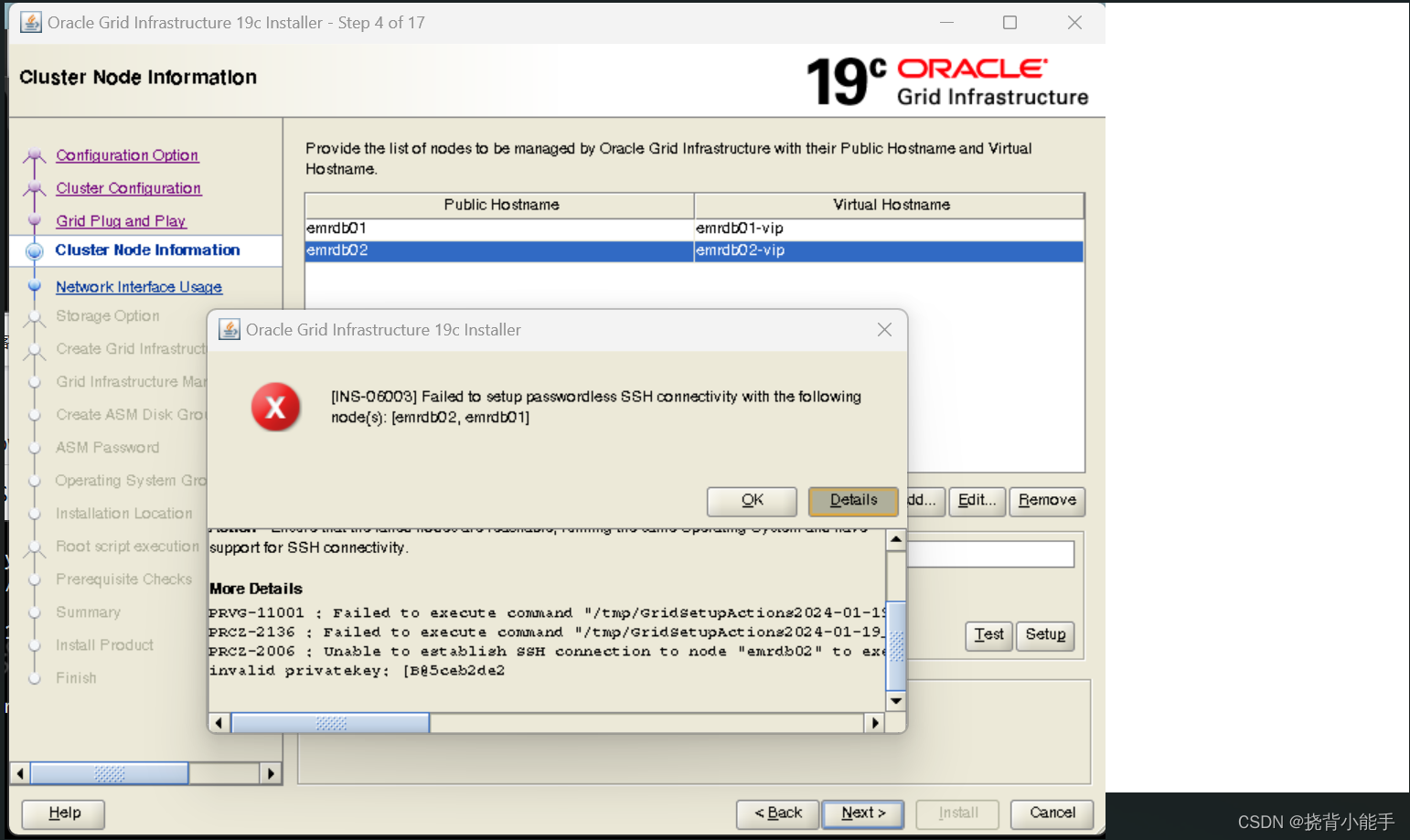
检查
是否有GPU
打开任务管理器,我这边显示有gpu
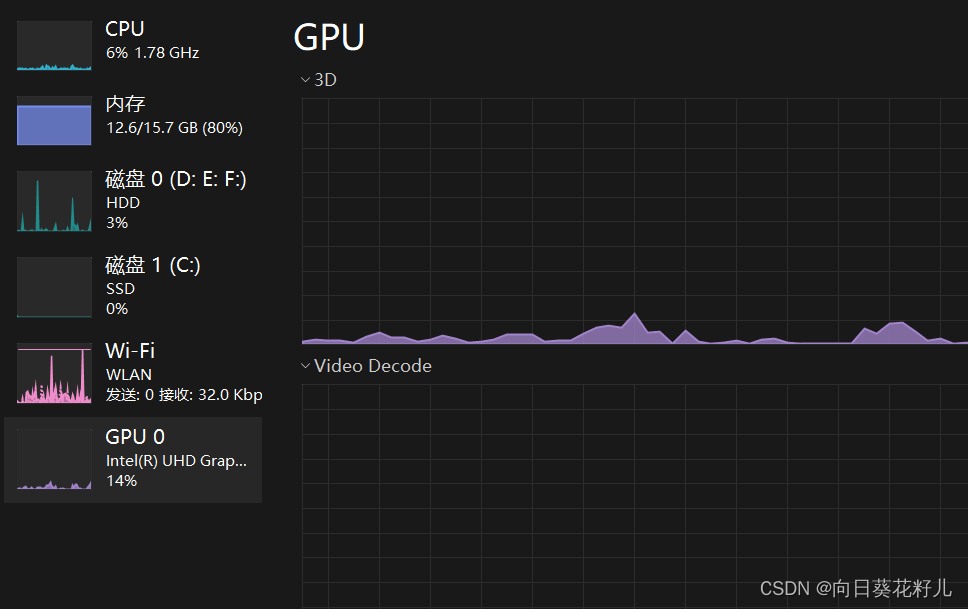
查看有没有安装cuda
nvidia-smi

我没有CUDA
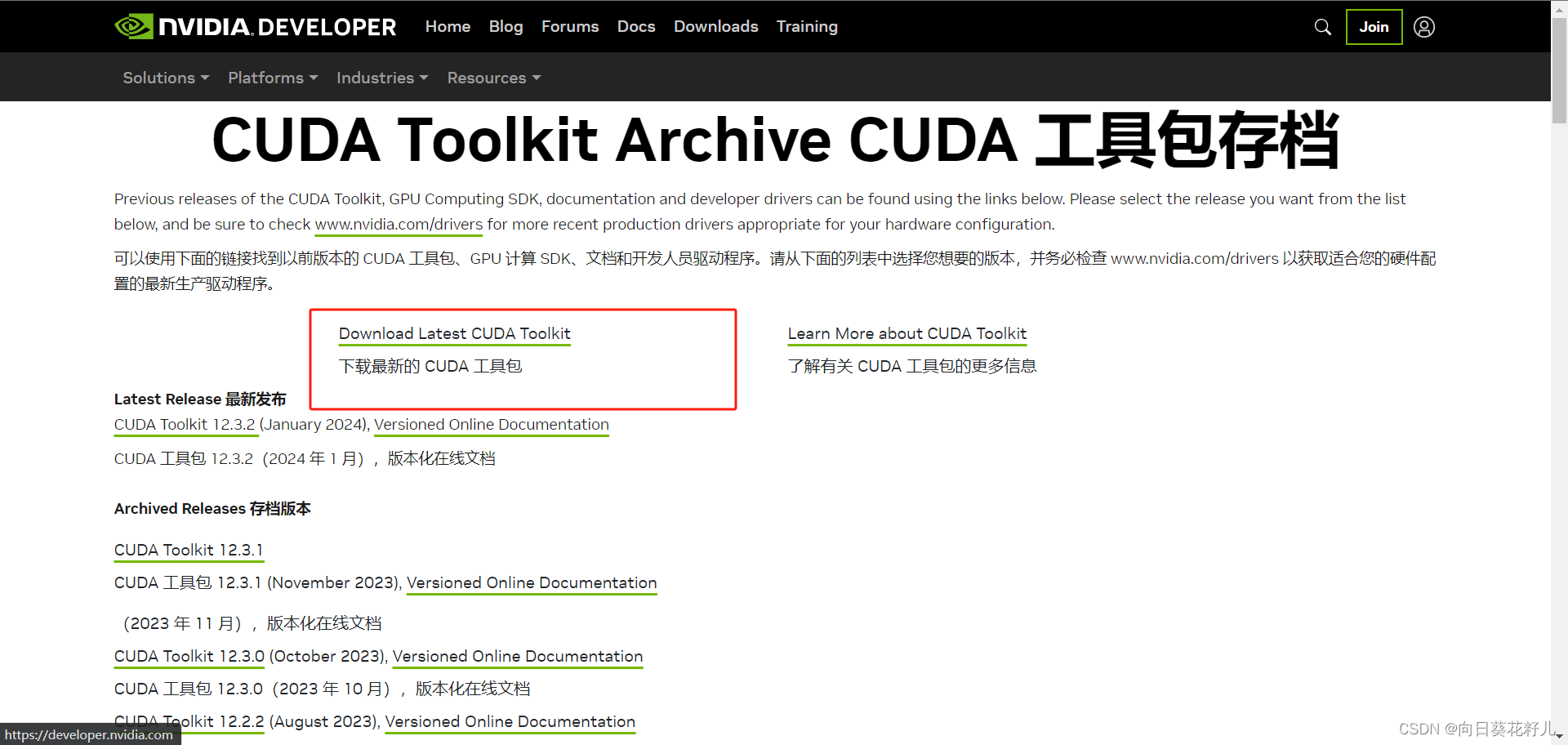
安装CUDA
https://developer.nvidia.com/cuda-toolkit-archive
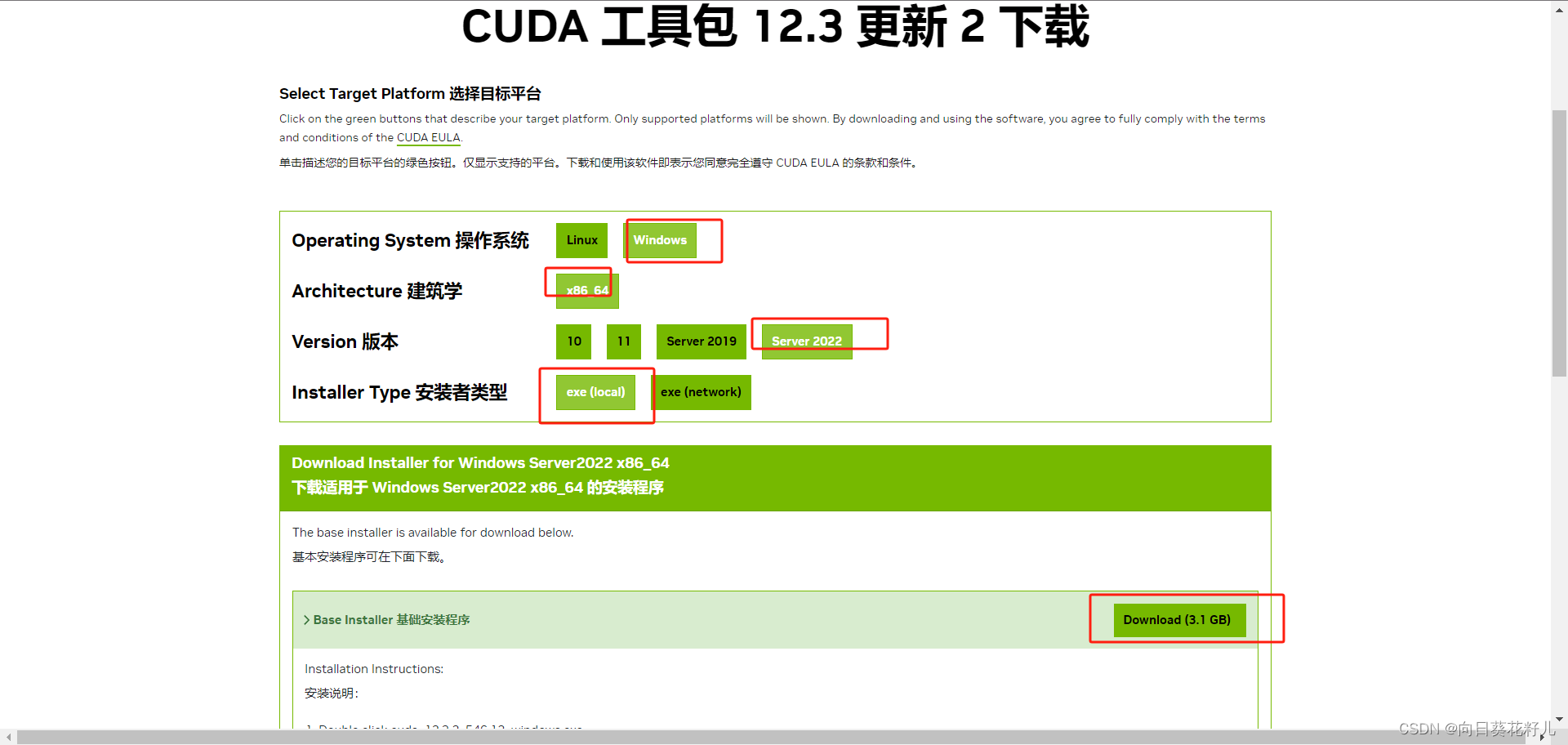
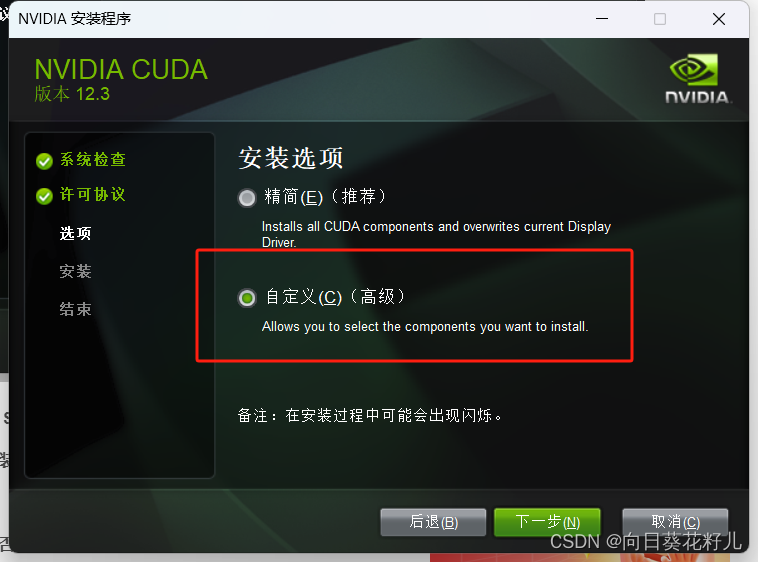
选择自定义安装
不要勾选Visual Studio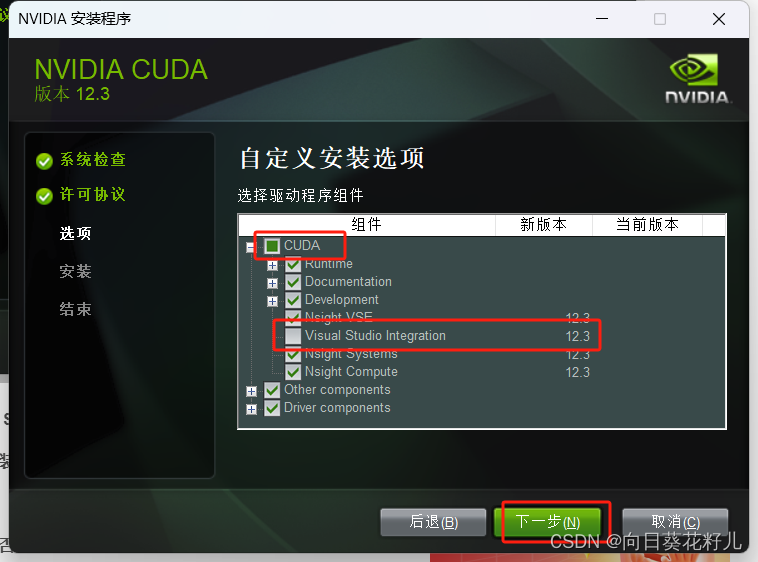
记录下面安装目录,如果后续环境变量没有自动添加,则需要手动添加下面路径到环境变量中。
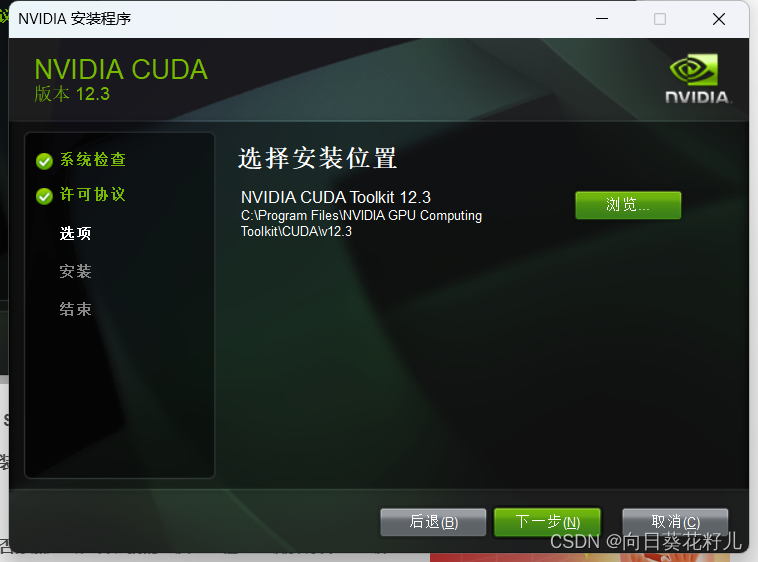
安装完毕
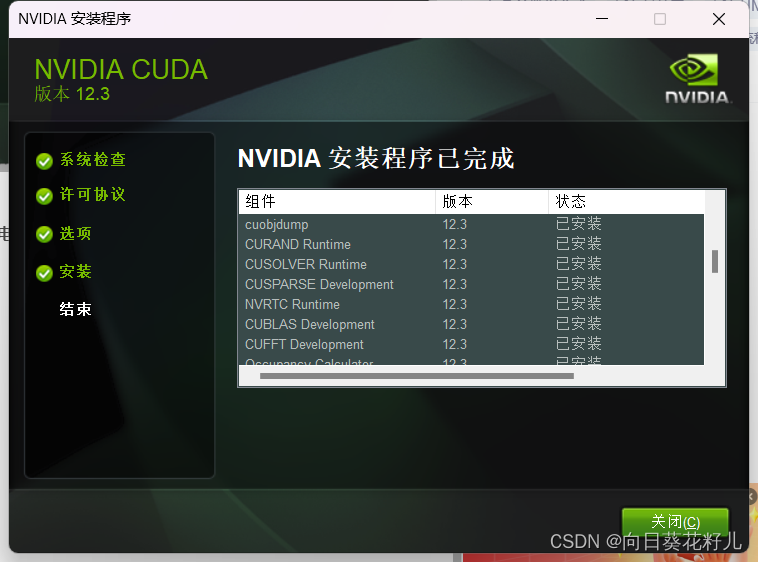
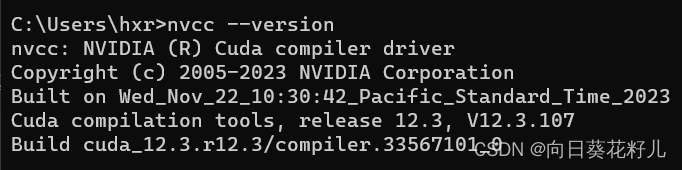
检查是否安装成功
我失败了

查看环境变量是否添加进去,右键我的电脑->属性->高级系统设置-高级
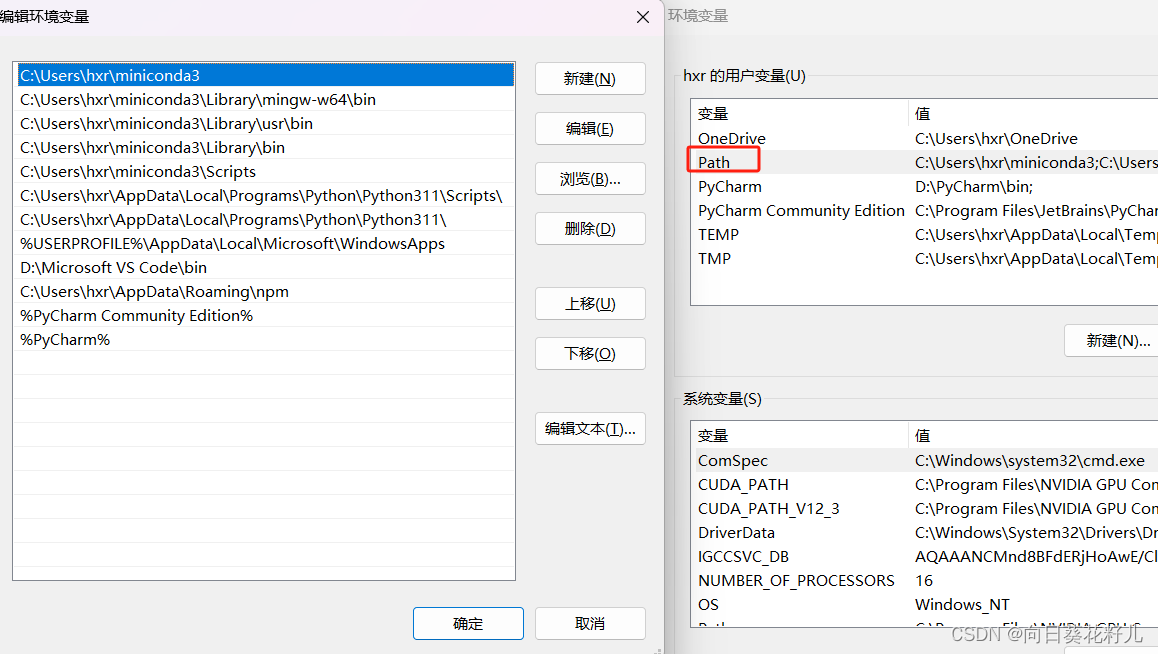 果然没有,那就手动添加
果然没有,那就手动添加
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.3
可以看到,已经添加成功
安装NVIDIA 驱动程序
程序添加CUDA
简洁版
import torch
print(torch.cuda.is_available())
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Selected device:", device)
详细版
我正在使用 text2vec 模型,并且该模型支持 GPU 加速,
通过以下步骤选择使用 GPU:
-
检查 GPU 是否可用:
在开始使用text2vec模型之前,你可以通过以下代码检查是否有可用的 GPU:import torch if torch.cuda.is_available(): print("GPU is available.") else: print("GPU is not available.")如果输出显示 GPU 可用,说明你的机器支持 GPU 加速。
-
选择 GPU 设备:
如果 GPU 可用,你可以选择使用 GPU 设备。在text2vec中,可能需要查看模型的文档或源代码,以确定如何将模型移至 GPU。通常,可以使用 PyTorch 或 TensorFlow 提供的方法将模型移至 GPU。import torch device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print("Selected device:", device) # 将模型移至 GPU model.to(device) -
进行文本向量化:
使用text2vec进行文本向量化时,确保你的文本向量化过程也在相同的设备上进行。这通常是由 PyTorch 或 TensorFlow 提供的方法来实现的。import torch # 假设 text2vec_model 是你的 text2vec 模型 text2vec_model.to(device) # 确保文本向量化也在相同的设备上进行 text_vector = text2vec_model.encode("Your text input", device=device)
请记住,确保 text2vec 模型库的版本是支持 GPU 加速的版本,且查阅文档以获取准确的信息。