【本节目标】
1.vector的介绍及使用
2.vector深度剖析及模拟实现
1.vector的介绍及使用
1.1 vector的介绍
vertor文档介绍
- 1. vector是表示可变大小数组的序列容器。
- 2. 就像数组一样,vector也采用连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。
- 3. 本质讲,vector使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大小。
- 4. vector分配空间策略:vector会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。
- 5. 因此,vector占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长。
- 6. 与其它动态序列容器相比(deque, list and forward_list), vector在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list和forward_list 统一的迭代器和引用更好。
1.2 vector的使用
vector学习时一定要学会查看文档:vector的文档介绍,vector在实际中非常的重要,在实际中我们熟悉常 见的接口就可以,下面列出了哪些接口是要重点掌握的。
1.2.1 vector的定义

我们先来看一下vector文档中的构造函数


我们先来直接看看第二个构造函数的使用:创建一个包含n个元素的容器。每个元素都是val的副本
void test1()
{
vector<int> v(10, 1);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
运行结果:

我们再来看看第三个构造函数:创建一个包含与范围 [first, last) 中的元素数量相同的容器,每个元素都是从该范围中对应元素构造而来的,顺序相同。
void test2()
{
vector<int> v1(10, 1);
vector<int> v2(v1.begin(), v1.end());
vector<int>::iterator it1 = v2.begin();
while (it1 != v2.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;
}运行结果:

我们这里的迭代器区间能不能是其他容器,比如string。
void test3()
{
string str("hello world");
//vector<int> v2(str.begin(), str.end());
//string是char类型,这里模板参数需要转为char
//如果为int则会输出字符对应的ASCII码值
vector<char> v2(str.begin(), str.end());
for (size_t i = 0; i < v2.size(); i++)
{
cout << v2[i] << " ";
}
cout << endl;
}
那在这里就要提出一个问题了,能不能用vector<char>替代string呢?
肯定不可以,虽然string的有些功能可以通过vector<char>实现,但是string中还提供了插入一个字符串的功能,vector<char>只能插入单个字符。同时有些库函数或接口可能期望传递的是以 null 结尾的 C 风格字符串,而
vector<char>不会在末尾添加 null 终止字符。在这种情况下,使用string更方便,因为它保证末尾有 null 终止字符。
1.2.2 vector iterator 的使用
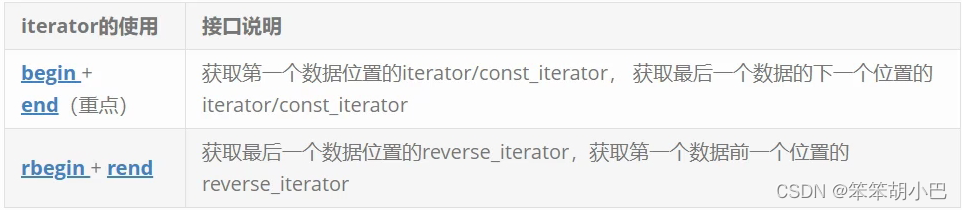
void test4()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
vector<int>::iterator it1 = v.begin();
while (it1 != v.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;
vector<int>::reverse_iterator it2 = v.rbegin();
while (it2 != v.rend())
{
cout << *it2 << " ";
++it2;
}
cout << endl;
}运行结果:

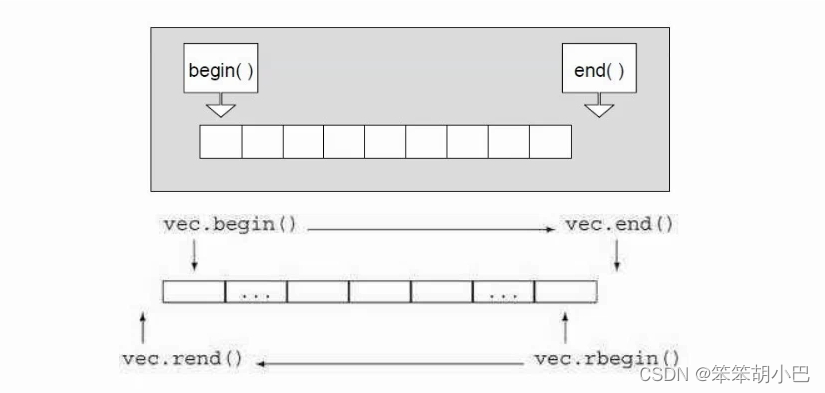
1.2.3 vector 空间增长问题
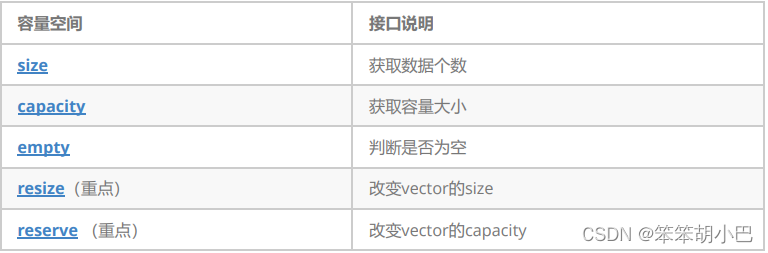
capacity的代码在vs和g++下分别运行会发现,vs下capacity是按1.5倍增长的,g++是按2倍增长的。 这个问题经常会考察,不要固化的认为,vector增容都是2倍,具体增长多少是根据具体的需求定义 的。vs是PJ版本STL,g++是SGI版本STL。
// 测试vector的默认扩容机制
void TestVectorExpand()
{
size_t sz;
vector<int> v;
sz = v.capacity();
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}运行结果:
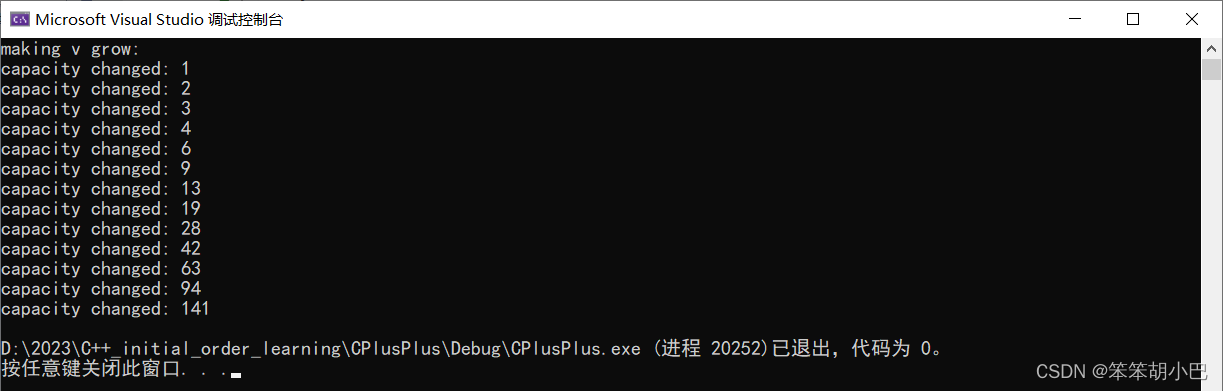
vs:运行结果:vs下使用的STL基本是按照1.5倍方式扩容
linux下的情况是怎么样的呢?我们去验证一下
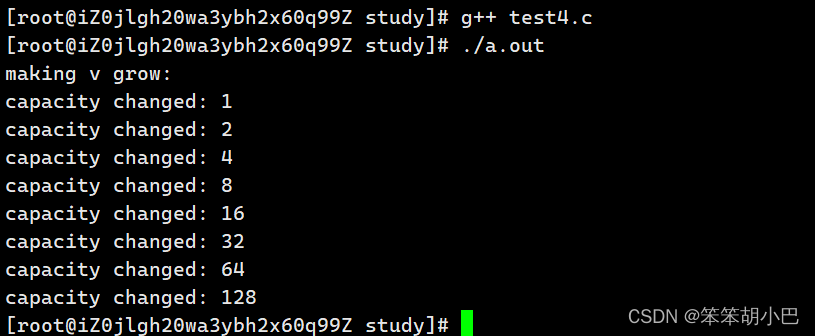
结论:g++运行结果:linux下使用的STL基本是按照2倍方式扩容
为了解决上面多次开辟空间造成的消耗,我们可以提前开辟空间,我们是用reserve还是resize呢?
reserve只负责开辟空间,如果确定知道需要用多少空间,reserve可以缓解vector增容的代价缺陷问题。而resize在开空间的同时还会进行初始化,影响size。

void TestVectorExpandOP()
{
vector<int> v;
size_t sz = v.capacity();
v.reserve(100); // 提前将容量设置好,可以避免一遍插入一遍扩容
cout << "making bar grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}vs上一般是不会缩容的,如果我们想要缩容呢?我们就可以使用C++11提供的缩容函数。
void test6()
{
vector<int> v;
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
}
cout << v.size() << endl;
cout << v.capacity() << endl;
v.resize(10);//不缩容
cout << v.size() << endl;
cout << v.capacity() << endl;
v.shrink_to_fit();
cout << v.size() << endl;
cout << v.capacity() << endl;
}运行结果:

1.2.4 vector 增删查改
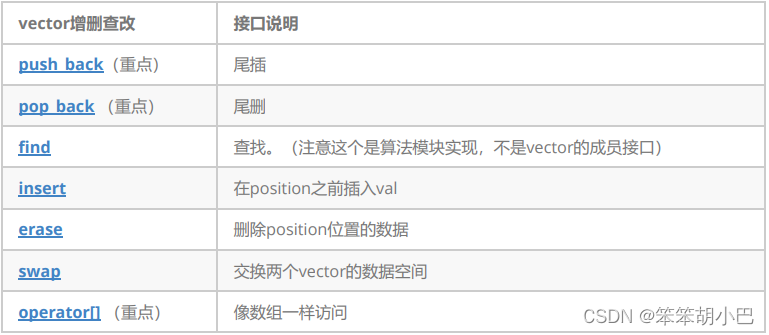
相比string容器的insert,这里vector容器提供的insert就简洁了很多。

我们知道string都是使用的下标,而这里的vector都是使用的迭代区间。
void test7()
{
vector<int> v;
//尾插
v.push_back(2);
v.push_back(3);
v.push_back(4);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
//头插
v.insert(v.begin(), 1);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}运行结果:

如果我们想在元素3的位置之前插入一个30呢?可以使用find函数找到元素3的下标,但是我们在vector里面没有找到find函数!!!

注意:find这个函数是算法模块实现,不是vector的成员接口。

问题:为什么string容器要单独写一个find函数,而不直接像vector一样直接使用算法里面的find呢?
string容器除了查找字符,有时候还会查找字符串,使用算法模块的find函数不太方便,同时string类返回下标才能和其他函数接口更好匹配,而算法模块里面的find函数返回的是迭代器。
void test7()
{
vector<int> v;
//尾插
v.push_back(2);
v.push_back(3);
v.push_back(4);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
//头插
v.insert(v.begin(), 1);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
vector<int>::iterator it = find(v.begin(), v.end(), 3);
//中间插入,如果找不到就不插入
if(it != v.end())
{
v.insert(it, 30);
}
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}运行结果:

注意:对于 vector 来说,它本身不提供流插入和流提取运算符的重载(<< 和 >>),因为这些运算符的行为和预期对于一系列同类型元素的容器并不明确。
输出操作的歧义性:
vector可能包含大量元素,直接使用流插入操作符<<输出整个容器可能会导致输出过于庞大,不方便进行控制。输入操作的难以解释性: 对于流提取运算符
>>,尝试从流中提取元素并放入std::vector时可能需要解决一些语义上的歧义问题。比如,应该如何确定输入流的结束以停止提取?如果元素类型没有默认构造函数,又该如何处理?
我们一般通过下面的方式去遍历访问。
//下标 + []
for (size_t i = 0; i < v.size(); i++)
{
cout << v[i] << " ";
}
cout << endl;
//迭代器
vector<int>::iterator it1 = v.begin();
while (it1 != v.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;
//范围for
for (auto e : v)
{
cout << e << " ";
}
cout << endl;1.2.5 vector 在OJ中的使用
1. 只出现一次的数字i
class Solution{
public:
int singleNumber(vector<int>&nums)
{
int value = 0;
for (auto e : nums)
{
value ^= e;
}
return value;
}
};
2. 杨辉三角OJ
我们先来介绍一个这个返回值类型是怎么个事儿。
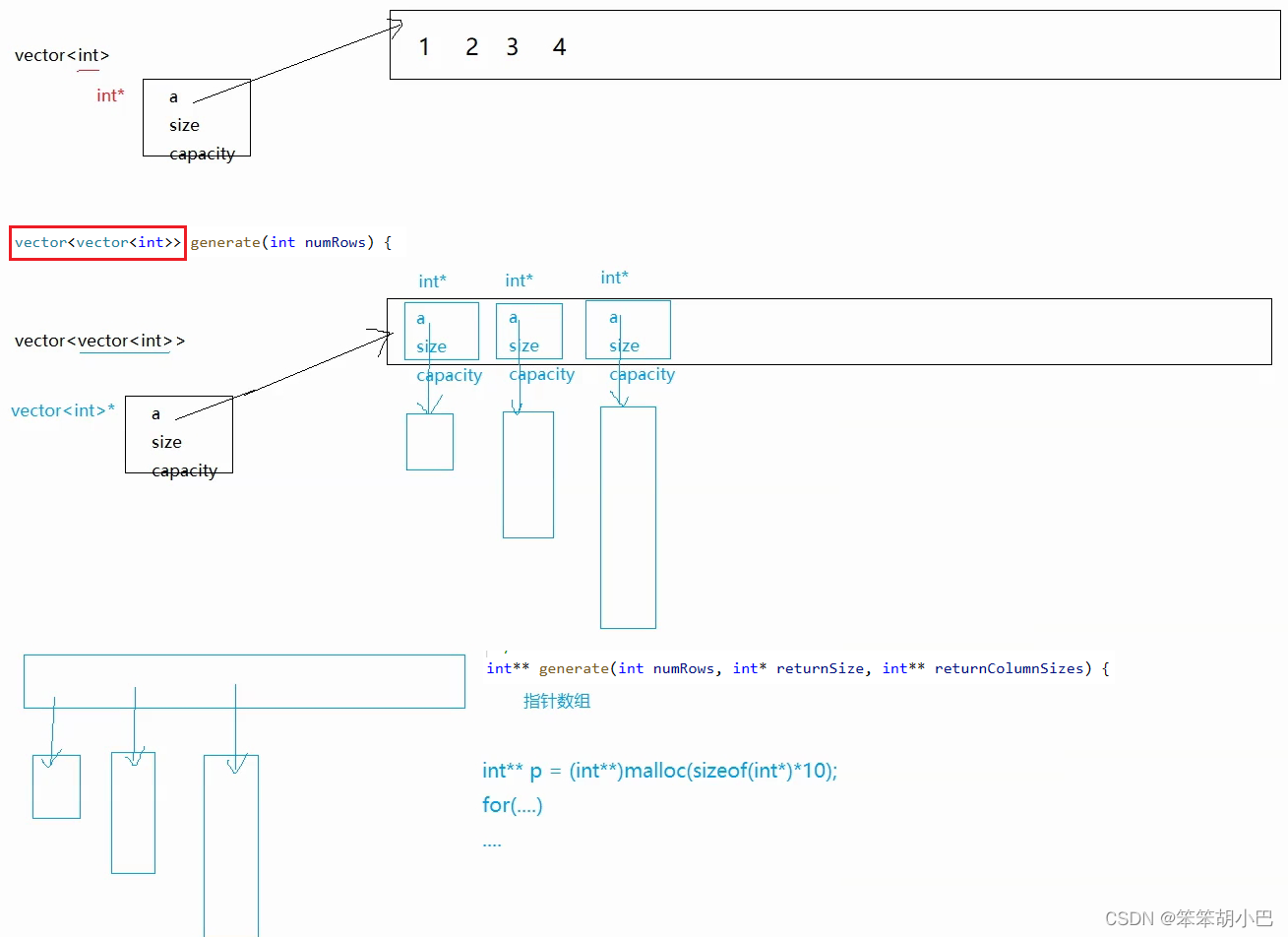
// 涉及resize / operator[]
// 核心思想:找出杨辉三角的规律,发现每一行头尾都是1,中间第[j]个数等于上一行[j-1]+[j]
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv(numRows);
for (int i = 0; i < numRows; ++i)
{
vv[i].resize(i + 1, 1);
}
for (int i = 2; i < numRows; ++i)
{
for (int j = 1; j < i; ++j)
{
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];
}
}
return vv;
}
};那我们的vector<string>可行吗?可行。
void test8()
{
vector<string> vstr;
string s1("张三");
vstr.push_back(s1);
vstr.push_back(string("李四"));
vstr.push_back("王五");
for (auto e : vstr)
{
cout << e << endl;
}
cout << endl;
}我们上面的程序vstr将每个string赋值个e,这里就会存在深拷贝的问题,消耗较大,所以我们可以使用引用,并且这里我们不希望值会被更改,所以加上const。
void test8()
{
vector<string> vstr;
string s1("张三");
vstr.push_back(s1);
vstr.push_back(string("李四"));
vstr.push_back("王五");
for (const auto& e : vstr)
{
cout << e << endl;
}
cout << endl;
}运行结果:

如果我们想访问第一个元素呢?此时e就是一个string,访问第一个字符就可以通过[ ]访问。
void test8()
{
vector<string> vstr;
string s1("leetcode");
vstr.push_back(s1);
vstr.push_back(string("our"));
vstr.push_back("vector");
for (const auto& e : vstr)
{
cout << e[0];
}
//还可以这样访问
//第一个[]调用vector的[],找到string
//的二个[]调用string的[],找到char
cout << vstr[0][1];
}运行结果:

这里就存在一个问题了,能否用vector<char>代替string类呢?
这里是不行的,string 类在 C++ 中是一个标准库提供的字符串类型,它自动管理字符串的长度,包括在末尾添加 null 终止符 '\0'。这使得 string 对象可以方便地与 C 风格的字符串互操作。而 vector<char> 是一个通用的动态数组,它只是存储一系列的字符,不会自动在末尾添加 null 终止符。因此,如果你试图用 vector<char> 来代替 string,你可能会遇到一些问题,尤其是在与 C 风格字符串函数或其他字符串处理函数的交互时,所以不能使用vector<char>代替string。
2.vector深度剖析及模拟实现
我们先来看一下vector实现的源码,看一个容器的源码,我么首先提出几点:
- 1.不要一行一行看
- 2.不要看太多细节,这个阶段我们的水平有一点不匹配,待我们的代码经验更丰富再去看细节
- 3.学会看框架
我们首先要看类的成员变量
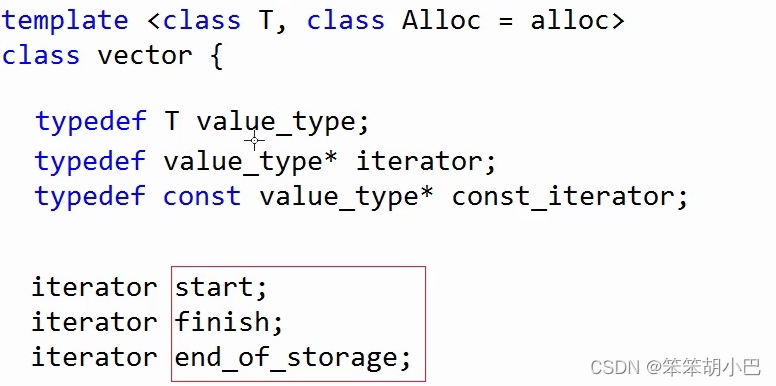
然后再看构造函数,我们去看看vector是怎么初始化的。
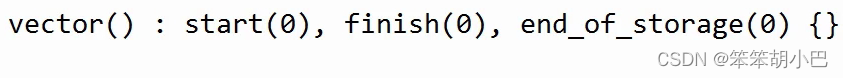
最后我再看看插入逻辑 - push_back


此时我们就能大概猜到上面成员变量的大概意思,start是指向数组开始的位置,finish是指向有效元素个数的下一个位置,end_of_storage是指向空间结束位置。
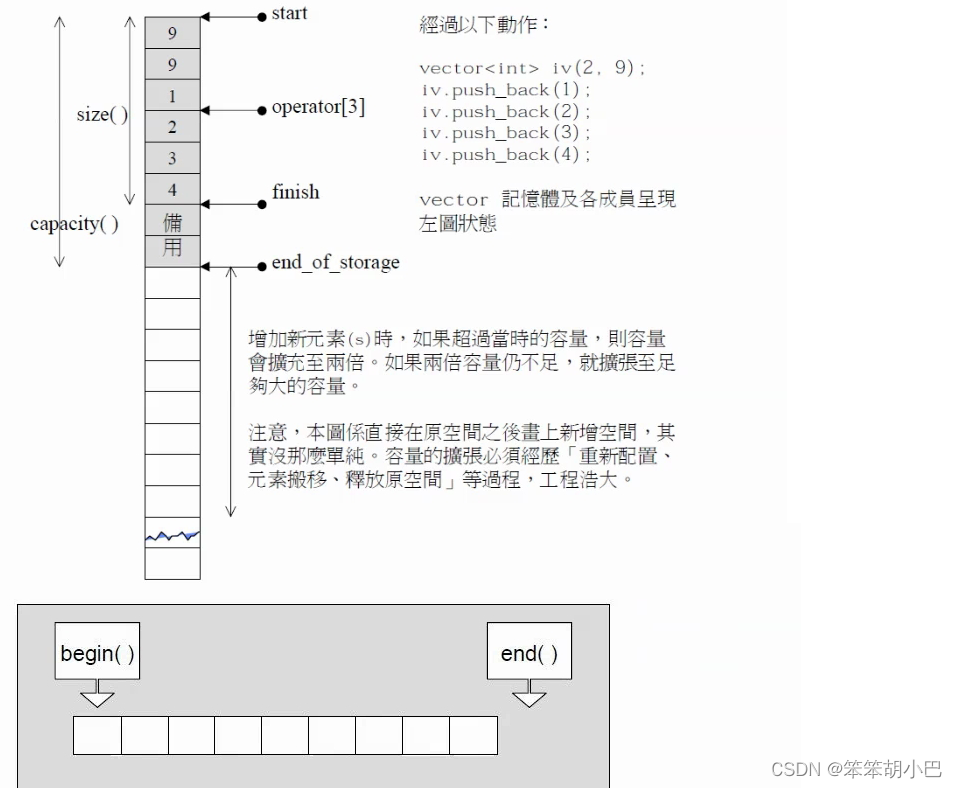
现在我们就开始手撕vector的实现。首先为了防止和库里面的vector容器冲突,我们直接使用命名空间解决这个问题。

然后我们再来写一下成员变量。
namespace yu
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}我们先来实现一下构造函数,这里直接无参时直接初始化为空指针即可。
vector()
:_start(nullptr)
,_finish(nullptr)
,_end_of_storage(nullptr)
{}除了无参的构造函数,库里面还存在其他的构造函数。

我们先来实现一下迭代器区间构造函数。
//迭代器区间构造
//单独添加模板作为参数
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}运行结果:

这里为什么不直接给迭代器,而要给一个模板参数呢?这里要支持多种形式,比如数组或者链表,数组这里可以是因为数组底层物理空间是连续的,属于天然迭代器。

接着实现一下n个val初始化
vector(size_t n, const T val = T())
{
resize(n, val);
}
void test_vector11()
{
vector<string> v1(5, "123");
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
vector<int> v2(5, 1);
for (auto e : v2)
{
cout << e << " ";
}
cout << endl;
}运行我们的程序发现报错了,我们发现v2调用了迭代器区间构造,因为它更匹配v2。

怎么修改呢?参数不使用size_t,使用重载int就可以解决。
// 使用int重载函数
vector(int n, const T val = T())
{
resize(n, val);
}
void test_vector11()
{
vector<string> v1(5, "123");
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
vector<int> v2(5, 1);
for (auto e : v2)
{
cout << e << " ";
}
cout << endl;
}再来实现一下析构函数
~vector()
{
if(_start)
{
delete[] _start;
_start = nullptr;
_finish = nullptr;
_end_of_storage = nullptr;
}
}vector的本质就是顺序表,在我们之前写的顺序表中,除了指向这个顺序表的指针,同时还存在了size和capacity这两个重要的变量,因此在这里我们也要有能获取size和capacity的函数。在这之前我们先复习一下,还记得我们的strlen是干嘛的吗?还记得是怎么实现的吗?
//模拟实现strlen
int mystrlen(char* str)
{
assert(str != nullptr);
char* begin = str;
while (*str != '\0')
{
++str;
}
return str - begin;
}
int main()
{
//strlen是获取字符串的个数,不包括'\0'
char str[] = "hello!";
printf("strlen(str):%d\n", strlen(str));
printf("mystrlen(str):%d\n", mystrlen(str));
return 0;
}运行结果:

通过上面的模拟实现我们想证明什么呢?我想说的是指针相减是之间元素的个数,begin指向'h'的位置,而str指向'\0'的位置,它们之间相减就是元素个数,而我们上面的vector的成员变量都是指针,因此我们也可以通过指针相减获取size和capacity。
//指针相减是之间的元素个数。
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _end_of_storage - _start;
}由于在获取size和capacity的时候,我们没有改变对象的属性,因此此时可以加上const修饰。现在我们再想实现尾插,尾插必定要有扩容的动作,所以这里我们先实现reserve函数(不缩容版本)。我们在模拟实现string类的时候已经实现过reserve函数,reserve函数的实现四个步骤:
- 1.开辟新空间
- 2.拷贝数据
- 3.释放旧空间
- 4.指向新空间
void reserve(size_t n)
{
if(n > capacity())
{
T* temp = new T[n];
if(_start)
memcpy(temp,_start,n*sizeof(T));
delete[] _start;
_start = temp;
_finish = _start + size();
_end_of_storage = _start + capacity();
}
}此时我们的开辟空间的函数就已经写成了,然后我们在来实现我们的尾插push_back函数,注意我们这里实现的是二倍扩容。
void push_back(const T& x)
{
if(_finish == _end_of_storage)
{
//开辟空间
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = x;
++_finish;
}这里就有一个问题了,我们在push_back函数已经判断了newcapacity必定是大于capacity(),可是在reserve函数我们又再次判断了一下,这是不是有一点多余呀!不多余,因为reserve函数除了push_back函数会使用,也可以单独使用,此时就需要另做判断。为了方便观察到我们是否成功插入函数,这里我们需要写一下迭代器begin和end。
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}现在就可以测试我们的vector的尾插功能了。
void test_vector1()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector<int>::iterator it = v.begin();
while(it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
int main()
{
yu::test_vector1();
return 0;
}
此时我们运行我们的程序,发现程序崩溃了。为什么呢?我们调试一下。
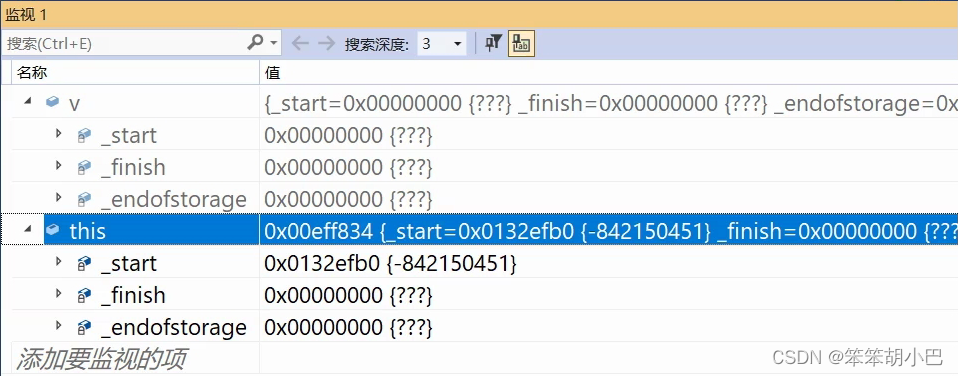
很明显我们发现我们开空间没有开辟成功,_finish为空指针,在尾插的时候进行了解引用操作,所以程序就会崩溃,所以就是eserve函数出现了问题。

当我们的程序运行到了39行,此时38行的代码已经运行完了,但是此时_finish还是为空指针,所以就可以断定是这一步出现了问题。

从上图我们就可以发现当我们执行_start = temp;之后,此时_start就也指向了tmp所指向的那一块空间,而此时_finish还是指向旧空间的地方,我们的size函数是使用的_finish - _start,此时_start的地址已经发生变化,_finish - _start之间相减就是未知数,所以此时程序就会报错,capacity同样如此。
void reserve(size_t n)
{
if(n > capacity())
{
T* temp = new T[n];
size_t oldsize = size();//保存旧空间有效元素的个数
if(_start)
{
//这里不需要拷贝n个,只需oldsize个,因为有效元素个数为oldsize
memcpy(temp,_start,oldsize*sizeof(T));
delete[] _start;
}
_start = temp;
_finish = _strat + oldsize;
_end_of_storage = _start + n;
}
}运行结果:

上面为了打印输出,我们使用的是迭代器的方式,我们前面也讲到打印一共有三种方法,现在我们已经使用了一种,还有两种是范围for和[]操作符重载。范围for前面我们也已经提到它底层就是通过迭代器实现的,它是一种傻瓜式的替换,我们来看一下范围for输出结果
void test_vector3()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
yu::test_vector3();
return 0;
}
运行结果:
vector尾插尾删的效率非常高效,但是头部或者中间插入删除效率比较一般,尽量少用,但是vector的最大优势还是随机访问。
c语言阶段学习的顺序表的随机访问是具有局限性的,是只读的,不能对内部元素进行修改。但是我们这里也可以修改,使用返回指针 + 解引用操作才可以。
int SLAT(SL* ps, int pos)
{
//可以获得当前位置的元素
//返回的是顺序表pos位置元素的拷贝
//但是不能对元素进行修改
}
SL s;
SLAT(&s, i);c++为了解决这个问题提供了运算符重载[]和at函数,这里着重实现运算符重载,它通过传引用返回,直接可以对元素进行修改。
//此时没有加const,可读可写
T& operator[] (size_t pos)//传引用返回
{
assert(pos < size());
return _start[pos];
}
void test_vector3()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
for(int i = 0; i < v.size(); ++i)
{
//v.operator[](i) == v[i]
cout << v[i] << " ";
}
cout << endl;
}
int main()
{
yu::test_vector3();
return 0;
}
我们来看一下范围for输出结果
运行结果:
有了上述三种形式输出打印,此时就可以完全实现print_vector函数了,那我们就来使用范围for吧。
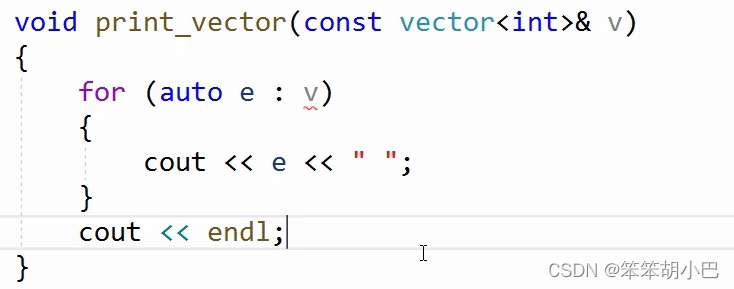
很奇怪,这里为什么报错了?这是因为print_vector的参数是const类型的,而我们没有实现const版本的迭代器,此时才会报错。
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}
void print_vector(const vector<int>& v)
{
for(auto e : v)
{
cout << e << " ";
}
cout << endl;
}此时我们再去运行一下,就没有错误了。然后我们再来实现一下尾删pop_back函数,这里比较简单,vector是不支持在单独的头插头删函数的,所以我们这里也就不实现了。
void pop_back()
{
assert(size() > 0);
--_finish;
}此时我们再实现一下在任意位置之前插入的函数insert。
// 在pos位置插入
void insert(iterator pos,const T& x)
{
assert(pos >= _start && pos <= _finish);
// 检查扩容
if(_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : capacity() * 2);
}
// 把pos后面的数据移走,再把x放到pos位置
memmove(pos + 1,pos,sizeof(T)*(_finish - pos));
*pos = x;
++_finish;
}
void test_vector2()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.insert(v.begin(), 100);
print_vector(v);
}
int main()
{
yu::test_vector2();
return 0;
}运行结果:

我们再头插一个数据,看看结果如何?

此时我们头插第一个数据没有问题,为什么插入再次头插程序就崩溃了呢?我们调式一下

发现是memmove函数发生崩溃了,为什么?这里本质是一直迭代器失效,pos失效了,扩容后出现问题了。
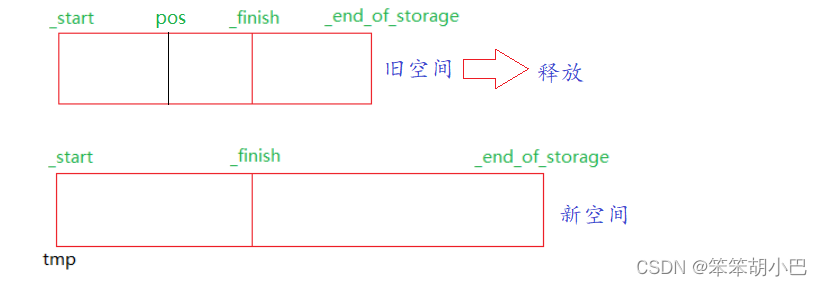
根据上面的图我们可以知道此时的pos仍然指向旧空间的位置,没有随着新空间的开辟而变化,所以当扩容之后,此时pos指向的就是随机地址,此时访问也肯定会出错,要想解决,我们就要更新pos。
// 在pos位置插入
void insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
// 检查扩容
if (_finish == _end_of_storage)
{
//记录pos到_start的距离
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : capacity() * 2);
//如果发生扩容
pos = _start + len;
}
// 把pos后面的数据移走,再把x放到pos位置
memmove(pos + 1, pos, sizeof(T) * (_finish - pos));
*pos = x;
++_finish;
}运行结果:

erase接口的实现
void erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _finish);
iterator it = pos + 1;
while (it < _finish)
{
*(it - 1) = *it ;
++it;
}
--_finish;
}
void test_vector3()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
print_vector(v);
v.erase(v.begin());
print_vector(v);
v.erase(v.begin() + 3);
print_vector(v);
}
int main()
{
yu::test_vector6();
return 0;
}运行结果:

resize接口的实现 - 不缩容
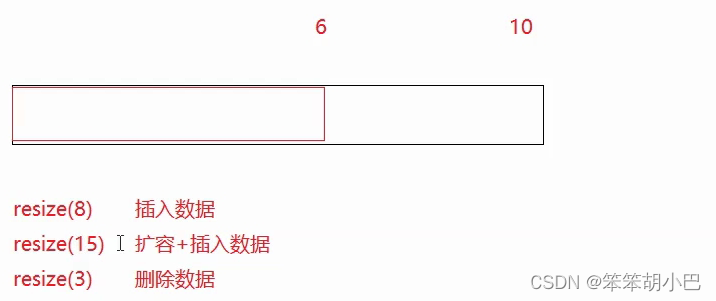
我们先来看一下resize的第二个参数T val = T(),这使一个缺省值,如果我们没有传参的时候,T()是一个匿名对象,它使用类型T的默认构造函数来初始化元素,比如我们的string类,它就会去调用string类的默认构造函数,此时会给val初始化一个带null字符'\0'的空串,对于内置类型,在C++中它也有默认构造函数,如果内置类型是int,它就会初始化为0,是double,就会初始化为0.0。
void resize(size_t n, T val = T())
{
if (n > size())
{
reserve(n);
//这里就包含了两种情况
/*
1.resize(8),此时n<capacity(),进入reserve函数啥事不干
2.resize(15),此时n>capacity(),进入reserve函数扩容
*/
while (_finish < _start + n)
{
*_finish = val;
++_finish;
}
}
else
{
_finish = _start + n;
}
}
void test_vector4()
{
vector<int> v;
v.reserve(10);
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
print_vector(v);
v.resize(8);
print_vector(v);
v.resize(15, 1);
print_vector(v);
v.resize(3);
print_vector(v);
}
int main()
{
yu::test_vector4();
return 0;
}运行结果:

内置类型我们已经验证过了会调用默认的构造函数初始化val,我们再来看看自定义类型
void test_vector5()
{
vector<string> v;
v.reserve(10);
v.push_back("xxxx");
v.push_back("xxxx");
v.push_back("xxxx");
v.push_back("xxxx");
v.push_back("xxxx");
v.push_back("xxxx");
print_vector(v);
v.resize(8);
print_vector(v);
v.resize(15, "yyyy");
print_vector(v);
v.resize(3);
print_vector(v);
}运行结果:
但是程序这里崩溃了,原因暂时先不说,我们可以观察到上面的现象就行。我们再看一下拷贝构造和赋值拷贝。
void test_vector3()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
print_vector(v);
// 拷贝构造
vector<int> v1 = v;
print_vector(v);
print_vector(v1);
}
int main()
{
yu::test_vector3();
return 0;
}运行结果:
此时我们的程序崩溃了,因为我们此时的程序没有写拷贝构造函数,此时使用的是编译器生成的默认拷贝构造函数,而它是浅拷贝,析构两次,所以程序此时就会报错。
vector(const vector<T>& v)
{
//开辟同样大小的空间,然后拷贝数据
_start = new T[v.capacity()];
memcpy(_start, v._start, sizeof(T) * v.size());
_finish = _start + v.size();
_end_of_storage = _start + v.capacity();
}运行结果:

同时我们这里也可以换一种写法
vector(const vector<T>& v)
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
for (auto e : v)
{
push_back(e);
}
}我们直接通过尾插push_back函数完成拷贝构造,push_back函数会帮我们改变_start , _finish和_end_of_storage。上面我们必须要对_start , _finish和_end_of_storage进行初始化成nullptr,否则就可能是随机值,会出现错误。同时我们这里还可以简化,根据C++11,我们可以给成员变量给上缺省值。
private:
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_storage = nullptr;
};
vector(const vector<T>& v)
{
for (auto e : v)
{
push_back(e);
}
}我们这里还可以优化,看看下面的代码
vector(const vector<T>& v)
{
reserve(v.capacity());
for (const auto& e : v)
{
push_back(e);
}
}此时提前开辟好空间,防止后面会反复开辟空间消耗时间,同时这里使用传引用拷贝,能节省很大开销。然后我们再来实现一下赋值拷贝,这里就不写传统写法的那个开空间拷贝了,这里直接使用现代写法。
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
}
// 赋值拷贝现代写法
// v2 = v1,v是v1的拷贝
// 这个参数不能传引用
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}3.vector 迭代器失效问题。(重点)
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所指向的 空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器, 程序可能会崩溃)。
对于vector可能会导致其迭代器失效的操作有:
3.1. 会引起其底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、 push_back等。
#include <iostream>
using namespace std;
#include <vector>
int main()
{
vector<int> v{ 1,2,3,4,5,6 };
auto it = v.begin();
// 将有效元素个数增加到100个,多出的位置使用8填充,操作期间底层会扩容
// v.resize(100, 8);
// reserve的作用就是改变扩容大小但不改变有效元素个数,操作期间可能会引起底层容量改变
// v.reserve(100);
// 插入元素期间,可能会引起扩容,而导致原空间被释放
// v.insert(v.begin(), 0);
// v.push_back(8);
// 给vector重新赋值,可能会引起底层容量改变
v.assign(100, 8);
/*
出错原因:以上操作,都有可能会导致vector扩容,也就是说vector底层原理旧空间被释放掉,
而在打印时,it还使用的是释放之间的旧空间,在对it迭代器操作时,实际操作的是一块已经被释放的
空间,而引起代码运行时崩溃。
解决方式:在以上操作完成之后,如果想要继续通过迭代器操作vector中的元素,只需给it重新
赋值即可。
*/
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}这里我们着重来介绍一下插入函数的迭代器失效问题。

在上面我们函数内部的迭代器失效的问题得到了解决,但是外部的迭代器失效问题依然没有解决,因为pos是形参,我们只在函数内部对pos位置进行了更新,而形参得改变是不会影响实参的,外部的it依然指向原始释放的旧空间,因此外部的迭代器失效问题依然没有解决。
3.2. 指定位置元素的删除操作--erase
#include <iostream>
#include <vector>
using namespace std;
int main()
{
int a[] = { 1, 2, 3, 4 };
vector<int> v(a, a + sizeof(a) / sizeof(int));
// 使用find查找3所在位置的iterator
vector<int>::iterator pos = find(v.begin(), v.end(), 3);
// 删除pos位置的数据,导致pos迭代器失效。
v.erase(pos);
cout << *pos << endl; // 此处会导致非法访问
return 0;
}erase删除pos位置元素后,pos位置之后的元素会往前搬移,没有导致底层空间的改变,理论上讲迭代器不应该会失效,但是:如果pos刚好是最后一个元素,删完之后pos刚好是end的位置,而end位置是没有元素的,那么pos就失效了。因此删除vector中任意位置上元素时,vs就认为该位置迭代器失效了。
以下代码的功能是删除vector中所有的偶数,请问那个代码是正确的,为什么?
void test_vector6()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}
}运行结果:
我们来调式一下程序
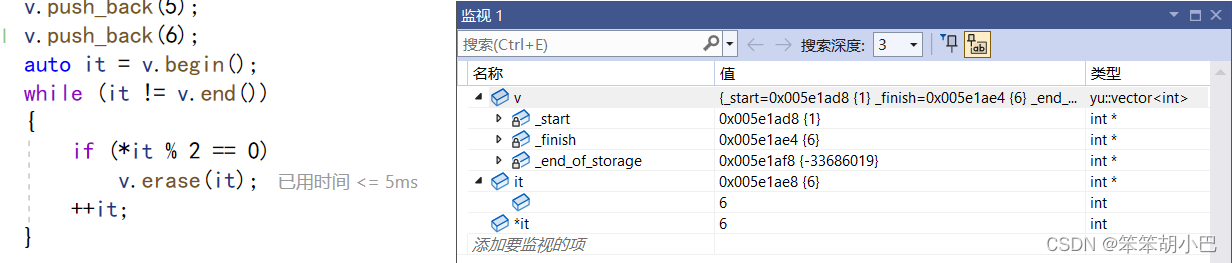
我们发现当程序删除最后一个元素后,此时就应该停止,但是我们的程序还执行了++it,导致it向后访问了,由于我们的程序是不缩容的,导致我们的程序删除最后一个元素仅仅是--finish,并没有将之前_finish的元素进行销毁,所以此时还是6,导致程序又进去了,然后程序判断为偶数,于是执行删除,但是此时pos位置不再小于_finish,于是程序就触发断言了。我们来看看图解
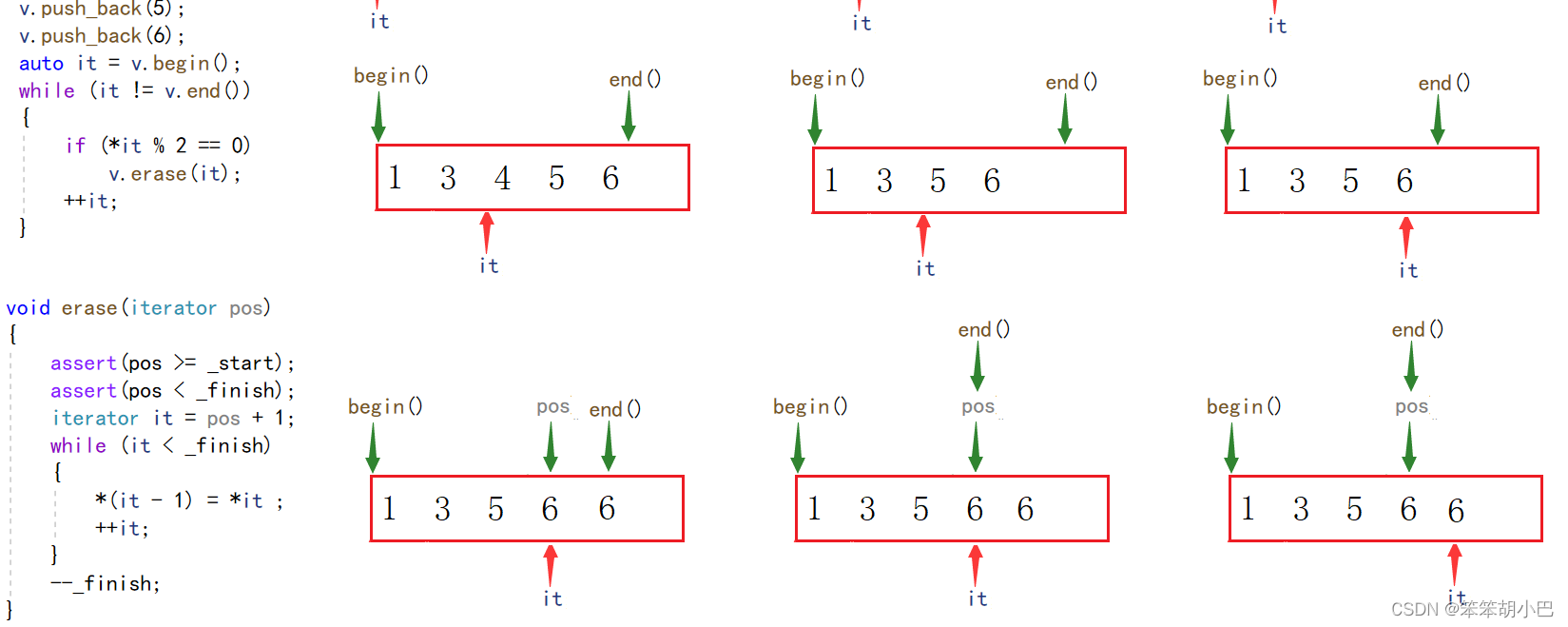
如果我们再尾插一个奇数呢?
void test_vector6()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}
print_vector(v);
}运行结果:

这是因为在删除6之后,it然后执行++,*it为7经过判断不为偶数就再次执行++it,然后it就到了end位置,程序不满足循环调教,于是就退出了,我们再看看下面的情况
void test_vector6()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(4);
v.push_back(5);
v.push_back(6);
v.push_back(7);
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}
print_vector(v);
}运行结果:

我们发现我们的程序没有做到有效的偶数删除,这是因为erase删除是从后先前覆盖的,删除了第一个元素2后,第二个2就把第一个2覆盖掉了,但是此时我们的程序执行了++it,就跳过了第二个元素2,所以我们程序的逻辑还是有一点问题,所以我们来修改一下我们的代码
void test_vector6()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(4);
v.push_back(5);
v.push_back(6);
v.push_back(7);
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
else
++it;
}
print_vector(v);
}运行结果:

如果最后一个元素是偶数呢?
void test_vector6()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(4);
v.push_back(5);
v.push_back(6);
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
else
++it;
}
print_vector(v);
}运行结果:

我们发现将++it放入到else里面,我们的程序就能正常去掉偶数值。这是因为我们erase的实现逻辑是覆盖操作,删除数据没有对it进行改变。但是这里能正常去掉偶数值是偶然性,我们来使用一下库里面的vector,看看结果是怎样?
void test_vector6()
{
std::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(4);
v.push_back(5);
v.push_back(6);
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
else
++it;
}
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}运行结果:
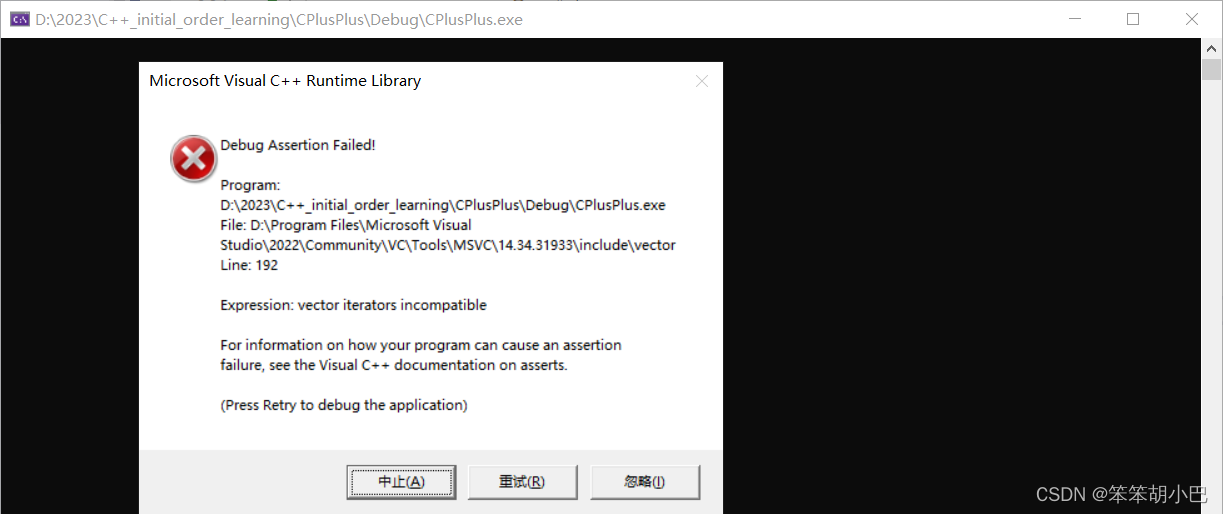
我们来调式一下,看看问题在哪?

我们发现我们的程序在332就出错了,这是因为vs进行了强制的检查验证,vs认为erase(it)之后,它就认为it此时已经失效了,就不允许再次访问了。所以我们上面的程序也是错误的,面对erase缩容和vs极端检查验证情况下都是错误的。
3.3. 注意:Linux下,g++编译器对迭代器失效的检测并不是非常严格,处理也没有vs下极端。
// 1. 扩容之后,迭代器已经失效了,程序虽然可以运行,但是运行结果已经不对了
int main()
{
vector<int> v{ 1,2,3,4,5 };
for (size_t i = 0; i < v.size(); ++i)
cout << v[i] << " ";
cout << endl;
auto it = v.begin();
cout << "扩容之前,vector的容量为: " << v.capacity() << endl;
// 通过reserve将底层空间设置为100,目的是为了让vector的迭代器失效
v.reserve(100);
cout << "扩容之后,vector的容量为: " << v.capacity() << endl;
// 经过上述reserve之后,it迭代器肯定会失效,在vs下程序就直接崩溃了,但是linux下不会
// 虽然可能运行,但是输出的结果是不对的
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}
程序输出:
1 2 3 4 5
扩容之前,vector的容量为: 5
扩容之后,vector的容量为 : 100
0 2 3 4 5 409 1 2 3 4 5// 2. erase删除任意位置代码后,linux下迭代器并没有失效
// 因为空间还是原来的空间,后序元素往前搬移了,it的位置还是有效的
#include <vector>
#include <algorithm>
int main()
{
vector<int> v{ 1,2,3,4,5 };
vector<int>::iterator it = find(v.begin(), v.end(), 3);
v.erase(it);
cout << *it << endl;
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
return 0;
}
程序可以正常运行,并打印:
4
4 5// 3: erase删除的迭代器如果是最后一个元素,删除之后it已经超过end
// 此时迭代器是无效的,++it导致程序崩溃
int main()
{
vector<int> v{ 1,2,3,4,5 };
// vector<int> v{1,2,3,4,5,6};
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}
for (auto e : v)
cout << e << " ";
cout << endl;
return 0;
}
========================================================
// 使用第一组数据时,程序可以运行
[sly@VM - 0 - 3 - centos 20220114]$ g++ testVector.cpp - std = c++11
[sly@VM - 0 - 3 - centos 20220114]$ . / a.out
1 3 5
======================================================== =
// 使用第二组数据时,程序最终会崩溃
[sly@VM - 0 - 3 - centos 20220114]$ vim testVector.cpp
[sly@VM - 0 - 3 - centos 20220114]$ g++ testVector.cpp - std = c++11
[sly@VM - 0 - 3 - centos 20220114]$ . / a.out
Segmentation fault
从上述三个例子中可以看到:SGI STL中,迭代器失效后,代码并不一定会崩溃,但是运行结果肯定不对,如果it不在begin和end范围内,肯定会崩溃的。
3.4. 与vector类似,string在插入+扩容操作+erase之后,迭代器也会失效
#include <string>
void TestString()
{
string s("hello");
auto it = s.begin();
// 放开之后代码会崩溃,因为resize到20会string会进行扩容
// 扩容之后,it指向之前旧空间已经被释放了,该迭代器就失效了
// 后序打印时,再访问it指向的空间程序就会崩溃
//s.resize(20, '!');
while (it != s.end())
{
cout << *it;
++it;
}
cout << endl;
it = s.begin();
while (it != s.end())
{
it = s.erase(it);
// 按照下面方式写,运行时程序会崩溃,因为erase(it)之后
// it位置的迭代器就失效了
// s.erase(it);
++it;
}
}迭代器失效解决办法:在使用前,对迭代器重新赋值即可。我们发现库中inser和erase是有返回值的。
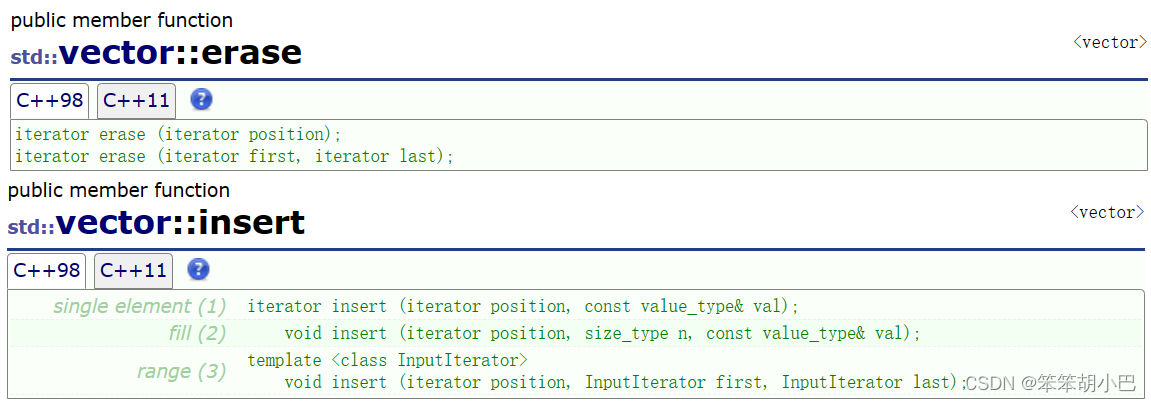
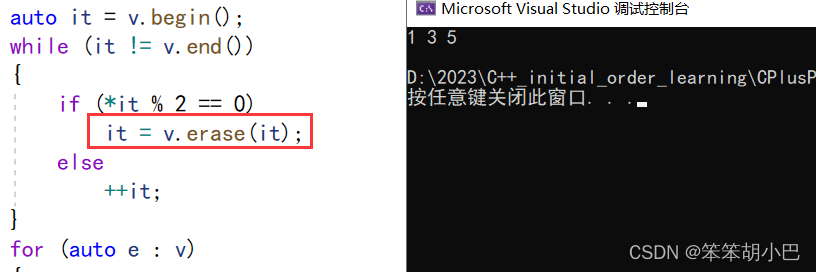
当我们用返回值接收对迭代器重新赋值,就解决了上面的问题。所以我们上面实现的erase函数和insert函数也要修改一下。
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _finish);
iterator it = pos + 1;
while (it < _finish)
{
*(it - 1) = *it ;
++it;
}
--_finish;
return pos;
}
// 在pos位置插入
iterator insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
// 检查扩容
if (_finish == _end_of_storage)
{
//记录pos到_start的距离
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : capacity() * 2);
//如果发生扩容
pos = _start + len;
}
// 把pos后面的数据移走,再把x放到pos位置
memmove(pos + 1, pos, sizeof(T) * (_finish - pos));
*pos = x;
++_finish;
return pos;
}再次用我们自己实现的vector就也可以正常运行。
结论:insert和erase形参pos都可能失效,原则是insert和erase过的迭代器都不要再使用。
4.vector深拷贝的相关问题
4.1 使用memcpy拷贝问题
假设模拟实现的vector中的reserve接口中,使用memcpy进行的拷贝,以下代码会发生什么问题?
void test_vector8()
{
vector<string> v;
v.push_back("1111");
v.push_back("2222");
v.push_back("3333");
v.push_back("4444");
v.push_back("5555");
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}运行结果:

我们来调式一下

我们发现我们的程序在扩容之后就出现了错误。
问题分析:
- 1. memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中
- 2. 如果拷贝的是基本类型的元素,memcpy既高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
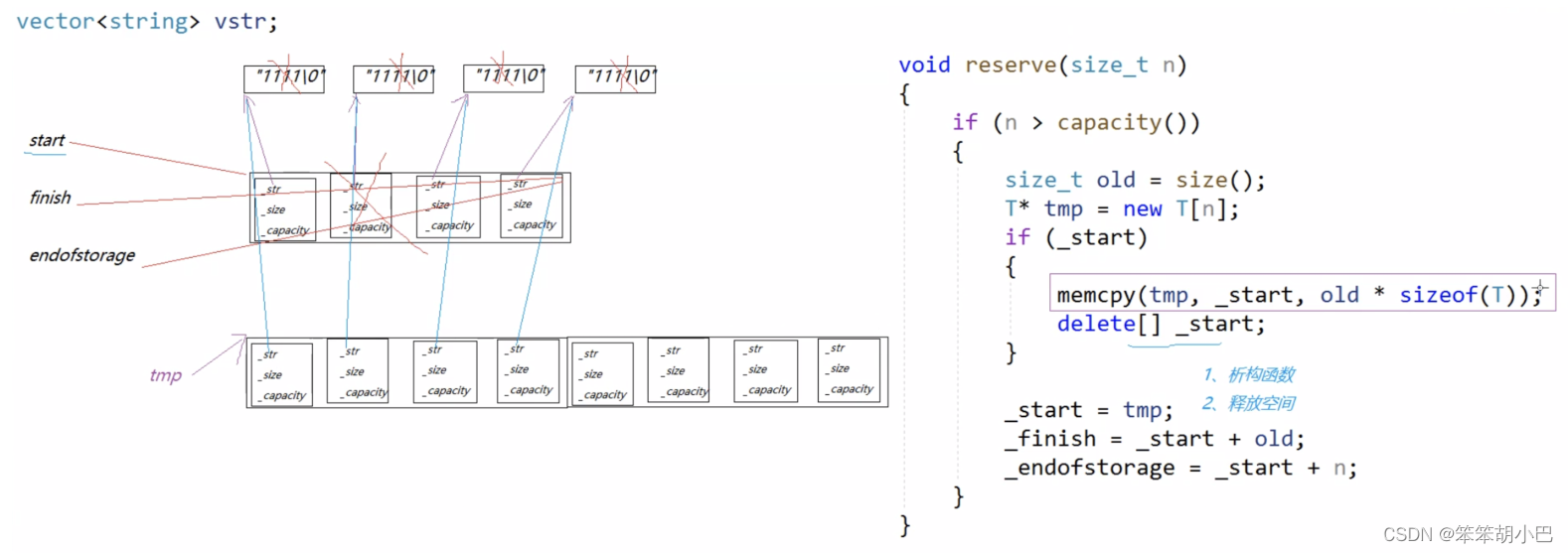
我们的delete会做两件事,首先是调用析构函数,然后再是释放空间,由于memcpy的拷贝实际是浅拷贝,再使用delete后,_str就会被析构函数情况,导致tmp里面的_str就是野指针,从而导致程序出错,所以要想解决这里的问题,就要对每一个string去做深拷贝。
void reserve(size_t n)
{
if (n > capacity())
{
T* temp = new T[n];
size_t oldsize = size();//保存旧空间有效元素的个数
if (_start)
//memcpy(temp, _start, n * sizeof(T));
for (size_t i = 0; i < oldsize; i++)
{
temp[i] = _start[i];//赋值操作符
}
delete[] _start;
_start = temp;
_finish = _start + oldsize;
_end_of_storage = _start + n;
}
}通过赋值操作符实现上面的深拷贝,temp[i]就是我们的string类型,进行赋值操作,它就会去调用string类的赋值操作符重载去实现深拷贝。结论:如果对象中涉及到资源管理时,千万不能使用memcpy进行对象之间的拷贝,因为memcpy是 浅拷贝,否则可能会引起内存泄漏甚至程序崩溃,我们的我insert里面有memmove,它也是浅拷贝,我们也要修改一下
// 在pos位置插入
iterator insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
// 检查扩容
if (_finish == _end_of_storage)
{
//记录pos到_start的距离
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : capacity() * 2);
//如果发生扩容
pos = _start + len;
}
// 把pos后面的数据移走,再把x放到pos位置
//memmove(pos + 1, pos, sizeof(T) * (_finish - pos));
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
return pos;
}这里也是如此,当T是string类型的时候,此时就是string赋值给string,此时调用的就是string的赋值了。
5.动态二维数组理解
// 以杨慧三角的前n行为例:假设n为5
void test2vector(size_t n)
{
// 使用vector定义二维数组vv,vv中的每个元素都是vector<int>
yu::vector<yu::vector<int>> vv(n);
// 将二维数组每一行中的vecotr<int>中的元素全部设置为1
for (size_t i = 0; i < n; ++i)
vv[i].resize(i + 1, 1);
// 给杨慧三角出第一列和对角线的所有元素赋值
for (int i = 2; i < n; ++i)
{
for (int j = 1; j < i; ++j)
{
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];
}
}
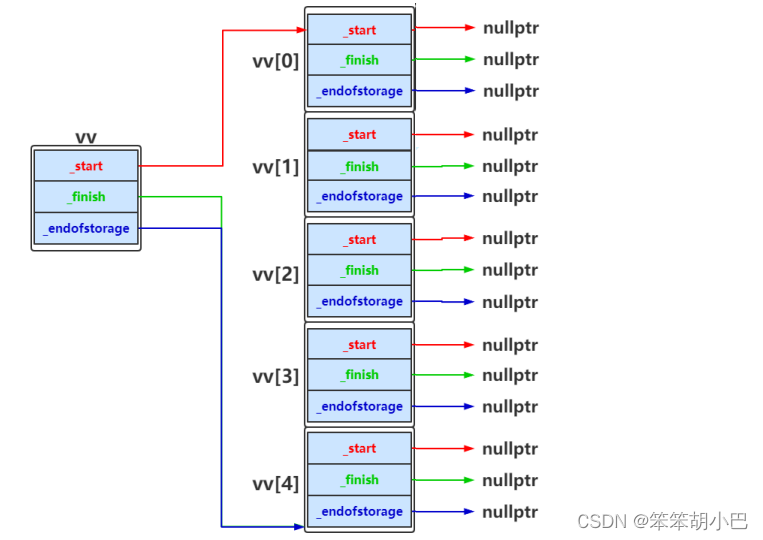
}yu::vector<yu::vector<int>> vv(n);构造一个vv动态二维数组,vv中总共有n个元素,每个元素都是vector类 型的,每行没有包含任何元素,如果n为5时如下所示:
vv中元素填充完成之后,如下图所示:
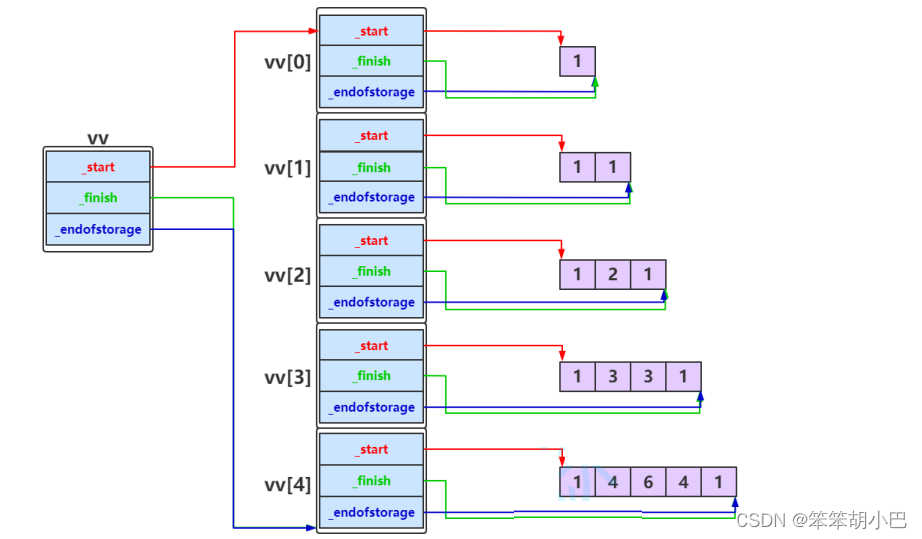
使用标准库中vector构建动态二维数组时与上图实际是一致的。