Lecture #21_ Introduction to Distributed Databases
Distributed DBMSs
分布式 DBMS 将单个逻辑数据库划分为多个物理资源。应用程序(通常)并不知道数据被分割在不同的硬件上。系统依靠单节点 DBMS 的技术和算法来支持分布式环境中的事务处理和查询执行。设计分布式 DBMS 的一个重要目标是容错(即避免单个节点故障导致整个系统瘫痪)。
- arallel DBMS:资源或节点在物理上彼此靠近。这些节点通过高速互连进行通信。它假设资源之间的通信不仅快速,而且便宜可靠;
- Distributed DBMS:资源之间可能相距甚远,因此,资源使用较慢的互连(通常通过公共网络)进行通信。节点之间的通信成本较高,而且故障不容忽视;
System Architectures
DBMS 的系统架构规定了 CPU 可直接访问的共享资源。它影响 CPU 之间的相互协调,以及 CPU 在数据库中检索和存储对象的位置。
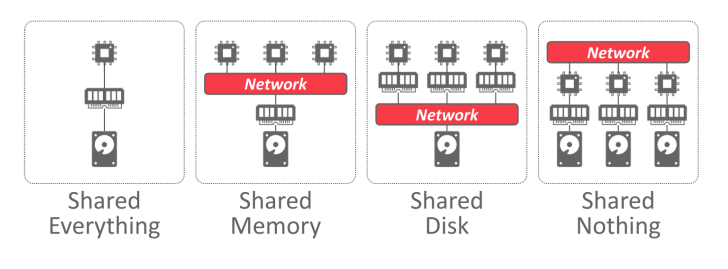
单节点 DBMS 使用所谓的shared everything架构。单节点在本地 CPU 上执行worker,并拥有自己的本地内存地址空间和磁盘。
- Shared Memory
- 在分布式系统中,共享内存是shared everything架构的替代方案。CPU 可通过快速互连访问公共内存地址空间,CPU 还可共享同一磁盘。
- 实际上,大多数 DBMS 都不使用这种架构,因为它是在操作系统/内核级别上提供的。这也会带来一些问题,因为每个进程的内存范围都是同一个内存地址空间,可能会被多个进程修改。
- 每个处理器都有一个关于所有内存数据结构的全局视图。处理器上的每个 DBMS 实例都必须 "了解 "其他实例。
- Shared Disk
- 在共享磁盘架构中,所有 CPU 都可以通过互连直接读写单个逻辑磁盘,但每个 CPU 都有自己的专用存储器。每个计算节点上的本地存储可以充当缓存。这种方法在基于云的 DBMS 中较为常见。
- DBMS 的执行层可以独立于存储层进行扩展。增加新的存储节点或执行节点不会影响其他层的数据布局或位置。
- 节点之间必须发送信息,以了解其他节点的当前状态。也就是说,由于内存是本地的,如果数据被修改,那么在该数据也位于其他 CPU 的主内存中时,必须将修改信息传递给其他 CPU。
- 节点有自己的缓冲池,被认为是无状态的。节点崩溃不会影响数据库的状态,因为数据库是单独存储在共享磁盘上的。存储层会在发生崩溃时保持状态。
- Shared Nothing
- 每个节点都有自己的 CPU、内存和磁盘。节点之间只通过网络通信。在云存储平台兴起之前曾被认为是构建分布式 DBMS 的正确方法。
- 在这种架构中,增加容量比较困难,因为 DBMS 必须将数据物理移动到新节点上。此外,要确保 DBMS 中所有节点的一致性也很困难,因为节点之间必须就事务的状态进行协调。不过,它的优点是,与其他类型的分布式 DBMS 体系结构相比,有可能实现更好的性能和更高的效率。
Design Issues
分布式 DBMS 的目标是保持数据的透明度,在单节点 DBMS 上运行的 SQL 查询在分布式 DBMS 上也能运行。
同构节点:集群中的每个节点都能执行同一套任务(尽管可能是不同的数据分区),因此非常适合shared nothing。这使得配置和故障切换变得 “更容易”。失败的任务会分配给可用的节点。
异构节点:节点被分配特定的任务,因此节点之间必须进行通信才能执行特定的任务。这样,单个物理节点就可以承载多个 "虚拟 "节点类型,用于执行专用任务,并可从一个节点独立扩展到其他节点。MongoDB 就是一个例子,它有路由器节点将查询路由到分片,有配置服务器节点存储从键到分片的映射。
Partitioning Schemes
分布式系统必须在多个资源(包括磁盘、节点、处理器)上对数据库进行分区。 在 NoSQL 系统中,这一过程有时被称为分片。DBMS 收到查询后,首先会分析查询计划需要访问的数据。DBMS 可能会将查询计划的片段发送到不同的节点,然后将结果合并,生成一个单一的答案。
分区方案的目标是最大限度地增加单节点事务,或只访问一个分区中包含的数据的事务。这样,数据库管理系统就无需协调其他节点上运行的并发事务的行为。另一方面,分布式事务会访问一个或多个分区的数据。这就需要昂贵而困难的协调工作。
对于逻辑分区节点,特定节点负责访问共享磁盘中的特定tuple。
对于物理分区节点,每个shared nothing节点读取和更新自己本地磁盘上的数据元组。
对表进行分区的最简单方法是 naive data partitioning。假设给定节点有足够的存储空间,则每个节点存储一个表。这种方法很容易实现,因为查询只需路由到特定的分区。但这并不好,因为它不具备可扩展性。如果经常查询一个表,而不是使用所有可用节点,那么一个分区的资源就会耗尽。
另一种分区方式是 vertical partitioning 垂直分区,它将表的属性分割成不同的分区。 每个分区还必须存储元组信息,以便重建原始记录。
更常见的是 horizontal partitioning 水平分区,它将表中的元组分割成互不相关的子集。选择在大小、负载或使用方面等分数据库的列,记为分区键。
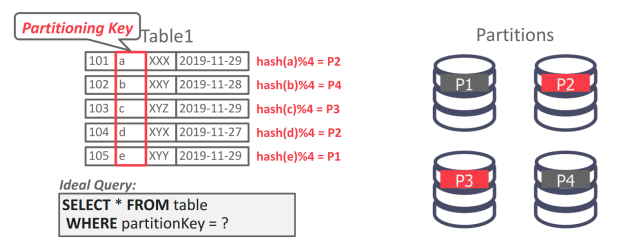
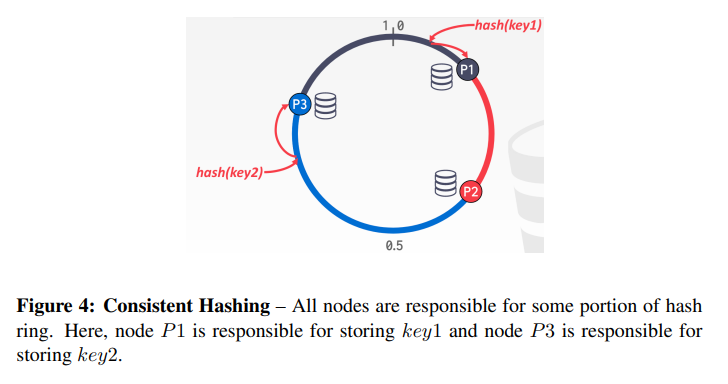
DBMS 可以根据散列、数据范围或谓词对数据库进行物理分区(shared nothing)或逻辑分区(共享磁盘)。散列分区的问题在于,当节点被添加或删除时,大量数据必须被洗牌。解决这个问题的方法就是一致性哈希。
一致性哈希将每个节点分配到某个逻辑环上的某个位置。然后,每个分区key的散列映射到环上的一个位置。顺时针方向上最靠近的节点负责该键。当节点添加或删除时,密钥只会在与新节点/删除节点相邻的节点之间移动,因此只有 1/n 部分的键会被移动。复制因子为 k 意味着每个键在顺时针方向最近的 k 个节点上被复制。
逻辑分区:节点负责一组键,但实际上并不存储这些键。这通常用于共享磁盘架构。
物理分区:节点负责一组键,并实际存储这些密钥。这通常用于无共享架构。
Distributed Concurrency Control
分布式事务访问一个或多个分区的数据,这就需要昂贵的协调工作。
- Centralized coordinator
- 集中式协调器协调所有行为。
- 客户端与协调器通信,以获取客户端希望访问的分区的锁。一旦收到协调器的确认,客户端就会向这些分区发送查询。 一旦某个事务的所有查询都完成,客户端就会向协调器发送提交请求。协调器随后会与事务中涉及的分区通信,以确定是否允许事务提交。
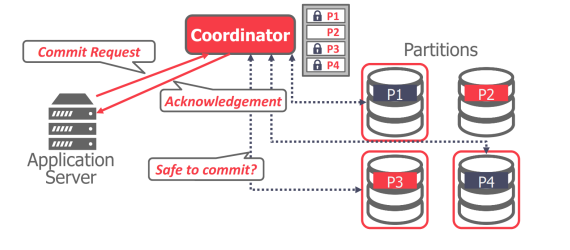
- Middleware
- 集中式协调器可用作中间件,接受查询请求并将查询路由到正确的分区。
- Decentralized coordinator
- 在分散式方法中,节点自行组织。客户端直接向其中一个分区发送查询。这个home partition将把结果发回给客户端。home partition负责与其他分区通信,并提交相应。
- 如果多个客户端试图获取同一分区上的锁,集中式方法就会出现瓶颈。对于分布式 2PL 来说,集中式方法会更好,因为它可以集中查看锁,并能更快地处理死锁。而分散式方法则很难做到这一点。
Lecture #22_ Distributed OLTP Databases
OLTP VS. OLAP

Distributed Transactions
如果一个事务访问多个节点上的数据,那么它就是 “分布式” 事务。执行这些事务比单节点事务更具挑战性,因为现在事务提交时,DBMS 必须确保所有节点都同意提交事务。DBMS 要确保数据库提供与单节点 DBMS 相同的 ACID 保证。
我们可以假设,分布式 DBMS 中的所有节点都很乖巧,并处于同一管理域之下。换句话说,如果没有节点故障,被告知要提交事务的节点就会提交事务。如果分布式 DBMS 中的其他节点不可信,那么 DBMS 就需要为事务使用容错协议(如区块链)。
Atomic Commit Protocols
当多节点事务结束时,DBMS 需要询问所有相关节点是否可以安全提交。根据协议的不同,可能需要大多数节点或所有节点提交。如两(三)阶段提交、raft、paxos、ZAB等。
如果协调器在发送准备信息后发生故障,两阶段提交(2PC)就会阻塞,直到协调器恢复。另一方面,如果大多数参与者都活着,只要有足够长的时间不再发生故障,Paxos 就不会阻塞。如果节点在同一个数据中心,不经常发生故障,也没有恶意,那么 2PC 通常比 Paxos 更受青睐,因为 2PC 通常会减少往返次数。
- Two-Phase Commit
- 客户端向协调器发送提交请求。在协议的第一阶段,协调器发送准备信息,主要是询问参与节点是否允许提交当前事务。如果某个参与节点确认当前事务有效,就会向协调器发送 “确定” 信息。 如果协调器收到所有参与节点的 "确定 "信息,系统就可以进入协议的第二阶段。如果有人向协调者发送中止,协调者就会向客户端发送中止。
- 协调器向所有参与方发送 “提交”(Commit)命令,如果所有参与方都发送了 “确定”(OK),协调器就会通知这些节点提交事务。一旦参与方回复 OK,协调器就可以告诉客户端事务已提交。如果事务在第一阶段被中止,参与者就会收到协调器发出的中止指令,并以 OK 作为回应。要么所有人都提交,要么没人提交。协调者也可以是系统的参与者。
- 此外,在发生崩溃的情况下,所有节点都会记录每个阶段的非易失性日志。 节点会阻塞,直到想出下一步行动方案。如果协调器崩溃,参与者必须决定如何处理。安全的选择是终止。或者,节点可以相互通信,看看是否可以在没有协调者明确许可的情况下提交。如果某个参与方崩溃,协调方如果还没有发送确认,就会假定该参与方以中止作为回应。
- 优化:
- 提前准备投票:DBMS 向一个远程节点发送查询,而它知道这将是在该节点执行的最后一次查询,那么该节点也会将其在准备阶段的投票与查询结果一起返回;
- 准备后提前确认:如果所有节点都投票决定提交事务,协调器可在提交阶段结束前向客户端发送事务成功的确认信息。
- Paxos
- 与 2PC 相比,Paxos(以及 Raft)在现代系统中更为普遍。2PC 是 Paxos 的退化情况;Paxos 使用 2F + 1 个协调器,只要其中至少有 F + 1 个协调器正常工作就能取得进展,而 2PC 则设定 F = 0。
- Paxos 是一种共识协议,由协调者提出一个结果(如提交或中止),然后由参与者投票决定该结果是否应该成功。如果大多数参与者都可用,该协议就不会阻塞,而且在最佳情况下,消息延迟可证明是最小的。对于 Paxos 来说,协调者称为提议者,参与者称为接受者。
- 一旦大多数接受者发送了 “同意”(Agree),提议者就会发送 “提交”(Commit)。与 2PC 不同的是,提议者必须等收到大多数接受者的 Accept 后,才会向客户端发送 “事务已提交” 的最终消息。
- Multi-Paxos:如果系统选出一个领导者,在一段时间内监督提议更改,那么就可以跳过提议阶段。当出现故障时,DBMS 可以退回到 full Paxos 阶段。
Replication
DBMS 可以在冗余节点上复制数据,以提高可用性。换句话说,如果某个节点宕机,数据不会丢失,而且系统仍然存活,无需重启。我们可以使用 Paxos 来决定向哪个副本写入数据。
在主副本中,每个对象的所有更新都会发送到指定的主副本。主服务器在不使用原子提交协议的情况下将更新传播到其副本,协调所有更新。如果不需要最新信息,可以允许只读事务访问副本。如果主服务器宕机,则会进行选举,选出新的主服务器。
在多副本中,事务可以在任何副本中更新数据对象。副本之间必须使用原子提交协议(如 Paxos 或 2PC。
K-safety 是确定复制数据库容错性的阈值。K 值表示每个数据对象必须始终可用的副本数量。如果副本数量低于这个阈值,DBMS 就会停止执行并下线。K 值越大,丢失数据的风险就越小。它是确定系统可用程度的阈值。
当事务在复制数据库中提交时,DBMS 会决定是否必须等待该事务的更改传播到其他节点,然后才能向应用程序客户端发送确认。有两种传播级别:同步(强一致性)和异步(最终一致性):
- 在同步方案中,主节点向副本发送更新,然后等待副本确认已完全应用(即记录)更改。然后,主数据库就可以通知客户端更新已成功。
- 在异步方案中,主服务器会立即向客户端返回确认,而不会等待副本应用更改。在这种方法中可能会出现过时的读取,因为在读取时更新可能还没有完全应用到副本中。如果可以容忍一定程度的数据丢失,那么这种优化方式是可行的。这在 NoSQL 系统中很常用。
传播定时:
- continuous:DBMS 会在生成日志信息时立即发送。请注意,提交和中止信息也需要发送。大多数系统都采用这种方法。
- on commit:只有在事务提交后,DBMS 才会向副本发送事务的日志信息。这样做不会浪费发送中止事务日志记录的时间,但会假设事务日志记录完全位于内存中。
向副本应用更改:
- 对于active-active方式,事务在每个副本中独立执行。最后,DBMS 需要检查事务在每个副本中的结果是否相同,以确定副本是否正确提交。这很困难,因为现在事务的排序必须在所有节点之间同步,这使得它不太常见。
- 对于active-passive式,每个事务都在单个位置执行,并将整体变更传播到副本。DBMS 可以发送被更改的物理字节(这是比较常见的),也可以发送逻辑 SQL 查询。
CAP Theorem
CAP 定理解释了分布式系统不可能始终保持一致性、可用性和分区容忍性(Consistent, Available, and Partition Tolerant)。这三个属性中只能选择两个。
一致性:一旦写入完成,所有未来的读取都应返回该写入应用或后续写入应用的值。此外,一旦读取返回,以后的读取都应返回该值或以后应用的写入值。NoSQL 系统在这一属性上有所妥协,更倾向于后两个属性。其他系统则偏向于这一属性和后两者之一。
可用性:所有正常运行的节点都能满足所有请求。
分区容错:尽管在试图就数值达成共识的节点之间会有一些信息丢失,但系统仍能正常运行。如果系统选择了一致性和分区容错,那么在大多数节点重新连接之前,将不允许进行更新。
现代版本考虑了一致性与延迟的权衡:PACELC 定理。如果分布式系统中存在网络分区 §,则必须在可用性 (A) 和一致性 © 之间做出选择,否则 (E),即使系统在没有网络分区的情况下正常运行,也必须在延迟 (L) 和一致性 © 之间做出选择。
Lecture #23_ Distributed OLAP Databases
Decision Support Systems
对于只读 OLAP 数据库来说,通常会有一个分支环境,即有多个 OLTP 数据库实例从外部世界获取信息,然后将这些信息输入后端 OLAP 数据库(有时称为数据仓库)。中间的步骤称为 ETL,即Extract、Transform和Load,它是将 OLTP 数据库合并为数据仓库的通用模式。
决策支持系统(Decision support systems,DSS)是服务于组织的管理、运营和规划层面的应用程序,通过分析存储在数据仓库中的历史数据,帮助人们就未来的问题做出决策。
建立分析数据库模型的两种方法是星形模式和雪花模式:
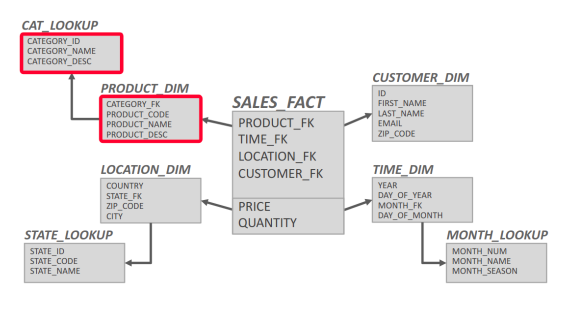
- 星形模式包含两类表:事实表和维度表。事实表包含应用程序中发生的多个 “事件”。它将包含每个事件的最小唯一信息,然后其余属性将作为外层维度表的外键引用。维度表包含在多个事件中重复使用的冗余信息。在星形模式中,只能从事实表中抽出一个维度层。由于数据只能有一级维度表,因此可能存在冗余信息。非规范化数据模型可能会导致完整性和一致性违规,因此必须对复制进行相应处理。星形模式的查询(通常)比雪花模式快,因为连接较少。
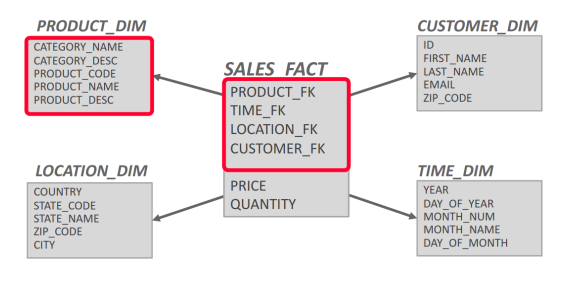
- 雪花模式与星形模式类似,只是允许从事实表中列出一个以上的维度。因此,星形模式的查询速度通常更快。
Execution Models
分布式 DBMS 的执行模型规定了查询执行期间节点之间的通信方式。执行查询的两种方法是 pushing 和 pulling。
将查询推送到数据:DBMS 将查询(或部分查询)发送到包含数据的节点,然后在通过网络传输之前,尽可能在数据所在的位置进行过滤和处理。然后将结果发回正在执行查询的节点,该节点使用本地数据和发送给它的数据完成查询。这种情况在无共享系统中更为常见。
为查询调用数据:DBMS 会将数据调用到正在执行查询的节点,以处理需要的数据。换句话说,节点会检测它们可以对哪些数据分区进行计算,并相应地从存储中提取数据。然后,本地操作被传播到一个节点,由该节点对所有中间结果进行操作。这通常是共享磁盘系统的做法。这样做的问题是,相对于查询的大小,数据的大小可能会有很大差异。也可以发送过滤器,以便只从磁盘检索所需的数据。
节点从远程来源接收的数据会缓存在缓冲池中。这样,DBMS 就能支持大于可用内存量的中间结果。但是,短暂页面在重启后不会被持久化。
大多数无共享分布式 OLAP DBMS 在设计时都假定节点在查询执行过程中不会发生故障。如果一个节点在查询执行过程中发生故障,那么整个查询就会失败。DBMS 可以在执行过程中对查询的中间结果进行快照,以便在节点发生故障时恢复。不过,这种操作的成本很高,因为将数据写入磁盘的速度很慢。
Query Planning
之前谈到的所有优化方法仍然适用于分布式环境,包括 predicate pushdown、early projections、optimal join orderings。分布式查询优化更加困难,因为它必须考虑数据在集群中的物理位置和数据移动成本。一种方法是生成一个单一的全局查询计划,然后将物理算子分发到节点,将其分解为特定于分区的片段。大多数系统都采用这种方法。
另一种方法是使用 SQL 查询,并将原始查询重写为特定分区查询。 这样就可以在每个节点上进行局部优化。SingleStore 和 Vitess 就是使用这种方法的系统实例。
Distributed Join Algorithms
对于分析型workload来说,大部分时间都花在连接和从磁盘读取数据上。分布式连接的效率取决于目标表的分区方案。
一种方法是将整个表放在一个节点上,然后执行连接。但是,这样 DBMS 就失去了分布式 DBMS 的并行性,也就失去了使用分布式 DBMS 的意义。这种方法还需要在网络上进行昂贵的数据传输。
要连接表 R 和表 S,DBMS 需要在同一节点上获取适当的数据元组。一旦连接成功就会执行连接算法。我们应该始终发送计算连接所需的最小数据量,有时甚至是整个数据元组。
分布式连接算法有四种情况:
- 其中一个表在每个节点上复制,另一个表在各节点上分区。每个节点并行连接其本地数据,然后将结果发送到协调节点。
- 两个表都根据连接属性进行分区,每个节点上的 ID 都是匹配的。每个节点对本地数据执行连接,然后发送到一个节点进行整合。
- 这两个表都根据不同的键进行分区。如果其中一个表较小,系统就会向所有节点广播该表。这又回到了方案 1。先计算本地连接,然后将这些连接发送到公共节点,以执行最终连接。这就是所谓的broadcast join。
- 这是最糟糕的情况。两个表都没有根据连接键进行分区。DBMS 通过在节点间重新洗牌来复制表。计算本地连接,然后将结果发送到公共节点进行最终连接。如果没有足够的磁盘空间,失败是不可避免的。这就是所谓的shuffle join。
半连接是一种连接操作,其结果只包含左表中的列。分布式 DBMS 使用半连接来尽量减少连接过程中发送的数据量,它与自然连接类似,只是限制了右表中未用于计算连接的属性。
Cloud Systems
供应商提供了_database-as-a-service_ (DBaaS)来提供受管理的DBMS环境。
云系统分为两种类型:
- 托管式DBMS(Managed DBMSs):
- 在托管式DBMS中,对DBMS的修改不大,以使其“意识到”它在云环境中运行。它提供了一种将客户端的备份和恢复抽象化的方式。这种方法在大多数供应商中得以应用。
- 云原生DBMS(Cloud-Native DBMS):
- 云原生系统是专门设计用于在云环境中运行的系统,通常基于共享磁盘架构。这种方法在Snowflake、Google BigQuery、Amazon Redshift和Microsoft SQL Azure等系统中使用。
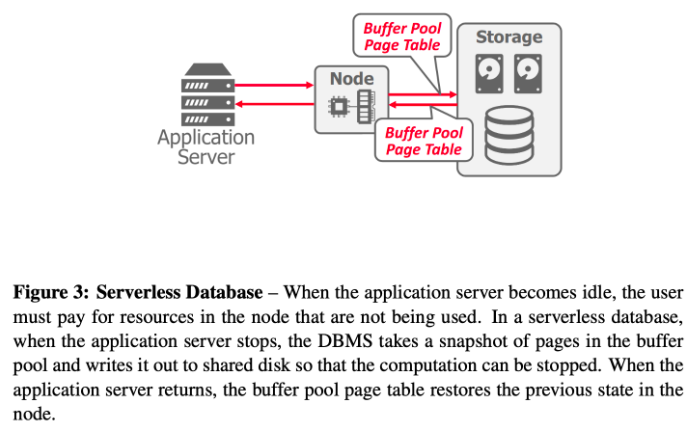
服务器无感知数据库(Serverless Databases):
- 与始终保持为每个客户端维护计算资源不同,无服务器DBMS在租户变得空闲时将其驱逐,并将当前进度保存到磁盘上。现在,用户只需要在不主动查询时支付存储费用。
数据湖(Data Lakes):
- 数据湖是一个集中的存储库,用于存储大量的结构化、半结构化和非结构化数据,而无需定义模式或将数据导入专有的内部格式。数据湖通常更快地接收数据,因为它们不需要立即进行转换。但它们要求用户编写自己的转换管道。
Disaggregated Components
一些可以帮助构建 distributed database 的组件库/系统:
- System Catalogs: HCatalog, Google Data Catalog, Amazon Glue Data Catalog,
- Node Management: Kubernetes, Apache YARN, Cloud Vendor Tools
- Query Optimizers: Greenplum Orca, Apache Calcite
Universal Formats
大多数 DBMS 为其数据库使用专有的磁盘二进制文件格式。 在系统之间共享数据的唯一方法是将数据转换为通用的基于文本的格式,包括 CSV、JSON 和 XML。云供应商和分布式数据库系统支持新的开源二进制文件格式,这使得跨系统访问数据变得更加容易。
通用数据库文件格式的著名示例:
- Apache Parquet:来自Cloudera/Twitter 的压缩列式存储。
- Apache ORC:Apache Hive 的压缩列式存储。
- Apache CarbonData:来自华为的带索引的压缩列式存储
- Apache Iceberg:来自Netflix的支持模式演化的灵活数据格式
- HDF5:用于科学工作负载的多维数组。
- Apache Arrow:Pandas/Dremio 的内存压缩列式存储。
Lecture #24_ Putting Application Logic into the Database
Motivation
到目前为止,我们一直认为应用程序的所有逻辑都位于应用程序本身。大多数应用程序使用 “对话式” 应用程序接口(如 JDBC、ODBC)与数据库管理系统交互。应用程序向数据库管理系统发送查询请求,然后等待响应。DBMS 发送响应后,就会等待应用程序对该连接的下一个请求。
可以将复杂的应用逻辑移入 DBMS,以避免多次网络往返。 这样做可以提高应用程序的效率、响应速度和可重用性。 这些方法的缺点是语法通常无法在不同的 DBMS 之间移植。
User-Defined Functions
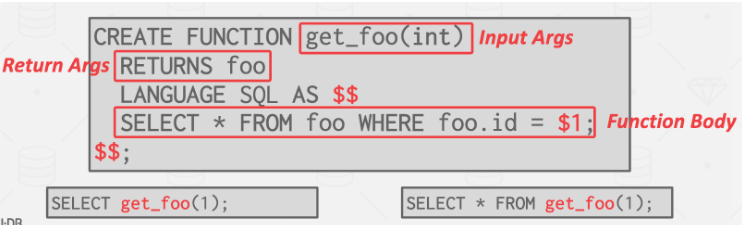
用户定义函数(User Defined Function,UDF)是由应用程序开发人员编写的函数,用于扩展系统的功能,超越其内置操作。每个函数接受标量输入参数,执行一些计算,然后返回一个结果(标量或表)。UDF只能作为SQL语句的一部分来调用。
返回类型
- 标量函数(Scalar Functions):返回单个数据值。
- 表函数(Table Functions):返回单个结果表。
函数体
- SQL函数(SQL Functions):基于SQL的UDF包含一系列SQL语句,当调用UDF时,DBMS按顺序执行这些语句。UDF返回最后一个查询的结果。
- 原生编程语言:开发人员可以使用DBMS原生支持的语言编写UDF。例如,SQL/PSM(SQL标准)、PL/SQL(Oracle、DB2)、PL/pgSQL(Postgres)、Transact-SQL(MSSQL/Sybase)。
- 外部编程语言:UDF可以使用更常规的编程语言编写(例如C、Java、JavaScript、Python),以独立的进程(沙盒)运行,以防止它们崩溃DBMS进程。
优点
- 模块化和代码重用:不同的查询可以重用相同的应用程序逻辑,无需重新实现。
- 减少网络开销:对于复杂操作,查询将减少应用程序服务器和DBMS之间的网络往返次数。
- 可读性:某些类型的应用程序逻辑以UDF的形式比SQL更容易表达和阅读。
缺点
- black box:查询优化器通常将UDFs视为黑匣子,因此无法估算其成本。
- 缺乏并行性:并行化查询具有挑战性,因为一系列查询可能存在相关性。一些UDFs会在运行时逐步构建查询序列。一些DBMS只会使用单个线程执行带有UDF的查询。
- 复杂的UDF在没有系统优化的情况下进行迭代执行可能非常慢。
Stored Procedures
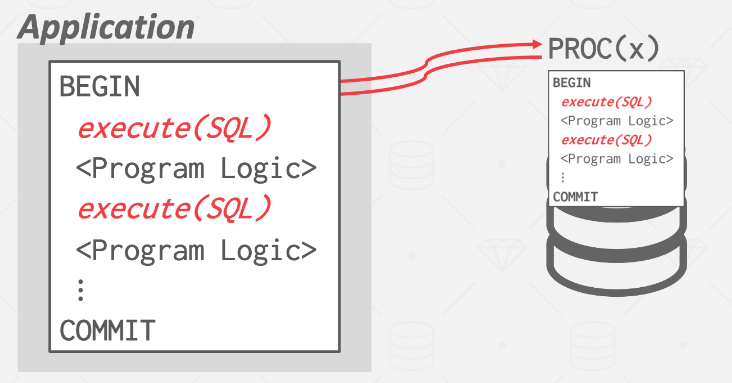
- _stored procedure _是一个独立的函数,它在 DBMS 内部执行更复杂的逻辑。
- 与 UDF 不同,stored procedure可以单独调用,而不必成为 SQL 语句的一部分。
- UDF 通常也是只读的,而stored procedure则允许修改DBMS
Triggers
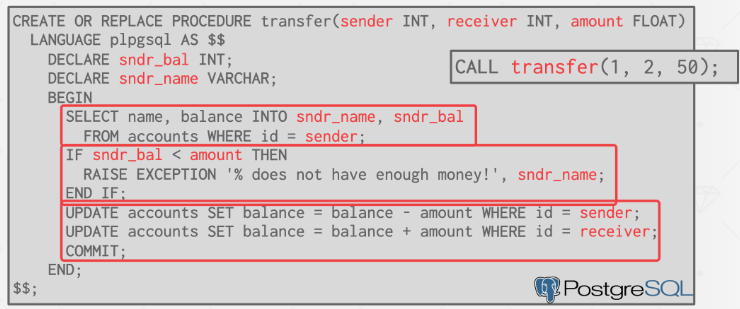
触发器(Trigger)是指示DBMS在数据库发生某个事件时调用用户定义函数(UDF)的机制。触发器的一些示例用途包括在表中的元组被修改时进行约束检查或审计。
每个触发器都具有以下属性:
- 事件类型(Event Type):表示触发器在何种类型的修改事件发生时被触发,常见的事件类型包括INSERT(插入)、UPDATE(更新)、DELETE(删除)、ALTER(修改)等。
- 事件范围(Event Scope):表示触发器的作用范围,即触发器应该针对哪个对象进行触发,常见的事件范围包括TABLE(表)、DATABASE(数据库)、VIEW(视图)等。
- 触发时机(Timing):表示触发器应该在SQL语句执行的哪个时刻被激活,常见的时机包括BEFORE(之前)、AFTER(之后)、INSTEAD OF(替代)等。BEFORE触发器通常在SQL语句执行之前触发,AFTER触发器通常在SQL语句执行之后触发,而INSTEAD OF触发器可以在SQL语句执行之前替代原始操作。
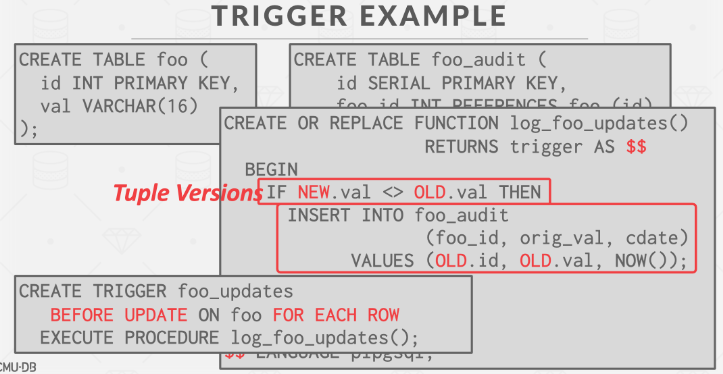
Change Notifications
变更通知(Change Notification)类似于触发器(Trigger),但是不同之处在于DBMS会向外部实体发送消息,告知数据库中发生了重要事件。它们可以与触发器一起链接,以在发生更改时传递通知。通知是异步的,这意味着只有在它们与DBMS互动时,才会被推送到正在监听的连接。一些ORM(对象关系映射)工具会定期使用轻量级的“SELECT 1”轮询DBMS,以获取新的通知。
通知通常包括以下命令:
- LISTEN(监听):连接在命名事件队列上注册,以侦听通知。
- NOTIFY(通知):将通知推送到任何正在命名事件队列上监听的连接。
User-Defined Types
大多数 DBMS 都支持 SQL 标准中定义的基本原始类型(如 ints、floats、varchars)。但有时应用程序希望存储由多个基本类型组成的复杂类型。或者,这些复杂类型可能对各种算术运算符具有不同的行为。
一种可能的解决方案是将复杂类型拆分存储,并将其每个基本元素作为自己的属性存储在表中。这样做的问题是,必须确保应用程序知道如何拆分/合并复合类型。另一种解决方案是让应用程序将复杂类型序列化(例如 Java “serialize”、Python “pickle”、Google Protobufs),并将其作为 blob 存储在数据库中。这种方法的问题是,如果不先反序列化整个 blob,就无法编辑类型中的子属性。
同样,DBMS 的优化器也无法估量访问序列化数据的谓词的选择性。 一种更好的方法是使用用户自定义类型(UDT)。这是一种特殊的数据类型,由应用程序开发人员定义,DBMS 可以原生存储。
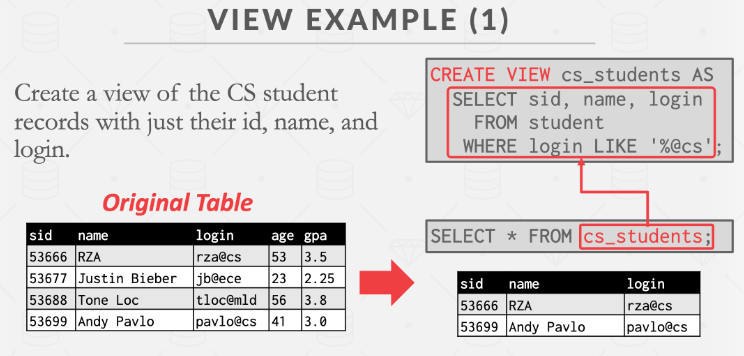
Views
创建一个包含 SELECT 查询输出的“虚拟”表。 然后可以像访问真实的表一样访问该视图。这允许程序员简化经常执行的复杂查询。(但它不会让 DBMS 运行得更快)通常还用作隐藏表的某些属性对特定用户不可见的机制。
与 SELECT…INTO 不同,视图不分配表来存储视图的结果。**物化视图(materialized view)**在内部维护视图的结果,当底层表发生变化时,视图的结果可能会自动更新。
![[设计模式Java实现附plantuml源码~创建型] 确保对象的唯一性~单例模式](https://img-blog.csdnimg.cn/direct/de13831771604c6bb436d863e5aea743.png)