为了实现监听器功能
pom.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.hmblogs</groupId>
<artifactId>hmblogs</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>hmblogs</name>
<description>hmblogs</description>
<properties>
<java.version>8</java.version>
<druid.version>1.2.8</druid.version>
<log4jdbc.version>1.16</log4jdbc.version>
</properties>
<dependencies>
<!-- druid数据源驱动 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- mybatis -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--Mysql依赖包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--lombok插件-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--监控sql日志-->
<dependency>
<groupId>org.bgee.log4jdbc-log4j2</groupId>
<artifactId>log4jdbc-log4j2-jdbc4.1</artifactId>
<version>${log4jdbc.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.9</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
application.yml文件内容如下:
server:
port: 8081
servlet.context-path: /
#配置数据源
spring:
datasource:
druid:
db-type: com.alibaba.druid.pool.DruidDataSource
driverClassName: net.sf.log4jdbc.sql.jdbcapi.DriverSpy
url: jdbc:log4jdbc:mysql://${DB_HOST:localhost}:${DB_PORT:3306}/${DB_NAME:eladmin}?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false
username: ${DB_USER:root}
password: ${DB_PWD:123456}
redis:
host: localhost
port: 6379
password: heming
database: 10logback.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="10 seconds">
<!-- 日志级别从低到高分为TRACE < DEBUG < INFO < WARN < ERROR < FATAL,如果设置为WARN,则低于WARN的信息都不会输出 -->
<!-- scan:当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true -->
<!-- scanPeriod:设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。 -->
<!-- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。 -->
<contextName>logback</contextName>
<property name="log.path" value="logs"></property>
<property name="Console_Pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level [%logger{50}] - %msg%n"/>
<appender name="Console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<Pattern>${Console_Pattern}</Pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- 时间滚动输出 level为 INFO 日志 -->
<appender name="RollingFileBackend" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/hmblogs.log</file>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level [%logger{50}] - %msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 每天日志归档路径以及格式 -->
<fileNamePattern>${log.path}/hmblogs/log-hmblogs-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>100MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!--日志文件保留天数-->
<maxHistory>15</maxHistory>
</rollingPolicy>
<!-- 此日志文件只记录info级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>Info</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!--additivity:是否继承root节点,默认是true继承。默认情况下子Logger会继承父Logger的appender,
也就是说子Logger会在父Logger的appender里输出。
若是additivity设为false,则子Logger只会在自己的appender里输出,而不会在父Logger的appender里输出。-->
<logger name="org.springframework" level="INFO" additivity="false">
<appender-ref ref="Console"/>
<appender-ref ref="RollingFileBackend"/>
</logger>
<logger name="org.mybatis" level="INFO"></logger>
<logger name="org.hibernate.SQL" level="DEBUG" additivity="false">
<appender-ref ref="Console"/>
<appender-ref ref="RollingFileBackend"/>
</logger>
<Logger name="org.apache.catalina" level="info"/>
<Logger name="org.apache.tomcat.util" level="info"/>
<!-- 从低到高为:All < Trace < Debug < Info < Warn < Error < Fatal < OFF-->
<root level="Info">
<appender-ref ref="Console"/>
<appender-ref ref="RollingFileBackend"/>
</root>
</configuration>BackendApplication.java文件内容如下:
package com.hmblogs.backend;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class BackendApplication {
public static void main(String[] args) {
SpringApplication.run(BackendApplication.class, args);
}
}
然后添加了kafkaConsumerListenerExample.java文件
package com.hmblogs.backend.util;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
*
* @description: kafka 消费者
* @copyright: @Copyright (c) 2022
* @company: hmblogs
* @author: heming
* @version: 1.0.0
* @createTime: 2024-01-18 8:31
*/
@Component
@Slf4j
public class kafkaConsumerListenerExample {
@KafkaListener(topics = "test", groupId = "0")
public void consume(ConsumerRecord<?, ?> record) {
Optional<?> value = Optional.ofNullable(record.value());
// 进行消息处理逻辑
log.info("print message: " + value);
}
}
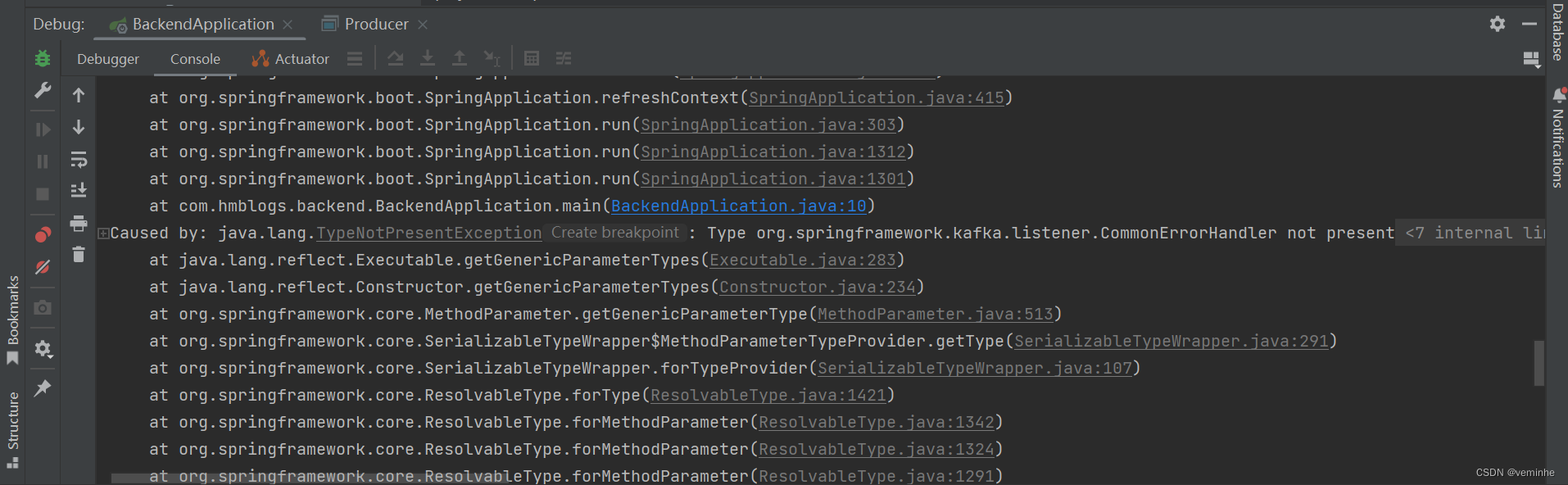
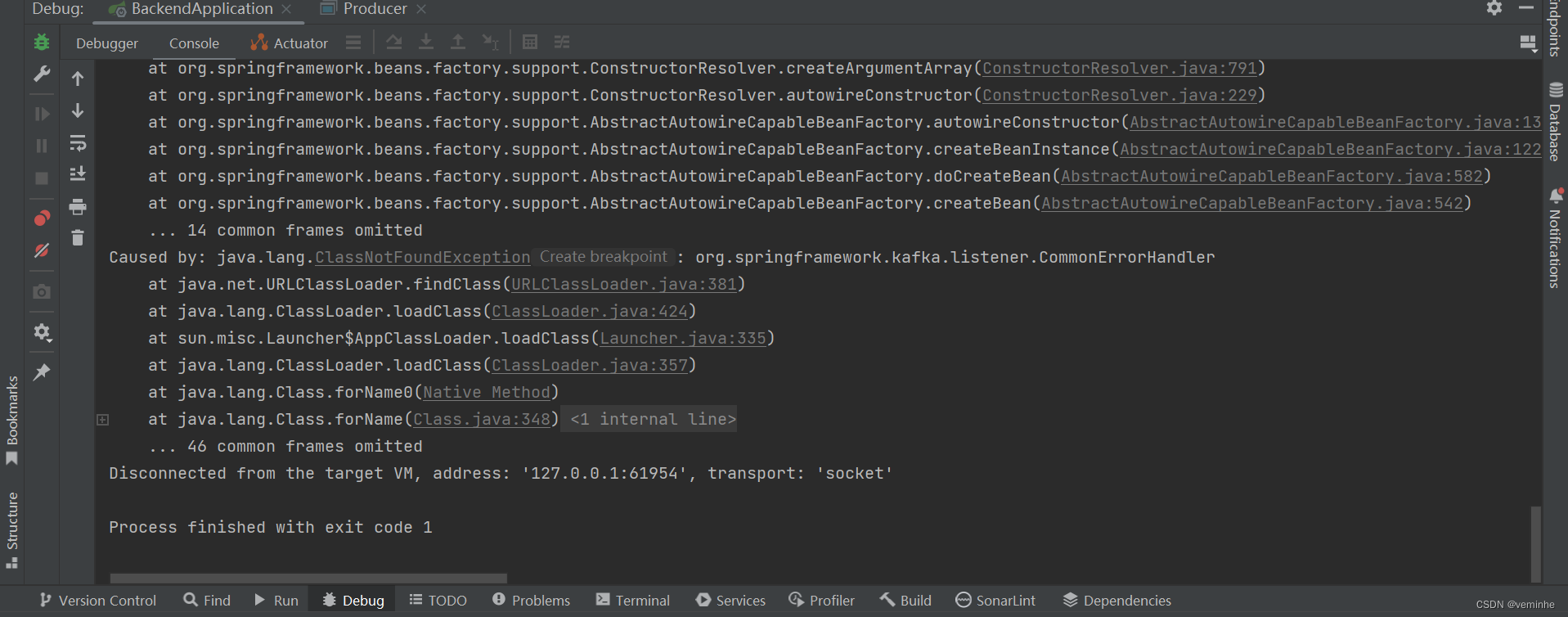
发到服务器上,启动hmblogs报错,截图如下:

Caused by: java.lang.TypeNotPresentException: Type org.springframework.kafka.listener.CommonErrorHandler not present
java.lang.ClassNotFoundException: org.springframework.kafka.listener.CommonErrorHandler
网上搜索资料,大部分讲的都是包冲突,在本地启动也是报这样的错,如下所示:




![RabbitMQ 部署与配置[CentOS7]](https://img-blog.csdnimg.cn/direct/afd49f9b2db343a4b40b02ddc01b4ee1.png#pic_center)