论文地址:https://arxiv.org/pdf/2204.03645.pdf
代码地址:https://github.com/dingmyu/davit
1.是什么?
Dual Attention Vision Transformers(DaViT)是一种新的Vision Transformer模型,它在全局建模方面引入了双注意力机制。这个模型的创新之处在于从两个正交的角度进行self-attention,分别对空间维度和通道维度进行建模。通过这种方式,DaViT能够更高效地捕捉图像中的全局信息。
具体来说,DaViT的双注意力机制包括以下两种self-attention方式:
- 空间self-attention:对于空间维度上的tokens,DaViT将其划分为不同的窗口,这类似于Swin中的窗口注意力(spatial window attention)。通过在空间维度上进行self-attention,DaViT能够捕捉到不同位置之间的关系。
- 通道self-attention:对于通道维度上的tokens,DaViT将其划分为不同的组(channel group attention)。通过在通道维度上进行self-attention,DaViT能够捕捉到不同特征之间的关系。
通过这两种self-attention的组合,DaViT能够同时考虑到空间和通道的信息,从而实现更全面的全局建模。这种双注意力机制使得DaViT在ImageNet1K数据集上达到了90.4%的Top1准确率,超过了之前的SwinV2模型。
2.为什么?
对于许多计算机视觉方法来说,全局上下文至关重要,如图像分类和语义分割。ViT的方法具有对全局上下文建模的强大能力,但它们的计算复杂度随着token长度的增加呈二次增长,限制了其扩展到高分辨率场景的能力。设计一个能够捕获全局上下文,同时从高分辨率输入中学习的体系结构仍然是一个开放的研究问题。
之前所有工作的一般模式是,在分辨率、全局上下文和计算复杂度之间权衡:像素级和patch级的self-attention要么是有二次计算成本,要么损失全局上下文信息。除了像素级和patch级的self-attention的变化之外,是否可以设计一个图像级的self-attention机制来捕获全局信息?
作者提出了Dual Attention Vision Transformers (DaViT),能够在保持计算效率的同时捕获全局上下文。提出的方法具有层次结构和细粒度局部注意的优点,同时采用 group channel attention,有效地建模全局环境。
本文的贡献主要有以下几点:
1.作者引入了 Dual Attention Vision Transformers(DaViT),它交替地应用spatial window attention和channel group attention来捕获长短依赖关系。
2.作者提出了 channel group attention,将特征通道划分为几个组,并在每个组内进行图像级别的交互。通过group attention,作者将空间和通道维度的复杂性降低到线性。
3.大量的实验表明,DaViT在四种不同的任务上取得了最好的性能。
3.怎么样?
双attention机制是从两个正交的角度来进行self-attention:
一是对spatial tokens进行self-attention,此时空间维度(HW)定义了tokens的数量,而channel维度(C)定义了tokens的特征大小,这其实也是ViT最常采用的方式;
二是对channel tokens进行self-attention,这和前面的处理完全相反,此时channel维度(C)定义了tokens的数量,而空间维度(HW)定义了tokens的特征大小。
可以看出两种self-attention完全是相反的思路。为了减少计算量,两种self-attention均采用分组的attention:对于spatial token而言,就是在空间维度上划分成不同的windows,这就是Swin中所提出的window attention,论文称之为spatial window attention;而对于channel tokens,同样地可以在channel维度上划分成不同的groups,论文称之为channel group attention。这两种attention如下图所示:

(a)空间窗口多头自注意将空间维度分割为局部窗口,其中每个窗口包含多个空间token。每个token也被分成多个头。(b)通道组单自注意组将token分成多组。在每个通道组中使用整个图像级通道作为token进行Attention。在(a)中也突出显示了捕获全局信息的通道级token。交替地使用这两种类型的注意力机制来获得局部的细粒度,以及全局特征。
两种attention能够实现互补:spatial window attention能够提取windows内的局部特征,而channel group attention能学习到全局特征,这是因为每个channel token在图像空间上都是全局的。
3.1网络结构
dual attention block
它包含两个transformer block:空间窗口self-attention block和通道组self-attention block。通过交替使用这两种类型的attention机制,作者的模型能实现局部细粒度和全局图像级交互。图3(a)展示了作者的dual attention block的体系结构,包括一个空间窗口attention block和一个通道组attention block。

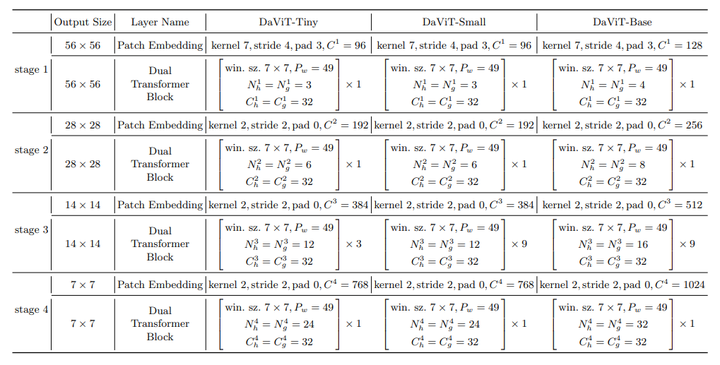
DaViT采用金字塔结构,共包含4个stages,每个stage的开始时都插入一个 patch embedding 层。作者在每个stage叠加dual attention block,这个block就是将两种attention(还包含FFN)交替地堆叠在一起,其分辨率和特征维度保持不变。
采用stride=4的7x7 conv,然后是4个stage,各stage通过stride=2的2x2 conv来进行降采样。其中DaViT-Tiny,DaViT-Small和DaViT-Base三个模型的配置如下所示:
global self-attention
回顾一下global self-attention:假定共有P个patch(特征图大小ℎw),每个patch的特征大小为C(总channel数量),所有的patch的特征X∈RP×C,self-attention的计算如下所示:

这里self-attention的head数量为,第i个head的query,key和value通过线性投射得到:
,它们的维度大小为
,其中
。这里省略attention之后的线性投射,所以共有4个线性投射,总的计算复杂度为
,而attention的计算复杂度为
,所以最终总的计算复杂度为
。可以看到计算量与patch总量的平方成正比,而patch总量和图像大小线性相关,当图像大小增加时,global self-attention的计算量将大幅度增加。
Spatial Window Attention
采用spatial window attention可以减少上述计算量,这里将patchs按照空间结构划分成个window(比如7x7大小),每个window的patch记为
,这里
。然后每个window里面的patch单独进行self-attention:
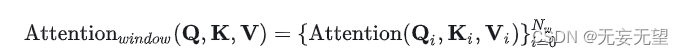
此时每个window attention的attention部分的计算复杂度为,总的计算复杂度为
。如果固定window大小,那么window attention的计算量就和patch总量成线性关系。虽然window attention降低了计算量,但是也变成了一种local attention,因为不同的windows之间并没有信息交换,Swin通过复杂的shift window来实现这种信息交换。
Channel Group Attention
channel group attention可以实现全局的attention。首先将channel分成个group,每个group的channel数量为
,这里有
,那么channel group attention的计算如下所示:

这里的分别是query,key和value,注意这里还是按照channel维度来进行线性投射得到,而不是在spatial维度,因为这样权重W是和图像的大小是无关的,模型可以适应任何大小的图像作为输入。在attention计算时,只需要将query,key和value的维度进行反转,即维度变成
,就可以实现channel attention了,由于这里我们希望attention在空间维度是全局的,所以不采用multi-head attention,或者说只用一个head,另外注意这里的scale因子采用的是1/
,而不是1/
,因为后者是图像大小相关的。同样地,channel group attention也包含4个线性投射,其计算复杂度也是
,而attention部分的计算复杂度为
。
channel attention可以自然地捕捉到全局信息和交互:(i)转换特征后,每个channel token本身在空间维度上是全局的,提供了图像的全局视野。(ii)给定维数为 P 的 ,计算
×
大小的attention map时所有空间位置都会被考虑,即 (
×P)·(P×
) 。(iii)通过这样的global attention map,channel attention动态地融合图像的多个全局视野,产生新的global token,并将信息传递给之后的spatial-wise层。信息交换是从全局角度而不是从patch角度进行的,补足了 window 局部性的不足。
3.2原理分析
Transformer中的全局交互可以总结为几种。Vanilla ViT和DeiT实现整个图像的不同patch之间的信息交换;Swin堆叠多个层次结构层,以最终获得全局信息。与它们不同,作者在计算attention score时,一个带channel attention的块,能考虑到所有的空间位置,学习全局交互,如(×P)·(P×
) 。它从多个global token中捕获信息,不同的channel可能包含来自对象的不同部分的信息,这些信息可以聚合到全局视图中。
对于第一列中的图像,在网络的第三个stage随机选择一个输出通道(第二列)及其对应的相关度前7的输入通道进行可视化。可以看到,channel attention融合了来自多个token的信息,选择了全局中重要的区域,并抑制了不重要的区域。

DaViT与Swin和DeiT的关系
虽然DaViT和Swin都使用窗口注意机制作为网络中的元素,但Swin的关键设计,即在连续层之间使用“移动的窗口”,本文方法没有使用。DaViT简化了其相对位置编码的depth-wise卷积,任意输入大小时,结构更干净。
下图显示了的channel attention group的有效性。在DaViT、Swin和DeiT的每个stage随机可视化一个特征通道。观察到: (i) Swin捕获了细粒度的细节,但在前两个stage没有重点,因为它缺乏全局信息。它直到最后一个阶段才能专注于主对象。(ii)DeiT在图像上学习粗粒度的全局特征,但丢失了细节,因此很难关注主要内容。(iii)DaViT通过结合两种类型的self attention来捕捉长短视觉依赖关系。它发现stage1中主要内容的细粒度细节,进一步关注stage2中的一些关键点,从而展示出强大的全局建模能力。然后,它从全局和局部的角度逐步细化感兴趣的区域。

3.3代码实现
import logging
from copy import deepcopy
import itertools
from typing import Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from .helpers import build_model_with_cfg, overlay_external_default_cfg
from .layers import DropPath, to_2tuple, trunc_normal_
from .registry import register_model
from .vision_transformer import checkpoint_filter_fn, _init_vit_weights
_logger = logging.getLogger(__name__)
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embeds[0].proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'DaViT_224': _cfg(),
'DaViT_384': _cfg(input_size=(3, 384, 384), crop_pct=1.0),
'DaViT_384_22k': _cfg(input_size=(3, 384, 384), crop_pct=1.0, num_classes=21841)
}
def _init_conv_weights(m):
""" Weight initialization for Vision Transformers.
"""
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight, std=0.02)
for name, _ in m.named_parameters():
if name in ['bias']:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0)
class MySequential(nn.Sequential):
""" Multiple input/output Sequential Module.
"""
def forward(self, *inputs):
for module in self._modules.values():
if type(inputs) == tuple:
inputs = module(*inputs)
else:
inputs = module(inputs)
return inputs
class Mlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
return x
class ConvPosEnc(nn.Module):
"""Depth-wise convolution to get the positional information.
"""
def __init__(self, dim, k=3):
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2d(dim,
dim,
to_2tuple(k),
to_2tuple(1),
to_2tuple(k // 2),
groups=dim)
def forward(self, x, size: Tuple[int, int]):
B, N, C = x.shape
H, W = size
assert N == H * W
feat = x.transpose(1, 2).view(B, C, H, W)
feat = self.proj(feat)
feat = feat.flatten(2).transpose(1, 2)
x = x + feat
return x
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding
"""
def __init__(
self,
patch_size=16,
in_chans=3,
embed_dim=96,
overlapped=False):
super().__init__()
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
if patch_size[0] == 4:
self.proj = nn.Conv2d(
in_chans,
embed_dim,
kernel_size=(7, 7),
stride=patch_size,
padding=(3, 3))
self.norm = nn.LayerNorm(embed_dim)
if patch_size[0] == 2:
kernel = 3 if overlapped else 2
pad = 1 if overlapped else 0
self.proj = nn.Conv2d(
in_chans,
embed_dim,
kernel_size=to_2tuple(kernel),
stride=patch_size,
padding=to_2tuple(pad))
self.norm = nn.LayerNorm(in_chans)
def forward(self, x, size):
H, W = size
dim = len(x.shape)
if dim == 3:
B, HW, C = x.shape
x = self.norm(x)
x = x.reshape(B,
H,
W,
C).permute(0, 3, 1, 2).contiguous()
B, C, H, W = x.shape
if W % self.patch_size[1] != 0:
x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1]))
if H % self.patch_size[0] != 0:
x = F.pad(x, (0, 0, 0, self.patch_size[0] - H % self.patch_size[0]))
x = self.proj(x)
newsize = (x.size(2), x.size(3))
x = x.flatten(2).transpose(1, 2)
if dim == 4:
x = self.norm(x)
return x, newsize
class ChannelAttention(nn.Module):
r""" Channel based self attention.
Args:
dim (int): Number of input channels.
num_heads (int): Number of the groups.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
"""
def __init__(self, dim, num_heads=8, qkv_bias=False):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
k = k * self.scale
attention = k.transpose(-1, -2) @ v
attention = attention.softmax(dim=-1)
x = (attention @ q.transpose(-1, -2)).transpose(-1, -2)
x = x.transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x
class ChannelBlock(nn.Module):
r""" Channel-wise Local Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
ffn (bool): If False, pure attention network without FFNs
"""
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
ffn=True):
super().__init__()
self.cpe = nn.ModuleList([ConvPosEnc(dim=dim, k=3),
ConvPosEnc(dim=dim, k=3)])
self.ffn = ffn
self.norm1 = norm_layer(dim)
self.attn = ChannelAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if self.ffn:
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer)
def forward(self, x, size):
x = self.cpe[0](x, size)
cur = self.norm1(x)
cur = self.attn(cur)
x = x + self.drop_path(cur)
x = self.cpe[1](x, size)
if self.ffn:
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x, size
def window_partition(x, window_size: int):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size: int, H: int, W: int):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True):
super().__init__()
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
attn = self.softmax(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
return x
class SpatialBlock(nn.Module):
r""" Spatial-wise Local Transformer Block.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
window_size (int): Window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
ffn (bool): If False, pure attention network without FFNs
"""
def __init__(self, dim, num_heads, window_size=7,
mlp_ratio=4., qkv_bias=True, drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
ffn=True):
super().__init__()
self.dim = dim
self.ffn = ffn
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
self.cpe = nn.ModuleList([ConvPosEnc(dim=dim, k=3),
ConvPosEnc(dim=dim, k=3)])
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim,
window_size=to_2tuple(self.window_size),
num_heads=num_heads,
qkv_bias=qkv_bias)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if self.ffn:
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer)
def forward(self, x, size):
H, W = size
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = self.cpe[0](x, size)
x = self.norm1(shortcut)
x = x.view(B, H, W, C)
pad_l = pad_t = 0
pad_r = (self.window_size - W % self.window_size) % self.window_size
pad_b = (self.window_size - H % self.window_size) % self.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
x_windows = window_partition(x, self.window_size)
x_windows = x_windows.view(-1, self.window_size * self.window_size, C)
attn_windows = self.attn(x_windows)
attn_windows = attn_windows.view(-1,
self.window_size,
self.window_size,
C)
x = window_reverse(attn_windows, self.window_size, Hp, Wp)
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = self.cpe[1](x, size)
if self.ffn:
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x, size
class DaViT(nn.Module):
r""" Dual-Attention ViT
Args:
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dims (tuple(int)): Patch embedding dimension. Default: (64, 128, 192, 256)
num_heads (tuple(int)): Number of attention heads in different layers. Default: (4, 8, 12, 16)
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
attention_types (tuple(str)): Dual attention types.
ffn (bool): If False, pure attention network without FFNs
overlapped_patch (bool): If True, use overlapped patch division during patch merging.
"""
def __init__(self, in_chans=3, num_classes=1000, depths=(1, 1, 3, 1), patch_size=4,
embed_dims=(64, 128, 192, 256), num_heads=(3, 6, 12, 24), window_size=7, mlp_ratio=4.,
qkv_bias=True, drop_path_rate=0.1, norm_layer=nn.LayerNorm, attention_types=('spatial', 'channel'),
ffn=True, overlapped_patch=False, weight_init='',
img_size=224, drop_rate=0., attn_drop_rate=0.
):
super().__init__()
architecture = [[index] * item for index, item in enumerate(depths)]
self.architecture = architecture
self.num_classes = num_classes
self.embed_dims = embed_dims
self.num_heads = num_heads
self.num_stages = len(self.embed_dims)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, 2 * len(list(itertools.chain(*self.architecture))))]
assert self.num_stages == len(self.num_heads) == (sorted(list(itertools.chain(*self.architecture)))[-1] + 1)
self.img_size = img_size
self.patch_embeds = nn.ModuleList([
PatchEmbed(patch_size=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else self.embed_dims[i - 1],
embed_dim=self.embed_dims[i],
overlapped=overlapped_patch)
for i in range(self.num_stages)])
main_blocks = []
for block_id, block_param in enumerate(self.architecture):
layer_offset_id = len(list(itertools.chain(*self.architecture[:block_id])))
block = nn.ModuleList([
MySequential(*[
ChannelBlock(
dim=self.embed_dims[item],
num_heads=self.num_heads[item],
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop_path=dpr[2 * (layer_id + layer_offset_id) + attention_id],
norm_layer=nn.LayerNorm,
ffn=ffn,
) if attention_type == 'channel' else
SpatialBlock(
dim=self.embed_dims[item],
num_heads=self.num_heads[item],
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop_path=dpr[2 * (layer_id + layer_offset_id) + attention_id],
norm_layer=nn.LayerNorm,
ffn=ffn,
window_size=window_size,
) if attention_type == 'spatial' else None
for attention_id, attention_type in enumerate(attention_types)]
) for layer_id, item in enumerate(block_param)
])
main_blocks.append(block)
self.main_blocks = nn.ModuleList(main_blocks)
self.norms = norm_layer(self.embed_dims[-1])
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.embed_dims[-1], num_classes)
if weight_init == 'conv':
self.apply(_init_conv_weights)
else:
self.apply(_init_vit_weights)
def forward(self, x):
x, size = self.patch_embeds[0](x, (x.size(2), x.size(3)))
features = [x]
sizes = [size]
branches = [0]
for block_index, block_param in enumerate(self.architecture):
branch_ids = sorted(set(block_param))
for branch_id in branch_ids:
if branch_id not in branches:
x, size = self.patch_embeds[branch_id](features[-1], sizes[-1])
features.append(x)
sizes.append(size)
branches.append(branch_id)
for layer_index, branch_id in enumerate(block_param):
features[branch_id], _ = self.main_blocks[block_index][layer_index](features[branch_id], sizes[branch_id])
features[-1] = self.avgpool(features[-1].transpose(1, 2))
features[-1] = torch.flatten(features[-1], 1)
x = self.norms(features[-1])
x = self.head(x)
return x
def _create_transformer(
variant,
pretrained=False,
default_cfg=None,
**kwargs):
if default_cfg is None:
default_cfg = deepcopy(default_cfgs[variant])
overlay_external_default_cfg(default_cfg, kwargs)
default_num_classes = default_cfg['num_classes']
default_img_size = default_cfg['input_size'][-2:]
num_classes = kwargs.pop('num_classes', default_num_classes)
img_size = kwargs.pop('img_size', default_img_size)
if kwargs.get('features_only', None):
raise RuntimeError('features_only not implemented for Vision Transformer models.')
model = build_model_with_cfg(
DaViT, variant, pretrained,
default_cfg=default_cfg,
img_size=img_size,
num_classes=num_classes,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs)
return model
参考:DaViT:双注意力Vision Transformer
DaViT: Dual Attention Vision Transformers