中的任何值的关系。通常,ANY 与比较运算符一起使用,例如 > ANY 或 < ANY。如上有两个表,分别为学生信息和多个成绩的表格。
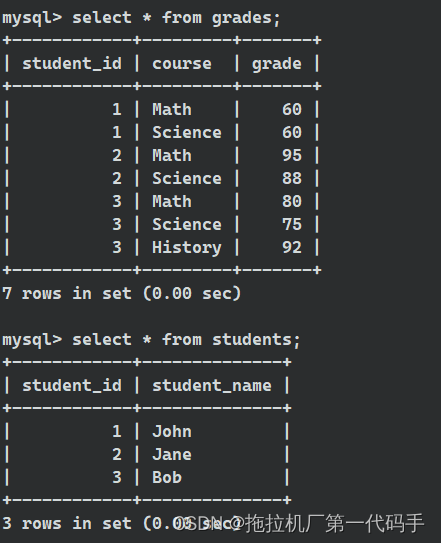
接下来要查询返回至少有一门课程成绩高于某个特定学生(例如Bob)的成绩的学生记录:
select s.student_id, s.student_name, g.course, g.grade
from students s, grades g
where s.student_id = g.student_id
and s.student_name <> 'bob' and g.grade > any (
select grade from grades where student_id = 3);
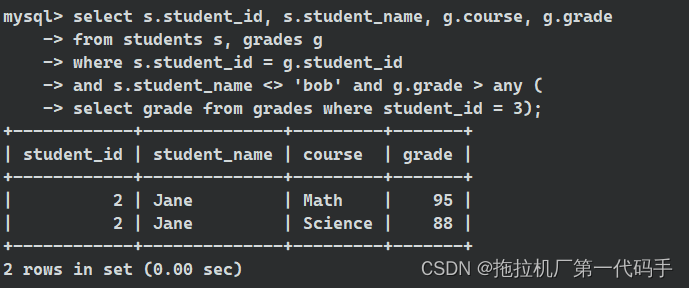
注意,与
all不同,any表示与子查询中的任何值进行比较,all是满足所有才为真,any是满足其中之一就为真(类似C语言中的&&和||)。同样,要确保子查询返回的结果不包含NULL值,以避免不确定的结果。
多列子查询
多列子查询通常用于在子查询中检索多列数据,并与主查询中的多列数据进行比较。假设有两个表格:orders 表格和 order_items 表格,用于跟踪订单和订单项的信息。
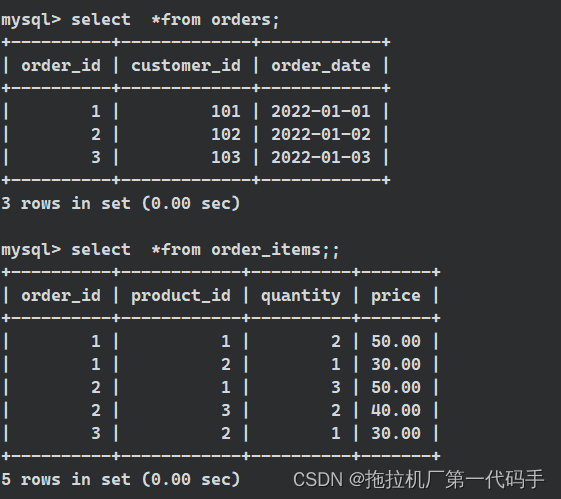
接下来想要查找所有订单的客户以及他们的订单总金额,但只包括那些订单总金额高于平均订单总金额的客户。
select o.customer_id,
sum(oi.quantity * oi.price) as total_amount
from orders o, order_items oi
where o.order_id = oi.order_id
group by o.customer_id
having sum(oi.quantity * oi.price) > (
select avg(order_total)
from (
select o.customer_id,
sum(oi.quantity * oi.price) as order_total
from orders o, order_items oi
where o.order_id = oi.order_id
group by o.customer_id
) as subquery
);
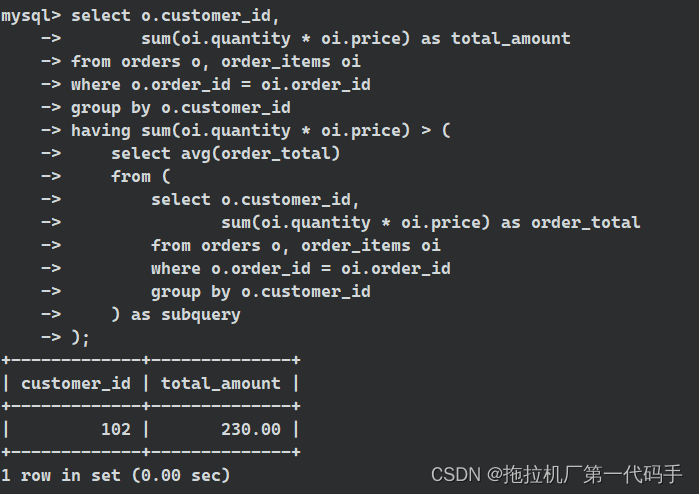
在上面的查询中使用了多列子查询。子查询计算了每个客户的订单总金额,并将其与平均订单总金额进行比较。主查询选择了那些订单总金额高于平均订单总金额的客户。
在from中使用子查询
在 FROM 子句中使用子查询是一种高级 SQL 技巧,通常用于创建临时表或派生表格,以便在查询中进一步使用。这种方法常常用于解决复杂的数据处理和报表生成问题。例如在如上的两个表格中,表格 orders 记录了订单信息,以及一个表格 order_items 记录了订单项的信息。当我们想计算每个订单的总金额,并在查询结果中包括订单的其他信息。
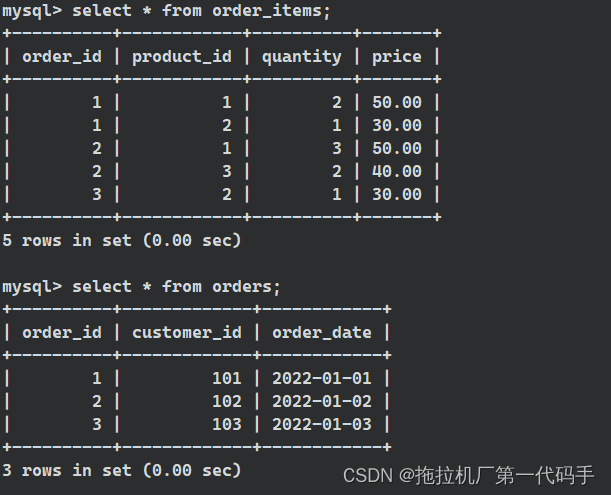
接下来,我们在 FROM 子句中使用子查询来计算每个订单的总金额并包括其他订单信息:
select o.order_id, o.customer_id, o.order_date, total_amount
from orders o, (
select oi.order_id, sum(oi.quantity * oi.price) as total_amount
from order_items oi
group by oi.order_id
) as order_totals
where o.order_id = order_totals.order_id;
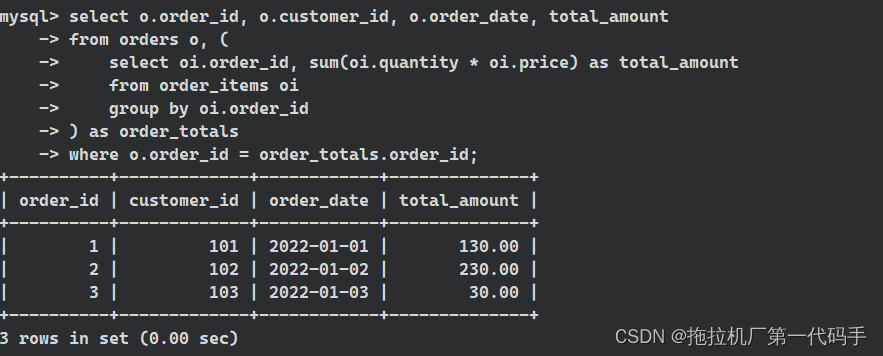
在这个查询中,我们在 FROM 子句中使用了一个子查询,该子查询计算了每个订单的总金额(通过对 order_items 表进行汇总)。然后,我们将主查询中的 orders 表格与子查询的结果进行连接,以获取每个订单的总金额以及其他订单信息。我们在一个查询中创建一个临时表格(order_totals),并将其用于进一步的数据处理。
合并查询
合并查询通常指的是使用 UNION 或 UNION ALL 操作符将多个查询的结果合并为一个结果集,这在需要合并多个查询结果时非常有用。
union
UNION 是用于合并两个或多个 SELECT 查询结果集的 SQL 操作符。它将多个查询的结果合并为一个结果集,并自动去除重复的行(不会保留重复的行)。UNION 的语法如下:
SELECT column1, column2, ...
FROM table1
UNION
SELECT column1, column2, ...
FROM table2;
假设有两个表格 students_a 和 students_b,它们包含了两个班级的学生信息。我们可以使用 UNION 合并这两个班级的学生名单:
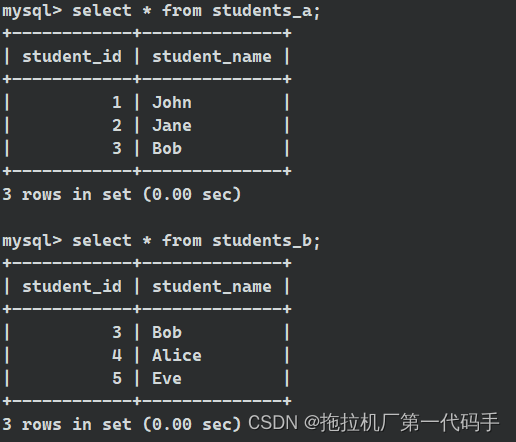
select student_name from students_a
union
select student_name from students_b;
在这个示例中,UNION 操作符合并了 students_a 和 students_b 表的学生名单,并返回不重复的学生名单。如果有学生出现在两个表中,只会在结果中出现一次。
union all
UNION ALL 是用于合并两个或多个 SELECT 查询结果集的 SQL 操作符,与 UNION 不同的是,它不会去除重复的行,而会保留所有行。UNION ALL 的语法如下:
SELECT column1, column2, ...
FROM table1
UNION ALL
SELECT column1, column2, ...
FROM table2;
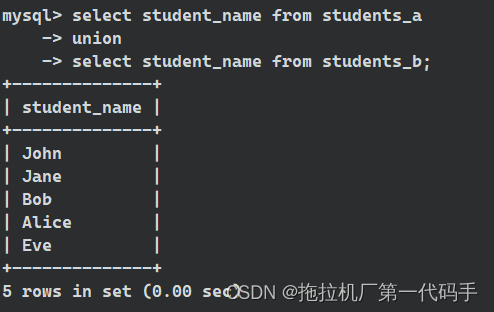
与上面一样有两个表格 students_a 和 students_b,它们包含了两个班级的学生信息。我们使用 UNION ALL 合并这两个班级的学生名单:
select student_name from students_a
union all
select student_name from students_b;
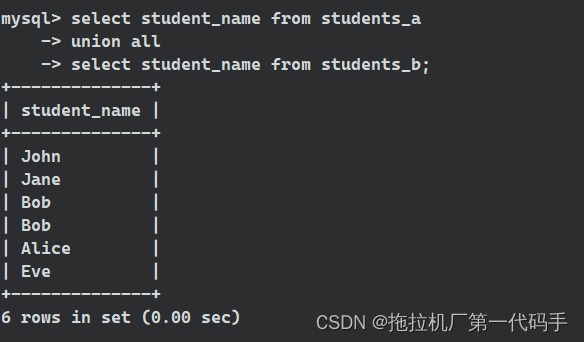
示例中,UNION ALL 操作符合并了 students_a 和 students_b 表的学生名单,并返回包括重复学生名单的结果。如果有学生出现在两个表中,它们都会在结果中保留。
与
UNION不同,UNION ALL不执行去重操作,因此在某些情况下,它可能比UNION更快,特别是当你知道结果中不会有重复行时。但要注意,如果你需要去除重复的行并且只保留唯一的行,应该使用UNION。
总结
文章主要介绍了MySQL中的多表查询相关的知识点,掌握这些功能和技巧可用于执行复杂的数据操作和查询,以满足各种数据库需求。码文不易,如果文章对你有帮助的话就劳烦点一个👍,感谢支持!



![洛谷P2615 [NOIP2015 提高组] 神奇的幻方(C语言)](https://img-blog.csdnimg.cn/direct/44b2ea1cf8d5446693879208c85c28da.png)